Aggregated Residual Transformations for Deep Neural Networks
Abstract
我们提出了一个简单的、高度模块化的图像分类网络架构。我们的网络是通过重复一个构建块来构建的,该构建块聚合了一组具有相同拓扑结构的转换(transformations)。我们的简单的设计得到一个均匀的多分支结构,只有设置了少数的超参数。这种策略使一个新的维度,我们称之为“cardinality”(转换集的大小),成为了除了深度(depth)和宽度(width)维度外的另一个必不可少的因素。在ImageNet-1K数据集上,我们的经验表明,即使在保持复杂度的限制条件下,增加cardinality也能提高分类精度。此外,当我们增加容量时,增加cardinality比增加深度或宽度有效。我们命名为ResNeXt的模型是我们进入ILSVRC 2016分类任务的基础,我们在该任务中获得了第二名。我们在ImageNet-5K集合和COCO检测集合上对ResNeXt进行了进一步的研究,也显示出了比ResNet更好的结果。代码和模型在网上公开。
1. Introduction
视觉识别研究正从“特征工程”向“网络工程”过渡[25,24,44,34,36,38,14]。与传统手工设计的特征(例如,SIFT[29]和HOG[5])相比,神经网络从大规模数据[33]中学习的特征在训练过程中需要最少的人力参与,并且可以转移到各种识别任务中[7,10,28]。然而,人类的努力的重点已经转移到为学习表征设计更好的网络架构上。
随着超参数(width2, filter size, strides etc.)的增多,尤其是在有许多层的情况下,设计架构变得越来越困难。VGG-nets[36]展示了一种构建深度网络的简单而有效的策略:即堆叠相同形状的构建块。ResNets[14]继承了这个策略,它的堆叠模块具有相同的拓扑。这个简单的规则减少了超参数的自由选择,而深度被作为神经网络的一个基本维度。此外,我们认为,该规则的简单性可以减少过度调整超参数以适应特定数据集的风险。VGGnets和ResNets的鲁棒性已经被各种视觉识别任务[7,10,9,28,31,14]和包括语音[42,30]和语言[4,41,20]的非视觉任务证明。
与VGG-nets不同,Inception模型家族[38,17,39,37]已经证明了精心设计的拓扑能够在低理论复杂度的情况下实现引人注目的精确性。Inception模型随着时间而发展[38,39],但是一个重要的共同属性是split-transform-merge策略。在Inception模块中,输入被分成几个低维的嵌入(通过1×1的卷积),通过一组专门的过滤器(3×3,5×5等)进行转换,然后通过串联进行合并。可以看出,该架构的solution空间相当于在高维嵌入上运行一个大层(如5×5)的solution空间的严格子空间。Inception模块的split-transform-merge行为被期望能接近大而密集的层的表现能力,且仅使用相对低的计算复杂度。
尽管有良好的准确性,在Inception模型的实现伴随着一系列复杂的因素——过滤器的数量和大小是为每个单独的转换而定制的,模块是逐步定制的。虽然这些组件的仔细组合产生了优秀的神经网络配方,但一般不清楚如何使Inception架构适应新的数据集/任务,特别是当有许多因素和超参数需要设计的时候。
