学习内容:
数据约束:
1.默认值:
create table test(
sid int,
sname varchar(20),
addres varchar(20) default '中国'
);
insert into test(sid,sname) values (1,'张三'); //不填写addres则默认值为中国
insert into test values (2,'赵四','美国'); //覆写默认值
insert into test values (3,'王五',null); //允许空值覆写
2.非空约束:
create table test(
sid int not null,
sname varchar(20),
addres varchar(20)
);
insert into test(sname,addres) values ('张三','中国'); //报错,sid必须填写
insert into test values (null,'赵四','美国'); //报错,非空约束必须赋值
3.唯一约束:
create table test(
sid int unique,
sname varchar(20),
addres varchar(20)
);
insert into test values (1,'赵四','美国');
insert into test values (1,'赵四','美国'); //报错,sid重复,sid必须唯一
insert into test values (null,'赵四','美国'); //唯一约束对空值不起作用,可插入值
4.主键约束
create table test(
sid int primary key,
sname varchar(20),
addres varchar(20)
);
insert into test values (1,'王五',美国); //可正常插入值
insert into test values (null,'王五',美国); //报错,不可为空值
insert into test values (1,'王五',美国); //报错,值重复
主键约束相当于 not null 和 unique的合并效果
5.自增:
create table test(
sid int(3) primary key auto_increment,
sname varchar(20),
addres varchar(20)
);
insert into test(sname,addres) values ('张三','中国');
insert into test(sname,addres) values ('王五','中国');
sid自增,会从1开始自增写入数值
0填充:
create table test(
sid int(3) zerofill primary key auto_increment,
sname varchar(20),
addres varchar(20)
);
规定sid的长度为3,0填充空位,写入的值sid会从001开始
6.外键约束:
先创建主表
create table major(
mid int primary key, //参考字段必须为主键
mname varchar(10)
);
再创建副表
create table secondary(
sid int primary key auto_increment,
sname varchar(10),
nid int
constraint fk_nid foreign key(nid) references major(sid)
自定义外键名 谁做外键 参考字段
注意:选定的外键必须与参考字段的数值类型一致
);
添加数据时,先添加主表,再添加副表
修改、删除数据时,先修改、删除副表数据
级联操作,修改主表数据,副表随之改变:
on update cascade on delete cascade
CREATE TABLE employee(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(10) NOT NULL,
deptid INT,
CONSTRAINT fk_deptid FOREIGN KEY(deptid) REFERENCES dept(did) ON UPDATE CASCADE ON DELETE CASCADE /*级联操作 主表改变副表随之改变*/
/*自定义外键名 谁做外键(数值类型必须与参考字段一样) 参考字段(主键)*/
);
INSERT INTO employee(ename,deptid) VALUES ('竜之峰帝人',3);
INSERT INTO employee(ename,deptid) VALUES ('折原临也',1);
INSERT INTO employee(ename,deptid) VALUES ('有马公生',2);
INSERT INTO employee(ename,deptid) VALUES ('贝多芬',2);
INSERT INTO employee(ename,deptid) VALUES ('肖邦',2);
INSERT INTO employee(ename,deptid) VALUES ('路飞',4);/*无法添加主表没有的id*/
SELECT * FROM employee;
DROP TABLE employee;
TRUNCATE TABLE employee;
UPDATE employee SET ename='宫园薰' WHERE ename='贝多芬';
DELETE FROM employee WHERE ename='肖邦';
CREATE TABLE dept(
did INT PRIMARY KEY,/*主表必须有主键*/
dname VARCHAR(10)
);
DROP TABLE dept;
SELECT * FROM dept;
INSERT INTO dept VALUES (1,'情报');
INSERT INTO dept VALUES (2,'音乐');
INSERT INTO dept VALUES (3,'dollars');
INSERT INTO dept VALUES (4,'海贼王');
UPDATE dept SET did=0 WHERE did=4;/*修改主表 副表随之改变*/
DELETE FROM dept WHERE did=3;/*删除部门 员工也随之删除*/
7.连接查询
将两个表连接为一个“表”进行查询
from 表1 [连接方式] join 表2 [on 连接条件];
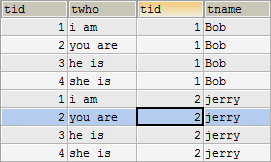
(1)交叉连接
select * from table1 cross join table2;
这种连接方式会将两个表的数据依次链接,即第一张表(左表)所有行数据与第二张表(右表)第一行数据进行连接,以此类推。
例:
(2)内连接
select * from table1 inner join table2 on 表一字段=表二字段;
这种连接方式可以根据on后的条件,将数据一一匹配起来
例:
根据protype_id来进行一一匹配

