第一章:
函数式编程主要基于数学函数和它的思想。
1.1 函数与js方法:
函数是一段可以通过其名称被调用的代码,可以传递参数并返回值。
方法是一段必须通过其名称及其关联对象的名称被调用的代码。
//函数
var func = (a)=>{return a}
func(5) //用其名称调用
//方法
var obj = {simple:(a)=>{return a}}
obj.simple(5) //用其名称及其关联对象调用
1.2 引用透明性
所有函数对于相同的输入都将返回相同的值(函数只依赖参数的输入,不依赖于其他全局数据,即函数内部没有全局引用),这使并行代码和缓存(用值直接替换函数的结果)成为可能。
1.3 命令式、声明式与抽象
命令式主张告诉编译器“如何”做
var array = [1,2,3]
for(let i=0; o<array.length;i++){
console.log(array[i])
}
声明式告诉编译器“做什么”,如何做的部分(获得数组长度,循环遍历每一项)被抽象到高阶函数中,forEach就是这样一个内置函数,本书中我们都将创建这样的内置函数。
var array = [1,2,3]
array.forEach(elememt=>console.log(elememt))
1.4 函数式编程的好处&纯函数
好处就是编写纯函数。纯函数是对相同输入返回相同输出的函数,不依赖(包含)任何外部变量,所以也不会产生改变外部环境变量的副作用。
1.5 并行代码
纯函数允许我们并行执行代码,因为纯函数不会改变它的环境,所以不需要担心同步问题。当然,js并没有真正的多线程支持并行,但如果你的项目使用了webworker来模拟多线程并行执行任务,这种时候就需要用纯函数来代替非纯函数。
let global = 'something';
let function1 = (input) => {
global = "somethingElse"
}
let function2 = ()=>{
if(global === 'something'){
//业务逻辑
}
}
如果我们要两个线程并行执行function1和function2,由于两个函数都依赖全局变量global,并行执行就会引起不良的影响(两个函数的执行顺序不同会有不同的结果),现在把它们改为纯函数。
let function1 = (input,global)=>{
global = "somethingElse"
}
let function2 = (global)=>{
if(global === "something"){
//业务逻辑
}
}
我们移动了global变量,把它作为两个函数的参数,使他们变成纯函数。现在并行执行不会有任何问题,由于函数不依赖于外部环境变量,不必担心线程的执行顺序。
1.6 可缓存
根据纯函数对于给定输入总是返回相同的输出,我们可以缓存函数的输出,减少多次的输入来反复调用函数。
var longRunningFnBookKeeper = {2:3,4:5...}
longRunningFnBookKeeper.hasOwnProperty(ip)?longRunningFnBookKeeper[ip]:longRunningFunction(ip)
1.7 管道与组合
纯函数应该被设计为:只做一件事。实现多个功能通过函数的组合来实现。
UNIX/LINUX中,在一个文件中找到一个特定的名称并统计它的出现次数:
cat jsBook | grep -i "composing" | wc
组合不是命令行特有的,它是函数式编程的核心。
1.8 关于js
js是一门面对对象的语言,不是一种纯函数语言,更像是一种多范式语言,但是非常适合函数式编程。
第二章:js函数基础
今天很多浏览器还不支持ES6,我们可以通过转换编译器babel,将ES6转换为ES5代码。
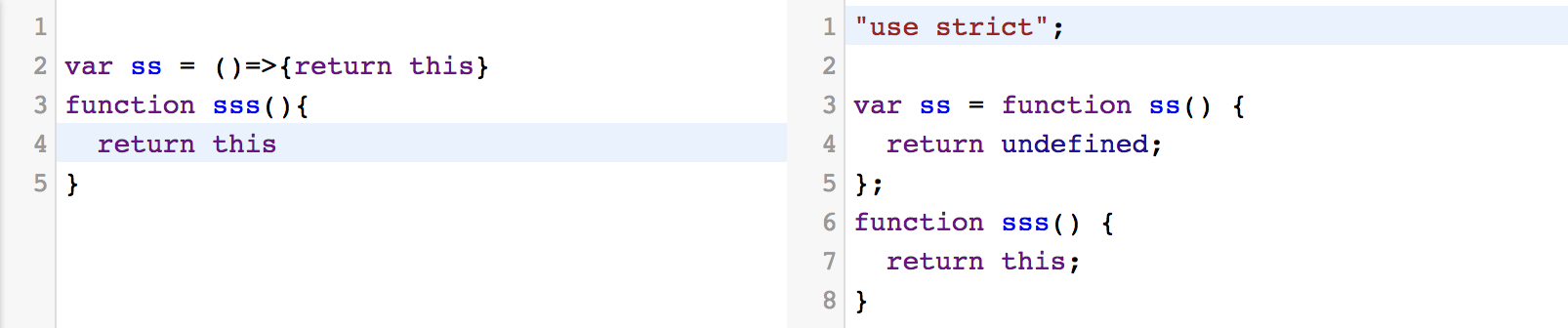
可以看到,箭头函数的this经过编译后为undefined,转换后的代码运行在严格模式下,严格模式是js的受限变体。
"use strict"
a = 1 // -> Uncaught ReferenceError: a is not defined; 此处直接报错
在函数内部如果用var声明变量和不用时有很大差别,用var声明的是局部变量,在函数外部访问这个变量是访问不到的,没var声明的是全局变量。在函数外部是可以访问到的。
如果你不使用var命令指定,在全局状态下定一个变量。在严格模式下这段代码会报错,因为全局变量在js中非常有害。
第三章:高阶函数
高阶函数(HOC):
- 接收函数作为参数
- 返回函数作为输出
- 接收函数作为参数且返回函数作为输出
满足以上三个之一的函数就是高阶函数。
3.1 理解数据
3.1.1 js中函数为一等公民:
因为函数也是js中的一种数据类型,可以被赋值给变量,作为参数传递,也可被其他函数返回。
3.1.2 把一个函数存入变量
let fn = () => {} //fn就是一个指向函数数据类型的变量,即函数的引用
fn() //调用函数,即执行fn指向的函数
3.1.3 函数作为参数传入
var tellType = arg =>{
if(typeof arg==='function'){
arg() //如果传入的是函数就执行
}else{
console.log(arg) //否则就输出数据
}
}
var fn = () => {console.log('i am a function')}
tellType(fn) //函数作为参数传入
3.1.4 返回函数
String是js的内置函数,注意:只返回了函数的引用,并没有执行函数
let crazy = () =>{ return String }
crazy() // String() { [native code] }
crazy()('HOC') // "HOC"
3.2 抽象和高阶函数
高阶函数就是定义抽象
3.2.1通过高阶函数实现抽象
