一 聚焦爬虫数据解析
1.1 基本介绍
聚焦爬虫的编码流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据
- 数据解析
- 进行持久化存储
如何实现数据解析
三种数据解析方式
- 正则表达式
- bs4
- xpath
数据解析的原理
- 进行标签定位
- 获取定位好的标签里面的文本数据和属性值1.2 爬取一个网站的图片

import requests
# 1. 指定url
url = "http://mpic.spriteapp.cn/ugc/2019/09/01/5d6be8e4396c4.gif"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
# 2. 基于requests模块发起请求
# 3. 获取响应对象中的数据
page_content = requests.get(url=url, headers=headers).content
# 4. 进行持久化存储
with open('./火狐突击.gif', 'wb') as f:
f.write(page_content)
执行

就有图片文件保存
上面的功能可以使用urlib实现
#引入urllib的request的模块 from urllib import request #指定url url = "http://mpic.spriteapp.cn/ugc/2019/09/01/5d6be8e4396c4.gif" #需要两个参数,一个是url.另一个是保存的文件名 request.urlretrieve(url=url,filename="./火狐突击_urllib.gif")
执行后出现
('./火狐突击_urllib.gif', <http.client.HTTPMessage at 0x7f41eabbb160>)
查看目录

使用urllib模块下载图片,代码量比较少
有一个缺点,如果有些网站有UA检测机制的话,此方法就不适用
1.3 聚焦爬虫
爬取不得姐的所有图片
其中一张图片信息如下

提取上面内容,使用正则匹配出元数据部分
html ="""<div class="j-r-list-c-img">
<a href="/detail-30930266.html">
<img src="http://mstatic.spriteapp.cn/xx/1/w3/img/lazyload/default.png" class="lazy" data-original="http://mpic.spriteapp.cn/ugc/2020/04/04/5e887902d0f98.gif" title="我抱得动你吗?" alt="我抱得动你吗?">
</a>
</div>
"""
#ex = '<div class="j-r-list-c-img">.*?</div>'
#匹配的内容:
"""<a href="/detail-30930266.html">
<img src="http://mstatic.spriteapp.cn/xx/1/w3/img/lazyload/default.png" class="lazy" data-original="http://mpic.spriteapp.cn/ugc/2020/04/04/5e887902d0f98.gif" title="我抱得动你吗?" alt="我抱得动你吗?">
</a>
"""
#ex = '<div class="j-r-list-c-img">.*?data-original="" title=".*?</div>'
#匹配的内容:
"""
第一个.*? <a href="/detail-30930266.html">
<img src="http://mstatic.spriteapp.cn/xx/1/w3/img/lazyload/default.png" class="lazy"
第二个.*? 抱得动你吗?" alt="我抱得动你吗?">
</a>
"""
import re
# re.S表示单行匹配,可以将字符串中的多行拼接起来,进行统一匹配,如果不加,则会一行一行地进行匹配,最后得到的结果是[]
ex = '<div class="j-r-list-c-img">.*?data-original="(.*?)" title=".*?</div>'
#获取的是一个列表后加上[0]就可以得到值
image_url = re.findall(ex,html,re.S)
print(image_url[0])
执行
http://mpic.spriteapp.cn/ugc/2020/04/04/5e887902d0f98.gif
完整代码
获取所有图片代码如下
# 爬取不得姐网站上面的所有图片
import os
import re
import requests
from urllib import request
# 1. 指定url
url = "http://www.budejie.com/pic/"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
ex = '<div class="j-r-list-c-img">.*?data-original="(.*?)" title=".*?</div>'
# 判断是否有images文件存在,如果不存在,就创建一个新的,用来存储图片,使用OS模块
if not os.path.exists('./images'):
os.mkdir('./images')
# 2. 基于requests模块发起请求
# 3. 获取响应对象中的数据
page_text = requests.get(url=url, headers=headers).text
# 4. 数据解析
img_url_list = re.findall(ex, page_text, re.S)
# 5. 进行持久化存储
for img_url in img_url_list:
#获取到图片的url之后,可以对这个如来进行切割,得到图片的名称,并进行存储,同时由于还有一层目录,就可以吧images拼接到字符串中
img_name = './images/' + img_url.split('/')[-1]
# 获取到图片的url之后,接下来进行图片的存储
request.urlretrieve(url=img_url, filename=img_name)
执行,就可以得到images目录,同时存有下载的图片