在本文中,我们提出了一个简单的架构,它采用了VGG/ResNets的重复层策略,同时以一种简单、可扩展的方式利用了split-transform-merge策略。我们的网络中的一个模块执行一组转换,每个转换都是低维的嵌入,其输出通过求和进行聚合。我们追求这个想法的一个简单实现——要被聚合的转换都是相同的拓扑(例如,图1(右))。这种设计允许我们扩展到任何大量的转换,而不需要专门的设计。
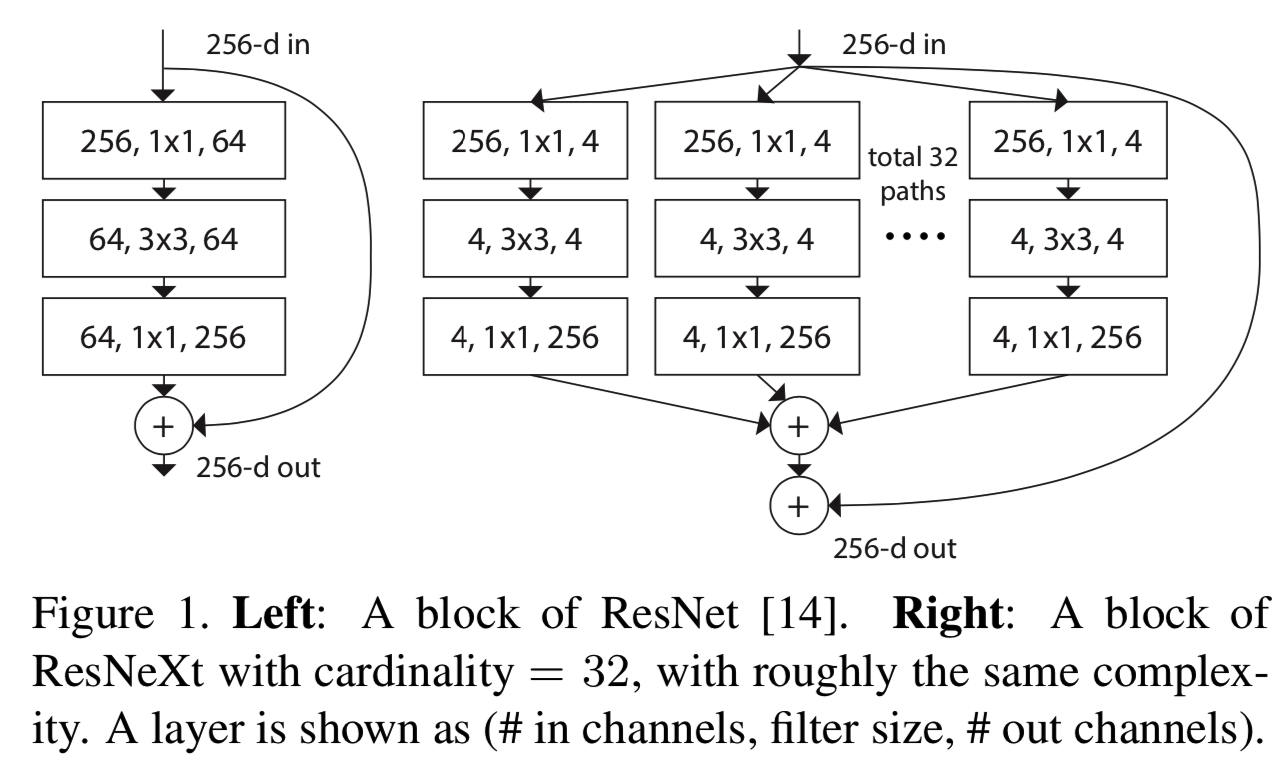
有趣的是,在这种简化的情况下,我们发现我们的模型还有另外两种等价形式(图3)。图3(b)中的重构形式与Inception-ResNet模块[37]相似,因为它连接了多条路径;但是我们的模块不同于所有已有的Inception模块,因为我们所有的路径共享相同的拓扑,因此可以很容易地将路径的数量隔离为一个要研究的因素。在更简洁的重构中,我们的模块可以通过Krizhevsky等人的分组(grouped)卷积[24](图3(c))进行重塑,但这是一种工程折衷手段。
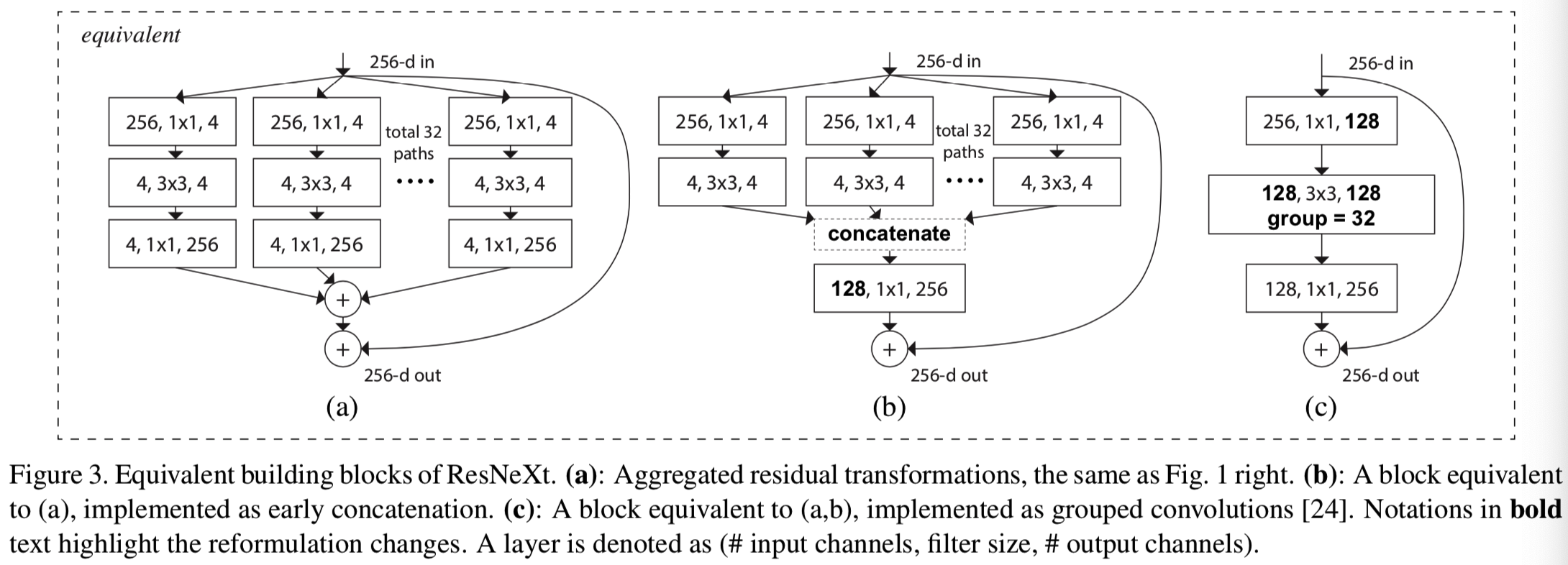
我们的经验证明,我们的聚合转换优于原来的ResNet模块,即使在保持计算复杂度和模型大小的限制条件下-例如,图1(右)是设计来保持图1(左)的FLOPs复杂性和参数的数量的。我们强调,虽然通过增加容量(更深入或更广)来提高精确度相对容易,但在文献中,在保持(或减少)复杂性的同时提高精确度的方法很少。
我们的方法表明,cardinality(转换集的大小)是一个具体的、可测量的维数,除了宽度和深度的维数之外,它是最重要的。实验表明,增加cardinality比增加深度或宽度更能有效地获得精度,特别是当深度和宽度的增加对现有模型的回报开始递减时。
我们命名为ResNeXt(表示next dimension)的神经网络在ImageNet分类数据集上的表现优于ResNet-101/152[14]、ResNet-200[15]、incection-v3[39]和incection-resnet -v2[37]。特别地,一个101层的ResNeXt能够达到比ResNet-200[15]更好的精度,但只有50%的复杂性。此外,ResNeXt的设计比所有的Inception模型都要简单得多。ResNeXt是我们提交给ILSVRC 2016分类任务的基础,获得了第二名的成绩。本文在更大的ImageNet-5K集合和COCO目标检测数据集[27]上对ResNeXt进行了进一步的评估,结果显示其准确性始终优于ResNet的对照物。我们期望ResNeXt也能很好地推广到其他视觉(和非视觉)识别任务。
2. Related Work
Multi-branch convolutional networks. Inception模型[38,17,39,37]是成功的多分支架构,其中每个分支都是精心定制的。ResNets[14]可以被认为是两个分支网络,其中一个分支是恒等映射。深度神经决策森林[22]是具有学习split函数的树状多分支网络。
Grouped convolutions. 分组卷积的使用可以追溯到AlexNet的论文[24]。Krizhevsky等[24]给出的动机是为了将模型分布在两个gpu上。分组卷积是由Caffe [19], Torch[3]和其他库支持移植的,主要是为了兼容AlexNet。就我们所知,几乎没有证据表明利用分组卷积能提高精度。分组卷积的一种特殊情况是通道级卷积,其中组的数量等于通道的数量。通道级卷积是[35]中可分离卷积的一部分。
