[论文阅读笔记] node2vec:Scalable Feature Learning for Networks
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
由于DeepWalk的随机游走是完全无指导的随机采样,即随机游走不可控。本文从该问题出发,设计了一种有偏向的随机游走策略,使得随机游走可以在DFS和BFS两种极端搜索方式中取得平衡。
(2) 主要贡献
Contribution: 本篇论文主要的创新点在于改进了随机游走的策略,定义了两个参数p和q,使得随机游走在BFS和DFS两种极端中达到一个平衡,同时考虑到局部和宏观的信息。
(3) 算法原理
node2vec算法框架主要包含两个部分:首先在图上做有偏向的随机游走,其次将得到的节点序列输入Skip-Gram模型学习节点表示向量嵌入(不再赘述,参考DeepWalk)。
有偏的随机游走策略:
其定义了两个参数p(向后参数)和q(向前参数),在广度优先搜索(BFS)和深度优先搜索(DFS)两种极端中达到一个平衡,从而同时考虑到局部和全局的结构信息。给定源点u,利用有偏随机游走生成长度为L的序列,随机游走的转移概率计算公式设计如下:
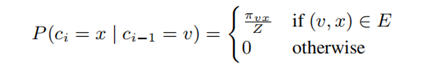
ci表示序列中的第i个点,c0=u,Z为一个归一化常数。分母πvx为v到x的非归一化的转移概率,如下所示(dtx为上一跳节点t与下一跳考虑跳转节点的距离):
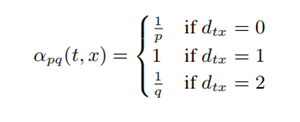
以一个例子来解释,如下图所示:

假设随机游走的上一跳节点是t,当前节点是v,则依据上述转移概率公式的设计下一跳节点怎么选择呢?下一跳节点可能是x1,x2,x3和t。由于x1与上一跳节点距离1跳,因此下一跳到节点x1的非归一化转移概率为1,而x2、x3与上一跳节点距离2跳,因此下一跳到x2和x3的非归一化转移概率均为1/q,此外t与上一跳节点距离0跳,因此下一跳到t的非归一化转移概率为1/p。以上便是Node2vec中设计的权衡BFS和DFS的随机游走策略。
通过以上方式生成同构网络上的随机游走序列之后,采用Skip-Gram模型训练节点向量即可。
(4) 参考文献
Grover A, Leskovec J. node2vec: Scalable feature learning for networks[A]. Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining[C]. 2016: 855–864.