二 bs4数据解析
2.1 基本使用
环境安装:
它是一个解析器,如果使用bs4进行数据解析,需要依靠lxml
root@darren-virtual-machine:~# pip3 install bs4
root@darren-virtual-machine:~# pip3 install lxml
导入bs4模块
from bs4 import BeautifulSoup
BeautifulSoup解析原理:
实例化一个BeautifulSoup对象,并将需要解析的页面源码数据加载到对象中使用该对象的相关属性和方法进行数据解析或提取
如何实例化一个BeautifulSoup对象
本地加载
f = open()
soup = BeautifulSoup(f, "lxml")
网络加载
soup = BeautifulSoup(page_text, "lxml")
创建一个本地的测试html文件
root@darren-virtual-machine:~# cd /root/Python爬虫/
root@darren-virtual-machine:~/Python爬虫# vim test_page.html
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>测试bs4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com/" target="_self" title="赵匡胤">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
<a class="du" href="">总为浮云能蔽日,长安不见使人愁</a>
<img alt="" src="http://www.baidu.com/meinv.jpg"/>
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
<li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>
<li><a alt="qi" href="http://www.126.com">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
<li><a class="du" href="http://www.sina.com">杜甫</a></li>
<li><a class="du" href="http://www.dudu.com">杜牧</a></li>
<li><b>杜小月</b></li>
<li><i>度蜜月</i></li>
<li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
</ul>
</div>
</body>
</html>
实例化一个对象
from bs4 import BeautifulSoup
f = open('./test_page.html', 'r', encoding='utf-8')
soup = BeautifulSoup(f, 'lxml')
#这里直接使用,就是打印的意思
soup
执行后,就会输出html的所有信息
BeautifulSoup对象相关的属性和方法
soup.tagName 获取页面源码中遇到的第一个标签
取出一个P标签
soup.p
执行

取属性: 返回的永远是一个单数
soup.tagName.attrs 取得标签里面所有的属性(返回的是一个字典)soup.tagName.attrs[属性名] 取标签的单个属性soup.tagName[属性名] 取标签的单个属性

取其中一个
soup.a.attrs["title"] #也可以直接soup.a["title"]
![]()
取文本:
soup.string: 只可以获取直系标签中的文本内容soup.text: 获取标签下的所有文本内容soup.get_text(): 获取标签下的所有文本内容
print(soup.p.string) print(soup.p.text) print(soup.p.get_text())
执行

find() 返回的永远是一个单数
find(tagName): 通过标签名进行数据解析
soup.find('a')
执行
<a href="http://www.song.com/" target="_self" title="赵匡胤">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
find(tagName, 标签属性): 通过标签属性进行标签定位
soup.find('div',class_ = "song")
执行