Compressing convolutional networks. 分解(在空间[6,18]和/或通道[6,21,16]上)是一种广泛采用的降低深度卷积网络冗余和加速/压缩的技术。Ioannou等[16]提出了一种减少计算量的“root”模式网络,根中的分支通过分组卷积来实现。这些方法[6,18,21,16]在降低复杂度和较小模型尺寸的情况下显示出了优雅的精度折衷。与压缩不同,我们的方法是一个在经验上显示更强表示的架构。
Ensembling. 对一组独立训练的网络进行平均是提高精度[24]的有效解决方案,在[33]识别比赛中被广泛采用。Veit等人[40]将单一ResNet解释为较浅网络的集合,这是ResNet的相加行为[15]的结果。我们的方法利用加法来聚合一组转换。但我们认为,将我们的方法视为集合是不精确的,因为要聚集的成员是共同训练的,而不是独立的。
3. Method
3.1. Template
我们遵循VGG/ResNets,采用高度模块化的设计。我们的网络由一堆残差块组成。这些块具有相同的拓扑,和有受到VGG / ResNets启发的两个简单的规则: (i)如果产生相同大小的空间map,块共享相同的超参数(宽度和过滤器的大小),和(2)每次当空间map下采样2块时,宽度则乘以2倍。第二个规则确保所有块的计算复杂度,即FLOPs(floating-point operations, in # of multiply-adds)大致相同。
有了这两条规则,我们只需要设计一个模板模块,就可以据此确定网络中的所有模块。因此,这两条规则极大地缩小了设计空间,并允许我们关注几个关键因素。由这些规则构建的网络如表1所示。

3.2. Revisiting Simple Neurons
人工神经网络中最简单的神经元执行内积(加权和),这是由全连接层和卷积层完成的基本变换。内积可以认为是一种聚合变换的形式:

其中,x = [x1, x2,…, xD]是神经元的D通道输入向量,wi是第i个通道的滤波器权值。这种操作(通常包括一些输出非线性)被称为“neuron(神经元)”。参见图2。

上面的操作可以被重建成splitting、transforming和aggregating。(i)Splitting:向量x被分成一个低维embedding,如图2所示,成一个个单维的子空间xi。 (ii)Transforming:低维表征被转换,图2所示,被简单地缩放:wixi。(iii)Aggregating:在所有embeddings上的转换通过![]() 被聚合在一起。
被聚合在一起。
3.3. Aggregated Transformations
鉴于上述对一个简单神经元的分析,我们考虑用一个更通用的函数代替初等变换(wixi),它本身也可以是一个网络。与“Network-in-Network”[26]增加了depth维度相反,我们展示了我们的“Network-in-Neuron”沿着一个新的维度扩展。
形式上,我们将聚合变换表示为:

其中![]() 可以是一个任意函数。类比一个简单的神经元,
可以是一个任意函数。类比一个简单的神经元,![]() 应该投射x到一个embedding(optionally low-dimensional),然后转换他
