MapReduce几个小应用
上篇文章已经介绍了怎么去写一个简单的MR并且将其跑起来,学习一个东西动手还是很有必要的,接下来我们就举几个小demo来体验一下跑起来的快感。
demo链接请参照附件:http://files.cnblogs.com/files/wangkeustc/demo.tar.gz
排序:
问题:将sort_input文件夹下的多个文件中的数据按照从小到大排序
设计思路:shuffle阶段会将发送到reduce的数据自动排序,所以我们这边只要保证在每个partiton中数字都是按照从小到大来的,比如第一个分区时1-20000的整数,第二个分区时20000-40000等。
所以这个问题的解答,我们引入了一个新的概念,定义属于自己的Partition类
单表关联:
问题:请参考join_input中的文件输入格式,也就是根据文件中的child-parent关系,找出存在的grandchild-grandparent关系,比如Tom Jerry 和Jerry Mark ,那么我们可以得到Mark是Tom的grandparent。
涉及思路:类似于将这张表中的parent和自身中的child做join,mapper阶段我们可以根据Tom Jerry的关系输入两个key,分别对应<Tom,1 Jerry>,其中1表示是parent和<Jerry,2 Tom>。在Reducer中我们只要把每个key对应的parent和他的child找出来做个循环就可以得到所有结果了。
上面两个例子,大家可以仔细阅读以下代码,最好也手动敲一遍,仔细琢磨以下,因为接下来讲到的MapReduce的工作机制会与此相关。
MapReduce工作机制
MapReduce执行总流程
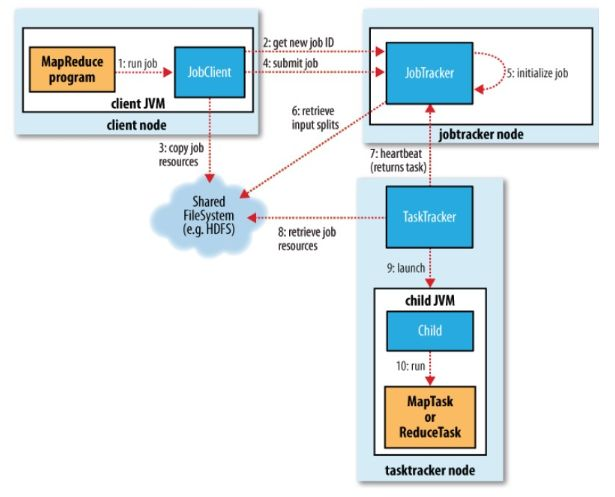
JobTracker:初始化作业,分配作业,与TaskManager通信,协调整个作业的执行
TaskTracker:保持与JobTracker的通信,执行map或者reduce任务
HDFS:保存作业的数据,配置信息等,保存作业结果。
具体相关流程
提交作业
客户端编写完程序代码后,打成jar,然后通过相关命令向集群提交自己想要跑的mr任务,具体过程如下:
- 通过调用JobTracker的getNewJobId()获取当前作业id
- 检查作业相关路径
- 计算作业的输入划分,并将划分信息写到Job.split文件中
- 将运行作业所需要的资源包括作业jar包,配置文件和甲酸所得的输入划分,复制到作业对应的HDFS上
- 调用JobTracker的summitJob()提交,告诉JobTracker作业准备执行
初始化作业
- 从HDFS中读取作业对应的job.split,得到输入数据的划分信息
- 创建并且初始化Map任务和Reduce任务:为每个map/reduce task生成一个TaskInProgress去监控和调度该task。
/** * Construct the splits, etc. This is invoked from an async * thread so that split-computation doesn't block anyone. */ public synchronized void initTasks() throws IOException, KillInterruptedException, UnknownHostException { if (tasksInited || isComplete()) { return; } ...... jobtracker.getInstrumentation().addWaitingMaps(getJobID(), numMapTasks); jobtracker.getInstrumentation().addWaitingReduces(getJobID(), numReduceTasks); this.queueMetrics.addWaitingMaps(getJobID(), numMapTasks); this.queueMetrics.addWaitingReduces(getJobID(), numReduceTasks); //根据numMapTasks任务数,创建MapTask的总数 maps = new TaskInProgress[numMapTasks]; for(int i=0; i < numMapTasks; ++i) { inputLength += splits[i].getInputDataLength(); maps[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf, this, i, numSlotsPerMap); } ...... // // Create reduce tasks //根据numReduceTasks,创建Reduce的Task数量 this.reduces = new TaskInProgress[numReduceTasks]; for (int i = 0; i < numReduceTasks; i++) { reduces[i] = new TaskInProgress(jobId, jobFile, numMapTasks, i, jobtracker, conf, this, numSlotsPerReduce); nonRunningReduces.add(reduces[i]); } ...... // create cleanup two cleanup tips, one map and one reduce. //创建2个clean up Task任务,1个是Map Clean-Up Task,一个是Reduce Clean-Up Task cleanup = new TaskInProgress[2]; // cleanup map tip. This map doesn't use any splits. Just assign an empty // split. TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT; cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks, 1); cleanup[0].setJobCleanupTask(); // cleanup reduce tip. cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks, jobtracker, conf, this, 1); cleanup[1].setJobCleanupTask(); // create two setup tips, one map and one reduce. //原理同上 setup = new TaskInProgress[2]; // setup map tip. This map doesn't use any split. Just assign an empty // split. setup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks + 1, 1); setup[0].setJobSetupTask(); // setup reduce tip. setup[1] = new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks + 1, jobtracker, conf, this, 1); setup[1].setJobSetupTask(); ......
- 上面的代码块提到的,创建两个初始化task,一个初始化Map,一个初始化Reduce
分配任务
JobTracker会将任务分配到TaskTracker去执行,但是怎么判断哪些TaskTracker,怎么分配任务呢?所以,我们要实现JobTracker和TaskTracker中的通信,也就是TaskTracker循环向JobTracker发送心跳,向上级报告自己这边是不是还活着,活干的怎么样了,可以接些新活等。作为JobTracker,接收到心跳信息,如果有待分配任务,就会给这个TaskTracker分配一个任务,然后taskTracker就把这个任务加入到他的任务队列中。我们可以主要看看TaskTracker中的transmitHeartBeart()和JobTracker的heartbeat()方法。
执行任务
TaskTracker申请到任务后,在本地执行,主要有以下几个步骤来完成本地的步骤化:
- 将job.split复制到本地
- 将job.jar复制到本地
- 将job的配置信息写入到Job.xml
- 创建本地任务目录,解压job.rar
- 调用launchTaskForJob()方法发布任务
发布任务后,TaskRunner会启动新的java虚拟机来运行每个任务,以map任务为例,流程如下:
- 配置任务执行参数(获取java程序的执行环境和配置参数等)
- 在child临时文件表中添加Map任务信息
- 配置log文件夹,配置Map任务的执行环境和配置参数;
- 根据input split,生成RecordReader读取数据
- 为Map任务生成MapRunnable,一次从RecordReader中接收数据,并调用map函数进行处理
- 将Map函数的输出调用collect收集到MapOUtputBuffer中