forEach实现遍历数组
const forEach = (array,fn)=>{
for(let i=0;i<array.length;i++){
fn(array[i])
}
}
forEachObject实现遍历对象
const forEachObject = (obj,fn)=>{
for(var property in obj){
if(obj.hasOwnProperty(properity){
fn(property,obj[property])
})
}
}
注意:forEach和forEachObject都是高阶函数,他们使开发者专注于任务,而抽象出遍历的部分。
unless函数:如果predicate为false,则调用fn
const unless = (predicate,fn)=>{
if(!predicate)
fn()
}
查找一个列表中的偶数
forEach([1,2,3,4,6,7],(number)=>{
unless((number%2),()=>{
console.log(number,"is even")
})
})
如果我们操作的是一个Number而不是array
const times = (time,fn)=>{
for(var i=0;i<time;i++){
fn(i)
}
}
times(100,function(n){
unless(n%2,function(){
console.log(n, "is even")
})
})
3.3 真实的高阶函数
a.every(function(element, index, array))
every是所有函数的每个回调函数都返回true的时候才会返回true,当遇到false的时候终止执行,返回false。
a.some(function(element, index, array))
some函数是“存在”有一个回调函数返回true的时候终止执行并返回true,否则返回false
在空数组上调用every返回true,some返回false。
3.3.1 every函数
every函数接受两个参数:一个数组和一个函数。它使用传入的函数检查数组的所有元素是否为true, 都为true才返回true
const every = (arr,fn)=>{
let result = true;
for(let i =0;i<arr.length;i++){
result = result&&fn(arr[i])
}
return true;
}
every([NaN,NaN,NaN],isNaN)
for..of循环:ES6中用于遍历数组元素的方法,重写every方法
const every = (arr,fn)=>{
let result = true;
for(const element of arr){
result = result&&fn(element)
}
return true;
}
3.3.2 some函数
some函数接受两个参数:一个数组和一个函数。它使用传入的函数检查数组的所有元素是否为true, 只要有一个为true就返回true
const some = (arr,fn)=>{
let result = false;
for(const element of arr){
result = result||fn(element)
}
return true;
}
some([5,NaN,NaN],isNaN)
3.3.3 sort函数
sort函数是一个高阶函数,它接受一个函数作为参数,该函数帮助sort函数决定排序逻辑, 是一个改变原数组的方法。
arr.sort([compareFunc])
compareFunc是可选的,如果compareFunc未提供,元素将被转换为字符串并按Unicode编码点顺序排列。
compareFunc应该实现下面的逻辑
function compareFunc(a,b){
if(根据某种排序标准a<b){
return -1
}
if(根据某种排序标准a>b){
return 1
}
return 0;
}
具体例子
var friends = [{name: 'John', age: 30},
{name: 'Ana', age: 20},
{name: 'Chris', age: 25}];
function compareFunc(a,b){
return (a.age<b.age)?-1:(a.age>b.age)?1:0
}
写成以下也ok,按照age升序排列
function compareFunc(a,b){
return a.age>b.age
}
friends.sort(compareFunc)

如果要比较不同的属性,我们需要重复编写比较代码。下面新建一个sortBy函数,允许用户基于传入的属性对对象数组排序。
const sortBy = (property)=>{
return (a,b) => {
return (a[property]<b[property])?-1:(a[property]>b[property])?1:0
}
}
var friends = [{name: 'John', age: 30},
{name: 'Ana', age: 20},
{name: 'Chris', age: 25}];
friends.sort(sortBy('age'))
注意:sortBy函数接受一个属性冰返回另一个函数,这个返回的函数就作为compareFunc传递给sort函数,持有property参数值的返回函数之所以能够运行是因为js支持闭包。
第四章:高阶函数与闭包
4.1理解闭包
4.1.1什么是闭包
简言之,闭包是一个内部函数,它是在一个函数内部的函数。
function outer(){
function inner(){
}
}
函数inner称为闭包函数,闭包如此强大的原因在于它对作用域链的访问。
闭包有3个可以访问的作用域:
1.闭包函数内声明的变量
2.对全局变量的访问
3.对外部函数变量的访问!!!!
