一。c++在内存区域的分配图
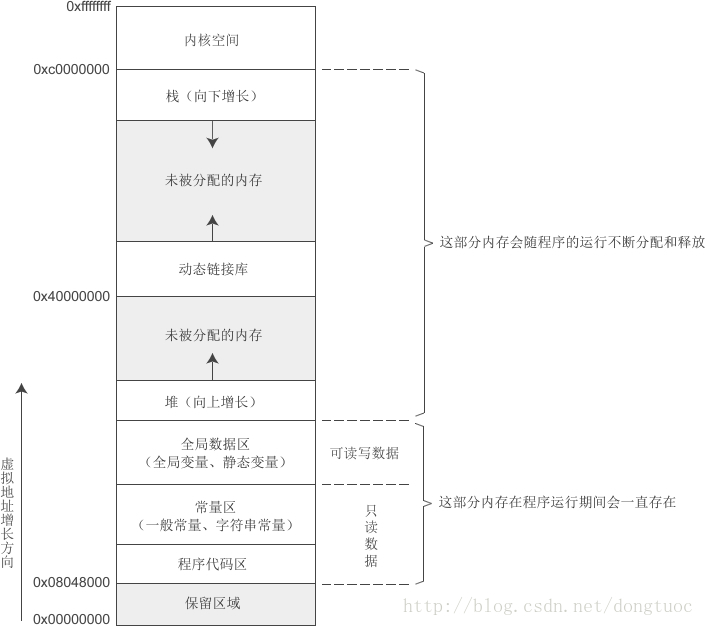
可以看出,对于Linux系统下的,存储空间的分配有着较为层次清晰的分层。单片机大概也遵循这个分区架构。
二进制代码以及常量(CONST修饰)以及全局变量在最底层,存储空间最靠前的部分
然后是堆区,堆区向上增长,我们常用到的molloc()、free()等函数操作的就是这个区,这也是芯片系统中唯一可以让程序员通过代码操作的一片存储空间
再然后是动态链接库
在往上(高地址)便是栈区。 最高地址一般为操作系统内核,用户无法访问
二。什么是栈,栈溢出是什么怎么解决
在计算机中,栈可以理解为一个特殊的容器,用户可以将数据依次放入栈中,然后再将数据按照相反的顺序从栈中取出。也就是说,先放入的数据最后才能取出,而最后放入的数据必须先取出。这称为先进后出(First In Last Out)原则。
放入数据常称为入栈或压栈(Push),取出数据常称为出栈或弹出(Pop)。
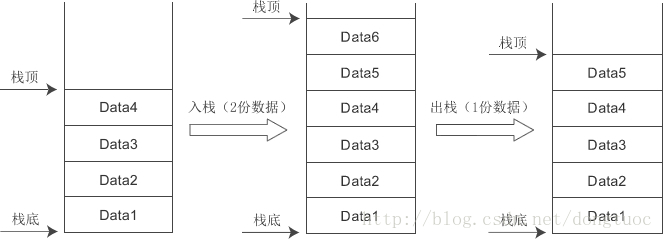
可以发现,栈底始终不动,出栈入栈只是在移动栈顶,当栈中没有数据时,栈顶和栈底重合。
这里需要注意标识栈顶和栈底的两个寄存器: ebp寄存器指向栈底,esp寄存器指向栈顶。从本质上来讲,栈是一段连续的内存,需要同时记录栈底和栈顶,才能对当前的栈进行定位。
栈溢出是怎么回事
了解了栈实际上也是一块内存后,栈溢出就好理解了。
因为栈一般默认为1-2m,一旦出现死循环或者是大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。
当我们定义的数据所需要占用的内存超过了栈的大小时,就会发生栈溢出。编译器会报栈溢出错误。
如一块芯片的内存RAM大小为4k,当我们定义了一个大数组,如下:
int buf[1024*5] = {0};- 1
很明显定义的数组超过了内存大小,这就导致了栈溢出。
解决方案:
方法一:用栈把递归转换成非递归
通常,一个函数在调用另一个函数之前,要作如下的事情:a)将实在参数,返回地址等信息传递给被调用函数保存; b)为被调用函数的局部变量分配存储区;c)将控制转移到被调函数的入口. 从被调用函数返回调用函数之前,也要做三件事情:a)保存被调函数的计算结果;b)释放被调函数的数据区;c)依照被调函数保存的返回地址将控制转移到调用函数.所有的这些,不论是变量还是地址,本质上来说都是"数据",都是保存在系统所分配的栈中的. 那么自己就可以写一个栈来存储必要的数据,以减少系统负担。
