RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
Abstract
我们提出了RepMLP,一个多层感知器风格的图像识别神经网络构建块,它由一系列全连接(FC)层组成。与卷积层相比,FC层更高效,更善于构建长期依赖关系和位置模式,但在捕获局部结构方面较差,因此通常不太适合用于图像识别。我们提出了一种结构重参数化(structural re-parameterization)技术,将局部先验加入到FC中,使其具有强大的图像识别能力。具体来说,我们在训练期间在RepMLP中构建卷积层,并将它们合并到FC中进行推理。在CIFAR上,一个简单的纯MLP模型显示了非常接近CNN的性能。通过在传统CNN中插入RepMLP,我们将ResNets在ImageNet上的准确率提高了1.8%,在人脸识别上提高了2.9%,在Cityscapes上提高了2.3%,且有着更低的FLOPs。我们有趣的发现强调,将FC的全局表征能力和位置感知与卷积的局部先验相结合,可以以更快的速度提高神经网络在具有平移不变性(例如,语义分割)和有着对齐图像和位置模式(例如,人脸识别)的任务的性能。代码可见https://github.com/DingXiaoH/RepMLP。
1. Introduction
图像的局部性(即相对于远距离的像素,一个像素与其临近像素相关性更强)造就了卷积神经网络(Convolutional Neural Network, ConvNet)在图像识别中的成功。在本文中,我们将这种归纳偏差称为局部先验(local prior)。
除此之外,我们还希望能够捕获长期依赖关系,这在本文中称为全局能力(global capacity)。传统的卷积神经网络通过深层的卷积神经层[25]形成的大的接收域来构建远程依赖。然而,重复的局部操作在计算上是低效的,可能会导致优化困难。之前的一些研究通过基于自注意力的模块增强了global capacity[25,11,23],但没有local prior。例如,ViT[11]是一个没有卷积的pure-Transformer模型,它将图像以序列的形式输入到Transformers中。由于缺少local prior这一重要的归纳偏差,ViT需要大量的训练数据(JFT-300M的3 × 108幅图像)来收敛。
另一方面,一些图像具有固有的位置先验,由于不同位置之间的参数是共享的,因此不能被一个卷积层有效利用。例如,当某人试图通过面部识别解锁手机时,脸部照片很可能位于中间,眼睛在上面,鼻子在中间。我们把利用位置先验的能力称为位置感知(positional perception)。
本文重新讨论了全连接(FC)层,为传统的ConvNet提供global capacity和positional perception。在某些情况下,我们直接使用FC代替卷积层来作为特征映射之间的转换。通过扁平化特征map,将其输入FC,然后重新调整大小,我们就可以享受positional perception(因为它的参数与位置相关)和global capacity(因为每个输出点与每个输入点相关)。无论从实际速度还是理论FLOPs来看,这种运算都是高效的,如表4所示。对于主要关注点是准确度和吞吐量而不是参数数量的应用场景,人们可能更喜欢基于FC的模型而不是传统的ConvNets。例如,GPU推断通常有几十GBs的内存,因此与计算和内部特征maps所消耗的内存相比,参数所占用的内存很小。
但是,由于空间信息丢失,FC没有local prior。在本文中,我们提出了一种structural re-parameterization技术,将local prior加入到FC中。具体而言,我们在训练过程中构造平行于FC的conv和batch normalization (BN)[15]层,然后将训练后的参数合并到FC中,以减少参数的数量和推理延迟。在此基础上,我们提出了一种重参数化的多层感知器(RepMLP)。如图1所示,训练时间RepMLP有FC层、conv层和BN层,但可以等效转换为只有三个FC层的推理时的块。structural re-parameterization的意义在于训练时间模型有一组参数,推理时模型有另一组参数,我们将训练时模型的参数转化为推理时模型的参数。注意,我们不会在每次推理之前推导参数。相反,我们一次性地转换它,然后就可以丢弃训练时的模型。

与conv相比,RepMLP在相同数量的参数下运行得更快,并且具有global capacity和positional perception。与自注意力模块相比[25,11],它更简单且可以利用图像的局部性。实验结果表明(表4,5,6),RepMLP在各种视觉任务,包括1)一般分类任务(如ImageNet[8])、2)带有位置先验的任务(如人脸识别)和3)平移不变任务(如语义分割)中均优于传统的卷积神经网络。
