1.spark内核架构常用术语
Application:基于spark程序,包含一个driver program(客户端程序)和多个executeor(线程)
Driver Progrom:代表着sparkcontext
executeor:某个Application运行在worker node上的一个进程,该进程负责运行Task,并且将数据存储到内存或者磁盘上,每个Application都有各自独立的executeor。
worker node:集群中任何可以运行Application代码的节点。
Task:被传送到某个executeor的工作单元。
Cluster Manager:在集群上获取外部服务(例如:StandaloneYearMesos)
job:包含多个Task组成的并行计算,往往有spark的action催生
stage:每个job会被拆分很多组task任务,每组任务被称为stage,也称为TaskSet
RDD:Spark的基本计算单元,可以通过一系列算子进行操作(主要有Transformation和Action)
DAG Scheduler:根据job构建基于Stage的DAG,并提交Stage给Task Scheduler
Task Scheduler:将Taskset提交给worker(集群)运行并回报结果
2.创建SparkContext
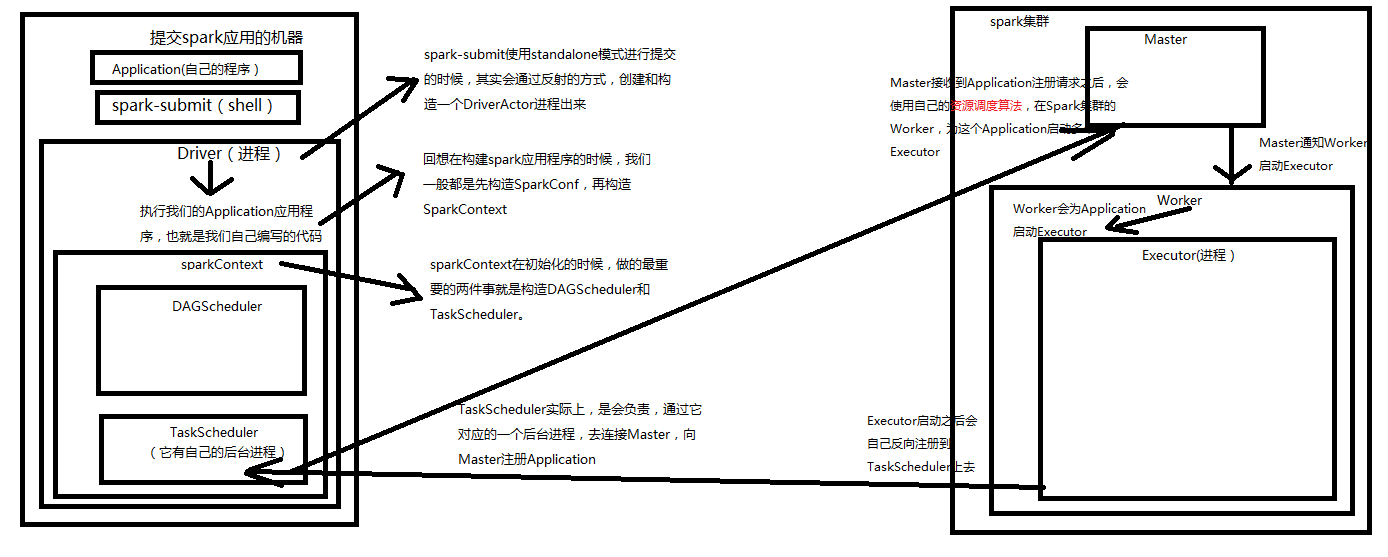
1.1 在shell下,spark-submit使用standalone模式提交的时候,其实会通过反射的方式,创建和构造一个Driveractor(和java的actor进程差不多)
1.2 Driver进程在执行我们提交的Application代码的时候,会先构建SparkConf,再构建SparkContext.
1.3 SparkContext在初始化的时候,做的最重要的事情,就是构造DAG Scheduler和Task Scheduler
1.4 TaskScheduler实际上,是会负责与它对应的一个后台进程,去连接Spark集群的Master并注册Application
1.5 Master接收到Application的注册请求后,会使用自己的资源调度算法(基于调度器standalone、Yarn、Mesos等都有不同的调度算法),在Spark集群的Worker上会为i这个Application启动Executor
1.6 Master通知Worker启动Executor后,Worker会为Application启动Executor进程
1.7 Executer启动后,首先做的就是会将自己反向注册给Task Scheduler上去,到此为止SparkContext完成了初始化
3.运行Application
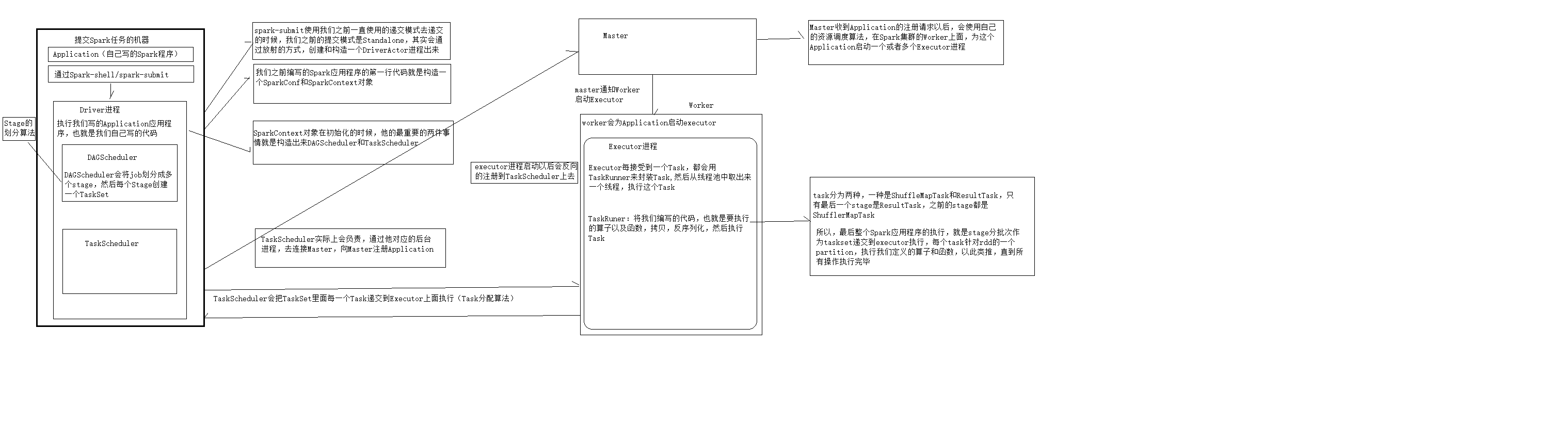
2.1 所有的Executer都会反向注册给Driver programe,Driver Programe当结束SparkContextc初始化后,会继续只想我们编写的代码哦
2.2 每执行一个Action就会创建一个job,job会提交给DAG Scheduler
2.3 DAG Scheduler会采用自己的stage划分算法将job划分为多个stage,然后每个stage会创建一个TaskSet
2.4 DAG Scheduler会将TaskSet传递给Task Scheduler,Task Scheduler会把TaskSet里的每一个Task提交到Worker上的Executer上执行
2.5 Executor每接收一个task都会用TaskRunner来封装task,然后从线程池里面取出一个线程,执行这个task,TaskRunner将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行Task。
2.6 Task有两种,ShuffleMapTsk和ResultTask。只有最后一个stage是ResultTask,之前的stage,都是ShuffleMapTask.
2.7所以,最后整个应用程序的执行,就是将stage分批次作为taskSet提交给executeor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数,为此类推,知道所有的操作完成为止。