方法二:使用static对象替代nonstatic局部对象
在递归函数设计中,可以使用static对象替代nonstatic局部对象(即栈对象),这不仅可以减少每次递归调用和返回时产生和释放nonstatic对象的开销,而且static对象还可以保存递归调用的中间状态,并且可为各个调用层所访问。由上图可知全局变量区内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在
方法三:增大堆栈大小值
当创建一个线程的堆栈时,系统将会保留一个链接程序的/STACK开关指明的地址空间区域。但是,当调用CreateThread或_beginthreadex函数时,可以重载原先提交的内存数量。这两个函数都有一个参数,可以用来重载原先提交给堆栈的地址空间的内存数量。如果设定这个参数为0,那么系统将使用/STACK开关指明的已提交的堆栈大小值。后面将假定我们使用默认的堆栈大小值,即1MB的保留区域,每次提交一个页面的内存。
函数调用栈
定义的数组会占用栈空间,同样,定义的函数也会占用栈空间,一个简单的例子便是函数的入栈和出栈。
举个例子:
void func(int a, int b)
{
int p =12, q = 345;
}
int main()
{
func(90, 26);
return 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
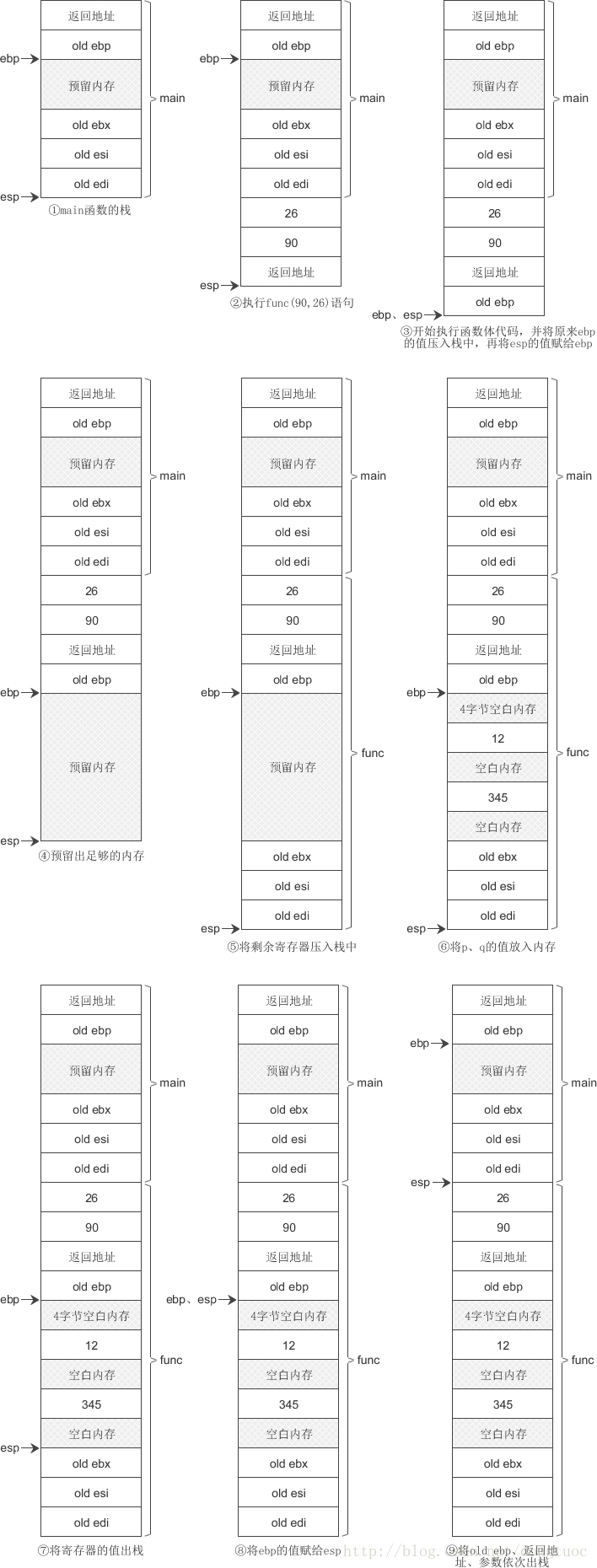
函数的进栈出栈过程如下图所示:
函数进栈
1) main() 是主函数,也需要进栈,如步骤①所示。
2) 在步骤②中,执行语句func(90, 26);,先将实参 90、26 压入栈中,再将返回地址压入栈中,这些工作都由 main() 函数(调用方)完成。这个时候 ebp 的值并没有变,仅仅是改变 esp 的指向。
3) 到了步骤③,就开始执行 func() 的函数体了。首先将原来 ebp 寄存器的值压入栈中(也即图中的 old ebp),并将 esp 的值赋给 ebp,这样 ebp 就从 main() 函数的栈底指向了 func() 函数的栈底,完成了函数栈的切换。由于此时 esp 和ebp 的值相等,所以它们也就指向了同一个位置。
4) 为局部变量、返回值等预留足够的内存,如步骤④所示。由于栈内存在函数调用之前就已经分配好了,所以这里并不是真的分配内存,而是将 esp 的值减去一个整数,例如 esp - 0XC0,就是预留 0XC0 字节的内存。
