https://github.com/facebookresearch/multigrain
MultiGrain: a unified image embedding for classes and instances
Abstract
MultiGrain是一种网络架构,产生的紧凑向量表征,既适合于图像分类,又适合于特定对象的检索。它建立在一个标准分类主干上。网络的顶部产生包含粗粒度和细粒度信息的嵌入,这样就可以根据对象类别、特定对象或是否失真的副本对图像进行识别。我们的联合训练很简单:在数据增加的情况下,我们尽量减少用于分类的交叉熵损失和决定两幅图像是否相同的排序损失,而不需要额外的标签。MultiGrain的一个关键组成部分是池化层,它在用较低分辨率图像训练的网络中使用高分辨率图像。
当输入一个线性分类器时,学习的嵌入提供最先进的分类精度。例如,通过在Imagenet上学习的ResNet-50,我们获得了79.4%的top-1精度,比AutoAugment方法有+1.8%的绝对改进。当与余弦相似度比较时,相同的嵌入性能与最先进的图像检索在中等分辨率中是同等的。
1. Introduction
图像识别是计算机视觉的核心,每年都有几十种新方法被提出,每种方法都针对问题的特定方面进行优化。从粗到细,我们可以区分(a)类(classes),即寻找一个特定类型的对象,不管内部类变化,(b)实例(instance),即在变化的观察条件下寻找一个特定的对象,和(c)副本(copies),即寻找一份特定图像的副本(尽管被编辑)这三种情况的识别。虽然这些问题在许多方面是相似的,但是标准的做法是对每种情况使用专门化的,因此是不兼容的图像表征。
专门化表征可能是准确的,但在某些应用程序中构成了一个重要的瓶颈。以图像检索为例,其目标是将查询图像匹配到包含其他图像的大型数据库。通过按类、实例或副本匹配查询,人们常常希望使用多个粒度搜索相同的数据库。图像检索系统的性能主要取决于所使用的图像嵌入。这就需要在数据库大小、匹配和索引速度以及检索准确性之间进行权衡。采用多个嵌入(针对每种类型的查询进行了狭义优化)意味着资源使用成倍增加。
在本文中,我们提出了一种新的表示,MultiGrain,它可以同时实现这三个任务,而不考虑它们的语义粒度差异,如图1所示。我们通过联合训练一个多任务的图像嵌入来学习MultiGrain。结果表征是紧凑的,并优于narrowly-trained嵌入。

实例检索具有广泛的工业应用,包括检测受版权保护的图像和看不见的物体基于样本的识别。在需要处理数十亿幅图像的情况下,获得适合多个识别任务的图像嵌入是很有意义的。例如,除了检测相同对象的副本或实例之外,图像存储平台可能会对输入图像执行一些分类。与所有这些任务相关的嵌入有利地减少了每个图像的计算时间和存储空间。
从这个角度来看,仅训练用于分类的卷积神经网络(CNNs)已经朝着通用特征提取器的方向走了很长一段路。我们可以学习同时有利于分类和实例检索的图像嵌入,这一事实令人惊讶,但并不矛盾。实际上,任务之间存在逻辑依赖关系:根据定义,包含相同实例的图像也包含相同的类;复制的图像包含相同的实例。这与多任务环境不同,在多任务环境中,任务是竞争的,因此很难结合在一起。相反,类、实例和副本的一致性会导致嵌入在特性空间中接近。然而,在不同的情况下,相似程度是不同的,分类需要更多外观变化的不变性和小图像细节的复制检测灵敏度。
为了学习一种满足不同权衡的图像表征,我们从现有的图像分类网络开始。我们使用一个generalized mean层,它将空间激活映射转换为固定大小的向量。最重要的是,我们证明了这是一种学习架构的有效方式,可以适应不同的分辨率在测试时,并提供更高的精度。这就避免了为学习更大的输入分辨率[18]所需的大量工程和计算工作
分类目标和实例识别目标的联合训练分别基于交叉熵和contrastive损失。值得注意的是,实例识别是免费学习的,没有使用特定于实例识别或图像检索的标签:我们只是使用图像的标识作为标签,并使用数据增强作为生成每个图像的不同版本的方法。
综上所述,我们的主要贡献如下:
- 我们介绍了MultiGrain结构,输出包含不同粒度级别的图像嵌入。我们的双 分类+实例 目标提高了分类本身精度。
- 我们表明,这种增益部分是由于批处理策略,其中每个批处理包含其有着不同的数据增强的图像的重复实例,以达到检索损失的目的;
- 我们结合了一个池化层,灵感来自图像检索。当提供高分辨率图像时,它可以显著提高分类精度。
总的来说,我们的架构在分类和图像检索方面都提供了具有竞争力的性能。值得注意的是,我们报告了我们使用ResNet-50网络在Imagenet上得到的准确性对比最先进结果来说显著提高了。
论文组织如下。第二部分介绍相关工作。第三部分介绍了我们的架构、训练过程,并解释了我们如何在测试时调整解决方案。第四部分报告主要实验。
2. Related work
Image classification. 大多数为广泛的任务而设计的计算机视觉架构利用了最初为分类而设计的主干架构,例如Residual网络[17]。对主干架构的改进最终在其他任务[16]中转化为更好的精确性,如LSVRC ' 15挑战的检测任务所示。虽然最近的结构[21,22,46]显示出一些额外的收获,其他的研究路线已经被成功地调查。例如,[30]最近的一个趋势是通过利用更大的弱注释数据的训练集来训练高容量网络。据我们所知,Imagenet ILSVRC 2012基准测试是在Imagenet训练数据上从零开始学习的模型,目前这个基准测试由巨大的AmoebaNet-B架构[23](557M参数)持有,它以480x480幅图像作为输入。
在我们的论文中,我们选择ResNet-50 [17] (有25.6M参数),因为在图像分类和实例检索方面的很多工作的文献中都采用了这种架构。
Image search: from local features to CNN.“图片搜索”是一个通用的检索任务,通常是与更具体的问题相关联,且为其进行评估,如地标识别[25、33],特定对象识别[31]或副本检测[8],其目标是在一个大的图像集合中找到与查询最相似的图像。在本文中,“图像检索”将指实例级检索,其中对象实例尽可能广泛,即不像Oxford/Paris基准那样仅限于建筑物。有效的图像检索系统依赖于准确的图像描述符。通常,一个查询图像是由一个嵌入向量来描述的,这个任务相当于在嵌入空间中搜索这个向量的最近邻。可能的改进包括精炼步骤,如几何验证(geometric verification)[33]、查询扩展(query expansion)[4,42]或数据库端预处理或扩充(database-side pre-processing or augmentation)[41,44]。
传统上,局部图像描述符被聚合为全局图像描述符,以便在inverted数据库中进行匹配,如在seminal bag-of-words model [39]中一样。在ImageNet上出现用于大规模分类的卷积神经网络[28,37]之后,很明显可见在分类数据集上训练的卷积神经网络对于各种视觉任务,包括实例检索,都是非常具有竞争力的图像特征提取器[1,9,35]。
特定对象检索的特定架构建立在一个规则的分类主干上,并进行了修改,以便池化阶段提供更多的空间位置,以应对小对象和杂乱的情况。例如,在各种数据集上检索实例的竞争基准是R-MAC图像描述符[43]。它将从CNN中提取的区域池化特征进行聚合。结果表明,该专用池化方法与PCA whitening[24]相结合,可以有效地实现图像区域间的多对多比较,有利于图像检索。Gordo等人[10,11]表明,使用排名损失在外部图像检索数据集中端对端微调这些区域聚合表征可以显著改善实例检索。
Radenović等人[34]表明用generalized mean池化方法替代R-MAC池化方法(见3.1节),这是一个整个图像p次幂特征的空间池化方法。取幂运算将特征定位在图像中感兴趣的点上,取代R-MAC中的区域聚合。
Multi-task training是一个活跃的研究领域[27,47],其动机是观察到深度神经网络可转移到广泛的视觉任务[35]。此外,经过训练的深度神经网络具有高水平的可压缩性[15]。在某些情况下,通过共享参数在不同任务之间共享神经网络的能力,通过允许数据集和低级特征之间的互补训练来帮助学习。尽管针对视觉的多任务网络如UberNet[27]已经取得了一些成功,但多任务网络的设计和训练仍然涉及许多启发式方法。正在进行的工作包括寻找一个高效参数共享[36]的合适的架构,和为该网络找到合适的优化参数,以脱离传统的单一任务单一数据库端到端梯度下降的设置,有效地加权梯度以在所有任务[13]中获得一个良好的网络。
Data augmentation是大规模视觉应用[28]训练的基础,可以提高泛化和减少过拟合。在随机梯度下降(SGD)优化设置中,可见在一个优化batch中,包含同个图像的多个数据增强实例,而不是只有不同的图像,其显著提高了数据增强效果,提高了网络的泛化性。Hoffer等人[19]同时引入了相应的batch augmented(BA)采样策略。当在神经网络的大规模分布式优化中增大batch的大小时,他们表明,在批处理中使用图像的数据增强副本填充这些较大的批处理可以获得更好的泛化性能,并通过减少数据处理时间而更有效地使用计算资源。正如3.3节中讨论并在我们的分类结果(4.4节)中突出显示的那样,我们表明,在这种采样方案下,使用相同的batch size可以获得性能上的提高,也就是说,每批不同图像的数量更少。我们认为在批处理中使用这种repeated augmentations(RA)的方案可以在优化过程中提高数据增强的效果。我们的结果表明,RA是一种普遍感兴趣的技术,超越大规模分布式训练应用,以改善神经网络的泛化。
3. Architecture design
我们的目标是开发一个既适用于图像分类又适用于实例检索的卷积神经网络。在当前的最佳实践中,用于类和实例识别的体系结构和训练过程有很大的不同。
本节将描述这些技术差异(见表1),以及我们解决这些差异的解决方案。这将我们引向一个统一的体系结构,如图2所示,我们以端到端的方式共同训练这两个任务。

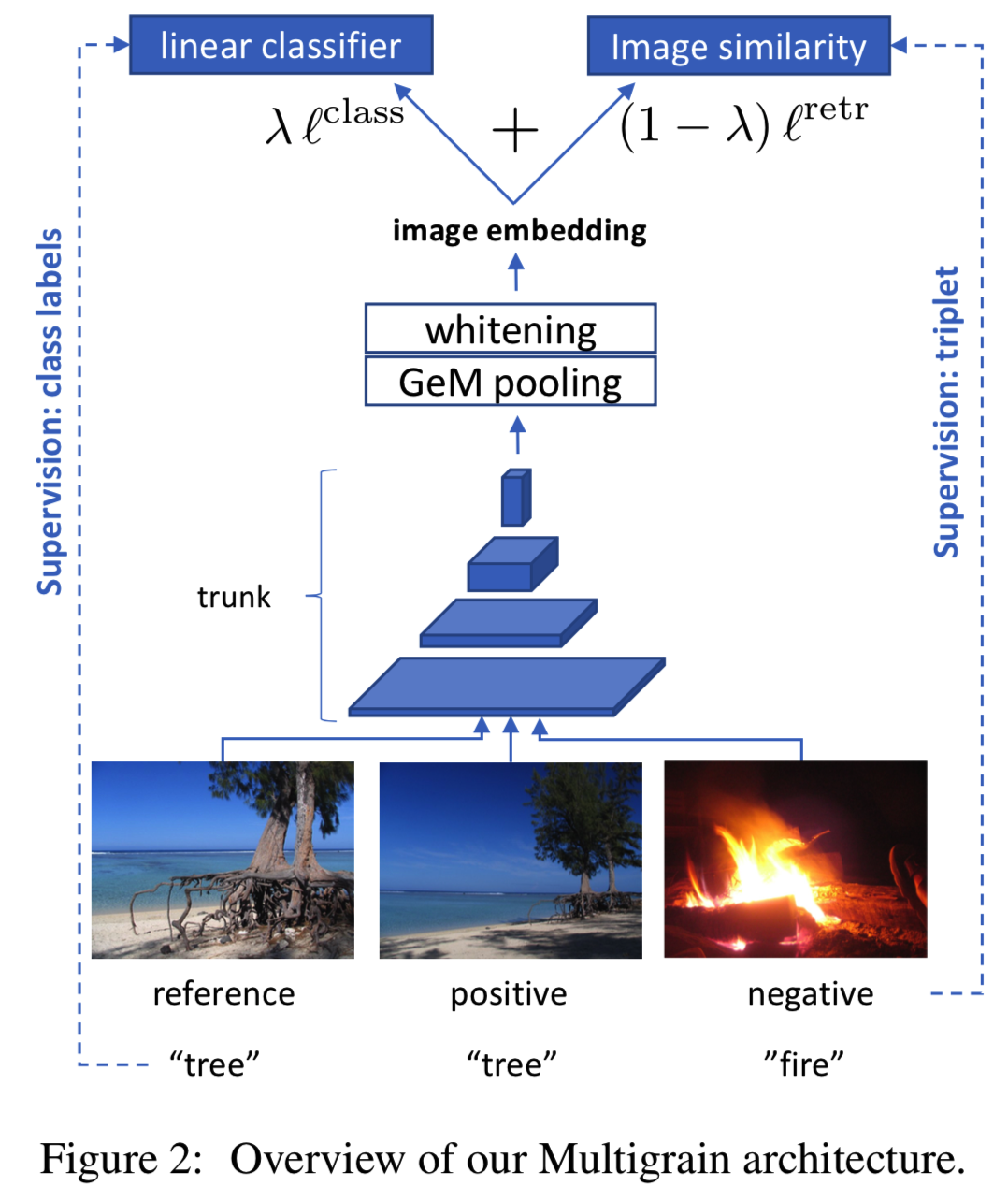
3.1. Spatial pooling operators
本节讨论最后的全局空间池层。局部池化运算符,通常使用max pooling,在大多数卷积网络的层中都可以找到,以实现对小转换的局部不变性。相比之下,全局空间池化将卷积主干产生的三维激活张量转换为矢量。
Classification. 在早期的模型中,如LeNet-5[29]或AlexNet[28],最终的空间池化只是激活映射的线性化。因此,它对绝对位置很敏感。最近的架构,如ResNet和DenseNet使用平均池化,其具有置换不变性,因此提供了一个更全局的转换不变性。
Image retrieval 需要更多的局部几何信息:特定的对象或地标在视觉上更加相似,但是任务受更多杂乱背景因素影响,并且给定的查询图像没有专门针对它的特定训练数据。这就是为什么池化操作符试图支持更多的局部性。接下来我们讨论generalized mean池化操作符。
让![]() 作为给定图像经过卷积神经网络计算得到的特征张量,其中C是特征channels的数量,H和W分别是映射的高和宽。使用
作为给定图像经过卷积神经网络计算得到的特征张量,其中C是特征channels的数量,H和W分别是映射的高和宽。使用![]() 表示映射中的一个“像素”,c表示通道,xcu表示相关的张量元素:
表示映射中的一个“像素”,c表示通道,xcu表示相关的张量元素:![]() 。generalized mean pooling(GeM)层计算张量中每个channel的generalized mean。正式来说,GeM embedding如下给定:
。generalized mean pooling(GeM)层计算张量中每个channel的generalized mean。正式来说,GeM embedding如下给定:

其中p> 0是一个参数。将该指数设为p > 1,增加了池化特征映射的对比度,聚焦于图像的显著特征[2,3,7]。GeM是对分类网络中常用的平均池化(p = 1)和空间最大池化层(p =∞)的推广。在最初的R-MAC中,它被用作最大池[7]的近似,但直到最近[34]才显示出它在图像检索方面与R-MAC具有竞争力。
据我们所知,本文是第一个在图像分类设置中应用和评价GeM池化方法的。更重要的是,在本文的后面,我们展示了对于所有任务来说,调整指数是改变输入图像在训练时间和测试时间之间的分辨率的一种有效的方法,这也解释了为什么由于该任务使用的是高分辨率的图像,因此它对图像检索有好处。
3.2. Training objective
为了将分类和检索任务结合起来,我们使用了一个由分类损失和实例检索损失组成的联合目标函数。两分支架构在图2中说明,下面将详细说明。
Classification loss. 对于分类,我们采用标准的交叉熵损失。正式来说,让![]() 表示深度网络为图像i计算出来的embedding,
表示深度网络为图像i计算出来的embedding,![]() 是类
是类![]() 的线性分类器的参数,yi则是该图的ground-truth类。然后:
的线性分类器的参数,yi则是该图的ground-truth类。然后:

其中![]() 。为了简单起见,我们省略了它,但通过向特征向量添加一个常量通道,分类层的偏差被纳入其权重矩阵中。
。为了简单起见,我们省略了它,但通过向特征向量添加一个常量通道,分类层的偏差被纳入其权重矩阵中。
Retrieval loss. 对于图像检索,两个匹配图像(正样本对)的嵌入距离应该小于非匹配图像(负样本对)的嵌入距离。这可以通过两种方式实现。[14]的contrastive损失要求正样本对之间的距离小于阈值,负样本对之间的距离大于阈值。相反,triplet损失要求图像更接近一个正样本而不是一个负样本[38],这是图像triplets的相对属性。这些损失需要调整多个参数,包括如何采样成对和triplets数据。这些参数有时很难调整,特别是triplet损失。
Wu等人[45]提出了一种有效的方法来解决这些困难。给定一批图像,它们将其embedding重新归一化到单位球面,将采样负样本对作为一个embedding相似度函数,并将这些数据对用于边际损失,这是contrastive损失的一种变体,分享了triplet损失的一些好处。
更详细说来,即在一个batch中给定有着embedding ![]() 的图像
的图像![]() ,然后边际损失为:
,然后边际损失为:
![]()
其中![]() 是归一化embeddings之间的欧式距离,如果两张图匹配,则标签yij为1;如果不匹配则为-1,边际α>0(一个常量超参数),β>0是一个控制包含embedding向量的embedding空间体积的参数(在训练时会和模型参数一起被训练)。由于归一化,
是归一化embeddings之间的欧式距离,如果两张图匹配,则标签yij为1;如果不匹配则为-1,边际α>0(一个常量超参数),β>0是一个控制包含embedding向量的embedding空间体积的参数(在训练时会和模型参数一起被训练)。由于归一化,![]() 等价于consine similarity,一直到whitening(3.4节),也在检索中使用。
等价于consine similarity,一直到whitening(3.4节),也在检索中使用。
损失(3)在使用采样[45]方法择的正样本和负样本对![]() 子集中计算:
子集中计算:

有着margin损失的加权采样距离的使用非常适合于我们的联合训练设置:这个框架容忍相对小的batch size( |B|∼80 to 120个实例),同时batch中每个实例只需要少量的正样本图片(3到5张),而不需要复杂的参数调优或离线取样。
Joint loss and architecture. 联合损失是分类损失和检索损失的组合,由因子λ∈[0,1]加权。对于批![]() 图像,联合损失写为:
图像,联合损失写为:

损失按相应求和项的数目进行标准化。
3.3. Batching with repeated augmentation (RA)
在这里,我们提出仅使用训练数据集进行图像分类,并通过数据增强来训练实例识别。其基本原理是,数据增强产生另一个包含相同对象实例的图像。这种方法不需要标准分类集之外的更多注释。
我们使用SGD和数据增强方法为训练引入了一种新的采样方案,我们称之为重复增强(repeated augmentations)。在RA中,我们从数据集中采样![]() 张不同图像来构建一个图像batch
张不同图像来构建一个图像batch ![]() ,并通过一个数据增强集对其转换m次,得到增强后的图像作为batch中的图像。因此,实例级ground truth yij = +1 表示图像i和j是同一训练图像的两个增强版本。与SGD中标准采样方案的关键区别在于,样本不是独立的,同一图像的增强版本高度相关。如果批处理大小比较小,这种策略会降低性能,但对于较大的批处理大小,在使用相同的批处理大小和学习率的情况下,RA的性能要优于标准的i.i.d.方案。这与[19]的观察不同,[19]也考虑了批中的重复样品,但同时增加了后者的大小。
,并通过一个数据增强集对其转换m次,得到增强后的图像作为batch中的图像。因此,实例级ground truth yij = +1 表示图像i和j是同一训练图像的两个增强版本。与SGD中标准采样方案的关键区别在于,样本不是独立的,同一图像的增强版本高度相关。如果批处理大小比较小,这种策略会降低性能,但对于较大的批处理大小,在使用相同的批处理大小和学习率的情况下,RA的性能要优于标准的i.i.d.方案。这与[19]的观察不同,[19]也考虑了批中的重复样品,但同时增加了后者的大小。
我们推测,相关RA样本的好处是有助于学习特征,这些特征对于重复图像之间唯一的区别——即增强来说是具有不变性的。通过与使用标准SGD采样比较,同一图像的两个版本只在不同的epochs被看到。在补充材料A中,对一个理想问题的研究说明了这一现象。
3.4. PCA whitening
为了将通过数据增强学习到的特征转移到标准检索数据集中,我们根据之前在图像检索方面的工作[11,24],采用了PCA whitening步骤。变换特征之间的欧氏距离相当于输入描述符之间的Mahalanobis距离。这是在训练网络之后,使用外部未标记图像数据集完成的。
PCA whitening的效果可以在分类层的参数中恢复(即PCA whitening不会影响分类结果),从而使白化后的嵌入既可以用于分类,又可以用于实例检索。细节上来说,e表示一个图像嵌入向量和wc是类c的权向量,⟨wc, e⟩是等式(2)的分类器的输出。白化操作![]() 可以写成[11]
可以写成[11]![]() ,给定白化矩阵S和中心向量μ,因此:
,给定白化矩阵S和中心向量μ,因此:
![]()
其中![]() 是类c的修改权重和偏差。我们观察到损失[5]的inducing decorrelation不足以保证特征的泛化,与之前的研究[11,34]一致
是类c的修改权重和偏差。我们观察到损失[5]的inducing decorrelation不足以保证特征的泛化,与之前的研究[11,34]一致
3.5. Input sizes
图像分类的标准做法是将输入图像的重置大小和中央裁切到一个相对低的分辨率,例如224×224像素[28]。这样做的好处是更小的内存占用、更快的推断以及在将输入裁剪为公共大小时可以对输入进行批处理。另一方面,图像检索通常依赖于图像中更细的细节,因为实例可以在各种比例下查看,并且只覆盖少量像素。因此,目前用于图像检索的性能最好的特征提取器通常使用输入最大边大小为800[11]或1024[34]像素的图像,而不将图像裁剪成正方形。这对于联合分类和检索网络的端到端训练是不切实际的。
相反,我们在标准的224 * 224分辨率下训练我们的架构,并且只在测试时使用较大的输入分辨率。这是有可能的,因为我们架构的一个关键优势:一个经过池化指数p和分辨率s的训练网络可以使用更大的池化指数p∗> p在更大的分辨率s∗>s下进行评估,参见4.4节的验证。
Proxy task for cross-validation of p∗. 为了选择适合于所有任务的指数p∗,我们在分类和检索之间创建一个合成检索任务In-aug。我们从ImageNet的训练集中采样2000张图像(每个类2张),并使用前面描述的“full”数据增强,为每个图像创建5个增强副本。
我们使用UKBench[31]一样的方法评估In-aug的检索精度,精确度从0到5不等,取决于衡量5个增强副本有多少排在前5位。我们选择In-aug中最好的性能p∗∈{1,2,…10},它提供了以下λ和s∗的选择:

在IN-aug获得的最优p∗提供了检索和分类之间的权衡。通过实验,我们观察到其他选择也适用于设置这个参数:通过交叉熵损失反向传播,仅使用给定分辨率的的训练输入来微调参数p∗也可以得到与p∗相似的结果和值。
4. Experiments and Results
在展示数据集之后,我们提供了一个参数化的研究和我们在图像分类和检索的结果。
4.1. Experimental settings
Base architecture and training settings. 卷积主干是ResNet-50[17]。SGD开始时学习速率为0.2,在30、60、90个epoch时分别降低了10倍,总共120个epoch(标准设置[32])。batch size |B|设置为512,一个epoch对应T = 5005次的固定迭代次数。在批采样均匀的情况下,一个epoch对应于训练集的两次遍历;当使用RA和m = 3时,一个epoch对应于训练集中约2/3的图像。为了进行公平的比较,所有的分类基线都使用这个更长的方案进行训练。
Data augmentation. 我们使用标准翻转,随机resized crop[20],随机照明噪声和亮度、对比度和饱和度的颜色抖动[28,20]。我们将这组增强称为“full”,详见补充材料C。如表2所示,仅使用交叉熵和均匀批抽样训练时,在我们所选择的方案和数据增强方法下,我们的网络top-1验证误差达到76.2%。在没有特别制作的正则化项[48]或数据增强[6]的情况下,这个数字是ResNet-50网络报道的最高精度[12,17]。

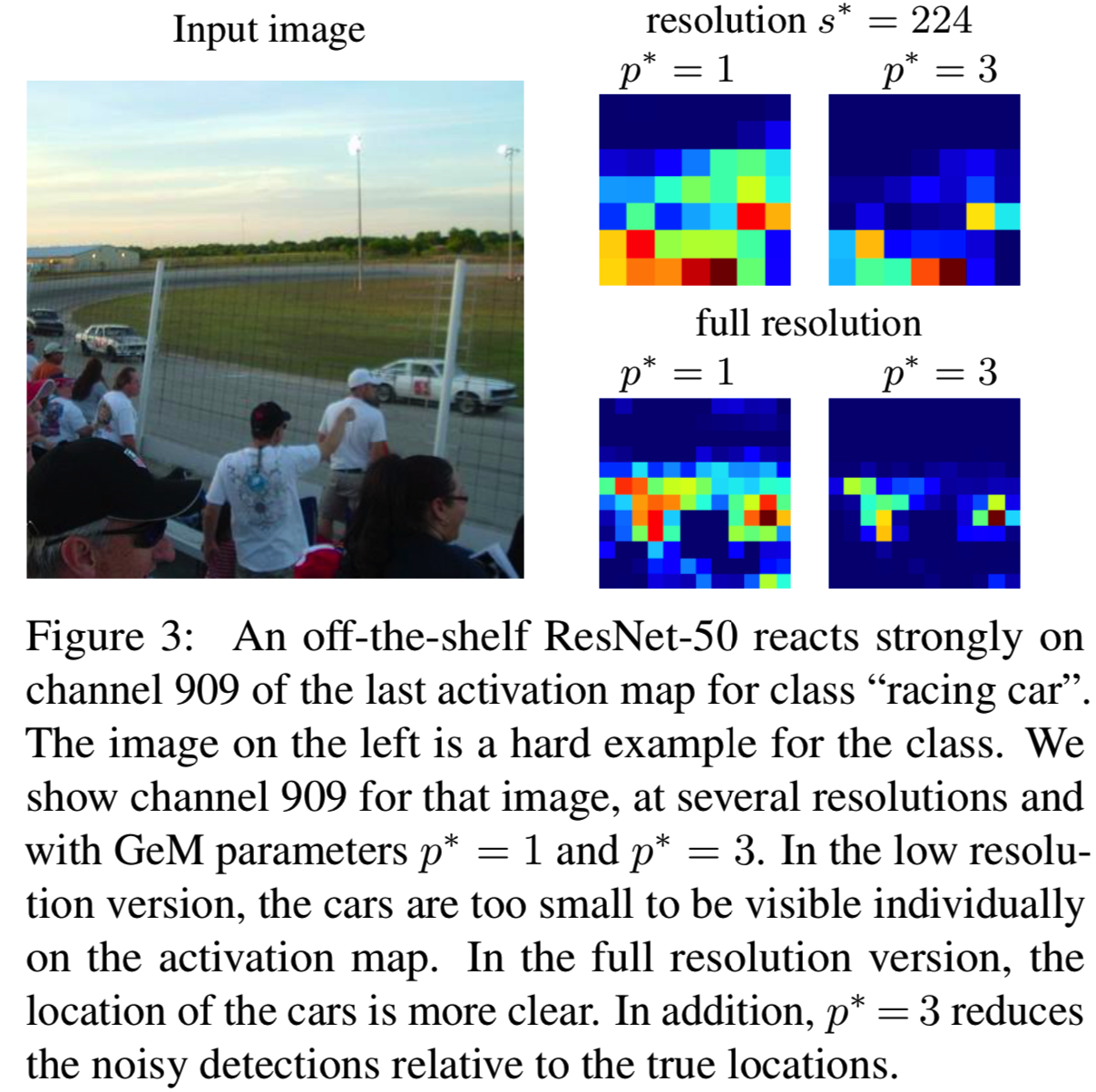
Pooling exponent. 在对我们的网络进行端到端的训练时,我们考虑了3.1节中GeM层的池化指数的两种设置:我们设置p = 1或p = 3。p = 1对应于分类架构中使用的平均池化。相关文献[34]和我们在现成分类网络上的初步实验表明,p = 3值可以提高标准基准上的检索性能。图3演示了这种选择。通过设置p = 3,检测小车的可信度很高,没有虚假检测。Boureau等人[3]分析稀疏特征的平均池化和最大池化。他们发现,当池化特征的数量增加时,使其更加稀疏是有益的,这与我们在这里所观察到的是一致的。
Input size and cropping. 如3.5节所述,我们对224×224像素的crop进行网络训练。为了测试,我们实验了在分辨率s∗= 224,500,800下计算MultiGrain嵌入。对于分辨率s∗= 224,我们遵循经典的图像分类协议“resolution 224”:图像的最小边被调整到256,然后提取一个224×224的中央剪裁。对于分辨率s∗> 224,我们代替遵循在图像检索中常见的协议,将图像最大的一边调整到所需的像素数,并在矩形图像上评估网络,而不裁剪。
Margin loss and batch sampling. 我们每个batch使用m=3的数据增强重复值。我们使用[45]的默认margin损失超参数(详见补充材料B)。在[45]中,距离加权采样是在用于训练的4个gpu上独立执行的。
Datasets. 我们在ImageNet-2012训练集上训练我们的网络,该训练集包含120万张图像,这些图像被标记为1000个目标类别[37]。分类精度报告了该数据集的50,000张验证图像。对于图像检索,我们报告了Holidays数据集[25]的mAP,必要时手动旋转图像,就像之前对数据集[10]的评估一样。我们还报告了UKB对象识别基准[31]的准确性,其中包含2550个对象实例在4个不同的视点的图像;每幅图像作为一个查询,在嵌入空间中找到它的4个最近邻;正确邻居的数量在所有图像上取平均值,得到最高分4。我们还报告了我们的网络在副本检测设置中的性能,表明了INRIA Copydays数据集[8]的“strong”子集上的mAP。我们从YFCC100M大规模的未标记图像[40]中随机采样10K干扰图像。我们称这个组合为C10k。
与C10k干扰物不同,利用YFCC100M的20K幅图像的特征进行PCA whitening。
4.2. Expanding resolution with pooling exponent
作为参考方案,我们以RA采样和池化指数p = 3在分辨率为224x224的条件下训练网络。在对同样224x224分辨率的图像进行测试时,Imagenet的top-1验证准确率为76.9%,比非RA基线高出0.7%,见表2。
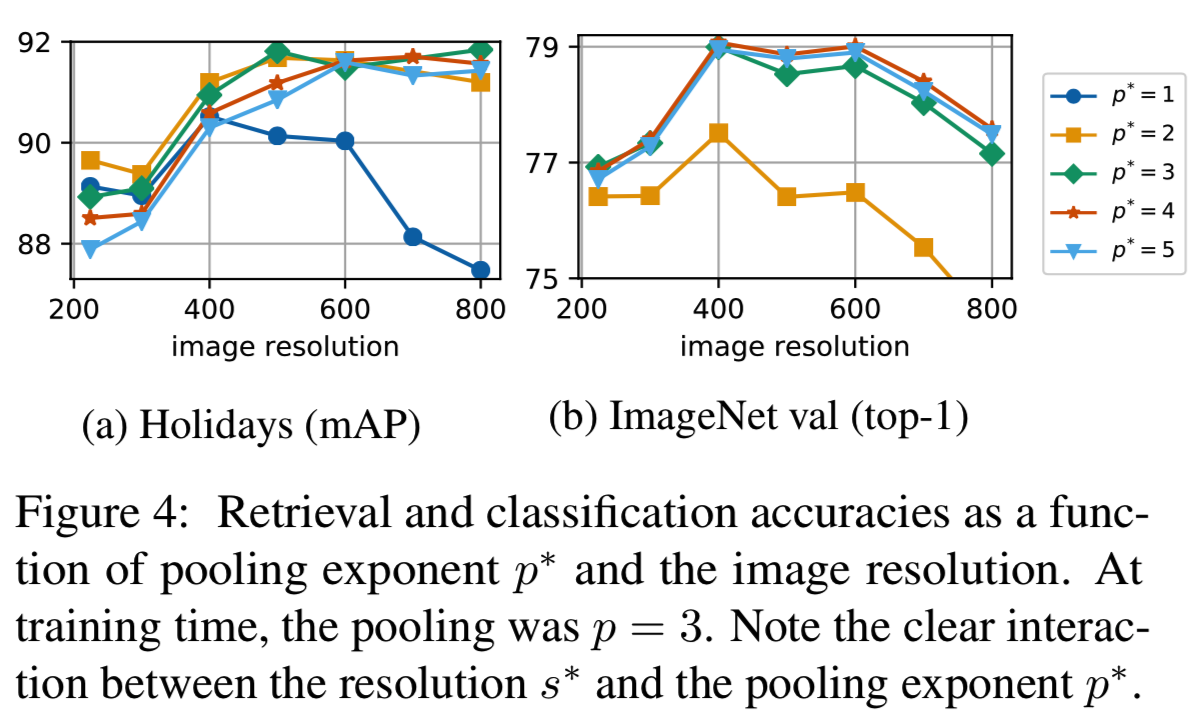
在测试时,我们输入更大的图像,也就是说,我们考虑分辨率s∗> 224年和在测试时改变指数![]() 。图4a和图4b显示了不同分辨率下,使用不同测试池化指数p∗值在ImageNet验证下的分类精度和在Holidays下的检索精度,测试池指数的不同值。正如预期的那样,在s∗= 224处,在分类中产生最佳精度的池化指数是训练网络所用的指数,p∗= 3。观察,在更大范围的测试需要一个指数p∗> p,用于分类和检索。
。图4a和图4b显示了不同分辨率下,使用不同测试池化指数p∗值在ImageNet验证下的分类精度和在Holidays下的检索精度,测试池指数的不同值。正如预期的那样,在s∗= 224处,在分类中产生最佳精度的池化指数是训练网络所用的指数,p∗= 3。观察,在更大范围的测试需要一个指数p∗> p,用于分类和检索。
下面,我们采用在In-aug交叉验证得到的值,见3.5节。
4.3. Analysis of the tradeoff parameter
现在我们分析权衡参数λ的影响。注意,这个参数并不能直接反映两个损失项在训练过程中的相对重要性,因为它们不是同质的:λ=0.5并不意味着他们同等重要。图5在epoch 0和120上通过测量网络反向传播梯度的平均范数,分析了分类和边际损失项的实际相对重要性。我们可以看到,在训练开始的时候,λ=0.5表示我们的分类项的权重会略微更多一些。在训练结束时,分类项占主导地位,这意味着网络已经学会了取消数据增强效果。
从性能上看,λ=0.1导致分类精度较差。有趣的是,λ=0.5(在s∗= 224时为77.4%)的分类性能比λ=1的更高,见表2。因此,边际损失导致了分类任务的性能增益。
在接下来的实验中,我们设置了λ=0.5,因为它在实际分辨率s∗= 224和500像素时给出了最好的分类精度。作为参考,我们还报告了一些使用λ=1的结果。
4.4. Classification results
从现在开始,我们的MultiGrain网络在分辨率s = 224训练,使用标准平均池化时使用p = 1或在使用GeM池化时使用p = 3。对于每个评估分辨率s∗= 224,500,800,根据章节3.5选择相同的指数p∗,产生一个用于分类和检索的单一嵌入。表2给出了分类结果。从设置p = 1、s = 224且使用的“full”数据增加(76.2% top-1精度)的基线Resnet-50,到设置p = 3、λ= 0.5、s = 500 (78.6% top-1精度)的MultiGrain模型,分类性能有了很大提高。我们确定了四个改进来源:
1. 重复增强:加入RA批采样(第3.3节)提高+0.6% (p = 1)。
2. 边际损失:检索损失有助于数据增强的泛化效果:+0.2% (p = 1)。
3.p = 3 pooling: 由于GeM(3.1节)在训练中增加了特征的局部化,使得margin loss的效果更强:+0.4%。
4. 扩展分辨率:当分辨率为500时使p = 3的MultiGrain网络的评估效果增加+1.2%,达到78.6的top-1精度。这是通过p = 3训练实现的——它产生更稀疏的特性,在不同的分辨率上更通用,并且通过p∗池化适配——没有它,在这个分辨率下的性能只有78.0%。
用于在更高分辨率下进行评估的p∗的选择有它的限制:在800像素,由于特征提取器的训练和测试规模之间的巨大差异,精度下降到77.2%(没有p∗适应的结果为76.2%)。
AutoAugment [6] (AA)是一种在ImageNet上使用强化学习技术来提高分类网络精度的数据增强学习方法。我们直接集成了算法[6]中在其Resnet-50模型上训练的数据增强方法,该算法在数据集上使用270次epoch的长训练方案,批处理大小为4096。
我们观察到,这种较长的训练对AA-generated增强产生了更大的影响。因此,我们使用一个更长的方案,每个epoch进行7508次迭代,保持批大小|B| = 512。
我们的方法受益于这种数据增强:在分辨率为224的情况下,当p = 3,λ= 0.5时,MultiGrain达到78.2%的top-1精度。据我们所知,这是Resnet-50在训练和评估这种分辨率时报告的最佳top-1准确度,显著高于单独使用AutoAugment[6]报告的77.6%或混合[48]报告的76.7%。在测试时使用更高的分辨率进一步提高了精度:在分辨率500时,我们获得了79.4%的top-1精度。我们调整池化指数以适应更大分辨率的策略仍然是有效的,并且在训练分辨率224时显著优于在ImageNet上学习的ResNet-50的最新性能。
4.5. Retrieval results
我们在表3中展示了我们的检索结果,并在补充材料(D)中给出了消融研究和副本检测结果。在可比分辨率下,我们的NultiGrain提高了所有数据集相对于Resnet-50基线的准确性。重复增强(RA)在此上下文中也是一个关键因素。
我们将基线与不使用注释检索数据集的基线进行比较。[10,11]用R-MAC池化给出现有的网络精确度。在可比较的分辨率(s∗=800)下,MultiGrain比他们的结果进行比较。它们在Holidays的精度达到93%以上的mAP,但这需要分辨率s≥1000像素。
值得注意的是,我们在分辨率s∗= 500时达到了合理的检索性能,相对于传统的检索推理分辨率s = 800-1000来说,这是一个有趣的操作点。实际上,Resnet-50在16个处理器内核上的前向传递在分辨率500时需要3.80秒,而在分辨率1024时需要18.9秒(慢5倍)。由于时间的二次增长,以及由MultiGrain计算的单一嵌入,我们的解决方案特别适合于大规模或低资源的视觉应用。
为了进行比较,我们还报告了一些在UKB和C10k数据集上较早的相关结果,这些结果与MultiGrain没有竞争力。Neural codes[1]是最早研究深度特征检索的工作之一。Fisher向量[26]是一种使用本地SIFT描述符的池化方法。
在分辨率为500时,我们可见边际损失(λ= 0.5)的结果比不使用边际损失(λ= 1)的结果稍低。这可能一部分是由于从In-aug任务到检索数据集中观察到的变化的转移有限。

5. Conclusion
在这项工作中,我们介绍了一种统一的用于图像分类和实例检索的嵌入。MultiGrain依赖于一个经典的卷积神经网络主干,在训练时使用GeM池化,且顶部对应两个分支。我们发现,通过调整这个池化层,我们能够增加在推理时使用的图像分辨率,同时在训练时保持较小的分辨率。我们已经证明了MultiGrain嵌入在分类和检索方面有很好的效果。有趣的是,与使用相同卷积主干获得的所有结果相比,MultiGrain还在纯分类方面得到了最好的效果。总的来说,我们的结果表明检索和分类任务可以相互受益。