动态时间规整DTW(Dynamic Time Warping )
原文:https://blog.csdn.net/raym0ndkwan/article/details/45614813
算法笔记-DTW动态时间规整
- 简介
- 简单的例子
- 定义
- 讨论
- 约束条件
- 步模式
- 标准化
- 点与点的距离函数
- 具体应用场景
- 分类
- 点到点匹配
算法笔记-DTW动态时间规整
动态时间规整/规划(Dynamic Time Warping, DTW)是一个比较老的算法,大概在1970年左右被提出来,最早用于处理语音方面识别分类的问题。
1.简介
简单来说,给定两个离散的序列(实际上不一定要与时间有关),DTW能够衡量这两个序列的相似程度,或者说两个序列的距离。同时DTW能够对两个序列的延展或者压缩能够有一定的适应性,举个例子,不同人对同一个词语的发音会有细微的差别,特别在时长上,有些人的发音会比标准的发音或长或短,DTW对这种序列的延展和压缩不敏感,所以给定标准语音库,DTW能够很好得识别单个字词,这也是为什么DTW一直被认为是语音处理方面的专门算法。实际上,DTW虽然老,但简单且灵活地实现模板匹配,能解决很多离散时间序列匹配的问题,视频动作识别,生物信息比对等等诸多领域都有应用。
例如下图,有两个呈现正弦规律序列,其中蓝色序列是稍微被拉长了。即使这两个序列,不重合,但是我们也可以有把握说这两个序列的相似程度很高(或者说这两个序列的距离很小)。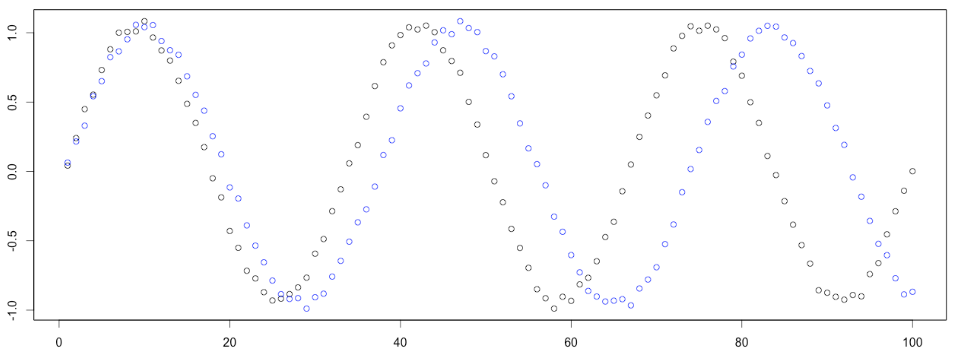
DTW能够计算这两个序列的相似程度,并且给出一个能最大程度降低两个序列距离的点到点的匹配。见下图,其中黑色与红色曲线中的虚线就是表示点点之间的一个对应关系。
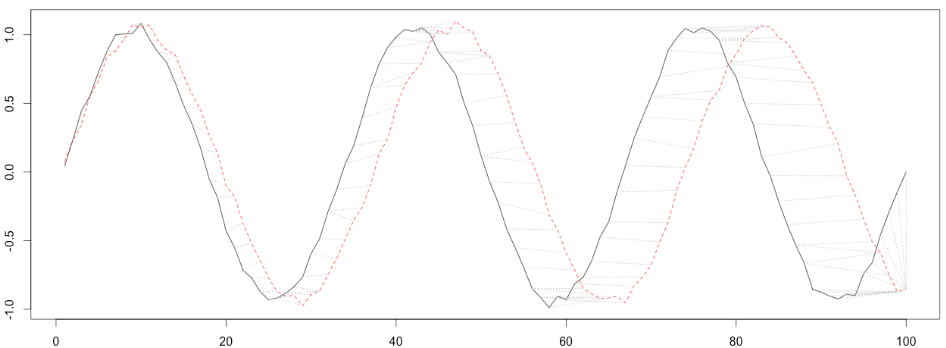
也就是说,两个比对序列之间的特征是相似的,只是在时间上有不对齐的可能,这个算法名中的Time Warping,指的就是对时间序列进行的压缩或者延展以达到一个更好的匹对。
2.简单的例子
比如说,给定一个样本序列X和比对序列Y,Z:
X:3,5,6,7,7,1
Y:3,6,6,7,8,1,1
Z:2,5,7,7,7,7,2
请问是X和Y更相似还是X和Z更相似?
