一、索引以及切片
s = 'python24期' #下标(索引) s1 = s[0] #打印索引是0号的,出来的结果是p,类型是str print(s1,type(s1)) s2 = s[2] #索引是2的,出来的结果是t print(s2) s3 = s[8] #索引是8的,出来的结果是期 print(s3) s33 = s[-1] #-1是表示最后一个 print(s33)
二、切片 顾头不顾腚
# s[起始索引:'结尾索引+1':步长] s = 'python24期' print(s[:2]) #py print(s[:6]) #python print(s[:]) #python24期 print(s[:6:2]) #pto s3 = s[-1:-4:-1] #期42 print(s3)
三、常用方法:对字符串操作形成的都是新的字符串
1、capitalize()首字符大写,其他字母小写
s = 'oldBoy' s1 = s.capitalize() print(s1) #Oldboy print(s) #oldBoy
2、swapcase() 大小写反转 *
s = 'oldBoy' s2 = s.swapcase() #OLDbOY print(s2)
3、center 居中 设置宽度 *
s3 = s.center(20) s3 = s.center(20,'*') print(s3)
结果:

4、title() 非字母隔开的'单词'首字母大写 *
ss = 'alex wusir~b3a2taibai*ritian' s4 = ss.title() print(s4)
结果:

5、全大写 **
s = 'oldBoy' s5 = s.upper() print(s5)
6、lower() 全小写 **
s = 'oldBoy' s5 = s.lower() print(s5)
案例:模拟验证码登录
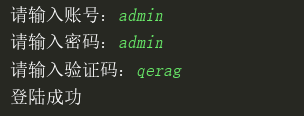
username = input('请输入账号:')
password = input('请输入密码:')
your_code = input('请输入验证码:').upper()
#print(your_code)
code = 'QerAg'.upper()
if username == 'admin' and password == 'admin':
if your_code == code:
print('登陆成功')
7、startswitch('o') 判断以什么开头 **
s = 'oldBoy'
s6 = s.startswith('o')
print(s6)
s61 = s.startswith('old')
print(s61)
s62 = s.startswith('oldBoy')
print(s62)
#返回结果都是True
8、endswith() 判断以什么结尾 **
s = 'oldBoy'
s63 = s.endswith('y',3)
print(s63)
#返回结果是True
9、strip() 默认去除str前后两端换行符、制表符、空格 ***
s = '
oldboy '
s7 = s.strip()
print(s7)
# 指定字符去除,
s = 'adsfadsfadskjkl;j'
print(s.strip('adflj')) #从左右两边挨个检查去除
结果:

10、lstrip() 只去除左边换行符、制表符、空格
s = ' oldboy ' s71 = s.lstrip() print(s71)
11、rstrip() 只去除右边换行符、制表符、空格
s = ' oldboy ' s72 = s.rstrip() print(s72)
案例:模拟用户登录,防止用户在前面或者后面加空格
username = input('请输入账号:').strip()
password = input('请输入密码:').strip()
if username == 'admin' and password == 'admin':
print('登陆成功')
12、split() str ---> list ***
s = 'alex wusir barry'
ss = 'alex,wusir,barry'
ss1 = ',alex,wusir,barry'
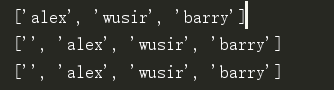
s8 = s.split() #默认按照空格分割
print(s8)
s9 = ss1.split(',') #按照逗号分割
print(s9)
print(ss1.split(',')) # 按照逗号分割,只要有逗号,就分割
# # 从前往后依次分割
s = 'alex wusir barry'
ss = 'alex,wusir,barry'
ss1 = ',alex,wusir,barry'
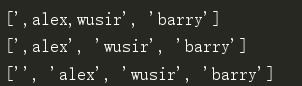
print(ss1.split(',',1)) # 前面第一个逗号分割的是一段,后面的是一段
print(ss1.split(',',2))
print(ss1.split(',',3))

# # 从后往前依次分割
s = 'alex wusir barry'
ss = 'alex,wusir,barry'
ss1 = ',alex,wusir,barry'
print(ss1.rsplit(',',1)) # 最后一个逗号分割的字符串是一段,前面的是一段
print(ss1.rsplit(',',2))
print(ss1.rsplit(',',3))
13、join ***
s = 'oldboy' s10 = '_'.join(s) #每隔一个字母中间都增加一个自定义的符号 s101 = 'alex'.join(s) print(s10) print(s101)

# 一个用途 list -----> str l1 = ['alex','wusir','bary'] # ---> s = 'alex wusir barry' s10 = ' _'.join(l1) print(s10)
14、replace *** 替换
s = '老男孩 老男孩 alex linux python 大数据 alex'
s11 = s.replace('alex','太白') #把所有alex的更好为太白
s12 = s.replace('alex','太白',1) #只更换1个,从左到右
print(s11)
print(s12)

15、is 系列 ***
name = '123' print(name.isalnum()) #字符串由字母或者数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isdigit()) #字符串只由数字组成 str ---> int 可以判断你输入的到底是不是数字

16、格式化输出 format ***
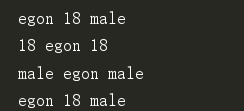
res = '{} {} {}'.format('egon',18,'male') # 根据顺序依次输出
print(res)
res1 = '{1} {0} {1}'.format('egon',18,'male') #根据索引进行格式化输出 0=18 1=egon 2=male
print(res1)
res11 = '{2} {0} {2}'.format('egon',18,'male') #根据索引进行格式化输出 0=18 1=egon 2=male
print(res11)
res2 = '{name} {age} {sex}'.format(sex='male',name='egon',age=18) #根据前面做对应
print(res2)
17、find 通过元素找索引,找不到返回-1 ***
s = 'oldboy'
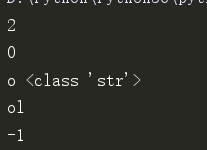
print(s.find('d')) #d的索引是2
print(s.find('o')) #o的索引是第0和5 但是默认找到一个就返回 。#当然这个还可以做切片.再研究。
print(s[-2],type(s[-2]))
print(s[:2])
print(s.find('A')) #没有A 所以返回-1
18、index 通过元素找索引,找不到报错 ***
s = 'oldboy'
print(s.index('d')) #d的索引是2
print(s.index('A')) #找不到就报错

公共方法:
19、len 测量个数
s = '''asdfadsfadsfadsfadsfadsfasd''' #len 测量个数 print(len(s))

20、count 某个元素出现的次数
s = '''asdfadsfadsfadsfadsfadsfasd'''
print(s.count('f')) #f出现了6次