我们的贡献总结如下。
- 我们提出利用FC的global capacity和positional perception,并配备local prior进行图像识别。
- 我们提出了一个简单的、平台无关的、可微的算法来将并行的conv和BN合并到FC中,而无需任何推理时间开销。
- 我们提出了RepMLP,一个高效的构建模块,并展示了它在多视觉任务上的有效性。
2.Related Work
2.1. Designs for Global Capacity
non-local网络[25]通过自注意力机制对远距离依赖进行建模。对于每个查询位置,non-local模块首先计算查询位置与所有位置的成对关系,形成注意力map,然后将所有位置的特征与注意力map中定义的权重进行加权和。然后将聚合特征添加到每个查询位置的特征中。
GCNet[1]创建了一个基于查询无关公式的简化网络,在保持non-local网络的准确性的同时,减少了计算量。GC块的输入经过全局注意池化、特征转换(1 × 1 conv)和特征聚合。
与这些工作相比,RepMLP更简单,因为它不使用自注意力,并且只包含三个FC层。如表4所示,与比Non-local模块和GC块相比,RepMLP提高了更多的ResNet-50性能。
2.2. Structural Re-parameterization
在本文中,structural re-parameterization是指构造平行于FC的conv层和BN层进行训练,然后将参数合并到FC中进行推理。下面的两项工作也可以归类为structural re-parameterization。
非对称卷积块(Asymmetric Convolution Block,ACB)[9]是常规卷积层的替代,它使用水平(如1 × 3)和垂直(3 × 1)卷积来加强正方形(3 × 3)卷积的“skeleton”。在几个卷积网络基准测试中报告了合理的性能改进。
RepVGG[10]是一个类似于vgg的架构,因为它的主体只使用3 × 3的conv和ReLU进行推理。该推理时间体系结构由具有恒等和1 × 1分支的训练时间体系结构转化而来。
RepMLP与ACB的关系更密切,因为它们都是神经网络构建块,但我们的贡献不是让卷积更强,而是让MLP在图像识别方面更强大,作为常规conv的替代。此外,RepMLP内部的训练时的卷积可能会由ACB、RepVGG块、或者其他形式的卷积来做进一步的改进。
3. RepMLP
训练时的RepMLP由三个部分组成,分别是Global Perceptron, Partition Perceptron and Local Perceptron(图1)。在本节中,我们介绍我们的公式,描述每个组件,并展示如何将训练时的RepMLP转换为三个FC层进行推理,其中的关键是一个简单的,平台无关且可微的方法,用于合并一个conv到一个FC。
3.1. Formulation
在本文中,特征map被表示为一个张量![]()
![]() ,其中N是batch size,C是channels的数量,H和W是高和宽。我们使用F和W分别表示卷积和FC的核。为了简化和更易于复现,我们使用如PyTorch[20]的相同的数据格式,使用伪代码表示转换过程。比如,经过K x K卷积的数据流表示为:
,其中N是batch size,C是channels的数量,H和W是高和宽。我们使用F和W分别表示卷积和FC的核。为了简化和更易于复现,我们使用如PyTorch[20]的相同的数据格式,使用伪代码表示转换过程。比如,经过K x K卷积的数据流表示为:

其中![]() 是输出特征map,
是输出特征map,![]() 是输出channels的数量,p是用来填补的像素数量,
是输出channels的数量,p是用来填补的像素数量,![]() 是卷积核(我们假设卷积是密集的,即groups的数量为1)。从现在开始,为了简化我们假设
是卷积核(我们假设卷积是密集的,即groups的数量为1)。从现在开始,为了简化我们假设![]() (步长为1,
(步长为1,![]() )
)
对于FC,P和Q为输入和输出维度,![]() 和
和![]() 分别是输入和输出,核为
分别是输入和输出,核为![]() 且矩阵乘法(MMUL)表示为:
且矩阵乘法(MMUL)表示为:
![]()
我们现在关注以![]() 为输入、以
为输入、以![]() 为输出的FC。假设FC没有改变分辨率,即
为输出的FC。假设FC没有改变分辨率,即![]() 。我们使用RS(“reshape”的简称)作为只改变张量形状规格,而不改变数据在内存中的顺序的函数,这是免费的。输入首先被flatten为长度为CHW的N个向量,
。我们使用RS(“reshape”的简称)作为只改变张量形状规格,而不改变数据在内存中的顺序的函数,这是免费的。输入首先被flatten为长度为CHW的N个向量,![]() ,乘以核
,乘以核![]() ,然后输出
,然后输出![]() ,再将其大小转变为
,再将其大小转变为![]() 。为了可读性,在没有歧义的情况下,省略RS:
。为了可读性,在没有歧义的情况下,省略RS:
![]()
这样的FC不能利用图像的局部性,因为它根据每个输入点计算每个输出点,而不知道位置信息。
3.2. Components of RepMLP
我们不以上面的方式去使用FC,因为其不仅缺少了local prior,还有大量的参数(![]() )。常见设置中,ImageNet中是
)。常见设置中,ImageNet中是![]() ,该单个FC就有10G个参数,这是不能接受的。为了减少参数,我们提出了Global Perceptron和Partition Perceptron去分开构建内和外分区依赖(inter- and intra-partition dependencies)。
,该单个FC就有10G个参数,这是不能接受的。为了减少参数,我们提出了Global Perceptron和Partition Perceptron去分开构建内和外分区依赖(inter- and intra-partition dependencies)。
Global Perceptron 将特征map分割,这样不同的分区就能共享参数。比如,![]() 大小的输入可以分成
大小的输入可以分成![]() ,我们将每个7x7的块称为分区(partition)。我们为该分隔使用一种高效的实现方法,即内存重安排的简单操作。让h和w表示每个分区所期望的高和宽(假设H和W能分别被h和w整除,否则就简单地对输入进行填补(pad)),输入
,我们将每个7x7的块称为分区(partition)。我们为该分隔使用一种高效的实现方法,即内存重安排的简单操作。让h和w表示每个分区所期望的高和宽(假设H和W能分别被h和w整除,否则就简单地对输入进行填补(pad)),输入![]() 首先被重置大小为
首先被重置大小为![]() 。注意该操作是免费的,因为内存没有移动数据。然后重新安排轴的顺序为
。注意该操作是免费的,因为内存没有移动数据。然后重新安排轴的顺序为![]() ,这里高效地移动了内存中的数据。在PyTorch中仅需要调用一个函数(permute)。然后
,这里高效地移动了内存中的数据。在PyTorch中仅需要调用一个函数(permute)。然后![]() 张量被重置大小为
张量被重置大小为![]() (在图1中被标志为partition map),这个过程也是免费的。在这里,参数数量从
(在图1中被标志为partition map),这个过程也是免费的。在这里,参数数量从![]() 减少到了
减少到了![]()
但是,分割打破了同一channel的不同分区之间的相关性。换句话说,模型将单独查看分区,完全不知道它们是并排放置的。为了将相关性添加到每个分区上,Global Perceptron 1)使用平均池化为每个分区获取一个像素,2)将其输入BN和一个两层MLP,然后3)重置大小并将其添加到partition map上。该附加操作能够通过自动传播高效实现(即隐式地将![]() 复制到
复制到![]() ),这样每个像素就会和别的分区相关了。然后partition map将被输入Partition Perceptron 和Local Perceptron。注意如果
),这样每个像素就会和别的分区相关了。然后partition map将被输入Partition Perceptron 和Local Perceptron。注意如果![]() ,我们直接将特征map输入Perceptron 和Local Perceptron,而不进行分割,因此这里就不需要Global Perceptron了。
,我们直接将特征map输入Perceptron 和Local Perceptron,而不进行分割,因此这里就不需要Global Perceptron了。
Partition Perceptron 有一个FC和一个BN层,以partition map作为输入。输出![]() 以和上面相反的顺序进行reshaped, re-arranged和reshaped来变为
以和上面相反的顺序进行reshaped, re-arranged和reshaped来变为![]() 。我们受groupwise conv [5, 26]启发,进一步减少FC3的参数。g表示groups的数量,表示groupwise conv为:
。我们受groupwise conv [5, 26]启发,进一步减少FC3的参数。g表示groups的数量,表示groupwise conv为:
![]()
相似地,groupwise FC的核是![]() ,其中有g倍的参数。虽然groupwise FC不直接被想PyTorch的计算框架支持,但其可以使用groupwise 1x1卷积来等价替换。该实现由3步组成:1)重置
,其中有g倍的参数。虽然groupwise FC不直接被想PyTorch的计算框架支持,但其可以使用groupwise 1x1卷积来等价替换。该实现由3步组成:1)重置![]() 为空间大小为1x1的“特征map”; 2)实现g个组的1x1卷积; 3)重置输出“特征map”为
为空间大小为1x1的“特征map”; 2)实现g个组的1x1卷积; 3)重置输出“特征map”为![]() 。我们表示groupwise矩阵乘法(gMMUL)为:
。我们表示groupwise矩阵乘法(gMMUL)为:

Local Perceptron 将partition map输入到几个卷积层中。受[9,10]启发,这里每个卷积层后跟着一个BN层。图1展示了一个![]() 且
且![]() 的例子。理论上,对核大小的唯一限制是
的例子。理论上,对核大小的唯一限制是![]() (因为使用大于分辨率的核是没有意义的),但是在ConvNet的常见实现中我们仅设置奇数核大小。为了简化,我们标注时使用了K x K,实际上非方形的卷积也是可以的(如1x3,3x1)。卷积的padding用于保持分辨率(即
(因为使用大于分辨率的核是没有意义的),但是在ConvNet的常见实现中我们仅设置奇数核大小。为了简化,我们标注时使用了K x K,实际上非方形的卷积也是可以的(如1x3,3x1)。卷积的padding用于保持分辨率(即![]() ),且组的数量g应该和Partition Perceptron一样。所有卷积分支和Partition Perceptron的输出将加在一起作为最后的输出。
),且组的数量g应该和Partition Perceptron一样。所有卷积分支和Partition Perceptron的输出将加在一起作为最后的输出。
3.3. A Simple, Platform-agnostic, Differentiable Algorithm for Merging Conv into FC
在将一个RepMLP转换成一个三层FC层前,我们首先展示如何将一个conv合并到FC。FC核为![]() 、卷积核为
、卷积核为![]()
![]() 且padding为p,我们期望构建
且padding为p,我们期望构建![]() 为:
为:
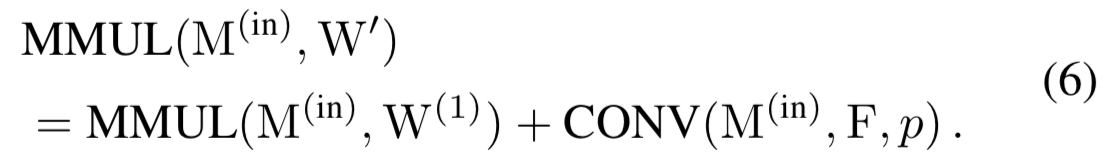
我们注意到对于与![]() 有着相同大小的任意核
有着相同大小的任意核![]() ,MMUL的可加性保证了:
,MMUL的可加性保证了:

所以只要我们能构造和![]() 有一样大小的
有一样大小的![]() ,且满足下面的式子,这样就可以将
,且满足下面的式子,这样就可以将![]() 合并到
合并到![]() :
:
![]()
很明显,![]() 肯定存在,因为一个卷积可以看作是一个在空间位置中共享参数的稀疏FC,这也是其平移不变性的恶原理,但是怎么使用给定的
肯定存在,因为一个卷积可以看作是一个在空间位置中共享参数的稀疏FC,这也是其平移不变性的恶原理,但是怎么使用给定的![]() 和p去构建它就没有那么显而易见了。因为当前计算平台使用不同的卷积算法(im2col-[2], Winograd- [17], FFT-[18], MEC-[4], and sliding-window-based)且数据内存分配和padding实现都有所不同,在某个特定平台构建矩阵的方法可能在另一个平台不适用。在本文中,我们提出一个简单且平台无关的解决方案。
和p去构建它就没有那么显而易见了。因为当前计算平台使用不同的卷积算法(im2col-[2], Winograd- [17], FFT-[18], MEC-[4], and sliding-window-based)且数据内存分配和padding实现都有所不同,在某个特定平台构建矩阵的方法可能在另一个平台不适用。在本文中,我们提出一个简单且平台无关的解决方案。
如上所述,对于任意![]() 、conv核
、conv核![]() 和padding p,存在一个FC核
和padding p,存在一个FC核![]() 为:
为:

使用等式2的公式,我们有:
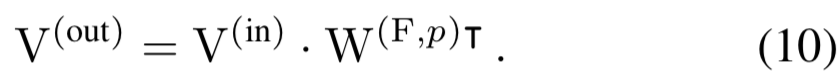
插入一个单位矩阵![]() 并使用结合律:
并使用结合律:
![]()
我们注意到因为![]() 是由
是由![]() 构建的,
构建的,![]() 是与F在特征映射
是与F在特征映射![]() 上的卷积,该特征映射
上的卷积,该特征映射![]() 由
由![]() 重置大小而来。带有显式的RS,式子为:
重置大小而来。带有显式的RS,式子为:
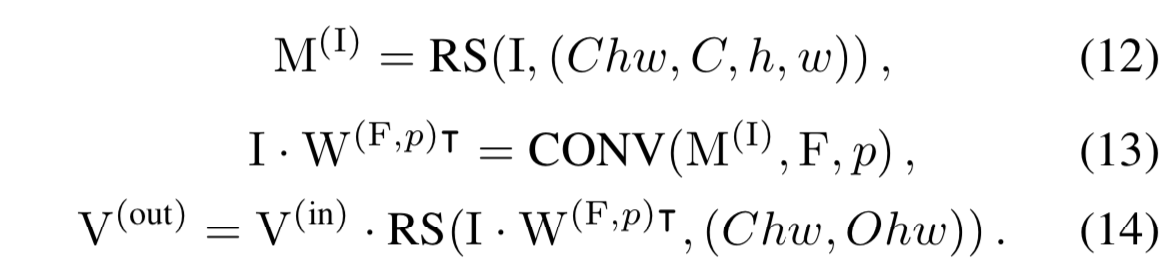
将等式10与等式13和14相比,得到:
![]()
代码实现:


def _convert_conv_to_fc(self, conv_kernel, conv_bias): #等式(15) #等式(12) I = torch.eye(self.C * self.h * self.w // self.fc3_groups).repeat(1, self.fc3_groups).reshape(self.C * self.h * self.w // self.fc3_groups, self.C, self.h, self.w).to(conv_kernel.device) fc_k = F.conv2d(I, conv_kernel, padding=conv_kernel.size(2)//2, groups=self.fc3_groups) fc_k = fc_k.reshape(self.O * self.h * self.w // self.fc3_groups, self.C * self.h * self.w).t() fc_bias = conv_bias.repeat_interleave(self.h * self.w) return fc_k, fc_bias
这就是我们使用卷积核![]() 和padding p来构建
和padding p来构建![]() 的方法。简而言之,卷积核的等效FC核是对单位矩阵进行适当重置大小后的卷积结果。更好的是,转换是有效且可微的,所以可以在训练期间派生FC内核并将其用于目标函数(例如,基于惩罚的pruning[13,19])。groupwise情况的表达式和代码以类似的方式导出,并在补充材料中提供。
的方法。简而言之,卷积核的等效FC核是对单位矩阵进行适当重置大小后的卷积结果。更好的是,转换是有效且可微的,所以可以在训练期间派生FC内核并将其用于目标函数(例如,基于惩罚的pruning[13,19])。groupwise情况的表达式和代码以类似的方式导出,并在补充材料中提供。
3.4. Converting RepMLP into Three FC Layers
(这里讲的是怎么讲卷积层和BN层融合在一起,然后再用上面的等式(15)将卷积核转成FC核,实现Conv+BN -> FC)
为了使用上面提出的理论,我们首先需要通过等价融合BN层到前面的卷积层和FC3中来移除它。![]() 表示卷积核,
表示卷积核,![]() 是BN累积的均值、标准差、可学习的scaling因子和bias,构造核
是BN累积的均值、标准差、可学习的scaling因子和bias,构造核![]() 和bias
和bias ![]() 为:
为:
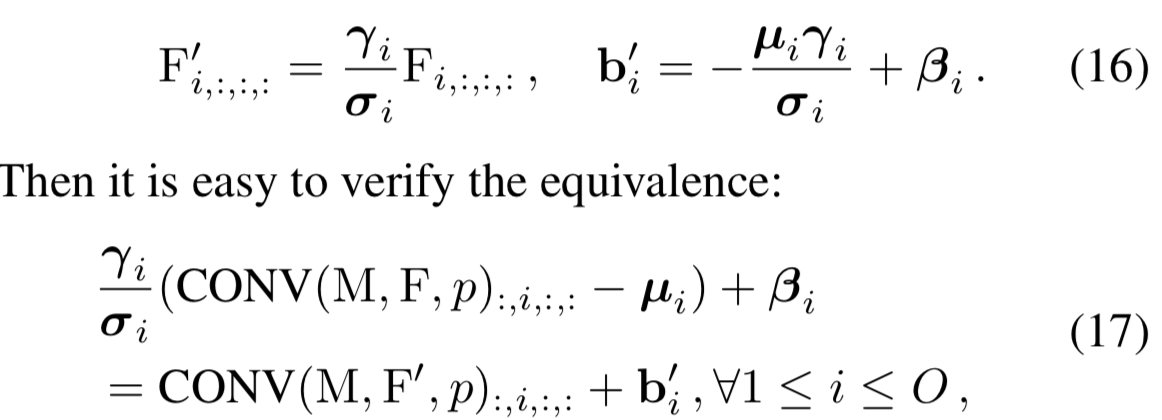
左边是conv-BN的原始计算流,右边则是构造后带有bias的卷积
代码实现:
def fuse_bn(conv_or_fc, bn): std = (bn.running_var + bn.eps).sqrt() t = bn.weight / std if conv_or_fc.weight.ndim == 4: t = t.reshape(-1, 1, 1, 1) else: t = t.reshape(-1, 1) return conv_or_fc.weight * t, bn.bias - bn.running_mean * bn.weight / std #等式(17) class ConvBN(nn.Module): ... def switch_to_deploy(self): kernel, bias = fuse_bn(self.conv, self.bn) conv = nn.Conv2d(in_channels=self.conv.in_channels, out_channels=self.conv.out_channels, kernel_size=self.conv.kernel_size, stride=self.conv.stride, padding=self.conv.padding, groups=self.conv.groups, bias=True) conv.weight.data = kernel conv.bias.data = bias self.__delattr__('conv') #就是switch后,把以前的删除 self.__delattr__('bn') self.conv = conv
Partition Perceptron中的一维BN和FC3也以相似的方式融合为![]() 。然后我们使用等式15转换所有卷积,然后将得到的结果矩阵添加到
。然后我们使用等式15转换所有卷积,然后将得到的结果矩阵添加到![]() 。卷积的bias就简单地复制hw倍(因为相同channel上的所有点共享一个bias),并添加到
。卷积的bias就简单地复制hw倍(因为相同channel上的所有点共享一个bias),并添加到![]() 。最后我们得到单个FC核和单个bias向量,然后用来参数化推理时的FC3。
。最后我们得到单个FC核和单个bias向量,然后用来参数化推理时的FC3。
Global Perceptron中的BN也被删除了,因为该删除等价于在FC1之前应用仿射变换,当两个序列的MMULs可以合并为一个时,FC1可以吸收这个仿射变换。计算公式和代码在补充资料中提供。

即:

(这个讲的是怎么将FC+BN -> FC)
4. Experiments
4.1. Pure MLP and Ablation Studies
我们首先通过在CIFAR-10上测试一个pure MLP模型来验证RepMLP的有效性。更准确地说,因为一个FC等价于一个1 × 1的conv,通过“pure MLP”我们意味着不使用大于1 × 1的conv核。我们交错RepMLP和FC(1×1 conv)去构建三个stages和使用最大池化实现下采样,如图2所示,并通过使用3×3 conv替换RepMLPs来构造一个用于比较的ConvNet对照组。在相当的FLOPs下,pure MLP三个stages的channels是16,32,64;ConvNet的则是32,64,128,因此,后者被称为wide ConvNet。我们采用标准的数据增强方法[14]:padding到40 × 40,随机裁剪,左右翻转。该模型的训练batch size为128个,cos学习率在100个epoch内从0.2退火到0。如表1所示,纯MLP模型达到91.11%的精度,只有52.8M的FLOPs。毫无疑问,纯MLP模型的性能并不优于Wide ConvNet,这促使我们将RepMLP和传统的ConvNet结合起来。

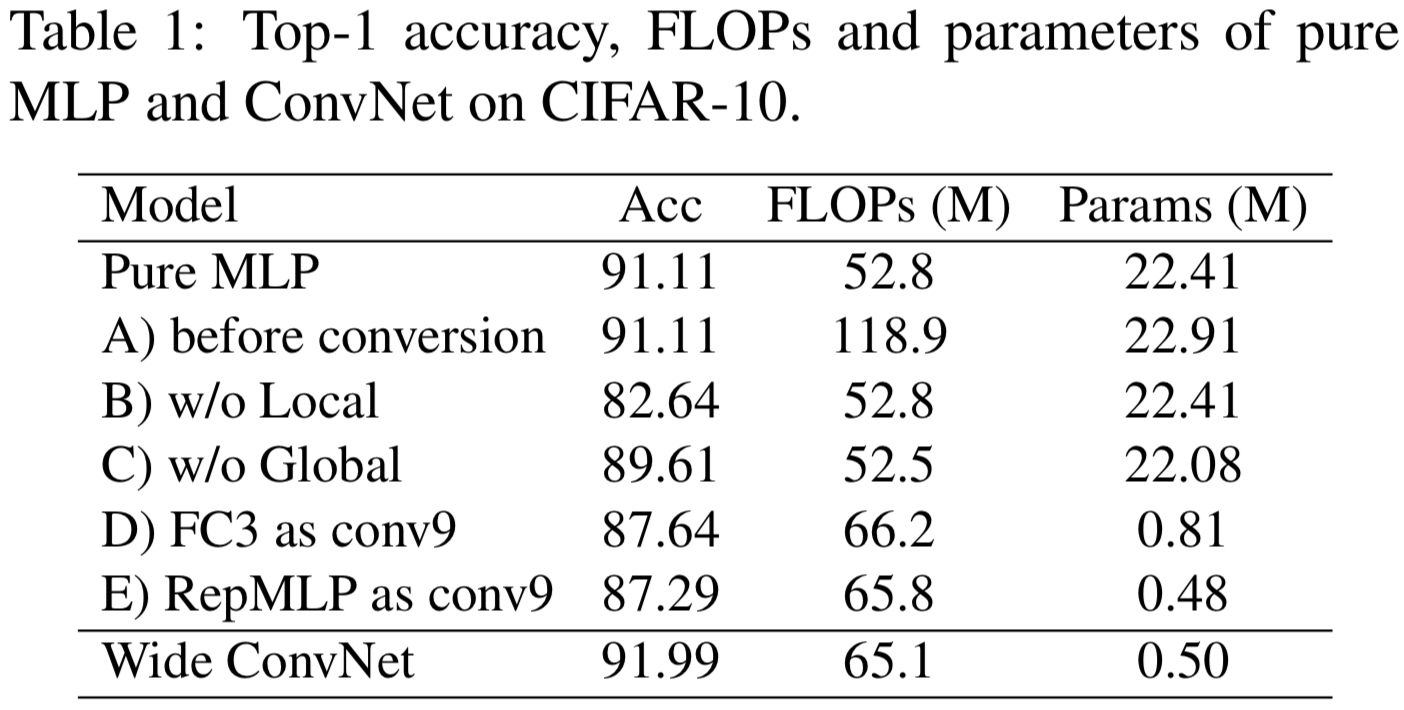
然后我们进行了一系列的消融研究。A)我们还报告了MLP在转换之前的FLOPs,它仍然包含conv层和BN层。虽然多出参数是很少的,但FLOPs却要高得多,这说明了structural re-parameterization的重要性。B)“w/o Local”是一个没有Local Perceptron的变体,准确率降低8.5%,说明了Local prior的重要性。C)“w/o Global”是删除FC1和FC2,并直接将partition map提供给Local Perceptron和partition Perceptron。D)“FC3 conv9”是使用一个conv(K = 9和p = 4,其感受域比FC3大)替换一个FC3,后面跟着BN,用来比较FC3和常规conv的表征能力。虽然比较偏向conv,因为它的接受域较大,但其精度低了3.5%,这验证了FC比conv更强大,因为conv是一个降级FC。E)“RepMLP as conv9”是直接用9 × 9的conv和BN代替RepMLP。与D相比,它的准确性较低,因为它没有Global Perceptrons。
4.2. RepMLP-ResNet for ImageNet Classification
我们以ResNet-50 [14] (torchvision版本[21])作为基础架构来评估作为传统ConvNet中的一个构建块的RepMLP。为了进行公平的比较,所有模型都在100个epochs内以相同的设置进行训练:在8个GPUs上的全局batch size为256,权重衰减为10−4,momentum为0.9,余弦学习率从0.1退火到0。我们使用mixup[27]和Autoaugment[7]的数据增强管道,随机裁剪和翻转。所有的模型都用单一的central crop进行评估,在相同的1080Ti GPU上测试速度,batch size为128,并以每秒几例进行速度测量。为了进行更公平的比较,对RepMLPs进行了转换,并对每个模型的所有原始conv-BN结构进行了转换,并对带有bias的conv层进行了转换,以便进行速度测试。
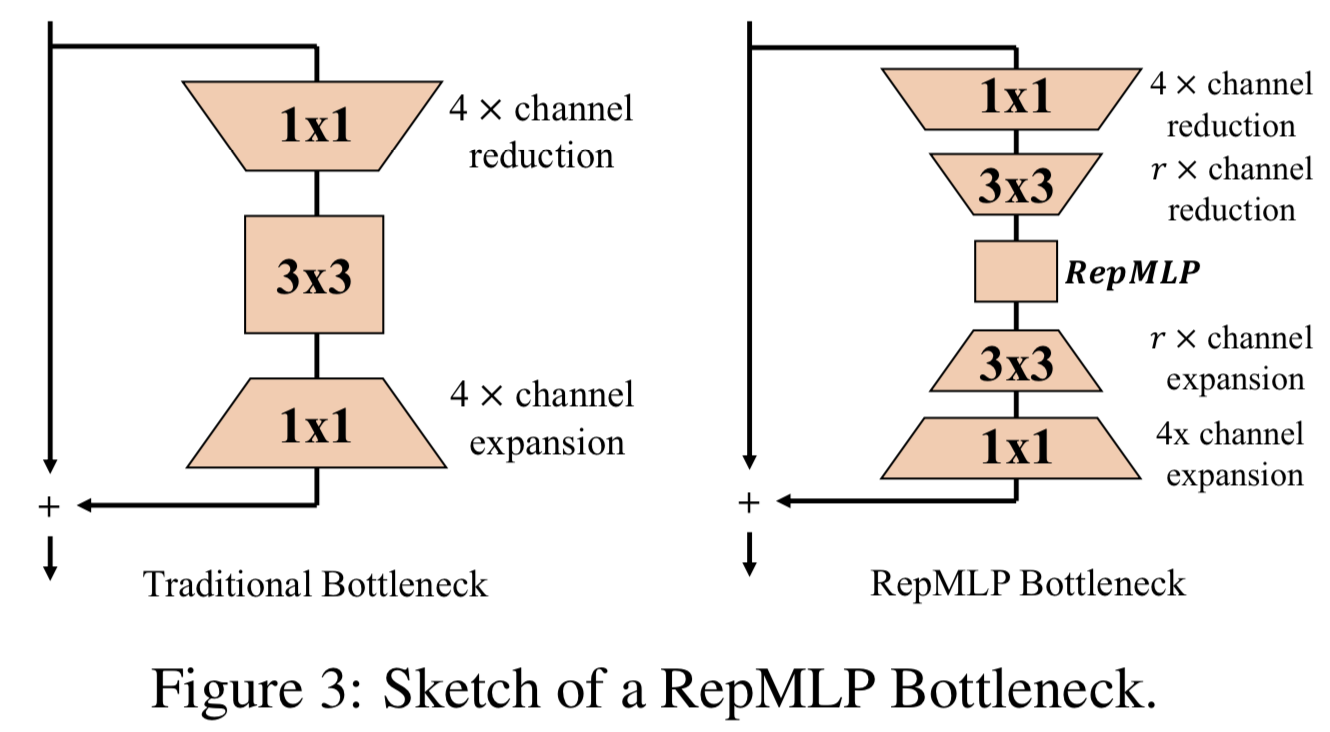
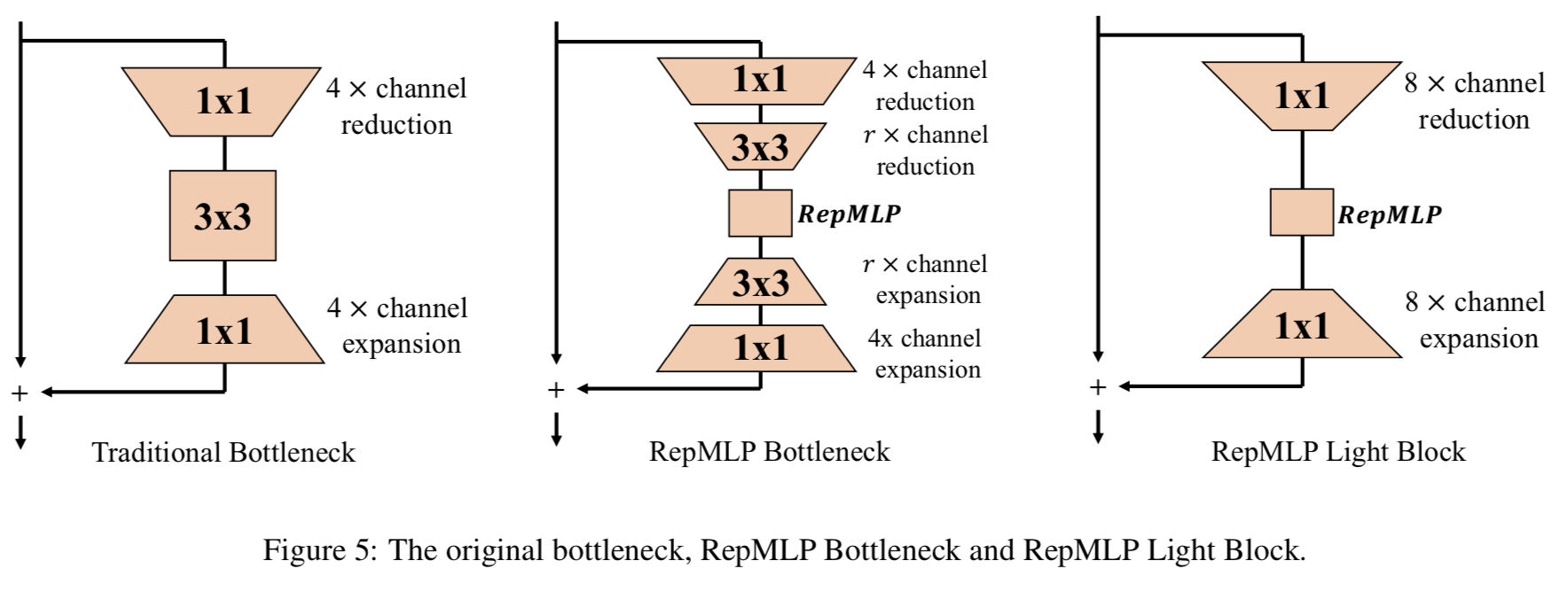
通常,我们将ResNet-50的四个残差阶段分别称为c2, c3, c4, c5。当输入为224 × 224时,4个stages的输出分辨率分别为56、28、14、7, 4个stages的3 × 3 conv层分别设置为C = O = 64、128、256、512。为了用RepMLP替换大3 × 3的conv层,我们使用h = w = 7和Local Perceptron中的三个K = 1,3,5的conv分支。我们在RepMLP前进行r倍通道减少,之后通过3 × 3的conv进行r倍通道扩展,进一步减少RepMLP的通道。整个block称为RepMLP Bottleneck(图3)。在一个特定的stage,我们将所有的stride-1 bottleneck替换为RepMLP Bottleneck,并保留原来的stride-2(即第一个)bottleneck。
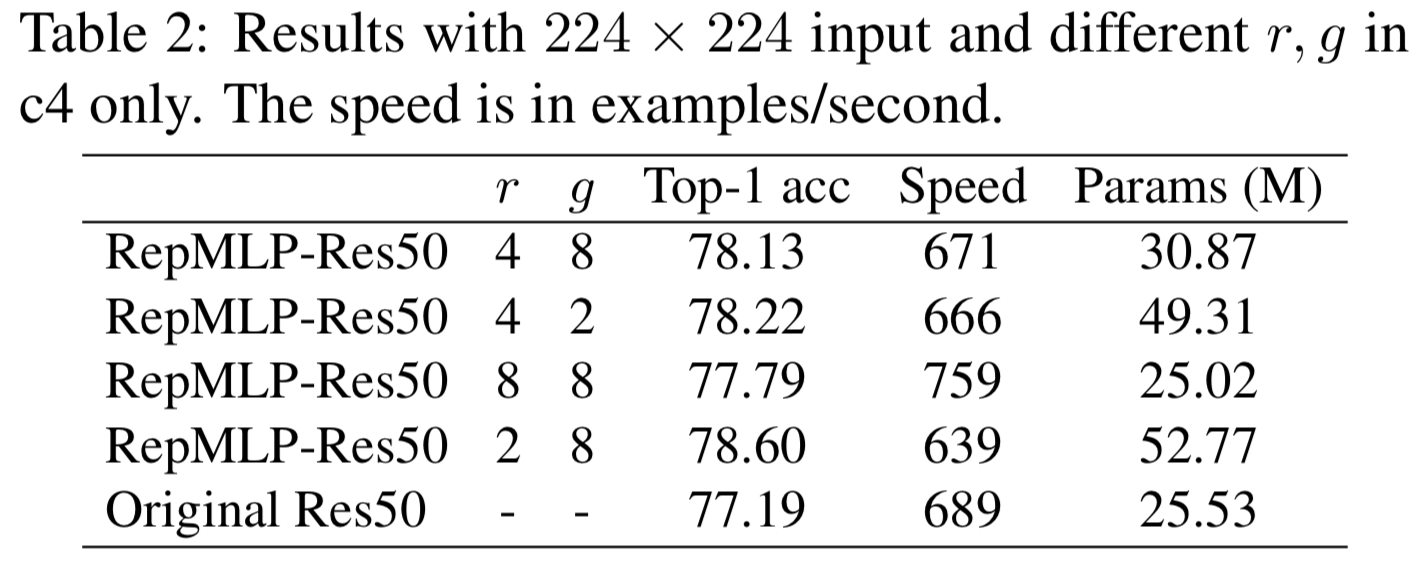
我们首先仅在c4使用RepMLP和变化超参数 r和g来测试他们如何影响准确度、速度和参数的数量(表2)。值得注意的是,通过8倍的reduction(这样RepMLP的输入和输出channels是256/8 = 32),RepMLP-Res50有更少的参数,运行比ResNet-50快10%。比较前两行可以发现,当前groupwise 1 × 1的conv是低效的,参数增加了59%,但速度只降低了0.7%。进一步对groupwise 1 × 1 conv进行优化可以使RepMLP更有效。在接下来的实验中,为了更好的权衡效果,我们用r=2 or 4和g=4 or 8。
我们继续在不同stages测试RepMLP。为了合理的模型尺寸,对c2,c3,c4,c5,我们分别设g = 8和r = 2,2,4,4。从表3中可以看出,用RepMLP Bottleneck替换原来的bottleneck会导致非常小的减速,但准确率会得到显著提高。仅在c4上使用RepMLP只增加了5M个参数,但准确率提高了0.94%,并且在c3和c4上使用RepMLP提供了最佳的折衷方案。它还建议RepMLP应与传统的conv结合以获得最佳性能,因为在所有四个stages中使用RepMLP的精度都低于c2+c3+c4和c3+c4。在接下来的实验中,我们在c3+c4中使用了RepMLP。

与具有更高输入分辨率的更大的传统卷积网络的比较(表4)进一步证明了RepMLP的有效性,并提供了一些有趣的发现。当使用320 × 320输入进行训练和测试时,我们使用了h = w = 10的RepMLP,并且Local Perceptron有4个分支K = 1,3,5,7。我们还改变组的数量来生成三个不同大小的模型。例如,g8/16表示c3 的g= 8, c4的g = 16。作为构建长距离依赖关系的两个经典模型,我们按照原始论文中的说明构造了Non-local[25]和GC[1]对照组,并且这些模型都使用相同的设置进行训练。我们还将著名的EfficientNet[22]系列作为一个强大的基线,再次使用相同的设置进行训练。我们有以下观察结果。
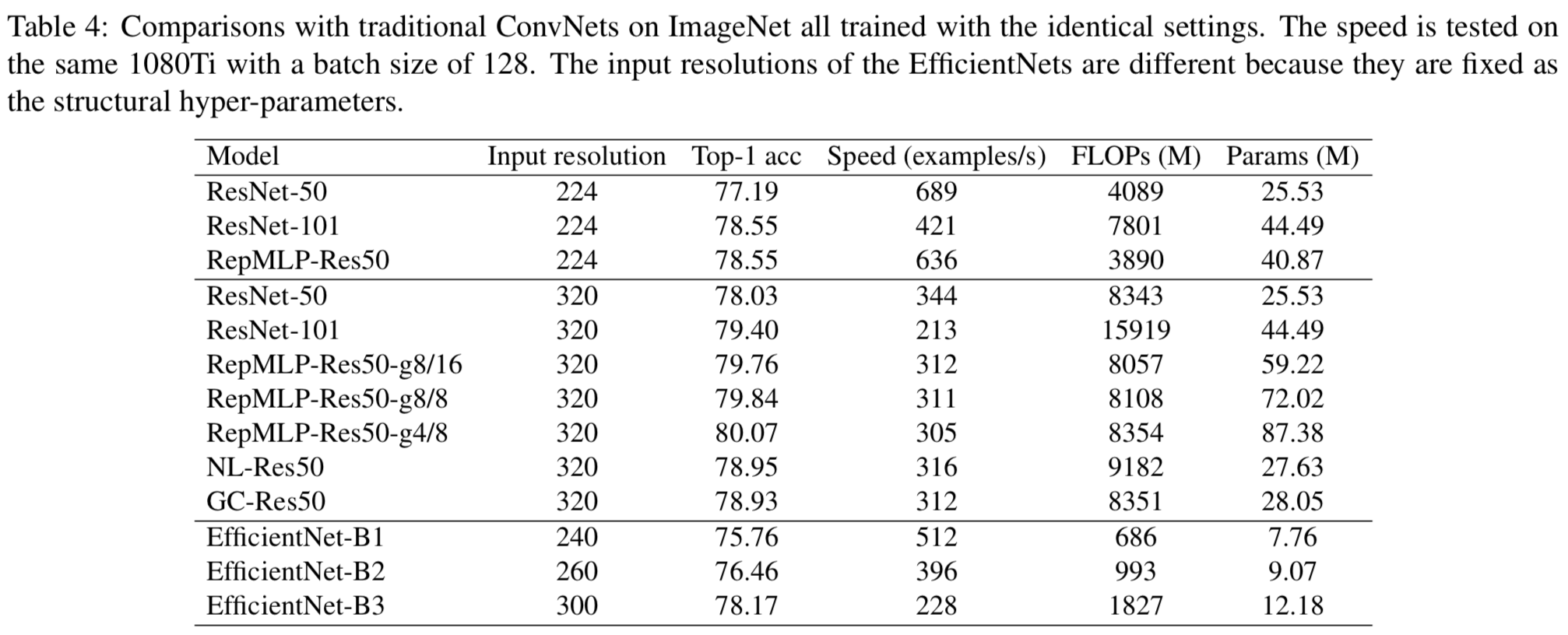
1)与相同参数数量的传统卷积网络相比,RepMLP-Res50的FLOPs要低得多,速度也快得多。例如,与224 × 224输入的ResNet-101相比,RepMLP-Res50只有50%的FLOPs和少了4M的参数,运行速度快50%,但它们的精度是相同的。输入为320 × 320时,RepMLP-Res50在精度、速度和FLOPs方面都有很大的优势。此外,ResNet-50的改进不应该简单地归因于深度的增加,因为它仍然比ResNet-101浅。2)增加RepMLPs的参数会导致非常轻微的减速。从RepMLP-Res50-g8/16到RepMLP-Res50-g4/8,参数增加了47%,而FLOPs仅增加了3.6%,速度仅降低了2.2%。这个属性对于大型服务器上的高吞吐量推断特别有用,在这种服务器上,吞吐量和准确性是我们主要关注的,而不是模型大小。3)与Nonlocal和GC相比,RepMLP-Res50的检测速度基本相同,但准确率提高了1%左右。4)与在GPU上效率不高的EfficientNets相比,RepMLP-Res50在速度和精度上都表现得更好。
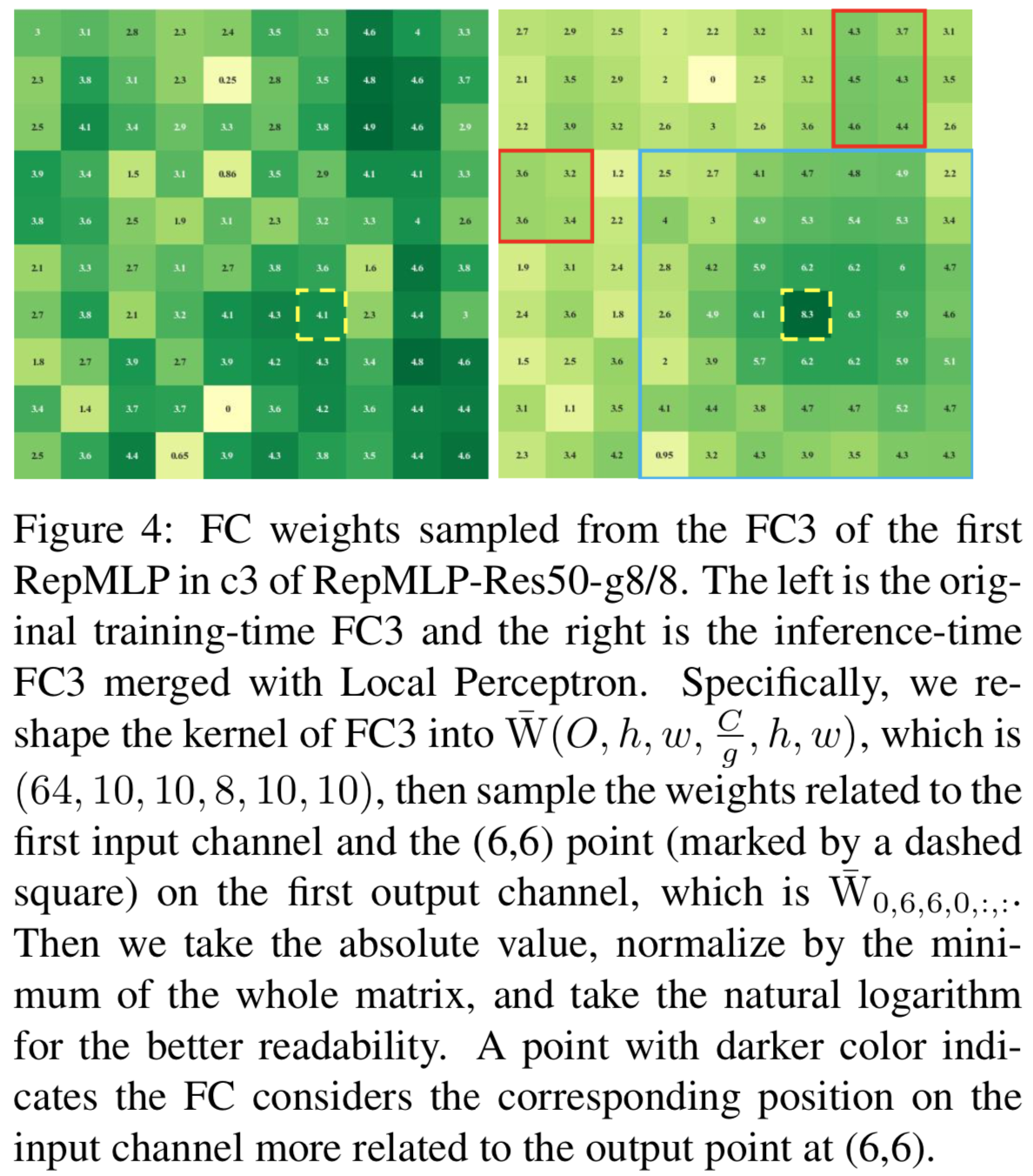
我们在图4中可视化了FC3的权值,其中采样的输出点(6,6)用一个虚线方块标记。原始FC3没有 local prior,因为标记点和其邻居的值不比其他的大。但是在合并Local Perceptron之后,生成的FC3核在标记点周围有更大的值,这表明模型更关注邻域,这是我们所期望得到的效果。此外,global capacity不会丢失,因为最大的conv核(在本例中是7 × 7,用蓝色正方形标记)之外的一些点(用红色矩形标记)的值仍然大于其内部的点。
我们还在附录记录了其他bottleneck(RepMLP Light Block)的设计,为8倍的channel reduction/expansion使用1x1的卷积,而不是3x3的卷积。与原始ResNet-50比较,其得到了相当的准确度(77.14% vs 77.19%),FLOPs降低30%,速度提高55%
4.3. Face Recognition
与conv不同,FC不是平移不变的,这使得RepMLP对于具有位置先验的图像(即人脸)特别有效。我们用于训练的数据集是MS1M-V2,这是一个大规模的人脸数据集,包含了来自85k个名人的5.8M张图像。它是MS-Celeb-1M数据集[12]的半自动改进版本,该数据集由来自100k个身份的1M张照片组成,有许多噪声图像和错误的ID标签。我们使用MegaFace[16]进行评估,其中使用60k个身份的1M张图像作为gallery集,使用来自FaceScrub的530个身份的1M图像作为probe集。它也是手动清除的改进版本。我们使用96 × 96输入进行训练和评估。
除了MobileFaceNet[3]作为一个众所周知的基线,它最初是为低功耗设备设计的,我们还使用定制的ResNet(在本文中称为FaceResNet)作为一个更强的基线。与常规的ResNet-50相比,c2、c3、c4、c5中的块数从3,4,6,3减少到3,2,2,2,宽度从256、512、1024、2048减少到128、256、512、1024,3 × 3的channels从64、128、256、512增加到128、256、512、1024。换句话说,残差块中的1 × 1 conv层不会减少或扩大channels。由于输入分辨率为96 × 96, c2、c3、c4、c5的空间大小分别为24、12、6、3。对于RepMLP的对照组,我们修改了FaceResNet,将c2,c3,c4的stride-1 bottlenecks(即c2的最后两个bottlenecks和c3,c4的最后两个bottlenecks)替换为RepMLP Bottlenecks,h = w = 6, r = 2, g = 4。
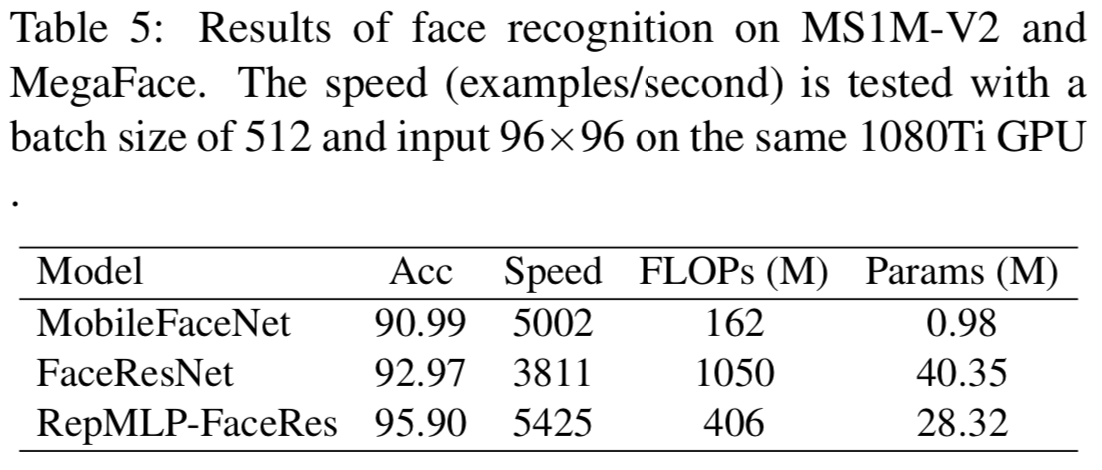
对于训练,我们使用的batch size为512,momentum为0.9,使用AM-Softmax loss[24],遵循[3]的权重衰减值。以0.1的学习率对所有模型进行420k次迭代训练,并在252k、364k和406k次迭代时将学习率除以10。为了进行评估,我们报告了MegaFace的top-1准确性。表5显示FaceResNet比MobileFaceNet提供更高的准确性,但运行速度较慢,而RepMLP-FaceRes在准确性和速度方面都优于前两者。与MobileFaceNet相比,RepMLP-FaceRes的准确率提高了4.91%,运行速度提高了8%(尽管它有2.5倍的FLOPs),这显然更适合高功率设备。
4.4. Semantic Segmentation
语义分割是一项具有平移不变性的代表性任务,因为汽车可能发生在左边或右边。我们验证了imagenet预训练的RepMLP-Res50在Cityscapes[6]上的泛化性能,该数据集包含5K个精细注释的图像和19个类别。我们使用RepMLP-Res50-g4/8和在ImageNet上使用320 × 320预训练的原始ResNet-50作为backbone。为了更好的再现,我们只采用了PSPNet[29]框架的官方实现和默认配置[28]:在8个GPUs上训练200个epochs,使用base为0.01和power为0.9的poly学习率策略,权重衰减为10−4和全局batch size为16。遵循PSPNet-50,我们在两个模型的c5和原ResNet-50的c4中使用dilated conv。我们在RepMLP-Res50-g4/8的c4中不使用dilated conv,因为它的感受域已经很大了。由于c3和c4的分辨率变成90 × 90, Global Perceptron的每个channels将有81个分区,因此FC1和FC2中有更多的参数。我们通过将FC1的输出维数和FC2的输入维数分别减少4倍 (c3)和8倍 (c4)来解决这个问题。FC1和FC2使用随机初始化,所有其他参数都从ImageNet 预训练模型中继承。
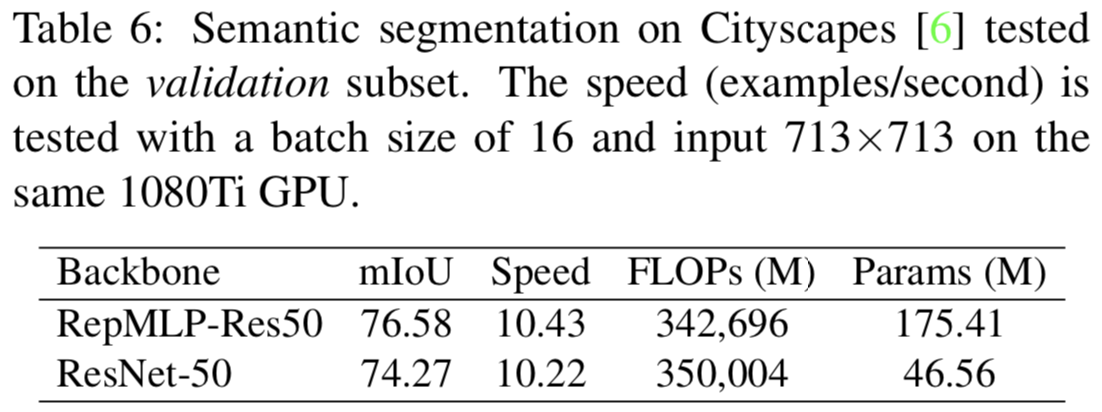
表6显示RepMLP-Res50-g4/8的PSPNet在mIoU中比Res-50 backbone性能好2.21%。虽然它有更多的参数,但FLOPs更低,速度更快。值得注意的是,我们的PSPNet基线比报告的PSPNet-50低,因为后者是为语义分割定制的(在最大池化之前增加了两层),但我们的不是。
5. Conclusion
一个FC比一个conv具有更强的表示能力,因为后者可以被视为一个具有共享参数的稀疏FC。然而,一个FC没有 local prior,这使得它不适合图像识别。在本文中,我们提出了RepMLP,它利用了FC的global capacity和positional perception,并通过一种简单的平台无关的算法重新参数化卷积,将 local prior整合到FC中。从理论角度看,将卷积网络视为FC的退化情况,开辟了一个新的视角,可以加深我们对传统卷积网络的理解。不应该忽视的是,RepMLP是为主要关注点为推断时的吞吐量和准确性,而不太关心参数数量的应用程序场景设计的。