let global = 'global';//2
function outer(){
let outer = 'outer';
function inner(){
let a=5;//1
console.log(outer) //3.闭包能够访问外部函数变量
}
return inner
}
outer()()//"outer"
4.1.2 闭包可以记住它的上下文
var fn = (arg)=>{
let outer = 'outer';
let innerFn = () =>{
console.log(outer)
console.log(arg)
}
return innerFn
}
var closeureFn = fn(5)
closeureFn()//outer 5
当执行var closeureFn = fn(5)时,函数innerFn被返回,js执行引擎视innerFn为一个闭包,并相应的设置了它的作用域。3个作用域层级在innerFn返回时都被设置了。
如此,closeureFn()通过作用域链被调用时就记住了arg、outer的值。
我们回到sortBy
const sortBy = (property)=>{
return (a,b) => {
return (a[property]<b[property])?-1:(a[property]>b[property])?1:0
}
}
当我们以如下形式调用时
sortBy('age')
发生下面的事情:
sortBy函数返回了一个接受两个参数的新函数,这个新函数就是一个闭包
(a,b)=>{/*实现*/}
根据闭包能访问作用域层级的特点,它能在它的上下文中持有property的值,所以它将在合适并且需要的时候使用返回值。
4.2真实的高阶函数
4.2.1 once:允许只运行一次给定的函数
这在开发过程中很常见,例如只想设置一次第三方库,初始化一次支付设置。
const once = (fn)=>{
let done = false;
return function(){
return done?undefined:((done=true),fn.apply(this,arguments))
}
}
var dopayment = once(()=>{console.log("Payment is done")})
dopayment() //Payment is done
dopayment() //undefined
js中,(exp1,exp2)的含义是执行两个参数并返回第二个表达式的结果。
注意:once函数接受一个参数fn并通过调用fn的apply方法返回结果。我们声明了done变量,返回的函数会形成一个覆盖它的闭包作用域,检查done是否为true,如果是则返回undefined,
否则将done设为true,如此就阻止了下一次的执行。
4.2.2 memoized
用于为每一个输入存储结果,以便于重用函数中的计算结果。
const memoized = (fn) => {
const lookupTable = {};
return (arg) => lookupTable[arg] || (lookupTable[arg]=fn(arg));
}
有一个名为lookupTable的局部变量,它在返回函数的闭包上下文中。返回函数将接受一个参数并检查它是否在lookupTable中。
如果在,就返回对应的值,否则使用新的输入作为key,fn(arg)的结果为value,更新lookupTable对象。
求函数的阶乘(递归法)
var factorial = (n) => {
if(n===0){
return 1;
}
return n*factorial(n-1)
}
现在可以改为把factorial函数包裹进一个memoized函数来保留它的输出(存储结果法)
let factorial = memoized((n)=>{
if(n===0){
return 1;
}
return n*factorial(n-1)
})
它以同样的方式运行,但是比之前快的多。
第五章:数组的函数式编程
我们使用数组来存储、操作和查找数据,以及转换(投影)数据格式。本章中使用函数式编程来改进这些操作。
5.1 数组的函数式方法
本节创建的所有函数称为投影函数,把函数应用于一个值并创建一个新值的过程称为投影。
5.1.1 map
首先来看遍历数组的forEach方法
const forEach = (array,fn) => {
for(const value of array)
fn(value)
}
map函数的实现代码如下
const map = (array,fn) => {
let results= [];
for(const value of array)
results.push(fn(value))
return results;
}
map和forEach非常类似,区别是用一个新的数组捕获了结果,并返回了结果。
let apressBooks = [
{
"id": 111,
"title": "c# 6.0",
"author": "ANDREW JKDKS",
"rating": [4],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 222,
"title": "Machine Learning",
"author": "ANDREW JKDKS",
"rating": [3],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 333,
"title": "Angularjs",
"author": "ANDREW JKDKS",
"rating": [5],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 444,
"title": "Pro ASP.NET",
"author": "ANDREW JKDKS",
"rating": [4.7],
"reviews": [{good:4, excellent: 12}]
}
];
假设只需要获取包含title和author的字段
map(apressBooks,(book)=>{
return {title:book.title,author:book.author}
})
5.1.2 filter
有时我们还想过滤数组的内容(例如获取rating>4.5的图书列表),再转换为一个新数组,因此我们需要一个类似map的函数,它只需要在把结果放入数组前检查一个条件。
const filter = (array,fn) => {
let results= [];
for(const value of array)
fn(value) ? results.push(value) : undefined
return results;
}
调用高阶函数filter
filter(apressBooks, (book)=>book.rating[0]>4.5)
返回结果

5.2 连接操作
map和filter都是投影函数,因此它们总是对数组应用转换操作后再返回数据,于是我们能够连接filter和map(注意顺序)来完成任务而不需要额外变量。
例如:从apressBooks中获取含有title和author对象且评级高于4.5的对象。
map(filter(apressBooks, (book)=>book.rating[0]>4.5),(book)=>{
return {title:book.title,author:book.author}
})
我们将后面的章节中国通过函数组合来完成同样的事情。
concatAll
对apressBooks对象稍作修改,得到如下数据结构
let apressBooks = [
{
name: "beginners",
bookDetails: [
{
"id": 111,
"title": "c# 6.0",
"author": "ANDREW 1",
"rating": [4],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 222,
"title": "Machine Learning",
"author": "ANDREW 2",
"rating": [3],
"reviews": [{good:4, excellent: 12}]
}
]
},
{
name: "pro",
bookDetails: [
{
"id": 333,
"title": "Angularjs",
"author": "ANDREW 3",
"rating": [5],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 444,
"title": "Pro ASP.NET",
"author": "ANDREW 4",
"rating": [4.7],
"reviews": [{good:4, excellent: 12}]
}
]
}
];
现在回顾上一节的问题:获取含有title和author字段且评级高于4.5的图书。
map(apressBooks,(book)=>{
return book.bookDetails
})
得到如下输出

如上图所示,map函数返回的数据包含了数组中的数组,如果把上面的数据传给filter将会遇到问题,因为filter不能在嵌套数组上运行。
我们定义一个concatAll函数把所有嵌套数组连接到一个数组中,也可称concatAll为flatten方法(嵌套数组平铺)。concatAll的主要目的是将嵌套数组转换为非嵌套的单一数组。
const concatAll = (array) => {
let results = [];
for(const value of array){
results.push.apply(results,value) //重点!!
