首先看看我的项目结构:

从上面的结果图中,我们可以看出,主要用了两个库:itextsharp.dll 和 pdfbox-1.8.9.dll,dll文件夹存放引用的库,handles文件夹存放抽取的处理代码,lib文件夹中,相当于数据库中的DBHelp类的作用。model文件夹就不用介绍了,大家都知道。
我们从大的逻辑开始介绍,TitleHandle类中有一个方法:

从此方法可以看出,它接收两个参数:block和isTrainModel,返回 HandleResult类型。
我们先来看看Block的定义:

块由行构成,我们再看看Line的定义:

行由单词构成,再来看Word定义:
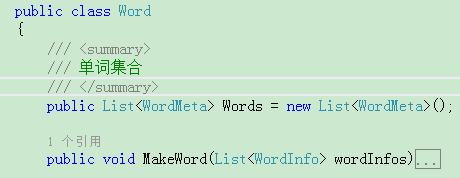
它其实是一个词的集合,WordMeta是一个单词的信息,它下面还有一层结构 WordInfo类,这个类是最基础的类,它代表了pdf文档中一个字符信息,底层基础决定上层建筑:
1 public class WordInfo 2 { 3 /// <summary> 4 /// x坐标 5 /// </summary> 6 public float X { set; get; } 7 /// <summary> 8 /// y坐标 9 /// </summary> 10 public float Y { set; get; } 11 12 public int XSize { set; get; } 13 14 public int YSize { get; set; } 15 16 public float XDirAdj { set; get; } 17 18 public float YDirAdj { set; get; } 19 20 /// <summary> 21 /// 字号 22 /// </summary> 23 public float FontSize { set; get; } 24 25 public float Xscale { set; get; } 26 27 public float Yscale { set; get; } 28 /// <summary> 29 /// 高度 30 /// </summary> 31 public float Height { set; get; } 32 33 /// <summary> 34 /// 空格大小 35 /// </summary> 36 public float Space { set; get; } 37 /// <summary> 38 /// 宽度 39 /// </summary> 40 public float Width { set; get; } 41 /// <summary> 42 /// 子字体 43 /// </summary> 44 public string Subfont { set; get; } 45 /// <summary> 46 /// 基本字体 47 /// </summary> 48 public string Basefont { set; get; } 49 /// <summary> 50 /// 是否加粗 51 /// </summary> 52 public bool IsBold { set; get; } 53 /// <summary> 54 /// 是否倾斜 55 /// </summary> 56 public bool IsItalic { set; get; } 57 /// <summary> 58 /// 单词 59 /// </summary> 60 public string Word { set; get; } 61 62 public override string ToString() 63 { 64 return "String[" + this.XDirAdj + "," 65 + this.YDirAdj 66 + " fs=" + this.FontSize 67 + " xscale=" + this.Xscale 68 + " isBold=" + this.IsBold 69 + " space=" + this.Space 70 + " isItalic=" + this.IsItalic 71 + "xSize" + this.XSize 72 + "ySize" + this.YSize 73 + " width=" + this.Width + "]" 74 + this.Word; 75 } 76 /// <summary> 77 /// 计算当前字符和lastChunk的距离 78 /// </summary> 79 /// <param name="lastChunk"></param> 80 /// <returns></returns> 81 public float DistanceFromEndOf(WordInfo lastChunk) 82 { 83 return this.X - lastChunk.X - lastChunk.Width; 84 } 85 86 87 }
这个类包括了字符的位置,大小,粗细等等信息。这些信息是基础当中的基础,因此非常重要,给我们判断一个块是否是标题,提供了依据,相当于国之宪法。
从我解剖出来的结构看,解析出pdf标题,关键有两点:
第一,如何正确地划分块,把具有相同格式的多行文字划分到一个块中,这样就形成了一个块的字典集合,也就是Block类中的字典类型:Dictionary<int, List<WordMeta>>。
分块也有难点,有很多上标和下标的句子,也有很多非常相似的块,可能分错。比如标题的块和作者的块,文字格式如果非常接近的话,就很容易把作者和标题划分到同一个块中,这给后面的工作带来了麻烦,以至于提取了错误的标题。
第二,如何从众多的块中筛选出标题。
此处也采取了很多筛选策略。
1、根据块长度,淘汰字符长度太短的。
2、根据块位置,淘汰位置太偏的。
3、评分机制,根据块的特征信息,计算出一个0-1之间的数值来,然后选取第一名和第二名的块。
4、在第一名和第二名之间选择。根据它们的位置,字符长度,分值,块的高度,块所包含的单词数等来判断。