①验证码处理: 现在许多网站需要登录,在这过程中很多会有验证码,有些简单的数字验证码可以直接通过二值化、灰度处理、降噪,最后直接用python的一些模块如: tessertocr进行识别.复杂一点的验证码,如:极验验证、12306等操作起来相对复杂,有的更需要借助机器学习来完成识别,这里就不详述;
②动态加载:有些网站为了提升用户体验,整个页面采用动态加载来实现,这里可以通过selenium来模拟浏览器运行,加载完需要的内容后再获取网页源码,从而达到采集的目的;
③JS加密:有些网站在前端显示数据前所有的信息都是通过加密处理的,所以如果我们想要获取到数据,就必须对这些加密数据进行解密,通常开发者会用js来实现,而我们要做的就是找到这段js加密解密代码,破解其加密方式或直接将获取的加密数据传入这段代码中解密;
④字体文件映射:经常留意网页源码的人可能会发现,有些网站在源码中显示的数据和浏览器渲染后的数据不同,甚至有些源码中的内容是乱码,下图是为我们公司网站做的反爬:
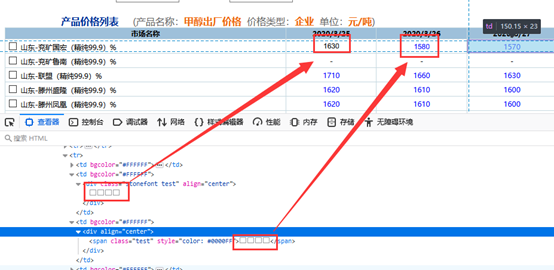
如果是这样,爬虫获取的数据就是错误的或者直接获取乱码.其实是开发者修改了字体文件中的映射关系,这种情况在处理的时候不仅要获取源码,还要获取返回的字体文件,通过分析文件中字体的对应关系再进行转换才能得到想要的结果.