5) 将 ebp、esi、edi 寄存器的值依次压入栈中。
6) 将局部变量的值放入预留好的内存中。
至此,func() 函数的活动记录就构造完成了。可以发现,在函数的实际调用过程中,形参是不存在的,不会占用内存空间,内存中只有实参,而且是在执行函数体代码之前、由调用方压入栈中的。
未初始化的局部变量的值为什么是垃圾值
为局部变量分配内存时,仅仅是将 esp 的值减去一个整数,预留出足够的空白内存,不同的编译器在不同的模式下会对这片空白内存进行不同的处理,可能会初始化为一个固定的值,也可能不进行初始化。
函数出栈
步骤⑦到⑨是函数 func() 出栈过程:
7) 函数 func() 执行完成后开始出栈,首先将 edi、esi、ebx 寄存器的值出栈。
8) 将局部变量、返回值等数据出栈时,直接将 ebp 的值赋给 esp,这样 ebp 和 esp 就指向了同一个位置。
9) 接下来将 old ebp 出栈,并赋值给现在的 ebp,此时 ebp 就指向了 func() 调用之前的位置,即 main() 活动记录的 old ebp 位置,如步骤⑨所示。
这一步很关键,保证了还原到函数调用之前的情况,这也是每次调用函数时都必须将 old ebp 压入栈中的原因。
最后根据返回地址找到下一条指令的位置,并将返回地址和实参都出栈,此时 esp 就指向了 main() 活动记录的栈顶, 这意味着 func() 完全出栈了,栈被还原到了 func() 被调用之前的情况。
函数执行完局部变量的值真的不存在了?
经过上面的分析可以发现,函数出栈只是在增加 esp 寄存器的值,使它指向上一个数据,并没有销毁之前的数据。
栈上的数据只有在后续函数继续入栈时才能被覆盖掉,这就意味着,只要时机合适,在函数外部依然能够取得局部变量的值。请看下面的代码:
#include <stdio.h>
int *p;
void func(int m, int n)
{
int a = 18, b = 100;
p = &a;
}
int main()
{
int n;
func(10, 20);
n = *p;
printf("n = %d
", n);
return 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行结果:
n = 18
在 func() 中,将局部变量 a 的地址赋给 p,在 main() 函数中调用 func(),函数刚刚调用结束,还没有其他函数入栈,局部变量 a 所在的内存没有被覆盖掉,所以通过语句n = *p;能够取得它的值。