什么是计算机科学
计算机科学不仅仅是对计算机的研究,虽然计算机在科学发展的过程找那个发挥了重大的作用,但是它是一个工具,一个没有灵魂的工具而已,所谓的计算机科学实际上是对问题,解决问题以及解决问题的过程中产生的解决方案的研究,例如给定一个问题,计算机科学家的目标是开发一个算法来处理问题,最终得到问题的解或者最优解,所以说计算机科学也可以被认为是符算法的研究,因此我们可以感觉到,所谓的算法就是对问题进行处理且求解的一种实现思路或者思想
如何形象化的理解算法
一个常胜将军在作战之前都会进行战略的制定,目的是为了能够在最短的时间切成本消耗最低的情况下获取最终的胜利。如果将编码作为战场,则程序员就是这场战役的指挥官,你如何可以将你的程序可以在最短且消耗资源最小的情况下获取最终的执行结果呢?算法就是我们的策略
意义
数据结构和算法思想的通用性异常的强大,在任何语言中都被使用,它们将会是我们编码生涯中伴随我们最长久利器(左膀右臂)。有一定经验的程序员最终拼的就是算法和数据结构。
数据结构和算法思想也可以帮助我们拓展和历练编码的思维,可以让我们更好的融入到编程世界的角角落落。
什么是算法分析
刚接触编程的学生经常会将自己编写的程序和别人的程序做比对,获取在比对的过程中会发现双方编写的程序很相似但又各不相同。那么就会出现一个有趣的现象:两组程序都是用来解决同一个问题的,但是两组程序看起来又各不相同,那么哪一组程序更好呢?
示例
a+b+c = 1000, a2 + b2 = c**2 (a,b,c均为自然数),求出a,b,c可能的组合?
for a in range(1001): for b in range(1001): for c in range(1001): if a+b+c == 1000 and a**2+b**2 == c**2: print(a,b,c)
for a in range(0,1001): for b in range(0,1001): c = 1000-a-b if a+b+c == 1000 and a**2+b**2 == c**2: print(a,b,c)
分析:很明显上述两中问题的解决方案是不同的。那如何判定上述两种解决方案(算法)的优劣呢? 可以观察计算两种算法使用耗费计算机资源的大小和它们的执行效率,但是一些较为复杂的算法,它耗费计算机资源的大小和执行效率我们很难能够直观的从算法的编码上分析出来。所以我们必须采用某种量化的方式求出不同算法的资源耗费和执行效率的具体值来判定算法之间的优劣。问题来了,如何进行量化计算呢?方法有两种:
方法1:计算算法执行的耗时(不推荐)
import time start_time = time.time() for a in range(0,1001): for b in range(0,1001): for c in range(0,1001): if a**2+b**2 == c**2 and a+b+c==1000: print(a,b,c) end_time = time.time() print(end_time-start_time) print(1) #执行结果 0 500 500 200 375 425 375 200 425 500 0 500 1221.7778379917145
import time start_time = time.time() for a in range(0,1001): for b in range(0,1001): c = 1000 - a - b if a**2+b**2 == c**2 and a+b+c==1000: print(a,b,c) end_time = time.time() print(end_time-start_time) #执行结果 0 500 500 200 375 425 375 200 425 500 0 500 2.3211328983306885
注意:单靠执行时间是不能反应算法的效率的,还和跟机器(执行环境)存在很大关系
方法2:计算算法的时间复杂度(推荐)
- 时间复杂度:量化算法需要的操作或者执行步骤的数量。
时间复杂度
我们试图通过算法的执行时间来判定算法的优劣。但是仅仅根据执行时间判定算法优劣有些片面,因为算法是独立于计算机的。重要的是量化算法需要的操作或者步骤的数量。选择适当的基本计算单位是个复杂的问题,并且将取决于如何实现算法。对于先前的求和算法,一个比较好的基本计算单位是对执行语句进行计数。