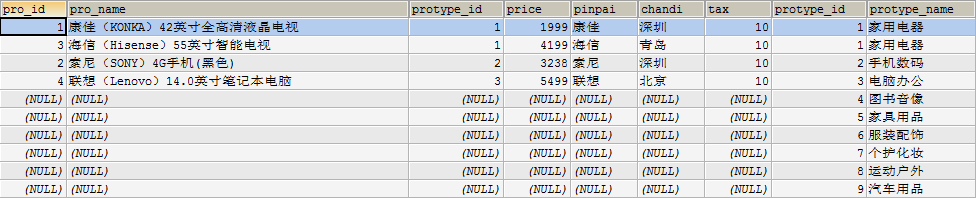
(a)左外连接:
select * from table1 left join table2 on 表一字段=表二字段;
这种连接方式可以将第一张表(左表)的全部数据加以显示(即使不符合on后的匹配条件的数据),第二张表(右表)不能匹配的数据自动填空值
例:
SELECT * FROM product RIGHT JOIN product_type ON product.protype_id=product_type.protype_id;

(b)右外连接:
select * from table1 right join table2 on 表一字段=表二字段;
这种连接方式可以将第二张表(右表)的全部数据加以显示(即使不符合on后的匹配条件的数据),第一张表(左表)不能匹配的数据自动填空值
例:
SELECT * FROM product LEFT JOIN product_type ON product.protype_id=product_type.protype_id;
(c)连接查询:
select 查询字段名 from table1 right join table2 on 表一的表一、二共有字段=表二的表一二共有字段;
on 之后的条件的解释:例如表一有字段 sno 而表二也有sno 则 on 表一.sno=表二.sno
例:
SELECT product.pro_name AS '产品名称',product.price AS '产品价格',product.pinpai AS '产品品牌',product_type.protype_name AS '产品类名'
FROM product INNER JOIN product_type ON product.protype_id=product_type.protype_id;

PS 多表连接查询
select 查询字段名 from table1 right join table2 on 表一的表一、二共有字段=表二的表一二共有字段 inner join table3 on 包含表三的任意两表的共有字段=包含表三的任意两表的共有字段 ;
该规则可以此类推,实现多张表联合查询
例:表一有 sno 表二有 sno cno 表三 有cno 则...on 表一.sno=表二.sno inner join 表三 on 表二.cno=表三.cno
SELECT student.sname,course.cname,score.degree
FROM student INNER JOIN score ON student.sno=score.sno INNER JOIN course ON score.cno=course.cno;
PS 如果 where 字段=多个值 则应使用 字段 in 值 取反值则是 not in
另外也可使用 union(去重) union all(不去重)来同时显示分别查询两个表后的结果
例如: select 字段1 from 表一 union select 字段2 from 表2; 表头的名字是字段1的名字
例:
SELECT * FROM score WHERE degree NOT IN (SELECT MAX(degree) FROM score GROUP BY sno HAVING COUNT(sno)>1);
SELECT cno,degree FROM score WHERE cno IN (SELECT cno FROM course WHERE tno IN (SELECT tno FROM teacher WHERE depart='计算机系'));
in 之后的值为多个
PPS:如果需要查询得值都在一个表中,而where 的判断条件需要用到其他的表,可以不用连接查询,利用子查询即可
例如:
SELECT tname,depart FROM teacher WHERE tno IN (SELECT tno FROM course WHERE cno NOT IN (SELECT cno FROM score GROUP BY cno));