应该投射x到一个embedding(optionally low-dimensional),然后转换他
在等式(2)中,C是要聚合的转换集的大小。我们称C为cardinality[2]。但等式(2)的C不需要等于等式(1)的D,可以是任意数。当宽度的维数与简单变换的数目(内积)有关时,我们认为cardinality的维度能控制更复杂变换的数目。我们通过实验证明cardinality是一个基本的维数,可以比宽度和深度的维数更有效。
在本文中,我们考虑了一种设计变换函数的简单方法:所有的![]() 具有相同的拓扑。这扩展了重复相同形状的层的vgg-style策略,这有助于隔离一些因素,并扩展到任何大量的转换。我们将单个转换
具有相同的拓扑。这扩展了重复相同形状的层的vgg-style策略,这有助于隔离一些因素,并扩展到任何大量的转换。我们将单个转换![]() 设置为瓶颈型架构[14],如图1(右)所示。在这种情况下,在每个
设置为瓶颈型架构[14],如图1(右)所示。在这种情况下,在每个![]() 的第一层1×1产生低维嵌入。
的第一层1×1产生低维嵌入。
等式(2)的聚合转换被当作残差函数[14](如图1 右):

其中y是输出
Relation to Inception-ResNet. 一些张量操作表明,图1(右)(图3(a))中的模块与图3(b)是等价的。图3(b)与inception- resnet[37]块类似,因为它在残差函数中涉及分支和连接。但与所有的Inception或inception-resnet模块不同,我们在多个路径中共享相同的拓扑。我们的模块在设计每个路径时只需要最少的额外工作。
Relation to Grouped Convolutions. 上面的模块使用分组卷积[24]表示法变得更加简洁。图3(c)说明了这种重新表述。所有的低维嵌入(1×1层)都可以被一个更宽的单层取代(如图3(c)中的1×1,128-d)。当分组卷积层将输入通道分成组时,splitting本质上是由分组卷积层完成的。图3(c)中的分组卷积层执行32组卷积,其输入和输出通道都是四维的。分组卷积层将它们连接起来作为层的输出。图3(c)中的模块与图1(左)中原有的瓶颈残差模块相似,但图3(c)是一个较宽但稀疏连接的模块。
我们注意到,只有当块的depth≥3时,重构才会产生非凡拓扑。如果块的深度为2(例如,[14]中的基本块),重新计算将导致一个很普通的宽的、密集的模块。参见图4中的说明。
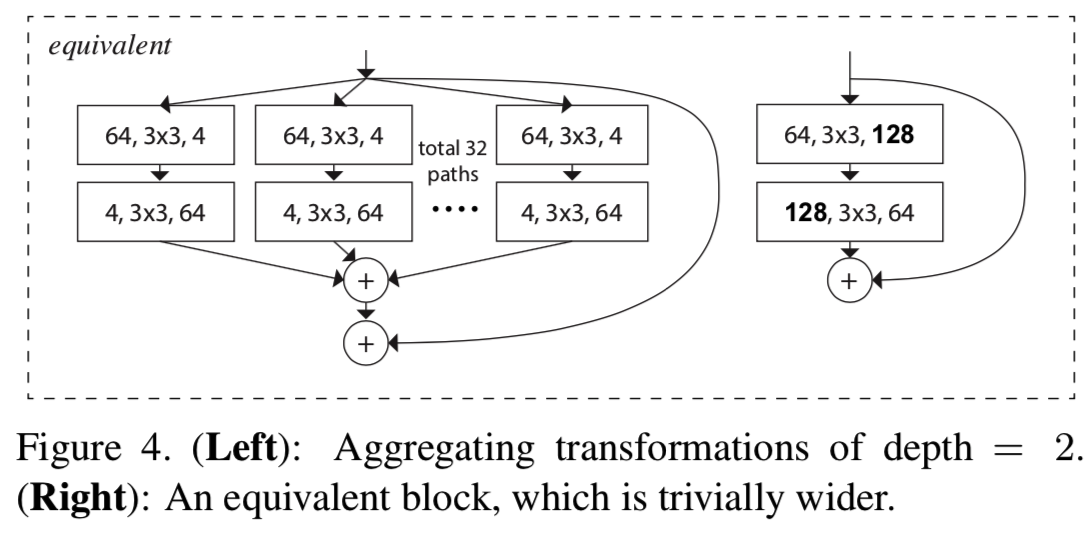
Discussion. 我们注意到,虽然我们提出的重构表现为串联(图3(b))或分组卷积(图3(c)),但这种重构并不总是适用于一般形式的等式(3),例如,如果变换![]() 采取任意形式且是异质的。我们在本文中选择使用齐次形式,因为它更简单,可扩展。在这种简化的情况下,图3(c)形式的分组卷积有助于简化实现。
采取任意形式且是异质的。我们在本文中选择使用齐次形式,因为它更简单,可扩展。在这种简化的情况下,图3(c)形式的分组卷积有助于简化实现。
3.4. Model Capacity
下一节的实验将显示,在保持模型复杂性和参数数量时,我们的模型将提高准确性。这不仅在实践中很有趣,而且更重要的是,参数的复杂性和数量代表了模型的内在能力,因此经常作为深层网络[8]的基本属性进行研究。