在使用class时,必须使用class_,后要加下划线,否则会有如下错误

string text 和get_text()区别

find_all() 返回的永远是一个列表
找到所有符合要求的标签
soup.find_all("a")
执行
[<a href="http://www.song.com/" target="_self" title="赵匡胤">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>,
<a class="du" href="">总为浮云能蔽日,长安不见使人愁</a>,
<a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a>,
<a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a>,
<a alt="qi" href="http://www.126.com">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a>,
<a class="du" href="http://www.sina.com">杜甫</a>,
<a class="du" href="http://www.dudu.com">杜牧</a>,
<a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a>]
也可以传入列表
soup.find_all(["a","p"])
就找到所有的a和p的标签
select 选择器 返回的永远是一个列表
标签选择器, 类选择器, ID选择器, 层级选择器
层级选择器:
单层级: soup.select(".tang > ul > li")
[<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>, <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>, <li><a alt="qi" href="http://www.126.com">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>, <li><a class="du" href="http://www.sina.com">杜甫</a></li>, <li><a class="du" href="http://www.dudu.com">杜牧</a></li>, <li><b>杜小月</b></li>, <li><i>度蜜月</i></li>, <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>]
多层级: soup.select(".tang li")
[<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>, <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>, <li><a alt="qi" href="http://www.126.com">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>, <li><a class="du" href="http://www.sina.com">杜甫</a></li>, <li><a class="du" href="http://www.dudu.com">杜牧</a></li>, <li><b>杜小月</b></li>, <li><i>度蜜月</i></li>, <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>]
2.2 实际案例
使用bs4实现将诗词名句网站中三国演义小说的每一章的内容爬取到本地磁盘进行存储
import requests
from bs4 import BeautifulSoup
# 1.指定URL(顺带加上UA伪装)
url = "http://www.shicimingju.com/book/sanguoyanyi.html"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
# 2.使用requests发起请求
response = requests.get(url=url, headers=headers)
# 3.获取响应数据
# 获取到的是标题页的页面源码数据
page_text = response.text
# 4.数据解析
# 实例化一个BeautifulSoup对象
soup = BeautifulSoup(page_text, 'lxml')
# 使用该对象的相关属性和方法进行数据解析和文本的提取,下面就是文章的标题
li_list = soup.select('.book-mulu li')
f = open('./sanguo.txt', 'w', encoding='utf-8')
#循环比标题
for li in li_list:
#取出标题的文本
name = li.a.text
#把取到的a标签和域名拼接
detail_url = "http://www.shicimingju.com" + li.a["href"]
# 获取到的是详情页的页面源码数据
detail_page_text = requests.get(url=detail_url, headers=headers).text
# 这是因为前面获取了源码,还要重新实例化一次,我们需要重新实例化一个详情页的BeautifulSoup对象,再进行数据解析
detail_soup = BeautifulSoup(detail_page_text, "lxml")
content = detail_soup.find('div', class_="chapter_content").get_text()
# 5.持久化存储
f.write(name + ":" + content + "
")
f.close()
执行后查看
查看爬取内容

三 xpath解析
3.1 基本介绍
通用性比较强
环境的安装: pip install lxml
解析原理:
- 实例化一个etree对象,且将解析的页面源码加载到该对象中
- 使用该对象中的xpath方法结合着xpath表达式进行标签定位和数据解析提取
etree对象的实例化:
- 本地加载: tree = etree.parse("filePath")
- 网络加载: tree = etree.HTML(page_text)
3.2 基本使用
from lxml import etree
tree = etree.parse('./test_page.html')
tree
tree方式打印出的是一个对象

常用的xpath表达式: 基于标签的层级实现定位,返回的永远是一个列表
/: 从标签开始实现层级定位
//: 从任意位置实现标签的定位
tree.xpath('//div')
执行

属性定位: tag[@attrName="attrValue"]
tree.xpath('//div[@class="song"]')
执行

索引定位: //div[@class="tang"]/ul/li[5] 注意索引值是从1开始
tree.xpath('//div[@class="song"]/img')
执行

获取的是列表
tree.xpath('//div[@class="song"]/img/@src')

取文本:
取直系文本内容: /text()
取所有文本内容: //text()
取属性: /@attrName
#列表直接使用[]就可以提取文本
tree.xpath('//div[@class="song"]/img/@src')[0]

取class="tang"下面的杜小月文本
# 需求1: 取class="tang"下面的杜小月文本
tree.xpath('//div[@class="tang"]/ul/li[6]/b/text()')[0]
执行 这里的索引是从1开始的


取"总为浮云能"这一段话
# 需求2: 取"总为浮云能"这一段话
tree.xpath('//div[@class="song"]/a[2]/text()')[0]
执行结果

# 需求3: 取“http://www.haha.com”这个域名
# 需求3: 取“http://www.haha.com”这个域名
tree.xpath('//a[@id="feng"]/@href')[0
执行

3.3 实例1:爬取58二手房上面的房源信息
(标题,价格,和概况)
新获取三个数据的标题 详情页url 和价格
import requests
from lxml import etree
#这个url是58的主页信息
url = "https://sz.58.com/ershoufang/?PGTID=0d100000-0000-43a0-55c0-fbb7aead05c1&ClickID=2"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
# 向二手房列表页发送请求,获取页面源码数据
page_text = requests.get(url=url, headers=headers).text
# 使用xpath进行数据解析,这里是网络加载,需要使用HTML
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
all_data_list = list()
for li in li_list[0:3]:
#获取的标题
title = li.xpath('./div[2]/h2/a/text()')[0]
#获取详情页url,可以根据这个url请求,获取
detail_url = li.xpath('./div[2]/h2/a/@href')[0]
#获取价格
price = li.xpath('./div[3]//text()')
print(title)
print(detail_url)
print(price)
执行结果

