邻接表的构造与邻接矩阵完全不同,同学们应该发现了,邻接表的的结构更像是由几个链表构成的。
在构造邻接表时,我们的确会借助链表的结构。对图中每个顶点的信息,我们都会分别使用一个链表来进行存储。
因此,我们需要初始化一个有 n 个元素的链表数组,n 为图中顶点数量。
我们要在邻接表中存储的图的信息,实际上就是顶点之间存在的有向边。
当从顶点 a 到顶点 b 存在一条有向边时,我们只需要在头结点为 a 的链表后插入一个结点 b。
值得注意的是,当一条边是从顶点 b 到顶点 a 时,我们同样需要在以 b 为头结点的链表后插入一个结点 a。
同样在输出邻接表的时候,我们也只需要把每个链表依次遍历输出就好了。
示例代码如下(C++ 版):
const int MAX_N = 100;
vector<int> adj[MAX_N];
void insert(int u, int v) {
adj[u].push_back(v);
}
// 输出从 u 连出的所有边,顶点从 0 开始编号
for (int i = 0; i < adj[u].size(); ++i) {
cout << "(" << u << ", " << adj[u][i] << ")" << endl;
}
除了通过vector(或 Java 中的ArrayList)实现以外,还可以直接用数组模拟链表来实现邻接表结构(常数相比使用vector来说更小,运行效率更高):
今天终于知道图的邻接表怎么用数组实现了。之前都是直接vector。
const int MAX_N = 100;
const int MAX_M = 10000;
struct edge {
int v, next;
} e[MAX_M];
//存储边的索引
int p[MAX_N], eid;
void init() {
memset(p, -1, sizeof(p));
eid = 0;
}
void insert(int u, int v) {
e[eid].v = v;
// 节点u的上一条边的索引
e[eid].next = p[u];
p[u] = eid++;
}
// 输出从 u 连出的所有边,顶点从 0 开始编号
for (int i = p[u]; i != -1; i = e[i].next) {
cout << "(" << u << ", " << e[i].v << ")" << endl;
}
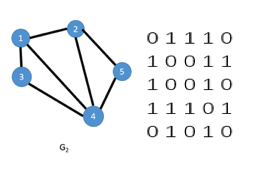
我们可以看到,邻接矩阵存储结构最大的优点就是简单直观,易于理解和实现。
其适用范围广泛,有向图、无向图、混合图、带权图等都可以直接用邻接矩阵表示。
另外,对于很多操作,比如获取顶点度数,判断某两点之间是否有连边等,都可以在常数时间内完成。
然而,它的缺点也是显而易见的:从以上的例子我们可以看出,对于一个有 n 个顶点的图,邻接矩阵总是需要 O(n*n) 的存储空间。
当边数很少的时候,就会造成空间的浪费。
因此,具体使用哪一种存储方式,要根据图的特点来决定:如果是稀疏图(点多边少),我们一般用邻接表来存储,这样可以节省空间;
如果是稠密图(点少边多),当需要频繁判断图中的两点之间是否存在边时往往用邻接矩阵来存储,其他时候用邻接表或邻接矩阵皆可。