我们在保持复杂性的同时, 评估不同的cardinalities,我们希望最小化对其他超参数的修改。我们选择调整bottleneck的宽度(例如图1(右)中的4-d),因为它可以从块的输入和输出中分离出来。这个策略不会改变其他超参数(块的深度或输入/输出宽度),因此有助于我们关注cardinality的影响。
在图1(左)中,原ResNet瓶颈块[14]的参数为256·64+3·3·64·64+64·256≈70k(在相同的feature map尺寸上)。当瓶颈宽度为d时,我们在图1(右)中的模板有:
![]()
个参数和成比例的FLOPs。
当C = 32, d = 4时,等式(4)≈70k。表2显示了cardinality C和瓶颈宽度d之间的关系。

因为我们采用了第3.1节中的两个规则,所以上面的近似等式在ResNet bottleneck块和我们所有阶段的ResNeXt(除了特征图大小变化的子采样层)之间都是有效的。表1比较了原始的ResNet-50和容量类似的ResNeXt-50。5我们注意到复杂度只能大致保留,但复杂度的差异很小,不会影响我们的结果。
4. Implementation details
我们的实现遵循[14]和公开可用的fb.resnet.torch代码[11]。在ImageNet数据集上,输入图像是由[11]实现[38]的缩放和高宽比数据增强后,从一幅resized图像中随机裁剪出来的224×224。除了那些增加维度的连接,叫做projections连接([14]中的B类型)外,其他的shortcuts是恒等连接。按照[11]的方法,通过在每个stage的第一个块的3×3层进行stride-2卷积, 对conv3、4、5实现下采样。我们使用的SGD在8个GPU上有256个mini-batch(32个GPU)。权重衰减是0.0001,momentum是0.9。我们从0.1的学习率开始,使用[11]中的schedule将它除以10三次。我们采用[13]的权值初始化。在所有消融比较中,我们评估单幅从短边为256的图像中心剪裁的224×224的误差。
我们的模型由图3(c)的形式实现。我们在图3(c)中的卷积之后执行批处理归一化(BN)[17]。ReLU是在每个BN之后执行的,除了代码块的输出之外,这里的ReLU是在和shortcut相加之后执行的,如[14]。
我们注意到,当BN和ReLU如上所述地被适当处理时,图3中的三种形式是严格等价的。这三种形式我们都训练过了,结果是一样的。我们选择图3(c)来实现,因为它比其他两种形式更简洁、更快。
5. Experiments
5.1. Experiments on ImageNet-1K
我们在1000级ImageNet分类任务[33]上进行了消融实验。我们按照[14]构建50层和101层残差网络。我们只是将ResNet-50/101中的所有块替换为我们的块。
Notations. 因为我们采用了在3.1节中的两个规则,所以通过模板引用架构就足够了。例如,表1显示了一个由cardinality= 32,bottleneck width= 4d的模板构造的ResNeXt-50(图3)。为了简单起见,我们将该网络记为ResNeXt-50(32×4d)。我们注意到模板的输入/输出宽度固定为256维(图3),每次对feature map进行采样时,所有宽度都加倍(见表1)。