在 sumOfN 中,赋值语句的计数为 1(theSum = 0) 加上 n 的值(我们执行 theSum=theSum+i 的次数)。我们通过函数 T 表示 T(n)=1+n。参数 n 通常称为“问题的规模”,我们称作 “T(n) 是解决问题大小为 n 所花费的时间,即 1+n 步长”。在上面的求和函数中,使用 n 来表示问题大小是有意义的。我们可以说,100,000 个整数和比 1000 个问题规模大。因此,所需时间也更长。我们的目标是表示出算法的执行时间是如何相对问题规模大小而改变的。
计算机科学家更喜欢将这种分析技术进一步扩展。事实证明,操作步骤数量不如确定 T(n) 最主要的部分来的重要。换句话说,当问题规模变大时,T(n) 函数某些部分的分量会超过其他部分。函数的数量级表示了随着 n 的值增加而增加最快的那些部分。
数量级通常称为大O符号,写为 O(f(n))。它表示对计算中的实际步数的近似。函数 f(n) 提供了 T(n) 最主要部分的表示方法。T(n)的最主要部分是:在上述示例中,T(n)=1+n。当 n 变大时,常数 1 对于最终结果变得越来越不重要。如果我们找的是 T(n) 的近似值,我们可以删除 1。因此T(n)中最主要的部分为n,因此f(n)=n。因此在sumOfN函数对应的算法的时间复杂度可即为O(f(n)),即为O(n)。
另外一个示例,假设对于一些算法,确定的步数是 T(n)=5n^2+27n+1005。当 n 很小时, 例如 1 或 2 ,常数 1005 似乎是函数的主要部分。然而,随着 n 变大,n^2 这项变得越来越重要。事实上,当 n 真的很大时,其他两项在它们确定最终结果中所起的作用变得不重要。当 n 变大时,为了近似 T(n),我们可以忽略其他项,只关注 5n^2 。系数 5 也变得不重要。我们说,T(n) 具有的数量级为 f(n)=n^2,或者 O( n^2 )。
示例:计算下列算法的时间复杂度
a =5 b =6 c = 10 for i in range(n): for j in range(n): x = i * j y = j * j z = i * j for k in range(n): w = a*k +45 v = b*b d = 33
分析:前三行赋值语句执行操作步骤为3,5-8行的执行操作步骤为3n,结合第四行的外部循环,整个内外循环的执行步骤为3n^2。9-11行为2n,12行为1。最终得出T(n)=3+3n^2+2n+1,简化操作后T(n)=3n^2+2n+4。通过查看指数,我们可以看到 n^2 项是最重要的,因此这个代码段是 O(n^ 2)。当 n 增大时,所有其他项以及主项上的系数都可以忽略。
数据结构
对于数据(基本类型的数据(int,float,char))的组织方式就被称作为数据结构。数据结构解决的就是一组数据如何进行保存,保存形式是怎样的。
案例:需要存储一些学生的学生信息(name,score),那么这些数据应该如何组织呢?查询某一个具体学生的时间复杂度是什么呢?
组织形式1:
[{'name':'zhangsan','score':100},
{'name':'lisi','score':99}
]
组织形式2:
[('zhangsan',100),
('lisi',99)
]
组织形式3:
{'zhangsan':{'score':100},
'lisi':{'score':99}
}
三种组织形式基于查询的时间复杂度分别为:O(n),O(n),O(1)
发现:python中的字典,列表,元组本身就是已经被封装好的一种数据结构啦。使用不同的数据结构进行数据的存储,所导致的时间复杂度是不一样。因此认为算法是为了解决实际问题而设计的,数据结构是算法需要处理问题的载体。
实操
在列表的操作有一个非常常见的编程任务就是是增加一个列表。我们马上想到的有两种方法可以创建更长的列表,可以使用 append 方法或拼接运算符。但是这两种方法那种效率更高呢。这对你来说很重要,因为它可以帮助你通过选择合适的工具来提高你自己的程序的效率。
实例化一个空列表,然后将0-n范围的数据添加到列表中。(四种方式)
def test01(): alist = [] for i in range(1000): alist = alist + [i] def test02(): alist = [] for i in range(1000): alist.append(i) def test03(): alist =[ i for i in range(1000)] def test04(): alist = list(range(1000))
使用timeit模块来计算上述四种方式的平均运行时长是多少?
