下面这个菜单中,要点击“货运表现”,我们来看一下xpath, 菜单中的所有项的id都是“vertab”,所以不能用id来定位,那么先用文本的xpath试试
//a[text()='货运表现']
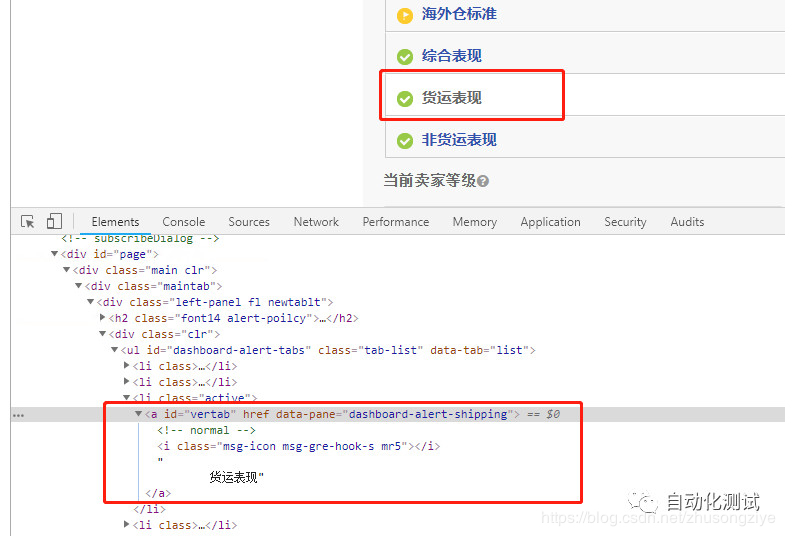
发现定位不了,因为文本“货运表现”的前后有空格和换行,那么用包含文本的xpath试试
//a[contains(text(),'货运表现')]
但是这个菜单中还有个“非货运表现”,文本也包含“货运表现”,显然不行
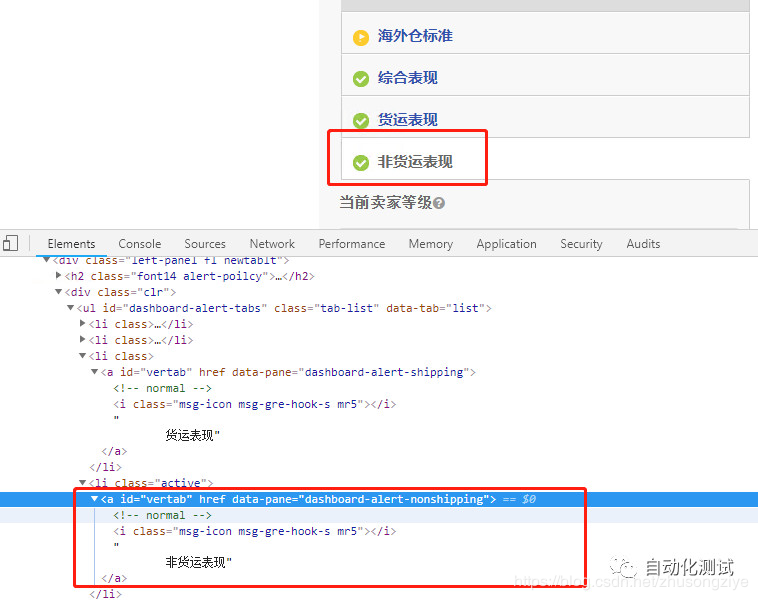
换成这个试试
//a[contains(text(),'货运表现') and not(contains(text(),'非货运表现'))]
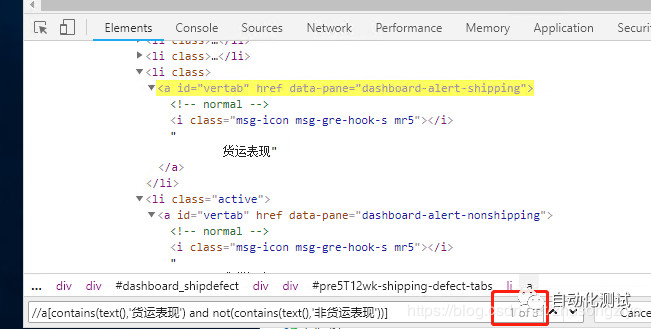
发现匹配到了多个,原来页面其他地方还有符合这个条件的,前面说了,这个菜单里面的几个项都有共同的id,那么加上id的条件试试
//a[@id='vertab' and contains(text(),'货运表现') and not(contains(text(),'非货运表现'))]
这个时候就可以了
有没有更简单的方法呢,各种语言里面都有去除前后空格的方法,难道xpath没有吗?
答案是:有
normalize-space这个方法就可以去除文本中的前后空格和回车,所以这样写
//a[normalize-space(text())='货运表现']
就可以了。