DTW首先会根据序列点之间的距离(欧氏距离),获得一个序列距离矩阵 MM,其中行对应X序列,列对应Y序列,矩阵元素为对应行列中X序列和Y序列点到点的欧氏距离:
X和Y的距离矩阵: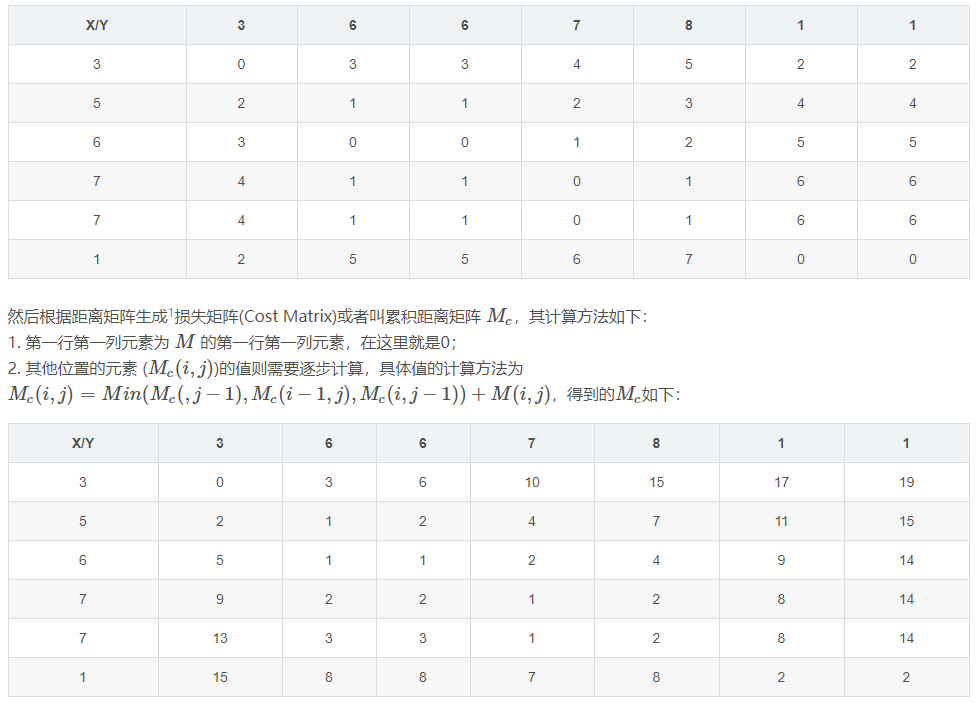
最后,两个序列的距离,由损失矩阵最后一行最后一列给出,在这里也就是2。
同样的,计算X和Z的距离矩阵:
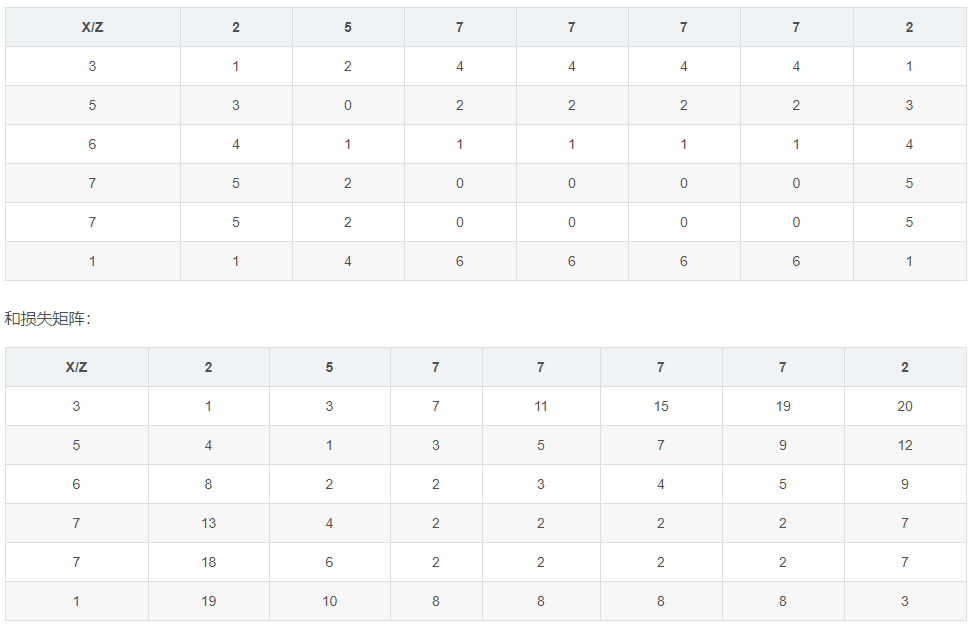
所以,X和Y的距离为2,X和Z的距离为3,X和Y更相似。
3.定义
有一个具体例子作为帮助,我们再来定义DTW算法。

4.讨论
实际上,虽然这个算法简单,但是有很多值得讨论的细节。
约束条件
首先,路径的寻找不是任意的,一般来说有三个约束条件:

步模式

标准化
序列的累积距离,可以被标准化,因为长的测试序列累积距离很容易比短的测试序列累积距离更大,但这不一定说明后者比前者与样本序列更相似,可以通过标准化累积距离再进行比较。不同的步模式会需要的不同的标准化参数。
点与点的距离函数