Cardinality vs. Width. 我们首先评估在保留复杂性的情况下,cardinality C和bottleneck width之间的权衡,如表2所示。结果如表3所示,误差与epoch的关系曲线如图5所示。与ResNet-50(表3上、图5左)相比,32×4d的ResNeXt-50验证误差为22.2%,比ResNet基线的23.9%降低1.7%。cardinality C从1增加到32,同时保持复杂性,错误率不断降低。此外,32×4d的ResNeXt的训练误差也比对应的ResNet小得多,说明增益不是来自正则化,而是来自更强的表示。

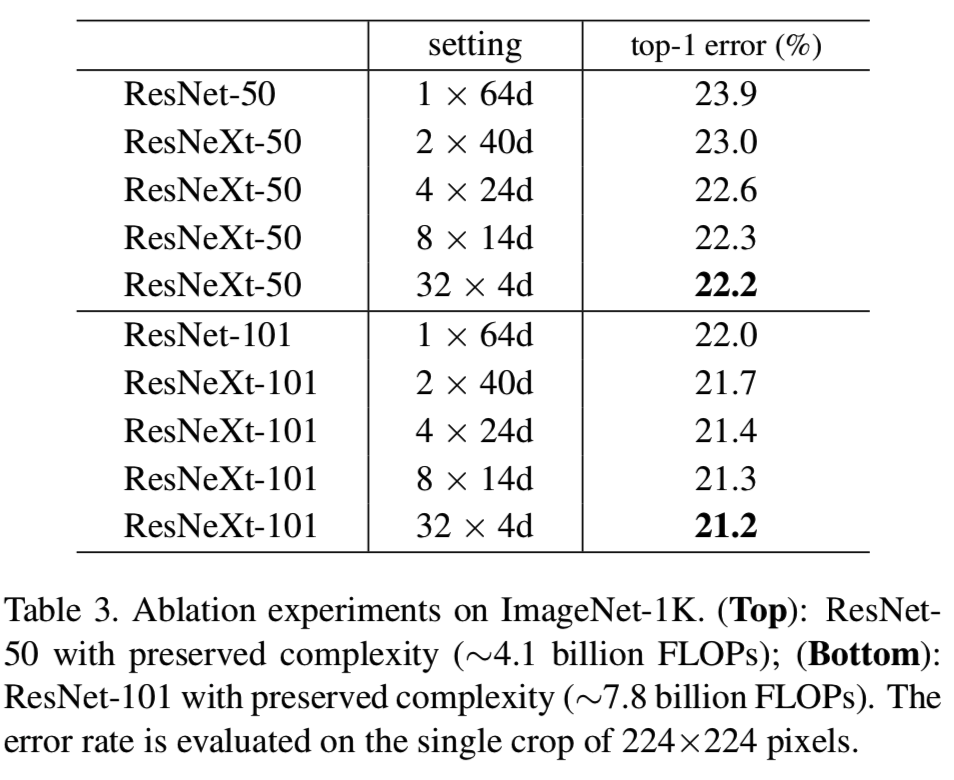
同样的趋势也出现在ResNet-101中(图5右,表3底),其中32×4d的ResNeXt-101比对应的ResNet-101表现好0.8%。虽然验证误差的提高比50层的情况小,但是训练误差的提高仍然很大(ResNet-101提高了20%,32×4d的ResNeXt-101提高了16%,图5右)。事实上,更多的训练数据将扩大验证错误的差距,正如我们在下一小节中的ImageNet-5K集所显示的那样。
表3还表明,在保持复杂性的情况下,以减少宽度为代价增加cardinality开始在瓶颈宽度较小时显示饱和精度(即精度下降的程度变小了)。我们认为,在这种权衡中继续减少宽度是不值得的。所以下面我们采用不小于4d的瓶颈宽度。
Increasing Cardinality vs. Deeper/Wider. 接下来,我们研究通过增加cardinalityC或增加深度或宽度来增加复杂性。下面的比较也可以看作是参照ResNet-101基线的2×FLOPs。我们比较一下下面的变体,它们有大约150亿的FLOPs。(i)深入200层。我们采用在[11]中实现的resnet-200[15]。(ii)扩大瓶颈宽度。(三)通过C翻倍来增加cardinality 。
表4显示,相对于ResNet-101基线(22.0%),复杂性增加2倍一致地减少了错误。但当进一步深入(ResNet-200,涨幅为0.3%)或进一步扩大宽度(ResNet-101,涨幅为0.7%)时,涨幅很小。
相反,增加cardinality C比增加深度和宽度显示更好的结果。采用2×64d ResNeXt-101(即在1×64d ResNet-101基线上将C翻倍并保持宽度)可将top-1误差降低1.3%至20.7%。64 * 4d ResNeXt-101(即在32 * 4d ResNeXt-101上将C加倍,保持宽度不变)将top-1误差降低到20.4%。
我们还注意到,32 * 4d的ResNet-101(21.2%)的性能优于更深的ResNet-200和更宽的ResNet-101,尽管它的复杂性只有约50%。这再次表明cardinality比深度和宽度维度更有效。
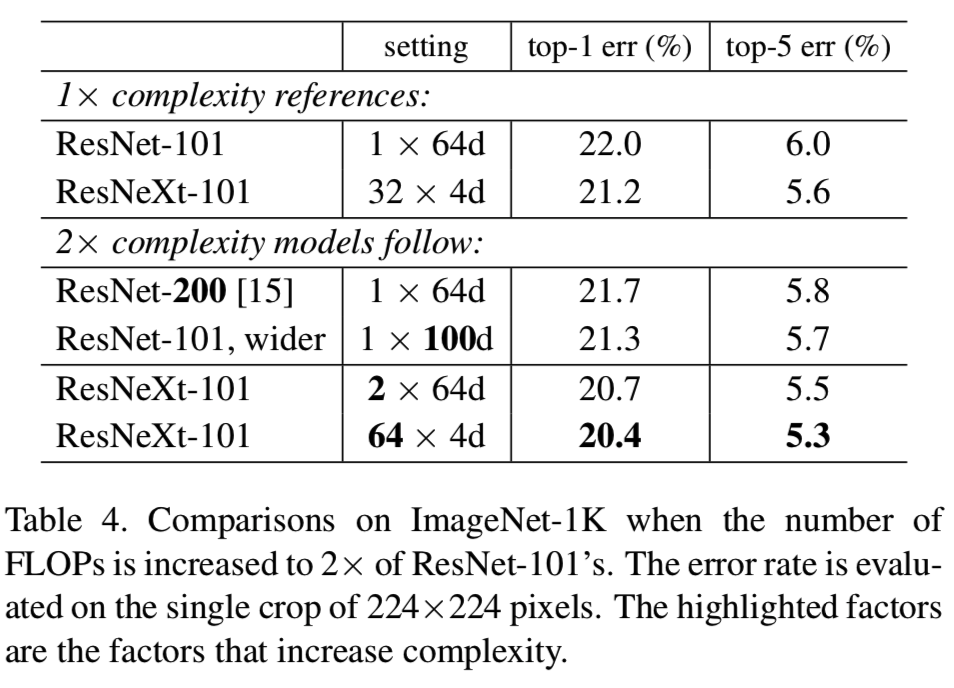
Residual connections. 下表显示了残差(shortcut)连接的效果:
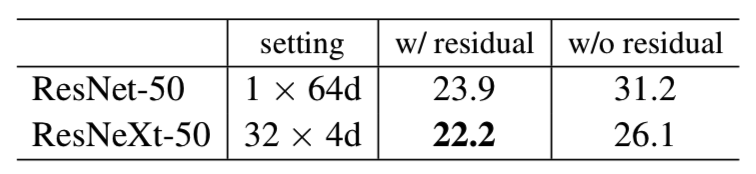
从ResNeXt-50删除shortcuts会使错误增加3.9个百分点,达到26.1%。而从ResNet-50中删除shortcuts则要糟糕得多(31.2%)。这些比较表明残差连接有助于优化,而聚合转换是更强的表示,这一点可以从以下事实看出:它们始终比有或没有残差连接的转换执行得更好。