}
return results;
}
使用js的apply方法,将push的上下文设置为results
concatAll(map(apressBooks,(book)=>{
return book.bookDetails
}))
返回了我们期望的结果(数组平铺)

转换为非嵌套的单一数组后就可以继续使用filter啦
filter(
concatAll(map(apressBooks,(book)=>{
return book.bookDetails
})),(book) => (book.rating[0] > 4.5)
)
返回结果

flatten嵌套数组扁平化
let arr = [[1,2,[3,4]],[4,5],77]
遍历每一项,如果仍是数组的话就递归调用flatten,并将结果与result concat一下。如果不是数组就直接push该项到result。
function flatten(array){
var result = [];
var toStr = Object.prototype.toString;
for(var i=0;i<array.length;i++){
var element = array[i];
if(toStr.call(element) === "[object Array]"){ //Array.isArray(element) === true
result = result.concat(flatten(element)); //[...result,...flatten(element)]
}
else{
result.push(element);
}
}
return result;
}
let results = flatten(arr)
5.3 reduce函数
reduce为保持Javascript闭包的能力所设计。
先来看一个数组求和问题:
let useless = [2,5,6,1,10]
let result = 0;
forEach(useless,value=>{
result+=value;
})
console.log(result) //24
对于上面的问题,我们将数组归约为一个单一的值,从一个累加器开始(result),在遍历数组时使用它存储求和结果。
归约数组:设置累加器并遍历数组(记住累加器的上一个值)以生成一个单一元素的过程称为归约数组。
我们将这种归约操作抽象成reduce函数。
reduce函数的第一个实现
const reduce = (array,fn)=>{
let accumlator = 0;
for(const value of array){
accumlator = fn(accumlator,value);
}
return [accumlator]
}
reduce(useless,(acc,val)=>acc+val) //[24]
但如果我们要求给定数组的乘积,reduce函数会执行失败,主要是因为我们使用了累加器的值0。
我们修改reduce函数,让它接受一个为累加器设置初始值的参数。
如果没有传递initialValue时,则以数组的第一个元素作为累加器的值。
const reduce = (array,fn,initialValue)=>{
let accumlator;
if(initialValue != undefined)
accumlator = initialValue;
else
accumlator = array[0];
//当initialValue未定义时,我们需要从第二个元素开始循环数组
if(initialValue === undefined){
for(let i=1; i<array.length;i++){
accumlator = fn(accumlator,array[i])
}
}else{//如果initialValue由调用者传入,我们就需要遍历整个数组。
for(const value of array){
accumlator = fn(accumlator,value);
}
}
return [accumlator]
}
尝试通过reduce函数解决乘积问题
let useless = [2,5,6,1,10]
reduce(useless,(acc,val)=>acc*val,1) //[600]
reduce使用举例
从apressBooks中统计评价为good和excellent的数量。->使用reduce
由于apressBooks包含数组中的数组,先需要使用concatAll把它转化为一个扁平的数组。
concatAll(map(apressBooks,(book)=>{
return book.bookDetails
}))
我们使用reduce解决该问题。
let bookDetails = concatAll(map(apressBooks,(book)=>{
return book.bookDetails
}))
reduce(bookDetails,(acc,bookDetail)=>{
let goodReviews = bookDetail.reviews[0] != undefined ? bookDetail.reviews[0].good : 0
let excellentReviews = bookDetail.reviews[0] != undefined ? bookDetail.reviews[0].good : 0
return {good:acc.good + goodReviews, excellent:acc.excellent + excellentReviews}
},{good:0,excellent:0})
在reduce函数体中,我们获取good和excellent的评价详情,将其存储在相应的变量中,名为goodReviews和excellentReviews。
5.4 zip数组
再回顾一下之前数据的结构,我们在apressBooks的bookDetails中获取reviews,并能轻松的操作它。
let apressBooks = [
{
name: "beginners",
bookDetails: [
{
"id": 111,
"title": "c# 6.0",
"author": "ANDREW 1",
"rating": [4],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 222,
"title": "Machine Learning",
"author": "ANDREW 2",
"rating": [3],
"reviews": [{good:4, excellent: 12}]
}
]
},
{
name: "pro",
bookDetails: [
{
"id": 333,
"title": "Angularjs",
"author": "ANDREW 3",
"rating": [5],
"reviews": [{good:4, excellent: 12}]
},
{
"id": 444,
"title": "Pro ASP.NET",
"author": "ANDREW 4",
"rating": [4.7],
"reviews": [{good:4, excellent: 12}]
}
]
}
];
但是有时候数据可能被分离到不同部分了。
let apressBooks = [
{
name: "beginners",
bookDetails: [
{
"id": 111,
"title": "c# 6.0",
"author": "ANDREW 1",
"rating": [4]
},
{
"id": 222,
"title": "Machine Learning",
"author": "ANDREW 2",
"rating": [3],
"reviews": []
}
]
},
{
name: "pro",
bookDetails: [
{
"id": 333,
"title": "Angularjs",
"author": "ANDREW 3",
"rating": [5],
"reviews": []
},
{
"id": 444,
"title": "Pro ASP.NET",
"author": "ANDREW 4",
"rating": [4.7]
}
]
}