- timeit模块:该模块可以用来测试一段python代码的执行速度/时长。
- Timer类:该类是timeit模块中专门用于测量python代码的执行速度/时长的。原型为:class timeit.Timer(stmt='pass',setup='pass')。
- stmt参数:表示即将进行测试的代码块语句。
- setup:运行代码块语句时所需要的设置。
- timeit函数:timeit.Timer.timeit(number=100000),该函数返回代码块语句执行number次的平均耗时。
if __name__ == '__main__': t1 = Timer('test01()', 'from __main__ import test01') print(t1.timeit(number=1000)) t2 = Timer('test02()', 'from __main__ import test02') print(t2.timeit(number=1000)) t3 = Timer('test03()', 'from __main__ import test03') print(t3.timeit(number=1000)) t4 = Timer('test04()', 'from __main__ import test04') print(t4.timeit(number=1000)) #结果 1.8884215653728142 0.09855135850354024 0.040059778813652525 0.01823048553707185
注意:你上面看到的时间都是包括实际调用函数的一些开销,但我们可以假设函数调用开销在四种情况下是相同的,所以我们仍然得到的是有意义的比较。因此,拼接字符串操作需要 1.88 毫秒并不准确,而是拼接字符串这个函数需要 1.88 毫秒。你可以测试调用空函数所需要的时间,并从上面的数字中减去它。剩下的基于列表的其他操作大家也可以使用timeit进行平均耗时的测量计算。
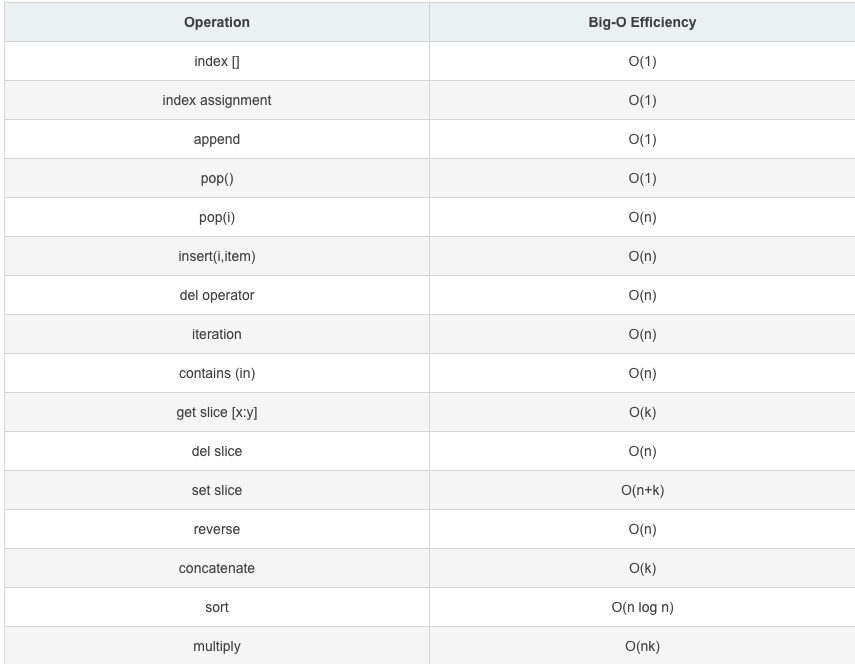
列表的相关操作的方法都是被封装好的,没有必要对相关操作的底层算法时间进行分析,下面直接给出大家一张基于列表操作的时间复杂度的表,供大家参考:
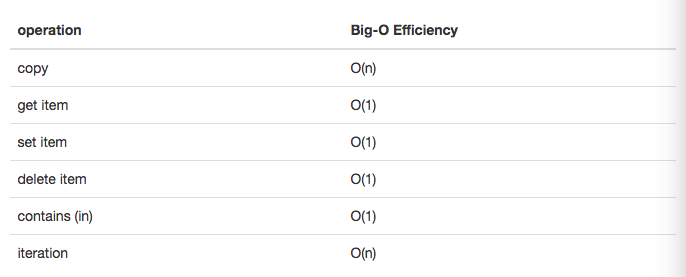
字典
python 中第二个主要的数据结构是字典。你可能记得,字典和列表不同,你可以通过键而不是位置来访问字典中的项目,字典的时间复杂度