https://github.com/adityac94/Grad_CAM_plus_plus
https://github.com/frgfm/torch-cam
Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks
Abstract
在过去的十年中,卷积神经网络(CNN)模型在解决复杂的视觉问题方面取得了巨大的成功。然而,考虑到缺乏对其内部功能的理解,这些深层模型被视为“黑盒”方法。最近,人们对开发可解释的深度学习模型产生了浓厚的兴趣,而本文正是朝着这个方向努力的成果。在最近提出的Grad-CAM方法基础上,我们提出一种广义的方法,称为Grad-CAM++,与当前最先进的方法相比,其可以对CNN模型的预测提供更好的视觉解释,给出更好的对象定位以及解释在单个图像中多个对象实例的出现。我们为所提出的方法提供了一个数学推导,该方法使用最后一个卷积层特征图对特定类得分的正偏导数的加权组合作为权重,为相应的类标签生成一个可视化的解释。我们在标准数据集上进行了大量的主观和客观的实验和评估,结果表明Grad-CAM++为一个给定的CNN架构提供了很有前途的人类可解释的视觉解释,涉及多个任务,包括分类、图像标题生成和3D动作识别;还可以使用在新的环境下,如知识蒸馏。
1 INTRODUCTION
与之前可视化CNNs的努力一致,我们也进行了人体研究来测试我们的解释的质量。这些研究表明,与Grad-CAM生成的相应可视化相比,Grad-CAM ++生成的可视化在底层模型(对于人类用户)中注入了更多的信任(即更可信)。
通过可视化的例子和客观的评估,我们还表明,在给定图像中对象类的弱监督定位方面,Grad-CAM++比Grad-CAM有所改进。
一个好的解释应该能够有效地蒸馏知识。这方面的可解释AI在最近的工作中很大程度上被忽略了。我们表明,在有约束的teacher-student环境中,可以通过使用一个特定的损失函数来提高学生的表现,这个损失函数的灵感来自Grad-CAM++生成的解释图。我们为实现这一目标引入了一种训练方法,并展示了使用我们的方法训练的学生模型所取得的良好效果。
最后,我们展示了Grad-CAM++在其他任务(除了识别任务以外的其他任务)中的有效性,特别是图像字幕和3D动作识别。到目前为止,CNN决策的可视化在很大程度上局限于二维图像数据,这是视频理解的3D-CNNs的可视化解释中为数不多的努力之一(最近[8]也是类似的努力)。
2 RELATED WORK
在本节中,我们对近年来在理解CNN预测方面所做的相关努力进行了调查。如前所述,Zeiler和Fergus[1]提出了在这一领域理解深度CNN的第一个努力,并开发了一种deconvolution方法,以更好地理解给定网络的上层已经学会了什么。“Deconvnet”使数据从高层的神经元激活流向图像。在这个过程中,图像中强激活的部分的神经元被突出显示。Springenberg等人[7]将这项工作扩展到guided backpropagation,帮助理解深度网络中每个神经元对输入图像的影响。这些可视化技术在[9]中进行了比较。Yosinski等人[10]提出了一种方法,通过合成输入图像,使神经网络中的特定单元高度激活,以可视化单元的功能。Simonyan等人在[11]中提出了一种更有指导性的方法来合成最大程度激活一个神经元的输入图像。在这项工作中,他们通过在像素空间中进行梯度上升以达到最大值来生成特定类的显著maps。这个合成的图像可以作为特定类的可视化结果,并帮助理解给定的CNN是如何建模类的。
从另一个角度,Ribeiro等人[12]引入了LIME(Local Interpretable Model-Agnostic Explanations),这种方法使用更简单的可解释分类器(如稀疏线性模型或浅决策树)对任何深度模型的复杂决策表面进行局部逼近。对于每一个测试点,分析稀疏线性模型的权值给了一个非专家的关于该特征在特定预测中的相关性的直觉。Shrikumar等人[13]最近提出了DeepLift,通过用离散梯度近似instantaneous梯度(相对于输入的输出的梯度)来评估每个输入神经元对特定决策的重要性。这样就不需要训练可解释分类器来解释每个测试点的每个输入-输出关系(如LIME)。在另一种方法中,AI-Shedivat等人[14]提出了 Contextual Explanation Networks(CENs),这是一类共同学习预测和解释其决策的模型。与现有的posthoc模型解释工具不同,CENs将深层网络与特定环境的概率模型结合起来,并以局部正确假设的形式构建解释。Konam[15]开发了一种算法来检测负责网络决策的特定神经元,并额外定位输入图像中最大程度激活这些神经元的patches。Lengerich等人[16]提出了一种完全不同的方法,在这种方法中,他们不是用输入来解释决策,而是开发了统计度量来评估网络中隐藏的表示与其预测之间的关系。最近的另一项工作是[17],专注于自动驾驶汽车的可解释性,训练了一个视觉注意力模型,然后再训练一个CNN模型,以获得潜在的显著图像区域,并应用causal filtering来找到真正影响输出的输入区域。
尽管最近有了这些发展,但我们离可解释深度学习模型的期望目标还很远,我们仍然需要开发算法来生成跨领域使用的可解释深度学习模型的结果。这些努力的一个关键目标是在将这些系统集成到我们的日常生活中时建立对它们的信任。我们在本文的工作主要是受两种算法的启发,即CAM [2]和Grad-CAM [6],这两种算法是目前[18]中广泛使用的。在CAM中,作者展示了尽管没有经过明确的训练,具有全局平均池化(GAP)层的CNN具有定位能力。在一个带GAP的CNN中,对于一个特定的类c,最终的分类分数Yc可以写成它经过全局平均池化的最后一个卷积层特征映射Ak的线性组合。

然后特定类的显著map Lc的每个空间位置(i,j)可以被计算为:

Lcij与特定类c的特定空间位置(i, j)的重要性直接相关,因此可以作为网络预测的类的可视化解释。CAM通过使用为给定图像生成的最后一个卷积层的激活映射,为每个c类训练一个线性分类器来估计这些权重wkc。但这将其解释能力限制在具有GAP倒数层的CNN上,并且需要在初始模型训练后再训练多个线性分类器(每个类一个)。
Grad-CAM就是为了解决这些问题而建立的。该方法[6]将特定feature map Ak和类c的权重wkc定义为:
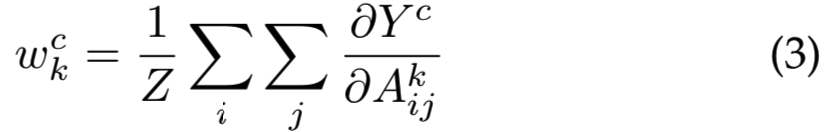
其中Z为常数(即激活map中的像素数量)。因此,Grad-CAM可以与任何深度CNN一起工作,其中最终的Yc是激活map Ak的可微函数,而无需任何再训练或架构修改。为了获得细粒度的像素尺度表示,Grad-CAM显著maps被上采样,并通过点乘与Guided Backpropagation[7]生成的可视化结果融合。这种可视化被称为 Guided Grad-CAM。
然而,这种方法有一些缺点,如图1所示。如果图像包含多个相同的类,Grad-CAM就不能正确地定位图像中的对象。这是一个严重的问题,因为在现实世界中,同一对象在图像中多次出现是非常常见的。偏导数的非加权平均值的另一个后果是,定位通常不对应整个对象,而是它的位和部分。这可能会妨碍用户对模型的信任,并妨碍Grad-CAM使深度CNN更加透明的前提。
在这项工作中,我们提出了一种对Grad-CAM的推广方法,它解决了上述问题,因此可以作为一个给定CNN架构的更好的解释算法,因此我们将所提出的方法命名为Grad-CAM ++。我们推导出该方法的closed-form解,并精心设计实验,以客观和主观地评价Grad-CAM++的能力。在我们的所有实验中,我们将我们的方法与Grad-CAM的性能进行了比较,因为它被认为是目前最先进的CNN判别(class specific saliency maps)可视化技术[18]。下面就开始介绍我们提出的方法,从它的直觉开始。
3 GRAD-CAM++: PROPOSED METHODOLOGY
3.1 Intuition
考虑一个显著map Lc(如等式2中定义的,其中i和j是map 像素上的迭代器)和一个二进制对象分类任务,如果对象不存在,输出为0,如果存在,输出为1。(对于图2中的图像I,网络输出为1)Ak表示第k个feature map的可视化结果。根据之前的工作[1],[19],每个Ak都是由一个抽象的视觉模式触发的。在本例中,如果检测到视觉模式,则Akij = 1,否则为0。(图2中,暗的区域对应Akij = 1)。希望对于导致物体存在的feature map像素来说,导数![]() 是高的。假设导数map为:
是高的。假设导数map为:
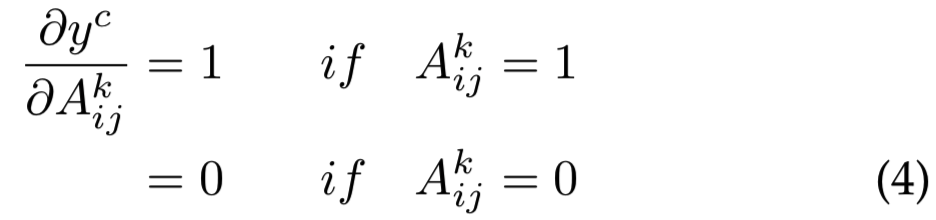
代入等式4中的值到等式3中,我们将获得Grad-CAM实例中给定图像I的feature map权重,三个feature map的权重分别为![]() 。这里Z = 80,即feature map的像素数量。Grad-CAM的显著map Lcgrad-cam可以使用等式2得到(参考图2)。与输入图像I相比,很明显,图像中物体的空间足迹对于Grad-CAM的可视化很重要。因此,如果一个有略微不同的方向或视图的对象(或激发不同feature map的部分对象)多次出现,不同的feature map可能会被不同的空间足迹激活,而具有较小足迹的feature map会在最终的显著map中消失。
。这里Z = 80,即feature map的像素数量。Grad-CAM的显著map Lcgrad-cam可以使用等式2得到(参考图2)。与输入图像I相比,很明显,图像中物体的空间足迹对于Grad-CAM的可视化很重要。因此,如果一个有略微不同的方向或视图的对象(或激发不同feature map的部分对象)多次出现,不同的feature map可能会被不同的空间足迹激活,而具有较小足迹的feature map会在最终的显著map中消失。

这个问题可以通过对像素级梯度求加权平均来解决。因此,通过显式编码权重wck的结构来重构等式3:
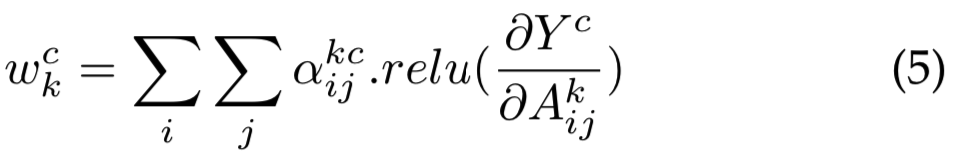
其中relu是Rectified Linear Unit activation function。这里![]() 是类c和卷积feature map Ak的像素梯度的加权系数:
是类c和卷积feature map Ak的像素梯度的加权系数:
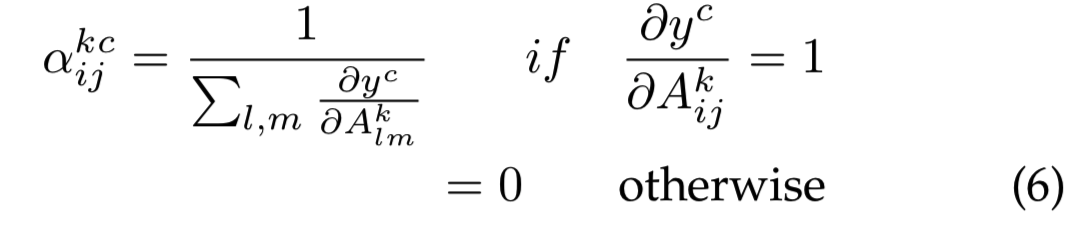
出现在所有feature maps的对象使用相等的重要性,即相等的![]() 来强调。
来强调。
在等式5中只考虑正梯度的想法类似于Deconvolution [1] 和Guided Backpropogation [7]。wck抓住了一个特定的激活图Ak的重要性,我们倾向于认为正梯度指示增加输出神经元的激活的视觉特征,而不是指示抑制输出神经元的激活。对于这一“正梯度”假设的实证验证将在7.1节后面进行。
我们现在介绍所提出的方法。
3.2 Methodology
我们提出一个方法去获得一个特定类c和激活map k的梯度权重![]() 。Yc是一个特定类c的分数。将等式1和等式5结合在一起,得到:
。Yc是一个特定类c的分数。将等式1和等式5结合在一起,得到:

其中,(i,j)和(a,b)是相同激活map Ak的迭代器,用来避免混乱。为了不失一般性,我们在推导中去掉了relu,因为它仅作为允许梯度回流的阈值。等式两边求关于Akij的偏导数:

再进一步求Akij的偏导数:

然后得到:

将该值代入等式5,得到Grad-CAM++的权重:

明显,与等式3对比,如果![]() ,则Grad-CAM++就等价为Grad-CAM。因此Grad-CAM++可以认为是Grad-CAM的广义形式。
,则Grad-CAM++就等价为Grad-CAM。因此Grad-CAM++可以认为是Grad-CAM的广义形式。
原则上,类分数Yc可以是任意预测;唯一的约束条件是Yc必须是光滑函数。由于这个原因,与Grad-CAM(它采用倒数第二层表示作为它们的类分数Yc)不同,我们通过指数函数传递倒数第二层分数,因为指数函数是无限可微的。
在图1中,我们可视化地显示了Grad-CAM++相对于Grad-CAM的优势。三种方法CAM、Grad-CAM和Grad-CAM++的对比可见图3:

3.3 Computation Analysis
计算高阶导数的时间开销与Grad-CAM保持相同的阶数,因为只使用对角项(没有交叉高阶导数)。如果我们通过指数函数传递倒数第二层分数,而最后一层只有线性或ReLU激活函数,那么高阶导数的计算就变得微不足道了。设Sc为c类的倒数第二层分数。
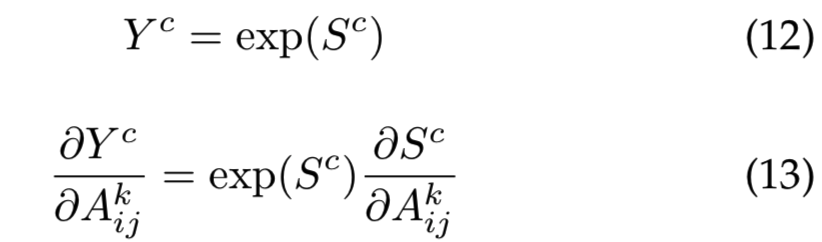
值![]() 可以使用能够实现自动微分的机器学习库TensorFlow和Pytorch得到。
可以使用能够实现自动微分的机器学习库TensorFlow和Pytorch得到。
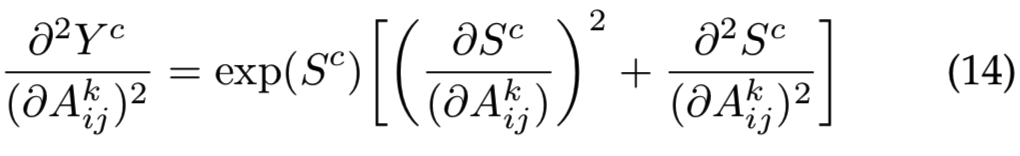
现在,假设一个ReLU激活函数,f(x) = max(x,0),其导数为:
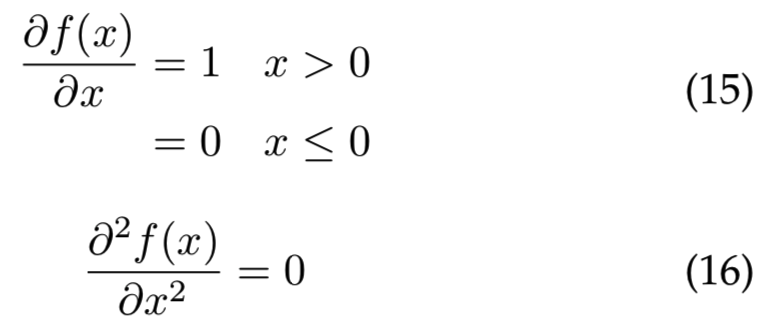
等式16在激活函数是线性函数时都是成立的。将其代入等式14,得到:

将等式17和18代入等式10,得到:

使用计算图中的一个后向传播就能够计算得到所有梯度权重![]() (等式5)。为了简化,我们使用的指数函数。其他光滑函数,如softmax激活函数,也可以带着对应的closed-form表达式来使用,以计算权重。softmax的梯度权重的导数在Section 3.4给出。
(等式5)。为了简化,我们使用的指数函数。其他光滑函数,如softmax激活函数,也可以带着对应的closed-form表达式来使用,以计算权重。softmax的梯度权重的导数在Section 3.4给出。
给定图像的显著maps Lc 以前向激活maps的线性组合计算得到,后面跟着relu层:
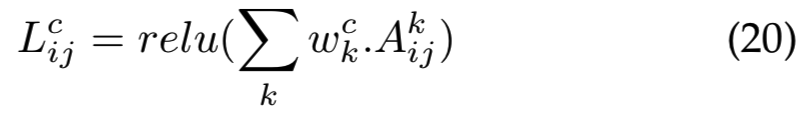
与Grad-CAM类似,为了生成最终的显著maps,我们将上采样(到图像分辨率)的显著maps Lc与Guided Backpropagation生成的像素空间可视化结果进行点乘。因此,生成的表示被称为Guided Grad-CAM++。
3.4 Gradient Weights for Softmax Function
和指数函数一样,softmax函数是平滑的,而且经常在分类场景中使用来获得最后的类概率输出。在这种情况下,最后类分数Yc为:
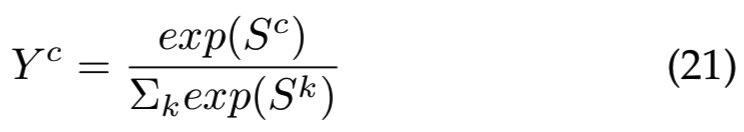
其中索引k遍历所有输出类,而Sk是倒数第二层中与输出类k相关的分数。

如果神经网络只有线性或ReLU激活函数,那么![]() 为0(等式16)
为0(等式16)
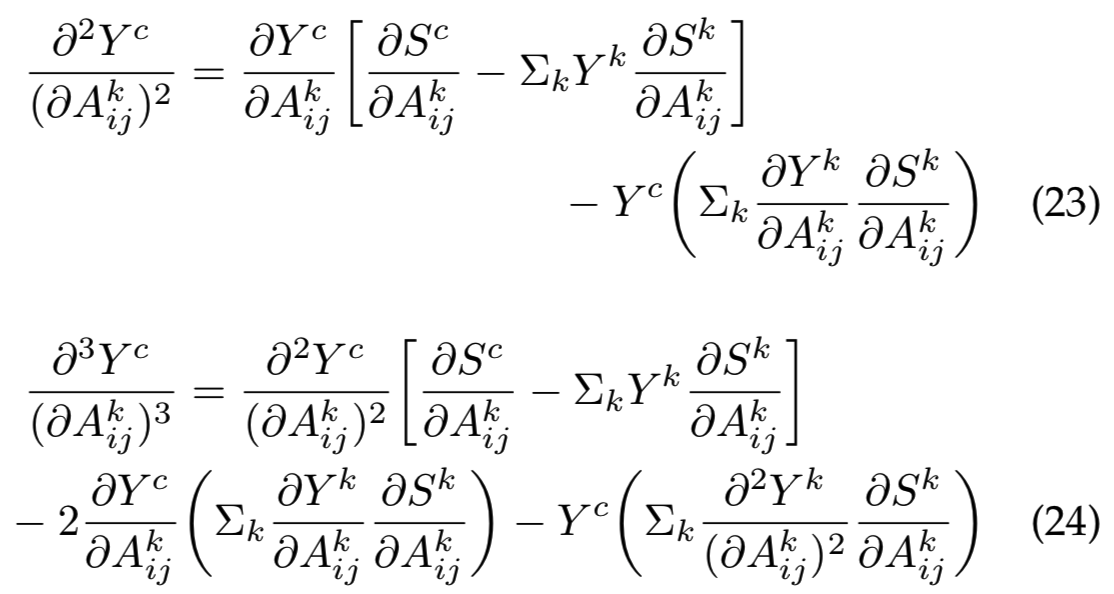
将等式23、24代入等式10,得到梯度权重。注意,尽管在softmax函数的情况下评估梯度权重比指数函数的情况更复杂,它仍然可以通过计算![]() 项的计算图的一次后向传递来计算。
项的计算图的一次后向传递来计算。
4 EXPERIMENTS AND RESULTS
5
6
省略
7 DISCUSSION
7.1 Why only Positive Gradients in Grad-CAM++?
在3.2节中,我们假设正梯度关于激活maps Ak中每个像素的加权组合与给定类c(等式5)的激活map的重要性强相关。在这一节中,我们通过放松梯度的约束来测试这种假设的正确性。我们采用与我们对Pascal VOC 2007 val集进行客观评价研究时使用的相同的VGG-16模型(章节4.1),并使用略有不同的wck重新做实验:
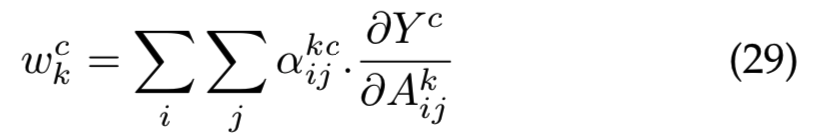
可见移除了relu函数。![]() 如等式10中计算得到,不同之处是,这里对于负梯度,
如等式10中计算得到,不同之处是,这里对于负梯度,![]() 的值不为0,而是:
的值不为0,而是:

我们将其称为Grad-CAM++的修改版,表示为![]() ,其没有和Grad-CAM++一样只使用正梯度。表7可见
,其没有和Grad-CAM++一样只使用正梯度。表7可见![]() 的效果没有Grad-CAM好。该结果支持了我们关于正梯度对于决定给定类c的激活map Ak的重要性是十分重要的假设。
的效果没有Grad-CAM好。该结果支持了我们关于正梯度对于决定给定类c的激活map Ak的重要性是十分重要的假设。

7.2 Does Grad-CAM++ do well because of larger maps?
人们可能会质疑Grad-CAM++做得很好是否是因为每张图片中都有更大的解释maps。一般来说,对于给定的图像I和类c,如果提供给模型作为输入的解释图区域面积更大,我们预计分类分数下降的幅度更小。我们绘制ROC曲线去分别测量Grad-CAM和Grad-CAM++中,遮挡map的空间区域和遮挡后类的相应置信度之间的权衡(即数量![]() , 其中OcI是遮挡图像的新分数,YcI是使用整张图作为输入的原始分数)。阈值参数θ由0到1以等间隔的离散间隔变化以生成曲线。对于给定的θ,遮挡图像分数为
, 其中OcI是遮挡图像的新分数,YcI是使用整张图作为输入的原始分数)。阈值参数θ由0到1以等间隔的离散间隔变化以生成曲线。对于给定的θ,遮挡图像分数为![]()
![]() 。k、j为像素上的迭代器,γ为每个解释区域像素值经验分布的θ-quantile。
。k、j为像素上的迭代器,γ为每个解释区域像素值经验分布的θ-quantile。![]() 。每个图像的经验分布分别计算,然后在数据集上求平均。图10显示了结果。我们可以观察到,在每一个quantile(θ),无论空间范围如何,Grad-CAM++突出显示的区域与Grad-CAM一样忠实或更忠实于基础模型。
。每个图像的经验分布分别计算,然后在数据集上求平均。图10显示了结果。我们可以观察到,在每一个quantile(θ),无论空间范围如何,Grad-CAM++突出显示的区域与Grad-CAM一样忠实或更忠实于基础模型。

8 CONCLUSION
在这项工作中,我们提出了一种基于CNN架构的可视化解释的通用方法,Grad-CAM++。我们为我们的方法提供了一个推导,并表明它是早期广泛使用的基于梯度的视觉解释方法的一个简单但有效的推广版本。我们的方法解决了Grad-CAM的缺点——特别是图像中类的多次出现和对象定位不佳。我们使用著名的标准CNN模型和数据集(ImageNet和Pascal VOC),客观地(对被解释的模型的忠实性)和主观地(调用人类信任)验证了我们的方法的有效性。我们还证明了Grad-CAM++在图像标题生成和视频理解(动作识别)等任务上也有优势。在第5节中,我们提出了一个研究方向,深度网络的解释不仅用于理解模型决策背后的推理,还用于训练较浅的学生网络。学生网络在运用解释方法提取知识时,比原来的教师网络学习了更好的表示(较低的测试错误率)。未来的工作包括在teacher-student场景中细化损失公式,以便更有效地通过Grad-CAM++的解释提取知识。我们也希望在一张图中有多个类的情况下更详细地研究该方法,以及探索扩展我们的算法来解释由其他神经网络架构,如递归神经网络、short-term memory网络和生成对抗网络,产生的决策的可能性。