];
reviews被填充到一个单独的数组中。
let reviewDetails = [
{
"id":111,
"reviews":[{good:4,excellent:12}]
},
{
"id":222,
"reviews":[]
},
{
"id":111,
"reviews":[]
},
{
"id":111,
"reviews":[{good:4,excellent:12}]
},
]
zip函数
const zip = (leftArr,rightArr,fn) => {
let index,results=[];
for(index=0;index<Math.min(leftArr.length,rightArr.length);index++){
results.push(fn(leftArr[index],rightArr[index]));
}
return results;
}
zip:我们只需要遍历两个给定的数组,由于要处理两个数组详情,就需要用 Math.min 获取它们的最小长度Math.min(leftArr.length, rightArr.length),一旦获取了最小长度,我们就能够用当前的leftArr值和rightArr值调用传入的高阶函数fn。
假设我们要把两个数组的内容相加,可以采用如下方式使用zip
zip([1,2,3],[4,5,6],(x,y)=>x+y)
继续解决上一节的问题:统计Apress出版物评价为good和excellent的总数。
我们接受bookDetails和reviewDetails数组,检查两个数组元素的id是否匹配,如果是,就从book中克隆出一个新的对象clone
//获取bookDetails
let bookDetails = concatAll(map(apressBooks,(book)=>{
return book.bookDetails
}))
//zip results
let mergedBookDetails = zip(bookDetails, reviewDetails, (book, review)=>{
if(book.id === review.id){
let clone = Object.assign({},book)
clone.ratings = review //为clone添加一个ratings属性,以review对象作为其值
return clone
}
})
注意:Object.assign(target, ...sources)
Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
let clone = Object.assign({},book)clone得到了一份book 对象的副本,clone指向了一个独立的引用,为clone添加属性或操作不会改变真实的book引用。

第六章:柯里化与偏应用
6 一些术语
6.1 一元函数
只接受一个参数的函数称为一元(unary)函数。
const identity = (x) => x
6.2 二元函数
接受两个参数的函数称为二元(binary)函数。
const add = (x,y) => x+y;
6.1 变参函数
指函数接受的参数数量是可变的。ES5中我们通过arguments来捕获可变数量的参数。
function variadic(a){
console.log(a)
console.log(arguments)
}
调用
variadic(1,2,3)
1
[1,2,3]
ES6中我们使用扩展运算符,获得可变参数
const variadic = (a,...variadic){
console.log(a)
console.log(variadic)
}
调用
variadic(1,2,3)
1
[2, 3]
6.2 柯里化
柯里化:把一个多参数函数转换为一个嵌套的一元函数的过程。
看个例子,假设有一个名为add的函数
const add = (x,y)=>x+y;
我们会如此调用该函数add(1,1),得到结果2。下面是add函数的柯里化版本:
const addCurried = x => y => x+y;
如果我们用一个单一的参数调用addCurried,
addCurried(3)
它返回一个函数,在其中x值通过闭包被捕获,fn = y => 4+y ,因此可以用如下方式调用addCurried
addCurried(3)(4) //7
类似的乘法函数
const curri = x=>y=>z=>x*y*z;
curri(2)(3)(4) //24
下面展示了如何把该处理过程转换为一个名为curry的方法, curry方法将接收到的函数参数curry化
const curry = (binaryFn) => {
return function(firstArg){
return function(secondArg){
return binaryFn(firstArg,secondArg)
}
}
}
调用curry函数,curry化add。
const add = (x,y)=>x+y;
let autoCurried = curry(add)
autoCurried(2)(3) //5
6.2.1 柯里化用例
假设我们要编写一个创建列表的函数,创建列表tableOf2、tableOf3、tableOf4等。
const tableOf2 = (y) => 2*y;
const tableOf3 = (y) => 3*y;
const tableOf4 = (y) => 4*y;
现在可以把表格的概念概括为一个单独的函数
const genericTable = (x,y) => x*y
我们将genericTable柯里化,用2填充tableOf2的第一个参数,用3填充tableOf3的第一个参数,用4填充tableOf4的第一个参数。
const tableOf2 = curry(genericTable)(2);
const tableOf3 = curry(genericTable)(3);
const tableOf4 = curry(genericTable)(4);
6.2.2 完整curry函数
添加规则,检查如果传入参数不是function,就会报错。
let curry = (fn) => {
if(typeof fn!=='function'){
throw Error('No function provided')
}
}
如果有人为柯里化函数提供了所有的参数,就需要通过传递这些参数执行真正的函数,重点在于返回函数curriedFn是一个变参函数。
let curry = (fn) => {
if(typeof fn!=='function'){
throw Error('No function provided')
}
return function curriedFn(){ //返回函数是一个变参函数
return fn(...arguments)
}
//采用如下写法也ok
// return function curriedFn(...args){
// return fn(...args)
// }
}
如果我们有一个名为multiply的函数:
const multiply = (x,y,z) => x*y*z;
可以通过如下方式调用,等价于multiply(1,2,3)
curry(multiply)(1,2,3) //6
下面回到把多参数函数转换为嵌套的一元函数(柯里化的定义)
let curry = (fn) => {
if(typeof fn!=='function'){
throw Error('No function provided')
}
return function curriedFn(...args){ //args是一个数组
if(args.length < fn.length){ //检查...args传入的参数长度是否小于函数参数列表的长度
return function(){
args = [...args,...arguments]
return curriedFn(...args)
};
}
return fn(...args) //不小于,就和之前一样调用整个函数
}
}
args.length < fn.length
检查...args传入的参数长度是否小于函数参数列表的长度,如果是,就进入if代码块,如果不是就如之前一样调用整个函数。
