说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先来看下Mapreduce的局限性和Spark如何做的改进.
Spark概述
MapReduce局限性
1 仅支持Map和Reduce两种操作
2 处理效率极低
- Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据;
- 任务调度和启动开销大
- 无法充分利用内存
- Map端和Reduce端均需要排序
3 不适合迭代计算(如机器学习,图计算等),交互处理(数据挖掘)和流式处理(实时日志分析)
4 MapReduce编程不够灵活
Spark的特点
1 高效(比MapReduce快10~100倍)
- 内存计算引擎,提供Cache机制来支持需要反复迭代计算或多次数据共享,减少数据读取的IO开销
- DAG引擎,减少多次计算之间中间结果写到HDFS的开销
- 使用多线程模型来减少task启动开销,shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
2 易用
提供了丰富的API,支持Java, Scala, Python和R四中语言
代码量比MapReduce少2~5倍
3 与Hadoop集成
- 读写HDFS/Hbase
- 与YARN集成
小结
IO和内存上: MapReduce数据从Map产出会写本地磁盘,并且排序, Reduce读取Map产出的数据计算后再产出到HDFS. 所以MapReduce的IO需要的多,并且数据来回在内存中加载释放. 而Spark把数据加载到内存中之后(DAG计算引擎)直到计算出结果才产出到HDFS(如果数据量超过内存量,也会溢写到磁盘).
调度上: Spark的每个Executor都有一个线程池(有一个线程公用的cache,省去进程频繁启停的开销),每一个task占用其中一个线程.
API上:MapReduce只有Map和Reduce操作, Spark有丰富的API使编程非常方便灵活.
Spark核心概念
RDD(Resilient Distributed Datasets)
弹性分布式数据集
- 分布在集群中的只读对象集合(由多个Partition构成)
- 可以存储在磁盘或内存中(多种存储级别)
- 通过并行“转换”操作构造
- 失效后自动重构
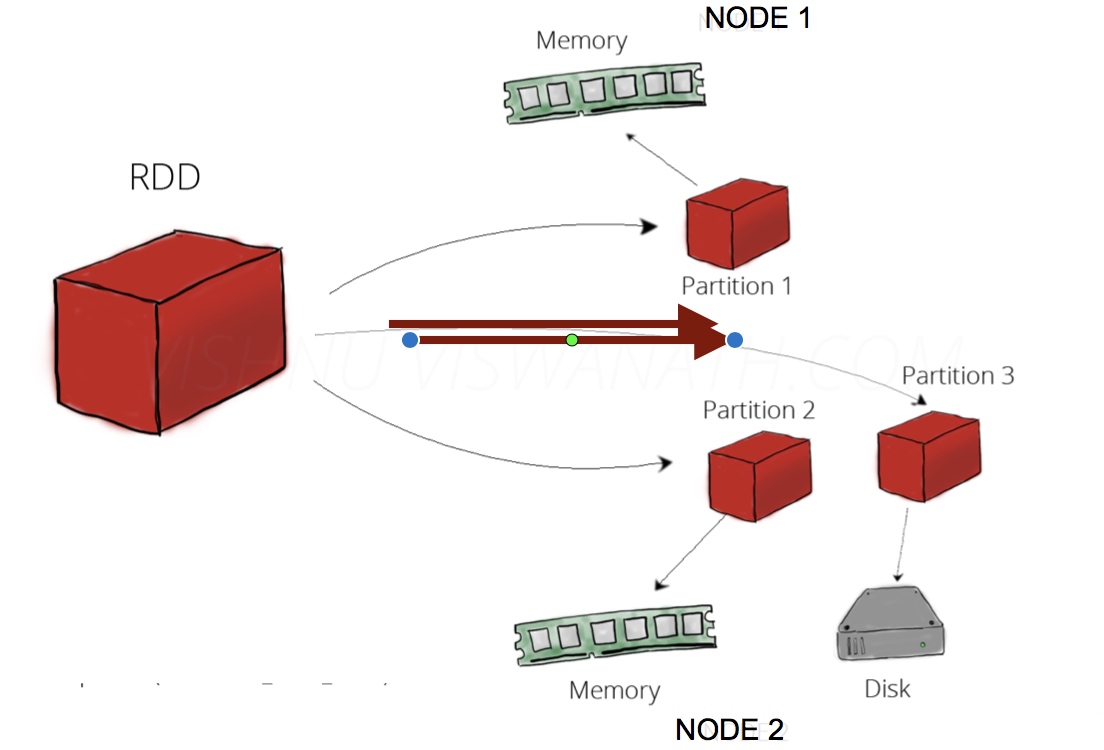 

RDD可以理解为一份数据在集群上的抽象, 被分为多个分区, 每个分区分布在集群不同的节点上(如上图), 从而让RDD中的数据可以被并行操作(分布式数据集).
RDD有一个重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition, 因为节点故障 导致数据丢了, 那么RDD会自动通过自己的数据来源重新计算该partition.
RDD的基本操作
RDD有两种基本操作:Transformation 和 Action
Transformation
- 通过Scala集合或者Hadoop数据集构造一个新的RDD
- 通过已有的RDD产生新的RDD(RDD不可修改)
比如:
构造数据集:
val rdd1 = SparkContext.textFile("hdfs://xxx")
val rdd2 = sc.parallelize( Array(1,2,3,4,5))
Transformation:
// map(输入一行,产出一行) val a = sc.parallelize(1 to 9, 3) val b = a.map(x => x*2) a.collect = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) b.collect = Array(2, 4, 6, 8, 10, 12, 14, 16, 18) //上述例子中把原RDD中每个元素都乘以2来产生一个新的RDD //filter(过滤条件) val c = a.filter(x => x>5) c.collect = Array(6, 7, 8, 9) //上述例子中过滤支取了a中>5的值 //flatMap(输入一行,产出多行) val d = a.flatMap(x=> Array(x, x*10)) d.collect = Array(1, 10, 2, 20, 3, 30, 4, 40, 5, 50, 6, 60, 7, 70, 8, 80, 9, 90) //上述例子中,把a中的一个元素变成了 a 和 a的10倍 2个元素.
Action
- 通过RDD计算得到一个或者一组值
比如:
//collect(把结果拿到driver端) //比如transformation中的collect用法 //count(计算行数) scala> a.count res5:Long = 9 //reduce(reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止) a.collect res6: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) a.reduce((x, y) => x + y) res7: Int = 45
小结
接口定义方式不同
- Transformation: RDD[x] -> RDD[y]
- Action: RDD[x] -> Z (Z不是一个RDD,可能是基本类型,数组等)
惰性执行(Lazy Exception)
- Transformation 只会记录RDD转换关系,并不会触发计算
- Action是出发程序分布式执行的算子
SparkRDD cache/persist
允许将RDD缓存到内存或者磁盘上,以便于重用
Spark提供了多种缓存级别,以便于用户根据实际需求进行调整
 

RDD cache的使用
val data = sc.textFile(“hdfs://nn:8020/input”) data.cache() //实际上是data.persist(StorageLevel.MEMORY_ONLY) //data.persist(StorageLevel.DISK_ONLY_2)
原文链接: