Interpretable and Accurate Fine-grained Recognition via Region Grouping
Abstract
我们提出了一种用于细粒度视觉识别的可解释深度模型。我们的方法的核心是在深度神经网络中整合基于区域的part发现和归因。我们的模型使用图像级对象标签进行训练,并通过对象parts的分割和识别它们对分类的贡献,提供对其结果的解释。为了便于在没有直接监督的情况下学习对象parts,我们探讨了对象parts发生的一个简单先验。我们证明,这一先验,当结合我们基于区域的part发现和归因,得到一个可解释的模型,且仍然是高度准确的。我们的模型在主要的细粒度识别数据集上进行了评估,包括CUB-200[56]、CelebA[36]和iNaturalist[55]。我们的结果与最先进的分类任务方法相比是有利的,并且我们的方法在目标parts的定位上优于以前的方法。该项目网站可见https://www.biostat.wisc.edu/ ̃yli/cvpr2020-interp/
1. Introduction
深度模型在视觉识别方面非常成功,但其结果往往难以解释。考虑图1中的例子。为什么一个深度模型会认出这种鸟是“黄头画眉”,或者认为这个人是“在微笑”? 虽然模型的解释可以发生在多个方面,我们认为,至少有一种解释模型的方式是分割有意义的对象parts区域(例如,人脸的眼睛,嘴,脸颊,额头和脖子),并进一步识别他们对决策的贡献(例如,对于微笑来说,嘴巴区域更具识别度)。我们如何设计一个可解释的深度模型,学习发现对象parts,并估计它们对视觉识别的重要性?

事实证明,parts发现是在没有明确的part注释监督的情况下学习对象parts,其本身就是一个具有挑战性的问题。首先第一步,我们将重点放在细粒度识别任务上,即属于同一超类别的parts共享共同的视觉模式。例如,大多数鸟类的尾巴都有相似的形状。我们的主要观察结果是,卷积网络的特征可以将像素分组成一组视觉上一致的区域[28,25],从中选择一个判别段子集进行识别[33,32,11]。只有对象标签作为指导,我们希望分组将有助于找到视觉上不同的部分,而选择过程将识别它们对分类的贡献。
我们基于区域的part发现的一个主要挑战是没有明确的监控信号来定义part区域。因此,必须加入目标parts的先验知识,以便于学习。我们工作的核心创新是对目标parts的一个简单先验的探索:给定单个图像,一个part的出现遵循U形分布。例如,鸟的头很可能出现在大多数鸟的图像中,而鸟的腿可能只出现在一些图像中。令人惊讶的是,我们证明了这个简单的先验,当结合我们基于区域的part发现,可以得到有意义的目标parts的识别。更重要的是,所得到的可解释深度模型仍然是高度精确的。最近的一些方法已经被开发用于在细粒度分类中发现parts,但没有一个考虑到我们使用的先验。
为此,我们提出了可解释的深度模型用于细粒度分类。具体来说,我们的模型学习了一个对象parts的字典,基于这个字典,一个2D特征map可以被分成“part” segments。这是通过在一个学习到的字典中比较像素特征和part表征来完成的。此外,基于区域的特征从结果segments池化得到,然后通过注意机制选择用于分类的segments子集。重要的是,在训练过程中,我们对每个part的出现执行U形先验分布。这是通过减小part发生在我们的先验分布和的经验分布之间的Earth Mover’s Distance来实现的。在训练过程中,我们的模型仅由带有我们所提出的正则化项的对象标签来监督。在测试过程中,我们的模型联合输出对象parts的segments、segments parts的重要性和预测的标签。因此,我们模型的解释性是通过part segmentation和每个part对分类的贡献得到的。
为了评估我们的模型,我们使用三个细粒度识别数据集进行了广泛的实验,以提高可解释性和准确性。为了量化可解释性,我们将模型的输出区域segments与标注的对象parts进行比较。为了准确性,我们报告用于细粒度分类的标准度量。在较小规模的数据集上,如CUB-200[36]和CelebA[56]中,我们的模型可以找到定位误差较低的鸟和脸的parts,同时在精度方面优于最先进的方法。在更有挑战性的iNaturalist数据集[55]上,我们的模型提高了强基线网络(ResNet101) 5.7%的精度,减少了目标定位误差,并展示了part发现好的定性结果。
2. Related Work
人们对解释深层模型产生了兴趣。我们的工作重点是遵循基于区域的识别范式去开发可解释的深度模型,用于细粒度分类。我们简要回顾了可解释深度学习、基于part的细粒度分类以及最近用于区域分割和基于区域识别的深度模型的相关文献。
Visualizing and Understanding Deep Networks. 最近的一些研究成果已经被开发出来,以可视化和理解训练有素的深层网络。这些事后方法中的许多[39,17,61,15,70,51]侧重于开发激活映射和/或训练网络中的过滤器权值的可视化工具。其他研究试图在预先训练的网络下识别输入图像中有区别性的区域[54,48,51,18,61,43,4,71,38]。除了定性的结果,Bau等人[4]提出了一个定量基准,将网络单元的激活与人类注释的概念mask进行比较。另一个方向是学习一个简单的模型,如线性分类器[45]或决策树[13],来模仿训练过的网络的行为,从而提供目标模型输出的解释。我们的工作在解释深层模型方面有着相同的动机,但是我们将解释融入到模型的学习中。与[4]类似,我们也使用人类注释的对象parts来量化我们的网络的可解释性。
Interpretable Deep Models. 可解释性可以用深度模型来构建。许多最近的作品都开发了可以通过其设计解释的深度模型。例如,Zhang等人[66]设计了一种正则化方法,鼓励高级卷积层中的每个滤波器聚焦于特定的目标部分。Brendel等人[6]提出了BagNet,以小图像块作为输入,然后后面跟着用于整个图像分类的bag-of-feature (BoF)表示。BagNet可以自然地将决策归因于局部区域,从而有助于解释决策过程。Alvarez-Melis和Jaakkola[40]提出对全局图像特征的基础进行相关性评分。另外,可以为可解释的模型设计新的网络体系结构。例如,Capsule网络[47]用向量代替常用的标量激活,后者被认为代表实体,如对象或对象部分。在[53]中,通过加强从卷积单元到最终预测的稀疏连接,在传统CNNs上进一步扩展了相关的思想。
最相关的工作是Chen等人的[8]。他们提议学习网络中目标parts的原型。因此,模型的决策取决于在输入图像中找到的原型的识别。与他们的工作类似,我们的模型也试图明确地编码对象part的概念。然而,我们的工作与[8]在两个关键方面有所不同:(1)我们采用区域分组的方法对图像分割进行解释;(2)模型的学习通过对目标parts发生的较强先验进行正则化。
Part Discovery for Fine-grained Recognition. 识别有区别性的目标parts对于细粒度分类非常重要[50,49,58,67]。例如,可以使用边界框或labdmark注释来学习对象parts,以便进行细粒度分类[24,34,41,62,64]。为了避免对对象parts进行代价高昂的注释,最近有几部作品关注于使用深度模型进行无监督或弱监督的part学习。Xiao等人[58]对卷积滤波器进行光谱聚类,寻找parts的代表性滤波器。Wang等人[57]提出学习一组卷积滤波器来捕捉类特定的对象parts。此外,注意力模式也被广泛地用于学习parts。Liu等人[35]利用强化学习选择区域proposals进行细粒度分类。Zheng等[68]将特征通道分组来寻找parts及其注意,将具有相似激活模式的通道作为part候选。
与以前的工作类似,我们的工作也试图找到parts,并确定它们对于细粒度分类的重要性。然而,我们的工作不同于以前的工作,考虑了对象parts发生的显式正则化。此外,我们在part发现时还考虑了一个大规模的数据集(iNaturalist[55])。在实验中,我们将在识别精度和part定位误差两方面与之前的方法进行比较。
Weakly-supervised Segmentation of Object Parts. 我们的工作也与先前的弱监督或无监督分割对象parts的工作有关。Zhang等人[65]从一个预先训练的CNN中提取激活,以在图中表示目标parts。他们对parts的学习是由一些parts注释监督的。Collins等人[12]对一个预先训练好的CNN进行了非负矩阵分解,其中每个分量定义了图像的一段。Jampani等人[28]提出了一种迭代深度模型来学习超像素段。最近,Hung等人[25]提出了一个深度模型,它包含了强先验,如空间一致性、旋转不变性、语义一致性和显著性,用于对象parts的无监督学习。我们的工作受到了[25]的启发,在[25]中,我们还探索了新的正则化来学习分割对象parts。然而,我们在细粒度分类的背景下考虑弱监督的part分割。此外,我们探索了一个非常不同的part发生的先验。
Region-based Recognition. 最后,我们的模型将分割和分类结合到一个深度模型中,从而与基于区域的识别[19,59,31,1]或组合学习[52]关联。最近,针对基于区域的识别设计深度模型的研究取得了进展。例如,Li等人[33]提出将CNN的特征分组成区域图,然后通过图卷积网络进行视觉识别。Chen等人[11]也探索了类似的思路。最近,Li等人[32]提出了一种深度模型,利用期望最大化,联合改进了区域的分组和标记。此外,Arslan[3]提出利用预定义区域构建图神经网络进行脑图像分类。我们的模型使用与[33,11,32]相似的思想对CNN特征进行分组。然而,这些前人的著作都没有关注分组的质量,因此不能直接用于解释。
3. Method
考虑一组N个2D图像特征maps ![]()
![]() ,以及其类别标签
,以及其类别标签![]() ,其中
,其中![]() 是来自卷积网络的2D图像平面HxW上的D维特征,
是来自卷积网络的2D图像平面HxW上的D维特征,![]()
![]() 是细粒度类别的图像级标签。我们模型的目标是学习一个part字典
是细粒度类别的图像级标签。我们模型的目标是学习一个part字典![]()
![]() 和一个用于细粒度分类的决策函数
和一个用于细粒度分类的决策函数![]() 。具体说来,
。具体说来,![]() ,其中的每个列向量
,其中的每个列向量![]() 表示一个对象part的概念。
表示一个对象part的概念。![]() 表示
表示![]() 的参数。
的参数。![]() 以特征maps
以特征maps ![]() 和part字典 D作为输入去预测标签
和part字典 D作为输入去预测标签![]() 。如图2所示,概述了整个模型。为了清晰起见,我们有时去掉下标n
。如图2所示,概述了整个模型。为了清晰起见,我们有时去掉下标n
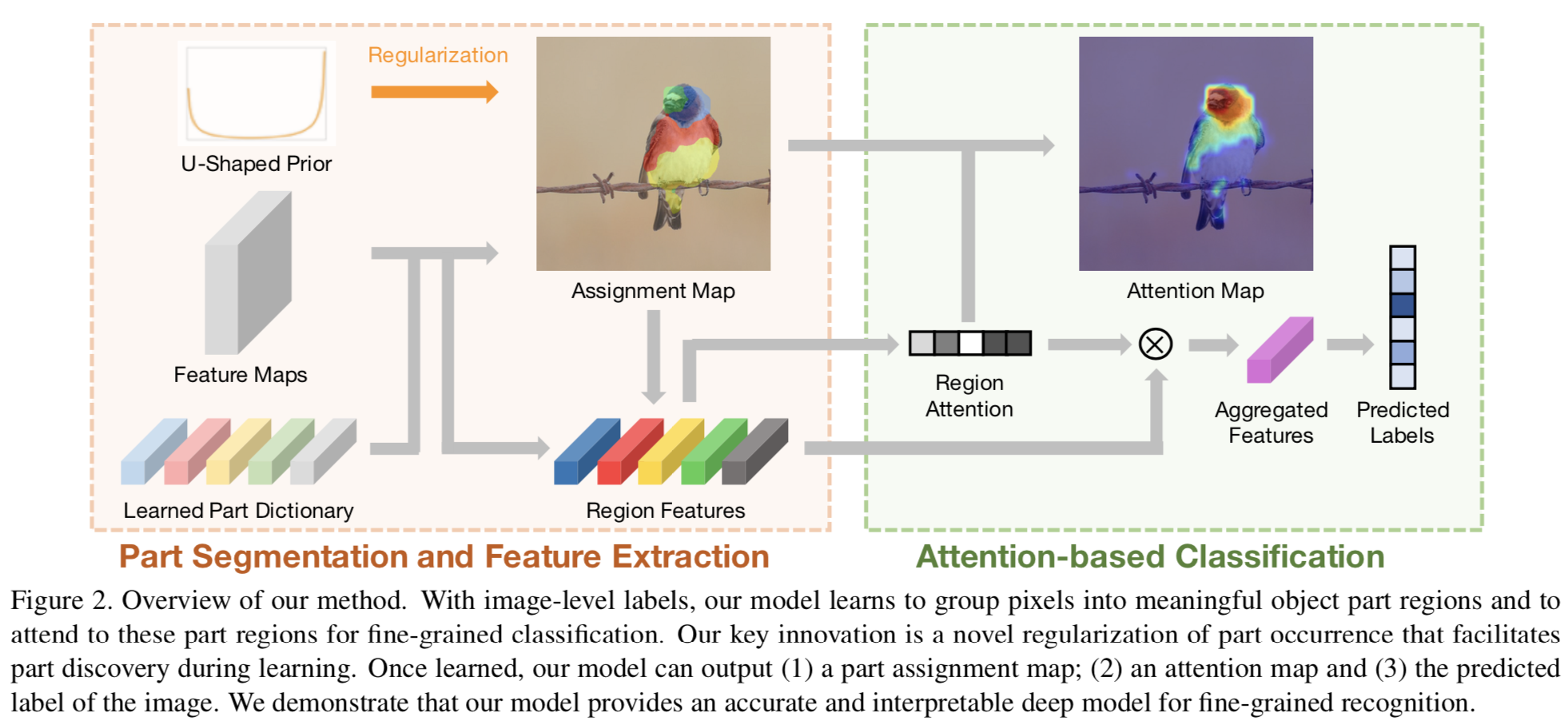
具体说来,假设函数![]() 能够分解为三个部分:
能够分解为三个部分:
- Part Segmentation. 通过对比feature maps
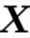 和part dictionary
和part dictionary 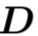 去创建一个soft assignment map
去创建一个soft assignment map 
 。通过使用一个分组函数
。通过使用一个分组函数 去得到它,即
去得到它,即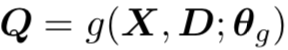
- Region Feature Extraction and Attribution. 基于assignment map
 和part dictionary ,region features
和part dictionary ,region features 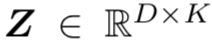 从feature maps 中池化得到。进一步计算一个注意力向量
从feature maps 中池化得到。进一步计算一个注意力向量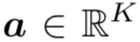 ,其中每个元素为一个part segment提供一个重要性分数。式子为
,其中每个元素为一个part segment提供一个重要性分数。式子为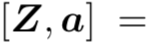
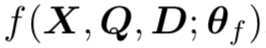
- Attention Based Classification. region features
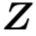 被region attention
被region attention  重新加权,后面跟着一个线性分类器用于y决策。通过
重新加权,后面跟着一个线性分类器用于y决策。通过 ,即
,即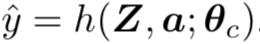 实现
实现
Regularization of Part Occurrence. 上面描述了我们对![]() 、
、![]() 和
和![]() 的设计,接下来说明学习的主要挑战。因为唯一的监督信号是y,保证字典
的设计,接下来说明学习的主要挑战。因为唯一的监督信号是y,保证字典![]() 能够捕获到有意义的对象parts是很有挑战的。我们的主要假设是我们能够通过强制 一组图像特征
能够捕获到有意义的对象parts是很有挑战的。我们的主要假设是我们能够通过强制 一组图像特征![]() 中的每个part
中的每个part ![]() 的出现都遵循一个先验分布去正则化学习。具体来说就死,给定
的出现都遵循一个先验分布去正则化学习。具体来说就死,给定![]() ,
,![]() 表示出现在
表示出现在![]() 的part
的part ![]() 的条件概率。我们假设
的条件概率。我们假设![]() 遵循U形分布
遵循U形分布![]() ,就像一个概率二进制开关,我们可以控制“开”和“关”的概率。例如,在CUB-200鸟类数据集中,鸟类的所有parts都显示在大多数鸟类图像中,因此开关几乎总是打开的。相比之下,在更有挑战性的iNaturalist数据集上,一个物体的part只在一定数量的类别中被激活,因此开关可能只在一些图像中被激活。
,就像一个概率二进制开关,我们可以控制“开”和“关”的概率。例如,在CUB-200鸟类数据集中,鸟类的所有parts都显示在大多数鸟类图像中,因此开关几乎总是打开的。相比之下,在更有挑战性的iNaturalist数据集上,一个物体的part只在一定数量的类别中被激活,因此开关可能只在一些图像中被激活。
3.1. Part Segmentation and Regularization
接下来说明part segmentation的细节,以及如何正则化parts的出现
Part Assignment. 我们采用以前工作[33,11]提出的projection unit。更详细说来,让![]() 表示assignment matrix
表示assignment matrix ![]() 的一个元素,其中i、j表示2D位置的索引,k表示parts。
的一个元素,其中i、j表示2D位置的索引,k表示parts。![]() 表示
表示![]() 中在位置(i,j)的特征向量
中在位置(i,j)的特征向量![]() 被分配给
被分配给![]() 中第k个part
中第k个part ![]() 的概率。
的概率。![]() 计算公式为:
计算公式为:

(根据式子可见,![]() 与part字典
与part字典![]() 越像,其被分配的概率越大)
越像,其被分配的概率越大)
其中![]() 是一个用于每个part
是一个用于每个part ![]() 的可学习的平滑因子。由于softmax归一化,所以
的可学习的平滑因子。由于softmax归一化,所以![]() 。除此之外,我们集合所有的assignment vectors
。除此之外,我们集合所有的assignment vectors ![]() 到我们的part assignment map
到我们的part assignment map ![]() 。
。
Part Occurrence. 给定一个part assignment map,我们下一步就是检测每个part ![]() 的出现。一个简单的part 检测器能够在第k个assignment map
的出现。一个简单的part 检测器能够在第k个assignment map ![]() 上使用max pooling操作实现。可是,我们发现在池化前平滑assignment map是有益的,即使用带有一个小
上使用max pooling操作实现。可是,我们发现在池化前平滑assignment map是有益的,即使用带有一个小
bandwidth的高斯核。该平滑操作帮助减小了feature map上的异常值。因此,我们的part 检测器被定义为![]() ,其中
,其中![]() 是一个2D高斯核,* 是一个卷积操作。
是一个2D高斯核,* 是一个卷积操作。![]() 范围在(0,1)。此外,k个part检测器的输出被串联为一个所有parts的发生向量
范围在(0,1)。此外,k个part检测器的输出被串联为一个所有parts的发生向量![]() 。(其实就t1就是从第1个HxW的assignment map中用Max pooling得到被分配给第1个part的最大概率,对应的t2、t3...tk就是分配给第2、3、k个part的最大概率,所以发生向量即k个最大概率值)
。(其实就t1就是从第1个HxW的assignment map中用Max pooling得到被分配给第1个part的最大概率,对应的t2、t3...tk就是分配给第2、3、k个part的最大概率,所以发生向量即k个最大概率值)
Regularization of Part Occurrence. 我们的核心想法是去正则化每个part的出现。通过强迫part出现的经验分布于U形先验分布对齐。更具体来说,就是给定N个样本,即从整体数据集中采样得到的mini-batch,我们首先通过串联所有出现向量![]() 成一个矩阵
成一个矩阵![]()
![]() 来估计经验分布
来估计经验分布![]() 。而且,我们假设一个先验分布
。而且,我们假设一个先验分布![]() 是已知的,如一个Beta分布。我们提出使用1D Wassertein distance,即Earth-Mover distance去对齐
是已知的,如一个Beta分布。我们提出使用1D Wassertein distance,即Earth-Mover distance去对齐![]() 和
和![]() ,如下所示:
,如下所示:

其中![]() 和
和![]() 是用于经验和先验分布的Cumulative Distribution Functions (CDFs)。z的区间为[0,1]
是用于经验和先验分布的Cumulative Distribution Functions (CDFs)。z的区间为[0,1]
在mini-batch训练中,Wassertein distance能够通过使用mini-batch中样本的总和去替换整数来近似得到,变为![]() 和
和![]() 的L1距离。在实践中,我们发现使用对数函数来rescale CDFs的逆函数是有帮助的,这提高了训练的稳定性。
的L1距离。在实践中,我们发现使用对数函数来rescale CDFs的逆函数是有帮助的,这提高了训练的稳定性。
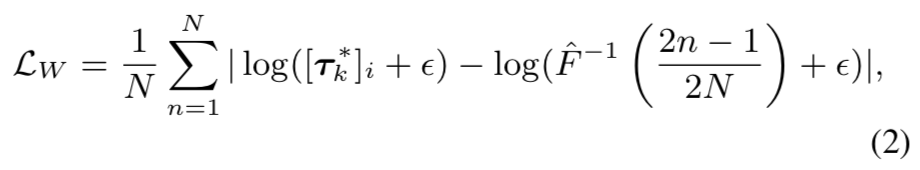
(这个就是正则化损失)
其中![]() 是
是![]() (size N)第k行向量的有序版本(升序),
(size N)第k行向量的有序版本(升序),![]() 是
是![]() 的第i 个元素。ε是一个用于数值稳定的小值。使用对数rescaling
的第i 个元素。ε是一个用于数值稳定的小值。使用对数rescaling
解决了等式(1)softmax函数中的梯度消失问题。即使一个part ![]() 离当前mini-batch所有特征向量很远,即等式(1)中的
离当前mini-batch所有特征向量很远,即等式(1)中的![]() 值很小,因为rescaling,
值很小,因为rescaling,![]() 也能得到一个非零的梯度。
也能得到一个非零的梯度。
我们注意到有不同的方法来对齐两个1D分布。我们之前已经通过使用像[5]中提出的shaping CDFs的方法去用Crame'r-von Mises标准进行了实验。然而,我们发现我们选择的1D Wasserstein 在数据集上产生了更稳健的结果。
3.2. Region Feature Extraction and Attribution
给定了part分配,我们的下一步是从每个区域汇集特征。这是通过使用非线性特征编码方案[33,29,42,2]来实现的,公式如下:

因此,![]() 是分配给part
是分配给part ![]() 的来自像素的区域特征。将
的来自像素的区域特征。将![]() 合并在一起,得到来自输入特征maps的区域特征集
合并在一起,得到来自输入特征maps的区域特征集![]() 。我们进一步使用一个有着几个残差块的子网络
。我们进一步使用一个有着几个残差块的子网络![]() 去进一步转换
去进一步转换![]() , 每个残差块都是一个包含三个1x1卷积+BN+ReLU的bottleneck。因此得到的转换特征为
, 每个残差块都是一个包含三个1x1卷积+BN+ReLU的bottleneck。因此得到的转换特征为![]() 。
。
然后,一个注意力模块附着在![]() 之上去预测每个区域的重要性。这通过一个子网络
之上去预测每个区域的重要性。这通过一个子网络![]() 实现,由
实现,由![]() 给定,其中
给定,其中![]() 包含多个1x1卷积+BN+ReLU。得到的注意力
包含多个1x1卷积+BN+ReLU。得到的注意力![]() 还被进一步用于分类。
还被进一步用于分类。
3.3. Attention Based Classification
最后,我们使用注意力向量![]() 重新加权转换后的区域特征
重新加权转换后的区域特征![]() ,后面接着一个线性分类器。因此,最后的预测为:
,后面接着一个线性分类器。因此,最后的预测为:
![]()
其中![]() 是C-分类的线性分类器的权重。注意,这里注意力
是C-分类的线性分类器的权重。注意,这里注意力![]() 作为区域特征
作为区域特征![]() 的一个调制器。因此
的一个调制器。因此![]() 中大的值表示其为分类中相对重要的区域
中大的值表示其为分类中相对重要的区域
Pixel Attribution.给定注意力![]() ,我们能够轻易地后向追踪特征map中每个像素的贡献。能够通过使用
,我们能够轻易地后向追踪特征map中每个像素的贡献。能够通过使用![]() 来实现,其中
来实现,其中![]() 仅仅是part分配map
仅仅是part分配map ![]() 的reshaped版本。
的reshaped版本。
3.4. Implementation
接下来,我们将说明我们的损失功能,网络架构,以及训练和推断的实现细节。
Loss Function. 我们的模型通过最小化分类的交叉熵损失和等式(2)中用于part正则化的基于正则化损失的1D Wasserstein distance进行训练。在我们的实验中,我们改变了平衡损失项和用于Wasserstein距离的先验Beta分布的权重。
Network Architecture. 我们用我们提出的模块替换了基线CNN (ResNet101[23])的最后一个卷积块。我们粗略地将最终模型中的参数数量与基线相匹配。
Training and Inference. 我们对所有数据集使用standard mini-batch SGD。由于不同的任务,超参数在数据集上的选择是不同的,并将在实验中讨论。我们应用了包括随机裁剪、随机水平翻转和颜色抖动在内的数据增强,并采用了[23]中学习速率衰减的方法。我们模型中的卷积层是从ImageNet预训练的模型初始化的。新的参数,包括part dictionary,遵循[22]进行随机初始化。所有参数在目标数据集上共同学习。在所有实验中,除非另行通知,我们将报告使用 single center crop的结果。
4. Experiments and Results
我们现在描述我们的实验并讨论结果。我们首先介绍实验中使用的数据集和指标。然后,我们描述在个别数据集上我们的实验和结果,然后进行消融研究。所有实验的结果都报告了准确性和可解释性,并与最新的方法进行了比较。
Datasets. 实验选取了三个细粒度识别数据集CelebA[36]、CUB-200-2011[56]和iNaturalist 2017[55]。这些数据集跨越一系列任务和规模。CelebA是一种用于人脸属性识别和人脸landmark检测的中等尺度数据集。CUB-200是一个鸟类物种识别的小型数据集,还附带鸟类关键点注释。最后,innaturalist 2017是一个用于细粒度物种识别和检测的大型数据集,涵盖了从哺乳动物到植物的5000多个类别。
Evaluation Metric. 我们为细粒度视觉识别评估我们模型的准确性和可解释性。为了精确,我们报告标准实例级或平均类精度,就像以前为细粒度分类考虑的那样。作为可解释性的代理,我们使用带注释的对象landmark来测量对象part定位错误,因为我们的模型是设计来发现对象part的。这种定位误差之前已经在part分割模型中考虑过,如Hung等[25]。对于数据集,例如iNaturalist 2017,不附带part注释,我们遵循Pointing Game的协议[63],并使用注释的对象边界框报告对象定位错误。Pointing Game被广泛用于评价可解释的深度模型[63,48,43]。
具体来说,在CelebA和CUB-200上报告了part的定位错误。遵循[25]中类似的协议,我们通过学习线性回归模型将assignment maps转换为一组landmark位置。回归模型将part assignment的2D几何中心映射到二维对象landmarks中。将预测的landmarks与测试集上的ground-truth进行比较。我们报告预测与ground-truth之间的归一化平均L2距离。对iNaturalist 2017报道了Pointing Game的结果。我们通过计算输出注意图的峰值位置位于ground-truth对象边界框之外的情况来计算错误率。
4.1. Results on CelebA
Dataset. CelebA[36]是一个人脸属性和landmark检测数据集,包含从互联网上收集的202599张名人人脸图像。每个人脸图像都被标注了40个人脸属性和5个landmark位置(眼睛、噪声和嘴角)。我们考虑对[36,25]中的数据进行两种不同的split。第一次从[36]split的图像包括162770张、19867张和19962张,分别用于训练、验证和测试,并用于评估人脸属性识别。此split中的人脸对齐到图像中心。第二次从[25]split的图像有45,609张用于训练,5379张用于拟合线性回归器,283张用于测试。第二次split用于报告part定位错误。人脸在这次split中没有对齐。
Implementation Details. 我们在使用相同架构的两个split上训练了两个模型。我们为每个人脸属性附加了一个单独的基于注意力的二元分类头,因为这些属性并不相互排斥。对于属性识别,我们的模型在训练集上进行训练,在测试集上进行评估。验证集用于超参数的选择。对于landmark定位,我们遵循了[25]的训练程序。我们的模型训练使用5e-3的学习速率,batch大小为32,30个epochs权重衰减为1e-4。我们将两个损失项之间的权重设为10:1,并使用α=1和β=1e-3的先验Beta分布(接近于p =1的伯努利方程)。所有输入图像都被调整为256×256,并在不裁剪的情况下输入到模型中。用了parts为9的字典。在报告局部定位误差时,我们通过 inter-ocular距离[25]对L2距离进行归一化。
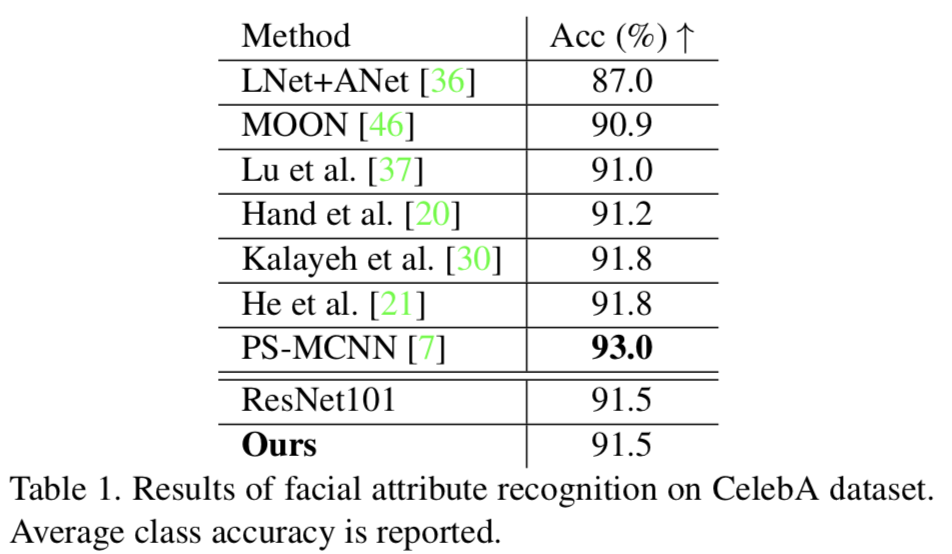
Recognition Results (Accuracy). 我们对属性识别的结果总结如表1所示。我们将我们的结果与最先进的方法[36,46,37,20,30,21,7]以及基线ResNet101(在ImageNet上预先训练)进行比较。令人惊讶的是,与以前的许多方法相比,基线ResNet101已经达到了类似甚至更高的精度,包括那些需要辅助人脸分析的方法[30,21]。我们的模型与强大的ResNet101基线表现相当。唯一明显优于我们的模型和ResNet101基线的方法是[7],它使用了额外的人脸身份标签。总而言之,我们的模型达到了最先进的精度。
Localization Results (Interpretability). 我们进一步评估面部landmark定位结果,如表2所示。我们的结果与最新的DFF[12]和SCOPS[25]方法进行了比较。DFF对预训练的CNN (VGG1)的特征图进行非负矩阵分解,以生成part分割。SCOPS在用于目标part分割的自监督训练中探讨了空间一致性,旋转不变性,语义一致性和视觉显著性。我们的模型在定位误差方面优于这两种方法,与SCOPS和DFF相比,分别实现了6.6%和21.9%的误差减少。这些结果表明,我们的模型具有较高的定位精度,从而支持我们的模型的可解释性。

Visualization. 我们的模型在人脸属性识别方面取得了最先进的成果,并为人脸landmark定位提供了新的能力。我们进一步可视化我们模型中的assignment maps,并将其与图3中的DFF[12]和SCOPS[25]进行比较。此外,我们在图4中显示了我们模型中的attention maps。注意,我们的attention maps是特定于属性的,因为我们为每个属性使用了单独的分类头。这些定性结果表明,我们的模型能够将人脸分割成有意义的part区域(例如,头发、额头、眼睛、鼻子、嘴巴和脖子),并关注那些对属性识别具有判别能力的区域(例如,眼睛区域代表“窄眼睛”,头发区域代表“黑头发”)。


Dataset. Caltech-UCSD Birds-200-2011[56] (CUB-200)是一个用于细粒度鸟类物种识别的小尺度数据集。CUB-200包含5,994/5,794张图片,用于训练/测试来自200种不同的鸟类。每张图片都附有一个物种标签、15个鸟类landmark和一个鸟类的边界框。
Implementation Details. 我们使用学习率为1e-3、batch大小为32、权重衰减为5e-4的方法训练了一个分类和landmar定位的单一模型,训练150个epochs。我们将两个损失项之间的权重设为2:1,使用与CelebA相同的先验分布和5个parts的字典。我们通过将最短边缩放到448来调整输入图像的大小,并随机裁剪448x448的区域用于训练。当报告part定位错误时,我们使用鸟的边界框大小来标准化L2距离,类似于[25]。
Recognition Results (Accuracy). 我们在表3中给出了我们的识别精度结果,并将其与最先进的方法进行了比较[27,14,68,16,9,57,60,10,69]。同样,基线ResNet101已经在CUB-200上实现了最先进的结果。我们的模型略低于ResNet101(-0.4%),表现与先前基于part的模型(如MA-CNN[68])相当。

Localization Results (Interpretability). 此外,我们评估了part定位误差,并将我们的结果与DFF[12]和SCOPS[25]进行比较。为了进行公平的比较,我们遵循[25]报告前三个类别的错误,如表4所示。同样,我们的模型显著降低了定位误差(2.9%-6.2%)。当拟合所有200个类别时,我们的模型平均定位误差为11.51%。这些结果为我们模型的可解释性提供了进一步的证据。
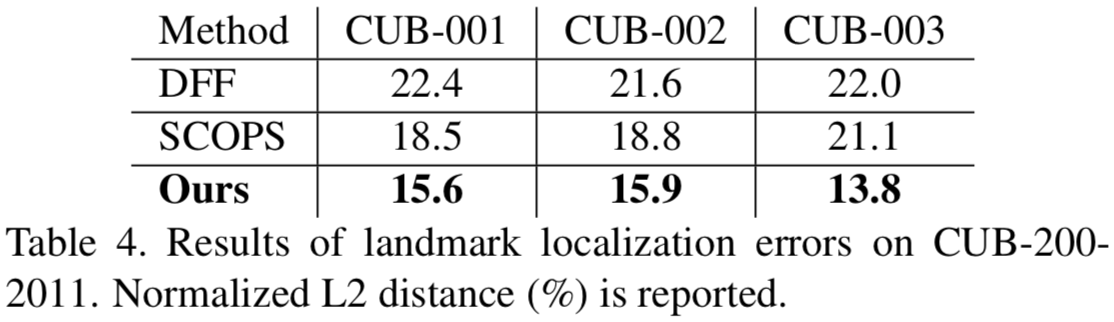
Visualization. 我们还将模型中的assignment maps 和attention maps可视化,如图5所示。我们的模型证明了发现鸟类的连贯部分(例如,喙/腿,头,翅膀/尾巴,身体)和选择重要区域(喙/腿和翅膀/尾巴)来识别物种的能力。

4.3. Results on iNaturalist 2017
Dataset. iNaturalist 2017[56]是一个用于细粒度物种识别的大规模数据集。它包含用于训练和测试的579184和95986张图,从5089个物种组织成13个超级类别。有些图像还带有对象的边框注释。由于数据集不包括part注释,我们报告Pointing Game的结果,以评估我们的模型的可解释性。这个数据集对于挖掘有意义的对象parts非常具有挑战性,因为不同超类别的对象具有截然不同的视觉外观(例如,植物和哺乳动物)。
Implementation Details. 我们训练一个单一的模型进行分类和定位。我们的模型训练使用的学习速率为1e-3,batch大小为128和在75个epochs内权重衰减为5e-4。在训练过程中,我们通过将最短边缩放到320来调整输入图像的大小,并随机裁剪224x224的区域。我们将两个损失项之间的权重设为10:1。采用8个parts的字典,考虑α=2e-3和β=1e-3的先验Beta分布。我们还通过将完整的图像(最短边320)输入到模型中探索了全卷积测试。
Recognition Results (Accuracy). 表5总结了我们的结果,并将其与基线ResNet101模型以及SSN[44]和TASN等最新方法进行了比较[69]。SSN和TASN都利用基于注意力的上采样放大有判别力的区域进行分类。

与CelebA和CUB-200不同,基线ResNet101的结果比最先进的模型(SSN和TASN)差得多。我们的模型至少使ResNet101基线值提高了3.7%。使用test time augmentation(全卷积测试)进一步提高了2%的结果。然而,我们的模型仍然比TASN(-1.4%)差。我们推测,我们的模型可以使用类似SSN和TASN的上采样机制进一步提高精度。
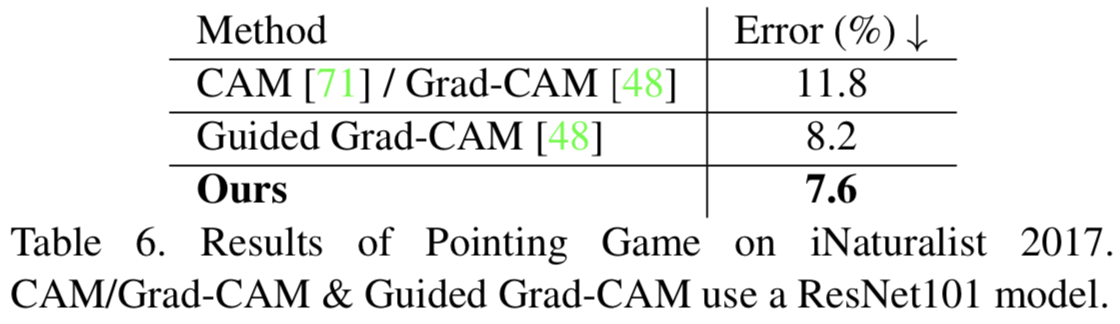
Localization Results (Interpretability). 此外,我们在表6中报告了Pointing Game的结果。我们的结果进一步与使用基线ResNet101模型的显著性方法进行比较,包括CAM/Grad-CAM[711,48]和Guided Grad-CAM[48]。注意,当从一个ResNet的最后一个卷积层可视化特征时,CAM和Grad--CAM是相同的。我们的模型实现了最低的定位误差(CAM/Grad-CAM和Guided Grad-CAM的改进分别为4.2%和0.6%)。
最后,assignment和attention maps的可视化结果可见图6和图7。

4.4. Ablation Study, Limitation and Discussion
Ablation. 我们对CelebA进行消融研究,以评估我们的模型组件。我们的研究考虑了两种变体,一种没有正则化,一种没有注意力。表7显示了来自[25]split的识别精度和定位误差。所有变体的精度都非常相似,但我们的正则化极大地提高了定位精度(3.9%)。在无注意力的情况下,我们的模型局部定位性能稍好,但与完整模型相比,缺乏区域和像素属性的关键能力。我们的完整模型对所有landmarks的定位误差都很小,分别为7.4%、7.5%、9.1%、9.3%和8.6%的左眼、右眼、鼻子、左嘴角和右嘴角。

Limitation and Discussion. 我们的模型在iNaturalist数据集上发现了很多失败案例,如图6和7所示。我们的模型可能无法将像素分组到part区域,有时产生不正确的saliency maps。我们推测这些失败案例是由我们之前的Beta分布产生的。在iNaturalist上有超过5K的细粒度类别,所有part的单一U型分布可能无法描述part的发生。此外,我们的模型没有对part之间的相互作用进行建模,并且需要一个中等到大的batch来估计part发生的经验分布。因此,一个有希望的未来方向是探索对象parts的更好先验。
5. Conclusion
我们提出了一个用于细粒度分类的可解释的深度模型。我们的模型利用了一个新的物体parts的发生先验,并将基于区域的parts发现和归因整合到一个深度网络中。仅使用图像级标签训练,我们的模型可以预测目标parts的 assignment map、part区域的attention map和目标标签,对目标分类和目标part定位有较好的效果。我们相信我们的模型向可解释深度学习和细粒度视觉识别迈出了坚实的一步。