args = [...args,...arguments]用来连接一次传入的参数,把他们合并进args,并递归调用curriedFn。由于我们将所有传入的参数 组合并递归地调用,再下一次调用中将会遇到某一个时刻if(args.length < fn.length)条件失败,说明这时args存放的参数列表的长度和函数参数的长度相等,程序就会被调用 fn(...args)。
调用
const multiply = (x,y,z) => x*y*z;
curry(multiply)(1)(2)(3) //6
6.2.3 日志函数 —— 柯里化的应用
开发者在写代码时候会在应用的不同阶段编写很多日志。我们编写如下日志函数。
6.3 柯里化实战
6.3.1 在数组内容中查找数字
在数组中查找数字,返回包含数字的数组内容。
无需柯里化时,我们可以如下实现。
["js","number1"].filter(function(e){
return /[0-9]+/.test(e) //["number1"]
})
采用柯里化的filter函数
let filter = curry((fn,ary)=>{
return ary.filter(fn)
})
filter(function(str){
return /[0-9]+/.test(str);
})(["js","number1"]) //["number1"]
6.3.2 求数组的平方
前几章中,我们使用map函数传入一个平凡函数来解决问题,此处可以通过curry函数以另一种方式解决该问题。
let map = curry(function(f,ary){
return ary.map(f)
})
map(x=>x*x)([1,2,3]) //[1, 4, 9]
6.4 数据流
我们设计的柯里化函数总在最后接受数组,这是有意而为之。如果我们希望最后接受的参数是位于参数列表的中间某位置呢?curry就帮不了我们了。
6.4.1偏应用
偏应用:部分地应用函数参数。有时填充函数的前两个参数和最后一个参数会使中间的参数处于一种未知状态,这正是偏应用发挥作用的地方,将未知状态的参数填充为undefined,之后填入其他参数调用函数。
setTimeout(()=>console.log("Do X task"),10)
setTimeout(()=>console.log("Do Y task"),10)
我们为每一个setTimeout函数都传入了10,我们希望把10作为常量,在代码中把它隐藏。curry函数并不能帮我们解决这个问题,原因是curry函数应用参数列表的顺序是从最左到最右。
一个方案是把setTimeout封装一下,如此函数参数就会变成最右边的一个。
const setTimeoutWrapper = (time,fn)=>{
setTimeout(fn,time);
}
然后就能通过curry函数来实现一个10ms的延迟了
const delayTenMs = curry(setTimeoutWrapper)(10)
delayTenMs(()=>console.log("Do X task"))
delayTenMs(()=>console.log("Do Y task"))
程序将以我们需要的方式运行,但问题是创建了setTimeoutWrapper这个封装器,这是一种开销。
6.4.2 实现偏函数(适用于任何含有多个参数的函数)
const partial = function(fn, ...partialArgs){
let args = partialArgs;
return function(...fullArguments){
let arg = 0;
for(let i=0;i<args.length && arg<fullArguments.length;i++){
if(args[i]===undefined){
args[i] = fullArguments[arg++];
}
}
return fn.apply(null,args)
}
}
使用该偏函数
let delayTenMs = partial(setTimeout,undefined,10);
delayTenMs(()=>console.log("Do Y task"))
说明:
我们调用
partial(setTimeout,undefined,10);
这将产生
let args = partialArgs = [undefined,10]返回函数将记住args的值(闭包)
返回函数非常简单,它接受一个名为fullArguments的参数。所以传入()=>console.log("Do Y task")作为参数,
在for循环中我们执行遍历并为函数创建必需的参数数组
if(args[i]===undefined){
args[i] = fullArguments[arg++];
}
从i=0开始,
返回函数将记住args的值,返回函数非常简单,它接受一个名为fullArguments的参数。所以传入
fullArguments = [()=>console.log("Do Y task")]
在if循环内
args[0]===undefined=>true
args[0]=()=>console.log("Do Y task")
如此args就变成
[()=>console.log("Do Y task"),10]
可以看出,args指向我们期望的setTimeout函数调用所需的数组,一旦在args中有了必要的参数,就可以通过fn.apply(null,args)调用函数了。
partial应用
注意,我们可以将partial应用于任何含有多个参数的函数,看下面的例子。js中使用JSON.stringify() 方法将一个JavaScript值(对象或者数组)转换为一个 JSON字符串。
JSON.stringify(value[, replacer[, space]])
value:
必需, 要转换的 JavaScript 值(通常为对象或数组)。
replacer:
可选。用于转换结果的函数或数组。
如果 replacer 为函数,则 JSON.stringify 将调用该函数,并传入每个成员的键和值。使用返回值而不是原始值。如果此函数返回 undefined,则排除成员。根对象的键是一个空字符串:""。
如果 replacer 是一个数组,则仅转换该数组中具有键值的成员。成员的转换顺序与键在数组中的顺序一样。
space:
可选,文本添加缩进、空格和换行符,如果 space 是一个数字,则返回值文本在每个级别缩进指定数目的空格,如果 space 大于 10,则文本缩进 10 个空格。space 也可以使用非数字,如: 。
我们调用下面的函数做JSON的美化输出。
let obj = {obj:"bar",bar:"foo"}
JSON.stringify(obj,null,2);
输出:
"{
"obj": "bar",
"bar": "foo"
}"
可以看到stringify调用的最后两个参数总是相同的“null,2”,我们可以用partial移除样板代码
let prettyPrintJson = partial(JSON.stringify, undefined, null, 2)
prettyPrintJson({obj:"bar",bar:"foo"})
输出:
"{
"obj": "bar",
"bar": "foo"
}"
该偏函数的小bug:
如果我们使用一个不同的参数再次调用prettyPrintJson,它将总是给出第一次调用的结果。
prettyPrintJson({obj:"bar",bar:"foo222"})
输出:总是给出第一次调用的结果
"{
"obj": "bar",
"bar": "foo"
}"
因为我们通过参数替换undefined值的方式修改partialArgs,而数组传递的是引用。
第七章:组合与管道(compose/pipe)
7.1 组合的概念
函数式组合:将多个函数组合在一起以便能构建出一个新函数。
Unix的理念
1.每个程序只做好一件事情。
2.每个程序的输出应该是另一个尚不可知的程序的输入。
Unix管道符号|
使用Unix管道符号|,就可以将左侧的函数输出作为右侧函数的输入。
如果想计算单词word在给定文本文件中的出现次数,该如何实现呢?