详情页的概况定位
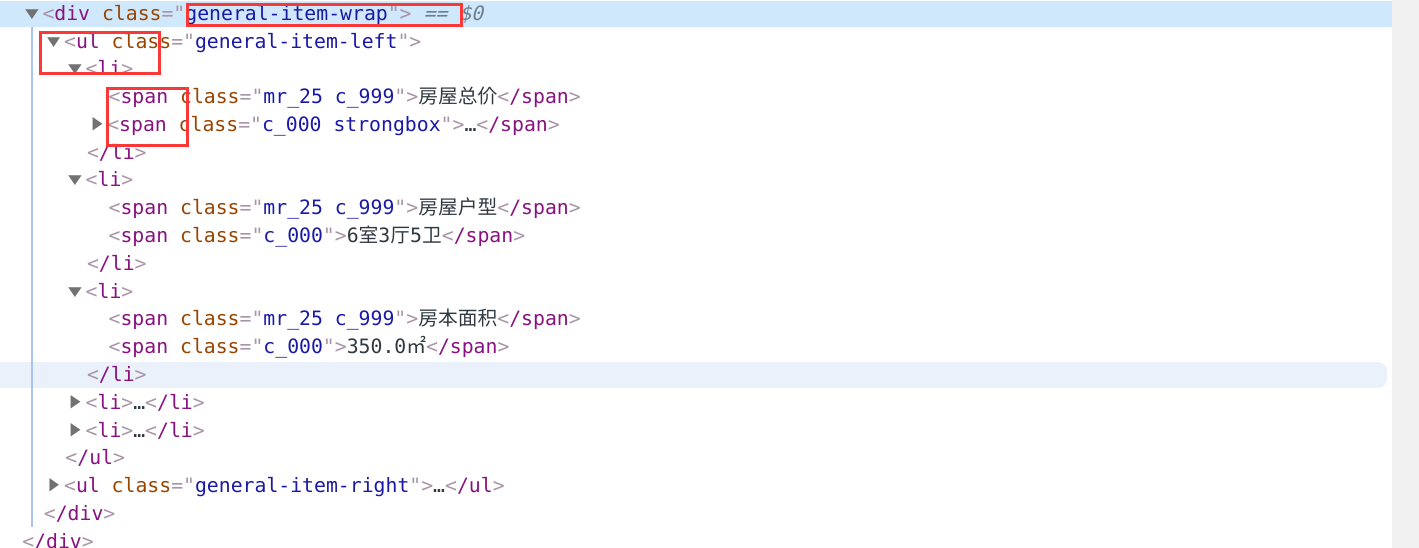
代码如下
import requests
from lxml import etree
#这个url是58的主页信息
url = "https://sz.58.com/ershoufang/?PGTID=0d100000-0000-43a0-55c0-fbb7aead05c1&ClickID=2"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
# 向二手房列表页发送请求,获取页面源码数据
page_text = requests.get(url=url, headers=headers).text
# 使用xpath进行数据解析,这里是网络加载,需要使用HTML
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
all_data_list = list()
for li in li_list[0:2]:
#获取的标题
title = li.xpath('./div[2]/h2/a/text()')[0]
#获取详情页url,可以根据这个url请求,获取
detail_url = li.xpath('./div[2]/h2/a/@href')[0]
#获取价格
price = li.xpath('./div[3]//text()')
detail_page_text = requests.get(url=detail_url, headers=headers).text
detail_tree = etree.HTML(detail_page_text)
detail_content = detail_tree.xpath('//div[@class="general-item-wrap"]/ul/li/span//text()')
#把数据封装到一个字典里面
dic = {
"title": title,
"price": price,
"detail_content": detail_content
}
#把字典的数据放入列表
all_data_list.append(dic)
print(all_data_list)
打印结果
[{
'title': '光明7栋小区花园|带精装修分期1年免息|长圳地铁xa0',
'price': ['
', '126', '万', '
', '18261元/㎡', '
'],
'detail_content': ['房屋总价', '
龒驋鸺万(单价龒龥驋鸺龒元/㎡)
', '房屋户型', '2室2厅1卫', '房本面积', '69.0㎡', '房屋朝向', '南', '一手房源', ' 否 ', '所在楼层', '低层(共25层)', '装修情况', '精装修', '
', '
', '找装修
', '
', '产权年限', '70年产权', '建筑年代', '2015年', '房屋总价', '
龒驋鸺万(单价龒龥驋鸺龒元/㎡)
', '
', '帮你凑钱
', '
', '房屋类型', '普通住宅', '交易权属', '经济适用房', '是否唯一', ' 否 ', '参考首付', '
37.8万(月供3617元/月)
']
}, {
'title': '满二唯一 红本在手 看房方便 周边配套丰富xa0',
'price': ['
', '300', '万', '
', '33926元/㎡', '
'],
'detail_content': ['房屋总价', '
麣龤龤万(单价麣麣齤驋鸺元/㎡)
', '房屋户型', '3室2厅1卫', '房本面积', '88.43㎡', '房屋朝向', '南北', '一手房源', ' 否 ', '所在楼层', '中层(共32层)', '装修情况', '精装修', '
', '
', '找装修
', '
', '产权年限', '70年产权', '建筑年代', '2015年', '房屋总价', '
麣龤龤万(单价麣麣齤驋鸺元/㎡)
', '
', '帮你凑钱
', '
', '房屋类型', '普通住宅', '交易权属', '商品房', '是否唯一', ' 是 ', '参考首付', '
90.0万(月供8611元/月)
乱码问题,请参考老男孩好教育老师文章:https://www.cnblogs.com/tiger666/articles/11414949.html
3.4 案例二:解析出所有城市名称
import requests
from lxml import etree
url = "https://www.aqistudy.cn/historydata/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
