抛出问题:为什么前面的线性回归要用最小二乘法?为什么要用这样的指标?
下面我们会给出一系列的概率假设,从而导出最小二乘法是一个很自然的算法:
先设 y^(i) = θTx^(i) + ε(i), 其中ε(i)叫做误差项 error term,这个可以看作是对未建模的效应的捕获,简单的说就是没有考虑到的特征,像预测房子中的这个房子有没有花园,房子的噪音多不多什么的,这些特征我们没有考虑到,但它对预测结果又确实有影响。
又假设这个ε(i)服从某个概率分布 ε(i)~N(0,σ^2),——即它服从正态分布,均值为0,方差为σ^2
于是根据正正态分布的概率密度函数就有: 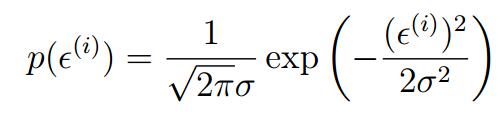
将现行回归方程代入我们可以得到(因为这个误差值是服从正态分布的,所以房屋的价格也服从正态分布,所以它的概率密度函数也是):
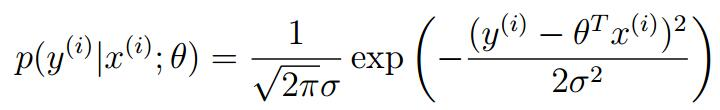
也即:
y(i) | x(i);θ ∼N(θTx^(i),σ^2)
这个表示这是给一个x^(i)以θ为参数的y^(i)的分布。注意θ不能当作条件,因为它不是个随机变量,它是个参数。
又假设这个error terms ,误差项之间是彼此独立的
现在定义一个θ参数的函数,似然函数L(θ) (likehood function)
L(θ) = L(θ;X,~y) = p(~y|X;θ),因为那个误差项的独立分布,我们可以把它写成:
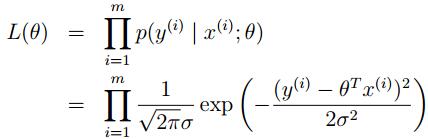 即高斯密度函数的乘积
即高斯密度函数的乘积
L(θ)似然性和概率其实差不多,只是L(θ)强调是个关于θ的函数,所以要注意这个语句的正确,是参数的似然性和数据的概率。
接下来就是选择θ的问题了,现在我们要做的是maximize L(θ),即选择θ使数据出现的可能性尽可能大
为了数学上的便利,现在又定义 ℓ(θ):
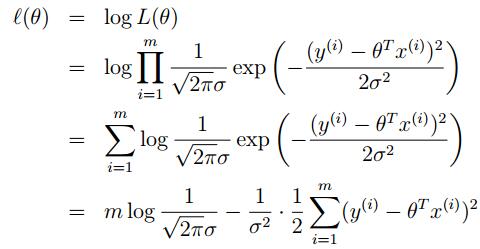
此时,要maxmize 这个L(θ)也就是要minimizing这个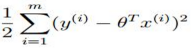 最小,看着玩意是不是很眼熟!!这就是我们之前的线性回归函数J(θ)!
最小,看着玩意是不是很眼熟!!这就是我们之前的线性回归函数J(θ)!
其实讲了这么多就是为了证明之前的那个普通最小二乘法的目的实际上是假设误差项满足高斯分布且独立分布的情况下。