Performance. 为了简单起见,我们使用Torch内置的分组卷积实现,没有特殊的优化。我们注意到,这个实现是暴力的,并且对并行不友好。在NVIDIA M40的8个gpu上,训练 表3中的32×4d ResNeXt-101,每个mini-batch需要0.95s,相比之下,有类似FLOPs的ResNet-101基线需要0.70s。我们认为这是合理的开销。我们期望精心设计的低层实现(例如,在CUDA中)将减少这种开销。我们还希望cpu上的推理时间能够表现更小的开销。训练2倍的复杂模型(64 * 4d ResNeXt-101),每个mini-batch需要1.7秒,在8个gpu上总共需要10天。
Comparisons with state-of-the-art results. 表5显示了ImageNet验证集上single-crop试验的更多结果。除了试验224×224 crop外,我们还评估了如[15]的320×320 crop。与ResNet、inception-v3/v4和inception-ResNet-v2相比,我们的结果良好,single-crop top-5达到4.4%。此外,我们的架构设计比所有的Inception模型简单得多,并且手工设置所需的超参数要少得多。
ResNeXt是我们进入ILSVRC 2016分类任务的基础,我们在其中获得了第二名。我们注意到,在使用multi-scale和/或multi-crop测试后,许多模型(包括我们的模型)在这个数据集上开始饱和。使用[14]中的multi-scale密集测试,单模型top-1/top-5 error为17.7%/3.7%,与inception-resnet-v2采用multi-scale、multi-crop测试的single-model结果17.8%/3.7%相一致。在测试集上,我们得到了3.03%的top-5 error的集成结果,与获胜者的2.99%和inception-v4/ inception-resnet -v2的3.08%[37]相当。

5.2. Experiments on ImageNet-5K
ImageNet-1K上的性能似乎达到饱和。但我们认为,这并不是因为模型的能力,而是因为数据集的复杂性。接下来,我们在拥有5000个类别的更大的ImageNet子集上评估我们的模型。
我们的5K数据集是整个ImageNet-22K集合[33]的子集。5000类别由原ImageNet-1K类别和额外的4000个在整个ImageNet中有着最多图像数量的类别组成。5K集有680万图片,大约是1K数据集的5倍。没有官方的train/val split可用,所以我们选择评估原始ImageNet-1K验证集。测试时,在1K-class验证集中,可以将模型评估为一个5K-way分类任务(所有预测为其他4K类的标签都是错误的)或一个1K-way分类任务(softmax仅应用于1K个类)。
实现细节与第4节相同。5K-training模型都是从零开始训练的,与1K-training模型的mini-batches数量相同(即1/5×epoch)。表6和图6为保留复杂度下的比较结果。与ResNet-101相比,ResNeXt-50将5K-way top-1错误降低3.2%,ResNetXt-101将5K-way top-1错误降低2.3%。在1k-way误差上观察到类似的差距。这些都说明了ResNeXt更强的表示能力。