# 使用requests模块发送请求获取页面源码数据
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
#使用管道符号,可以取到热门城市和城市信息
city_list = tree.xpath('//div[@class="bottom"]/ul/li/a/text() | //div[@class="bottom"]/ul/div[2]/li/a/text()')
print(city_list)
执行
 执行结果
执行结果3.5 解析图片数据(中文乱码问题)
# url:http://pic.netbian.com/4kmeinv/
import requests
from lxml import etree
url = "http://pic.netbian.com/4kqiche/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
response = requests.get(url=url, headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@class="clearfix"]/li')
for li in li_list:
title = li.xpath('./a/b/text()')[0]
# 使用ISO-8859-1这种通用编码方式可以处理大部分中文乱码的情况
title = title.encode('ISO-8859-1').decode('gbk')
detail_url = "http://pic.netbian.com" + li.xpath('./a/@href')[0]
print(title, detail_url)
执行
《Karma SC1 Vision Con http://pic.netbian.com/tupian/24859.html 2019 Ford GT MK II 福特 http://pic.netbian.com/tupian/24849.html 福特ford gt mk ii 4k跑 http://pic.netbian.com/tupian/24831.html 法拉利ferrari 488 pist http://pic.netbian.com/tupian/24830.html 奥迪audi r8 lms gt2 赛 http://pic.netbian.com/tupian/24829.html 2019年法拉利Portofino跑 http://pic.netbian.com/tupian/23939.html 2019年劳斯莱斯幽灵黑徽 http://pic.netbian.com/tupian/23824.html 2019 McLaren Senna GTR http://pic.netbian.com/tupian/23823.html 2019年劳斯莱斯幽灵黑徽 http://pic.netbian.com/tupian/23822.html 迈凯伦McLaren 600LT Sp http://pic.netbian.com/tupian/23695.html 白色劳斯莱斯5k图片 http://pic.netbian.com/tupian/23654.html 《迈凯伦720S GT3》4k壁 http://pic.netbian.com/tupian/23426.html 兰博基尼Lamborghini Ur http://pic.netbian.com/tupian/23017.html 保时捷Porsche 911 Carr http://pic.netbian.com/tupian/23016.html 兰博基尼LP580橙色跑车4 http://pic.netbian.com/tupian/22673.html 奔驰银箭Mercedes-Benz http://pic.netbian.com/tupian/22109.html 劳斯莱斯幻影Rolls-Royc http://pic.netbian.com/tupian/22107.html McLaren 720S GT3 迈凯伦 http://pic.netbian.com/tupian/22041.html 迈凯伦McLaren 720S GT3 http://pic.netbian.com/tupian/22040.html Mercedes-Benz Vision E http://pic.netbian.com/tupian/22039.html 迈凯伦720S白色跑车3440 http://pic.netbian.com/tupian/22036.html
参考:老男孩教育:https://www.oldboyedu.com/