spark围绕弹性分布式数据集(RDD)的概念展开的,RDD是一个可以并行操作的容错集合。
创建RDD的方法:
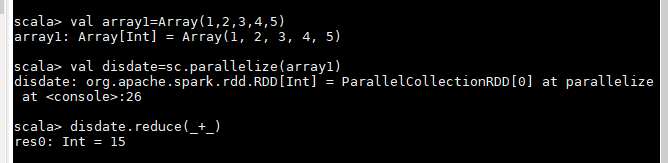
1.并行化集合(并行化驱动程序中现有的集合)
调用SparkContext的parallelize收集方法
2.外部数据集操作(引用外部系统存储的数据集)
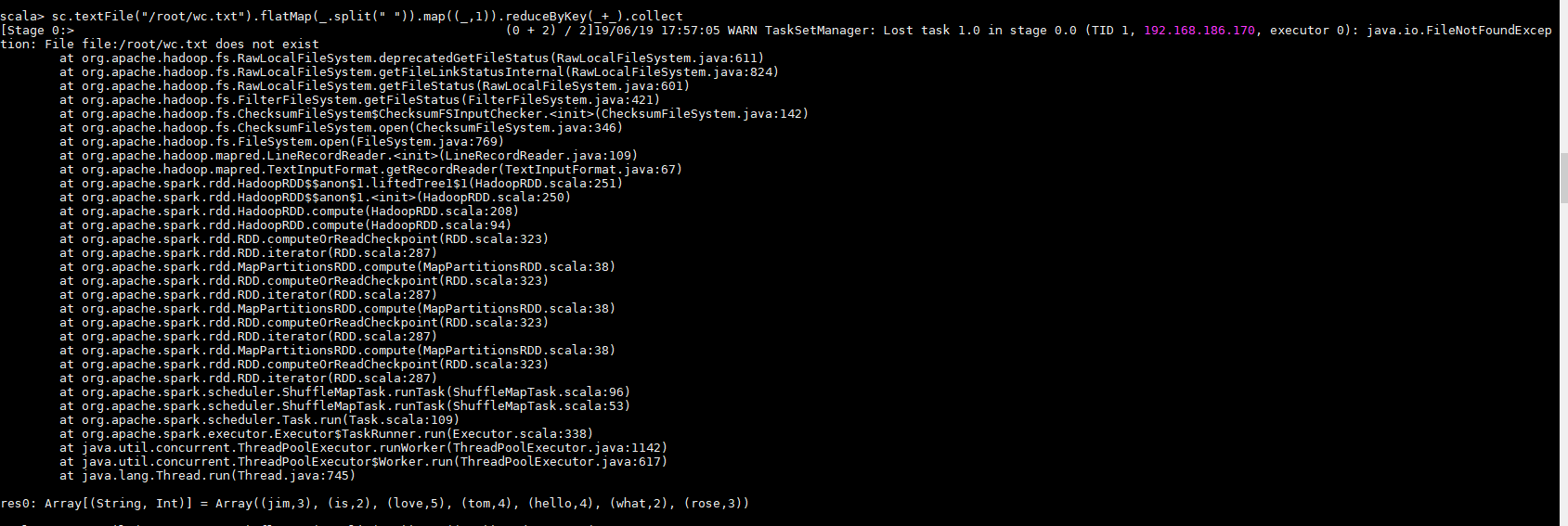
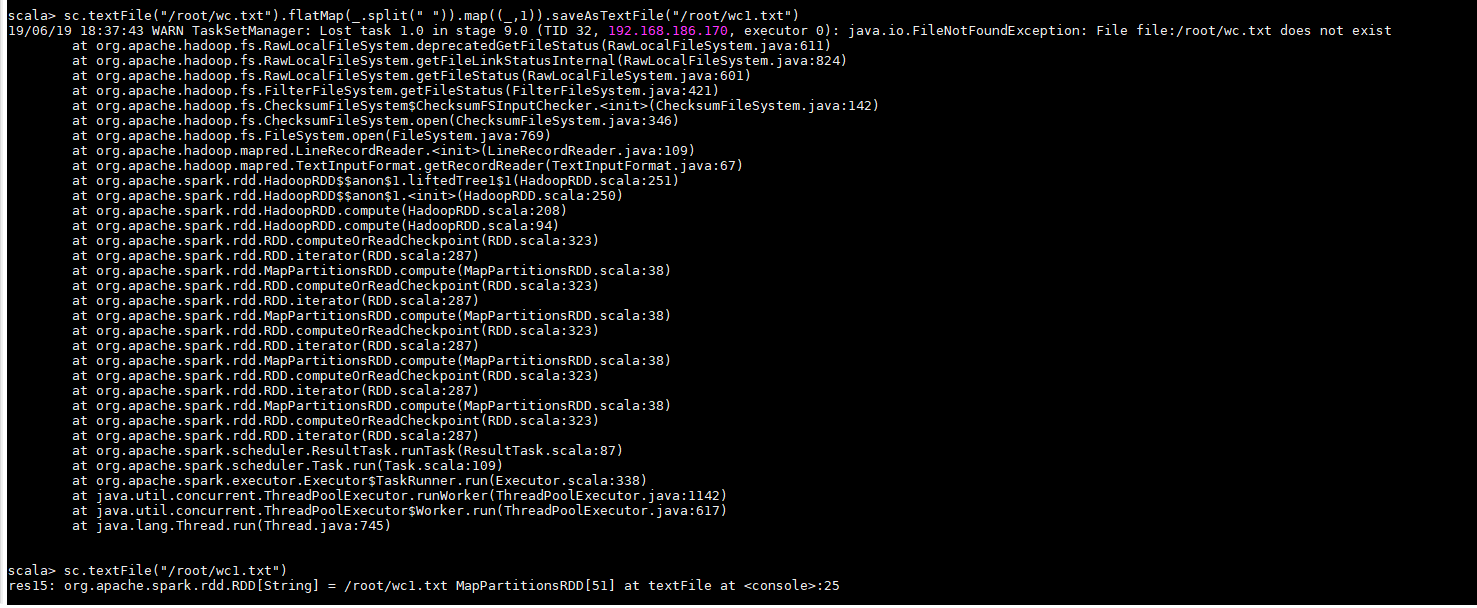
RDD操作
1.Transformations
是从将一个以有的RDD生成另外一个RDD.Transformation具有延迟加载的特性(lazy特性),Transformation算子的代码不会真正的被执行,只有当我们的程序中遇到一个action的算子的时候,代码才会真正的被执行。这种涉及模式,提高了spark的运行效率。
常用:
map
filter(过滤)