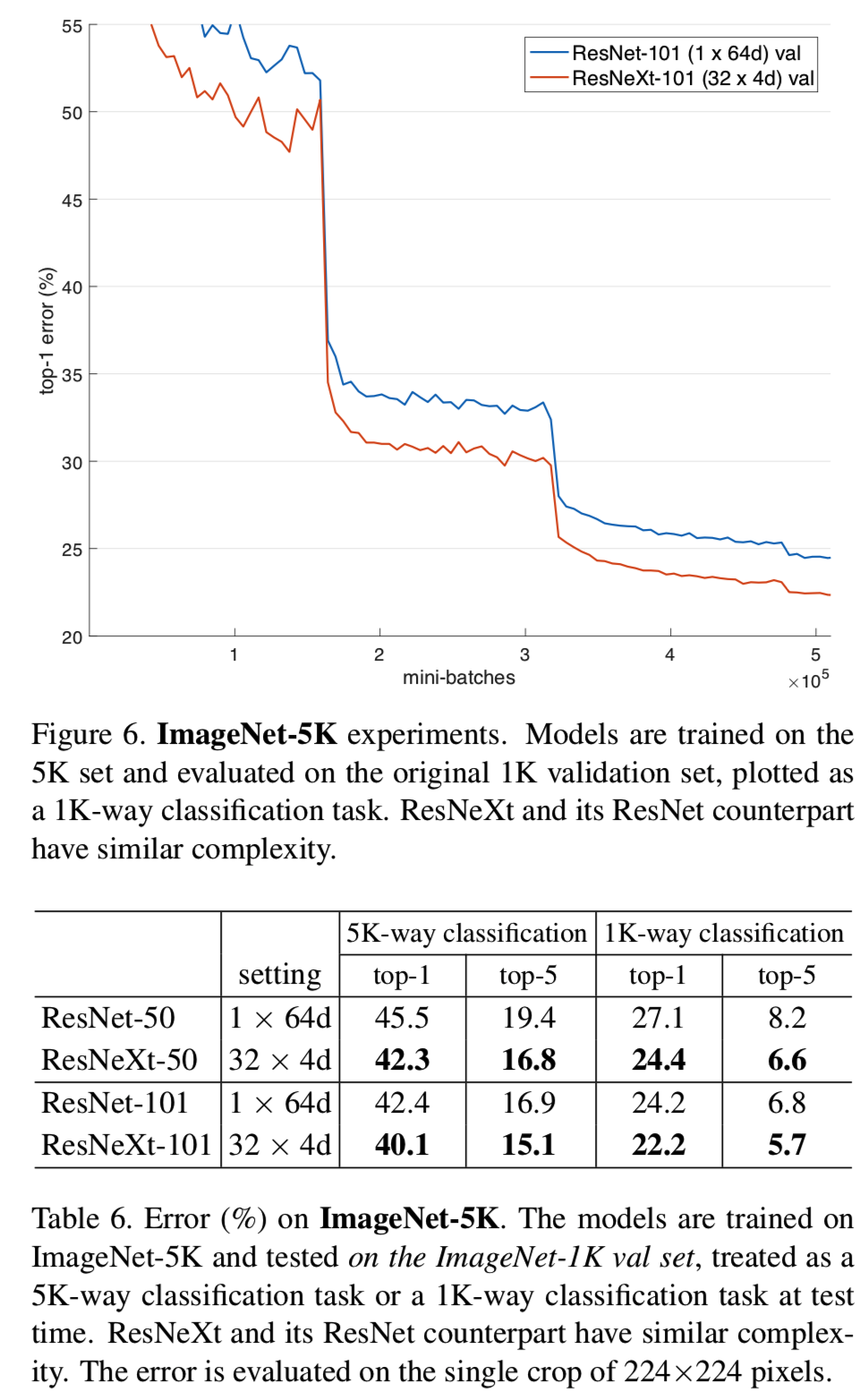
此外,我们发现训练在5K集的模型 (在表6,1K error 为 22.2%/5.7%)与训练在1K集上的模型(21.2%/5.6%)具有竞争性,两者都评估在相同1K分类任务验证集。这个结果没有增加训练时间(由于相同数量的mini-batches),也没有使用微调。考虑到对5K个类别进行分类的训练任务更具挑战性,我们认为这是一个有希望的结果。
5.3. Experiments on CIFAR
我们在CIFAR-10和100数据集[23]上执行更多实验。我们使用如[14]中的架构,并使用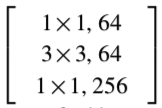 的bottleneck模版替代基础的残差块。遵循[14],我们的网络从一个3x3的卷积层开始,后面跟着3个stages,每个stage有3个残差块,并以平均池化层和全连接分类器结尾(一共29层)。我们采用与[14]相同的平移和翻转数据增强方法。实现细节在附录中。
的bottleneck模版替代基础的残差块。遵循[14],我们的网络从一个3x3的卷积层开始,后面跟着3个stages,每个stage有3个残差块,并以平均池化层和全连接分类器结尾(一共29层)。我们采用与[14]相同的平移和翻转数据增强方法。实现细节在附录中。
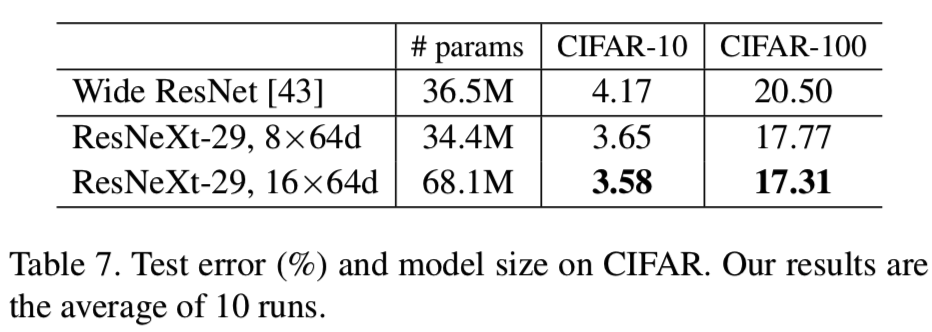
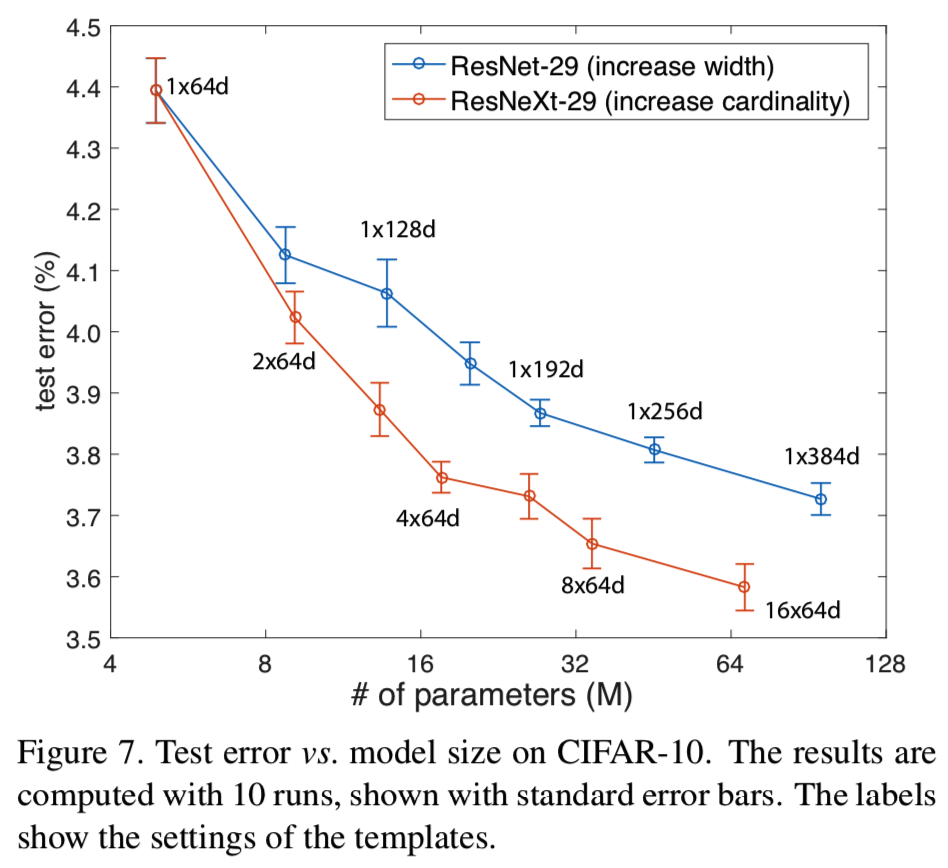
我们比较了基于上述基线增加复杂性的两种情况:(i)增加cardinality并固定所有宽度,或者(ii)增加bottleneck的宽度并固定cardinality= 1。我们在这些变化下训练和评估一系列的网络。图7显示了测试错误率与模型大小的比较。我们发现增加cardinality比增加宽度更有效,这与我们在ImageNet-1K上观察到的一致。表7显示了结果和模型大小,并与已发表的最佳记录的Wide ResNet[43]进行了比较。我们的模型具有相似的模型尺寸(34.4M),显示出比Wide ResNet更好的结果。我们更大的方法在CIFAR-10上达到3.58%的测试错误(平均10次运行),在CIFAR-100上达到17.31%。据我们所知,这些是文献(包括未发表的技术报告)中最先进的结果(具有类似的数据增加)。
5.4. Experiments on COCO object detection
接下来,我们评估在COCO目标检测集[27]的泛化性。遵循[1], 我们在加上35k val子集的80k训练集上训练模型,并在5k val子集(称为minival)上评估。我们评估了COCO-style平均精度(AP)以及AP@IoU =0.5[27]。我们采用basic Faster R-CNN[32],并遵循[14]插入ResNet/ResNeXt。模型在ImageNet-1K上进行了预训练,在检测集上进行了微调,实现细节在附录中。
表8显示了这些比较。在50层基线上,ResNeXt将AP@0.5提高了2.1%,AP提高了1.0%,而没有增加复杂性。ResNeXt显示了对101层基线的较小改进。我们推测,训练数据越多,差距越大,在ImageNet-5K集合上可以观察到这一点。
值得注意的是,最近在Mask R-CNN[12]中使用了ResNeXt,在COCO实例分割和目标检测任务上取得了最先进的结果。