除了测试序列以外,DTW唯一需要的输入,就是距离函数dd(除了欧氏距离,也可以选择Mahalanobis距离等),所以不需要考虑输入的具体形式(一维或多维,离散或连续),只要能够给定合适的距离函数,就可以DTW比对。前面说到,DTW是对时间上的压缩和延展不敏感,但是对值的大小是敏感的,可以通过合理选取距离函数来让DTW适应值大小的差异。
5.具体应用场景
这里讨论两个具体应用DTW的可能场景:
分类
气象指数在旱季和雨季的样本序列分别为X1和X2,现有一段新的气象指数Y,要判断该气象指数测得时,是雨季还旱季?
算出DTW(X1,Y)和DTW(X2,Y),小者即为与新测得气象指数更贴近,根据此作判断。
DTW就是一个很好的差异比较的工具,给出的距离(或标准化距离)能够进一步输入到KNN等分类器里(KNN就是要找最近的邻居,DTW能够用于衡量“近”与否),进行进一步分类,比对。
点到点匹配
给定标准语句的录音X,现有一段新的不标准的语句录音Y,其中可能缺少或者掺入了别的字词。如何确定哪些是缺少的或者哪些是掺入别的?
通过DTW的扭曲路径,我们可以大致得到结论: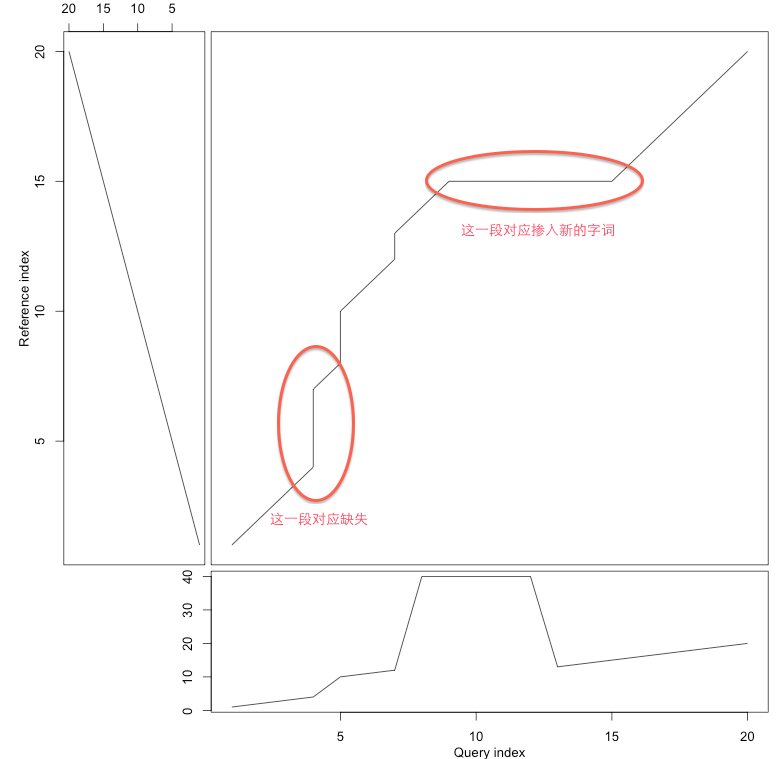
DTW的输出是很丰富的,除了距离外,还提供了扭曲路径,可用于点到点的匹配,这个信息是非常丰富的,能够看到序列的比对,发现异常的序列