cat test.txt | grep 'world' | wc
cat用于在控制台现实文本文件的内容,它接受一个参数(文件位置)
grep在给定的文本中搜索内容
wc计算单词在给定文本中的数量
7.2 compose函数
本节创建第一个compose函数,它需要接收一个函数的输出,并将其作为输入传递给另外一个函数。
const compose = (a, b)=>(c)=>a(b(c))
compose 接收函数a 、b作为输入,并返回一个接收参数c的函数。当用c调用返回函数时,它将用输入c调用函数b,b的输出作为a的输入,这就是compose函数的定义。
注意:函数的调用方向是从右至左的。
7.3 应用compose函数
例子1:对一个给定的数字四舍五入求和。
let data = parseFloat("3.56")
let number = Math.round(data) //4
下面通过compose函数解决该问题:
const compose = (a, b)=>(c)=>a(b(c))
let number = compose(Math.round, parseFloat)
number("3.56") //4
以上就是函数式组合,我们将两个函数(Math.round、parseFloat)组合在一起以便能构造出一个新函数,注意:Math.round和parseFloat知道调用number函数时才会执行。
例子2:计算一个字符串中单词的数量
已有以下两个函数:
let splitIntoSpaces = (str) => str.split(" ")
let count = (array) => array.length;
如果想用这两个函数构建一个新函数,计算一个字符串中单词的数量。
const countWords = compose(count, splitIntoSpaces)
调用
countWords("hello what's your name") // 4
7.3.1 引入curry和partial
以上的例子中,仅当函数接收一个参数时,我们才能将两个函数组合。但还存在多参数函数的情况,我们可以通过curry和partial函数来实现。
5.2中,我们通过以下写法从apressBooks中获取含有title和author对象且评级高于4.5的对象。
map(filter(apressBooks, (book)=>book.rating[0]>4.5),(book)=>{
return {title:book.title,author:book.author}
})
本节使用compose函数将map和filter组合起来。
compose只能组合接受一个参数的函数,但是map和filter都接受两个参数map(array,fn) filter(array,fn)(数组,操作数组的函数),不能直接将他们组合。我们使用partial函数部分地应用map和filter的第二个参数。
我们定义了过滤图书的小函数filterGoodBooks和投影函数projectTitleAndAuthor
let filterGoodBooks = (book)=>book.rating[0]>4.5;
let projectTitleAndAuthor = (book)=>{return {title:book.title, author:book.author}}
现在使用compose和partial实现
let queryGoodBooks = partial(filter, undefined, filterGoodBooks);
let mapTitleAndAuthor = partial(map, undefined, projectTitleAndAuthor);
let titleAndAuthorForGoodBooks = compose(mapTitleAndAuthor, queryGoodBooks)
使用
titleAndAuthorForGoodBooks(apressBooks)
输出:
0: {title: "Angularjs", author: "ANDREW JKDKS"}
1: {title: "Pro ASP.NET", author: "ANDREW JKDKS"}本例子使用partial和compose解决问题,也可以用curry来做同样的事情。
提示:颠倒map和filter的参数顺序。
const mapWrap = (fn,array)=>{
return map(array,fn)
}7.3.2 组合多个函数
当前的compose只能组合两个给定的函数,我们重写compose函数,使它能组合三个、四个、更多函数。
const compose = (...fns) =>
(value) =>
reduce(fns.reverse(), (acc, fn) => fn(acc), value)
reduce用于把数组归约为一个单一的值,例如求给定数组的元素乘积,累乘器初始值为1
reduce([1,2,3,4],(acc,val)=>acc*val,1) //24
此处通过fns.reverse()反转函数数组,(acc, fn) => fn(acc)以传入的acc为参数依次调用每一个函数。累加器的初始值是value变量,它作为函数的第一个输入。
上一节中,我们组合了一个函数用于计算给定字符串的单词数。
let splitIntoSpaces = (str) => str.split(" ")
let count = (array) => array.length;
const countWords = compose(count, splitIntoSpaces)
countWords("hello what's your name") // 4
假设我们想知道给定字符串的单词数是基数还是偶数,而我们已经有如下函数
let oddOrEven = (ip) => ip%2 == 0 ? "even" : "odd";
通过compose,将这三个函数组合起来
const oddOrEvenWords = compose(oddOrEven, count, splitIntoSpaces);
oddOrEvenWords("hello what's your name") // ["even"]7.4 管道/序列
compose的数据流是从右至左的,最右侧的函数会首先执行,将数据传递给下一个函数,以此类推...最左侧的函数最后执行。
而当我们进行“|”操作时,Unix命令的数据流总是从左至右的,本节中,我们将实现pipe,它和compose函数所做的事情相同,只不过交换了数据流方向。
管道/序列(pipeline/sequence):从左至右处理数据流的过程称为管道/序列。
7.4.1 实现pipe
pipe是compose的复制品,唯一修改的是数据流方向。
const pipe = (...fns) =>
(value) =>
reduce(fns, (acc, fn) => fn(acc), value)
此处没有像compose一样调用fns.reverse(),这意味着我们将按照原有顺序执行函数。
调用pipe函数。注意,我们改变了调用顺序,先splitIntoSpaces, 中count, 最后oddOrEven。
const oddOrEvenWords = pipe(splitIntoSpaces, count, oddOrEven);
oddOrEvenWords("hello what's your name") // ["even"]
7.5 组合的优势:结合律
函数式组合满足结合律:
compose(compose(f,g),h) == compose(f,compose(g,h))
看一下上一节的例子
//compose(compose(f,g),h)
const oddOrEvenWord1 = compose(compose(oddOrEven, count), splitIntoSpaces);
oddOrEvenWord1("hello what's your name") //["even"]
//compose(f,compose(g,h))
const oddOrEvenWord2 = compose(oddOrEven, compose(count, splitIntoSpaces));
oddOrEvenWord2("hello what's your name") //["even"]
真正的好处:把函数组合到各自所需的compose函数中,
let countWords = compose(count, splitIntoSpaces)
let oddOrEvenWords = compose(oddOrEven, countWords)
or
let countOddOrEven= compose(oddOrEven, count)
let oddOrEvenWords = compose(countOddOrEven, splitIntoSpaces)
第八章:函子
函子:用一种纯函数式的方式进行错误处理。
8.1.1 函子是容器
函子是一个实现了map(遍历每个对象值的时候生成一个新对象)的普通对象(在其他语言中可能是一个类)。简而言之,函子是一个持有值的容器,能够持有任何传给它值,并允许使用当前容器持有的值调用任何函数。
创建Container构造函数
const Container = function(val){
this.value = val;
}
不使用箭头函数的原因是箭头函数不具备内部方法Construct和prototype属性,所以不能用new来创建一个新对象。
应用Container
let testValue = new Container(3) //Container {value: 3}
let testObj = new Container({a:1}) //Container {value: {a: 1}}
let testArray = new Container([1,2]) //Container {value: [1,2]}
我们为Container创建一个of静态工具方法,用以代替new关键词使用
Container.of = function(value){
return new Container(value)
}
用of方法重写上面的代码
testValue = Container.of(3)
testObj = Container.of(3)
testArray = Container.of([1,2])
注意:Container也可以包含嵌套的 Container
Container.of(Container.of(33))
输出:
Container {
value: Container {
value: 33
}
}
8.1.2 函子实现了map方法
map方法允许我们使用当前Container持有的值调用任何函数。
即map函数从Container中取出值,将传入的函数作用于该值,再将结果放回Container。
Container.prototype.map = function(fn){
return Container.of(fn(this.value))
}
第十章:使用Generator
Generator是ES6中关于函数的新规范。它不是一种函数式编程技术,但它是函数的一部分。
10.1 异步代码及其问题(回调地狱)
同步VS异步
同步:函数执行时会阻塞调用者,并在执行完后返回结果。
异步:在执行时不会阻塞调用者,一旦执行完毕就会返回结果。
处理Ajax请求时就是在处理异步调用。
同步函数
let sync = () =>{
//一些操作
//返回数据
}
let sync2 = () =>{
//一些操作
//返回数据
}
let sync3 = () =>{
//一些操作
//返回数据
}
同步函数调用
result = sync()
result2 = sync2()
result3 = sync3()
异步函数
let async = (fn)=>{
//一些异步操作
//用异步操作调用回调
fn(/*结果数据*/)
}
let async2 = (fn)=>{
//一些异步操作
//用异步操作调用回调
fn(/*结果数据*/)
}
let async3 = (fn)=>{
//一些异步操作
//用异步操作调用回调
fn(/*结果数据*/)
}
异步函数调用
async(function(x){
async2(function(y){
async3(function(z){
...
})
})
})
10.2 Generator基础
Generator是ES6规范的一部分,被捆绑在语言层面。
10.2.1创建Generator
function* gen(){
return 'first generator';
}
gen()
返回一个Generator原始类型的实例

调用实例的next函数,从该Generator实例中获取值
gen().next()
输出:
{value: "first generator", done: true}
gen().next().value
输出:
"first generator"
10.2.2 Generator的注意事项
一:不能无限制地调用next从Generator中取值
let genResult = gen()
//第一次调用
genResult.next().value
输出:"first generator"
//第二次调用
genResult.next().value
输出:undefined
原因是Generator如同序列,一旦序列中的值被消费,你就不能再次消费它。
本例中,genResult是一个带有"first generator"值的序列,第一次调用next后,我们就已经从序列中消费了该值。
由于序列已为空,第二次调用它就会返回undefined。
为了能够再次消费该序列,方法是创建另一个Generator实例
let genResult = gen()
let genResult2 = gen()
//第一个序列
genResult.next().value
输出:"first generator"
//第二个序列
genResult2.next().value
输出:"first generator"
10.3.2 yield关键词
来看一个简单的Generator序列
function* generatorSequence(){
yield 'first';
yield 'second';
yield 'third';
}
创建实例并调用
let genSequence = generatorSequence();
genSequence.next().value //"first"
genSequence.next().value //"second"
genSequence.next().value //"third"
yield让Generator惰性的生成一个值的序列。(直到调用才会执行)
yield使Generator函数暂停了执行并将结果返回给调用者,并且它还准确地记住了暂停的位置。下一次调用时就从中断的地方恢复执行。
10.2.4 done属性
done是一个判断Generator序列已经被完全消费的属性。当done为true时就应该停止调用Generator实例的next。
let genSequence = generatorSequence();
genSequence.next() //{value: "first", done: false}
genSequence.next() //{value: "second", done: false}
genSequence.next() //{value: "third", done: false}
genSequence.next() //{value: undefined, done: true}
下面的for...of循环用于遍历Generator
function* generatorSequence(){
yield 'first';
yield 'second';
yield 'third';
}
for(let value of generatorSequence()){
console.log(value) //first second third
}
10.2.5 向Generator传递数据
function* sayFullName(){
var firstName = yield;
var secondName = yield;
console.log(firstName+secondName)
}
let fullName = sayFullName();
fullName.next()
fullName.next('xiao ')
fullName.next('ming')
输出:xiao ming
分析:第一次调用fullName.next()时,代码将返回并暂停于var firstName = yield; 第二次调用yield被'xiao '替换,暂停在var secondName = yield;,第三次调用yield被'ming'替换,不再有yield。
10.3使用Generator处理异步调用
简单的异步函数
let getDataOne = (cb) => {
setTimeout(function(){
//调用函数
cb('dummy data one')
},1000)
}
let getDataTwo = (cb) => {
setTimeout(function(){
//调用函数
cb('dummy data two')
},1000)
}
调用
getDataOne((data)=>console.log(data)) //1000毫秒之后打印dummy data one
getDataTwo((data)=>console.log(data)) //1000毫秒之后打印dummy data two
下面改造getDataOne和getDataTwo函数,使其使用Generator实例而不是回调来传送数据
let generator;
let getDataOne = () => {
setTimeout(function(){
//调用Generator,通过next传递数据
generator.next('dummy data one')
},1000)
}
let getDataTwo = () => {
setTimeout(function(){
//调用Generator,通过next传递数据
generator.next('dummy data two')
},1000)
}
将getDataOne和getDataTwo调用封装到一个单独的Generator函数中
function* main(){
let dataOne = yield getDataOne();
let dataTwo = yield getDataTwo();
console.log(dataOne)
console.log(dataTwo)
}
用之前声明的generator变量为main创建一个Generator实例。该Generator实例被getDataOne和getDataTwo同时用于向其调用传递数据。generator.next()用于触发整个过程。main 函数开始执行,并遇到了第一个yield:let dataOne = yield getDataOne();
generator = main()
generator.next()
console.log("first be printed")
输出:
first be printed
1000毫秒之后打印
dummy data one
dummy data two
main代码看上去是在同步的调用getDataOne和getDataTwo,但其实两个调用都是异步的。
有一点需要注意:虽然yield使语句暂停了,但它不会让调用者阻塞。
generator.next() //虽然Generator为异步代码暂停了
console.log("first be printed") //console.log正常执行,说明generator.next不会阻塞执行