官方文档
实现自动化转换格式并且屡试不爽的工具,解压并添加环境变量
链接:https://pan.baidu.com/s/1uU1ZMQJb8LCIvQo7CCxwNw
提取码:3yaf
查看配置是否成功
语音合成代码
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '15842727' API_KEY = 'gBsfoHWw4pOh9n3sNhwoB853' SECRET_KEY = '4e0WXxlTo5lMgFu45lLnO490SnnpLQLN' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def yyhc(text): result = client.synthesis(text, 'zh', 1, { 'vol': 5, 'spd': 5, 'pit': 5, 'per': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result)
语音识别代码
from aip import AipSpeech from yyhc_text import yyhc import os """ 你的 APPID AK SK """ APP_ID = '15842727' API_KEY = 'gBsfoHWw4pOh9n3sNhwoB853' SECRET_KEY = '4e0WXxlTo5lMgFu45lLnO490SnnpLQLN' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() # 识别本地文件 ret = client.asr(get_file_content('hhxx.wma'), 'pcm', 16000, { 'dev_pid': 1536, }) print(ret) if ret.get("result")[0] == "好好学习天天向上": yyhc("学习使我快乐")
通过录音机录制一段普通户音频(好好学习,天天向上),把音频文件放入到项目中测试
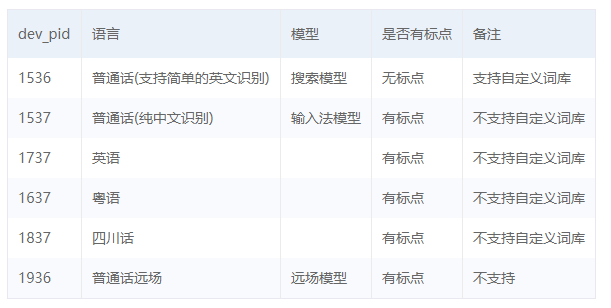
asr函数需要四个参数,第四个参数可以忽略,自有默认值,参照一下这些参数是做什么的
第一个参数: speech 音频文件流 建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。(虽说支持这么多格式,但是只有pcm的支持是最好的)
第二个参数: format 文件的格式,包括pcm(不压缩)、wav、amr (虽说支持这么多格式,但是只有pcm的支持是最好的)
第三个参数: rate 音频文件采样率 如果使用刚刚的FFmpeg的命令转换的,你的pcm文件就是16000
第四个参数: dev_pid 音频文件语言id 默认1537(普通话 输入法模型)
成功的dict中 result 就是我们要的识别文本
失败的dict中 err_no 就是我们要的错误编码,错误编码代表什么呢?
