补充材料在https://openaccess.thecvf.com/content_ICCV_2019/supplemental/Revaud_Learning_With_Average_ICCV_2019_supplemental.pdf
Learning with Average Precision: Training Image Retrieval with a Listwise Loss
Abstract
图像检索可以被表述为一个排序问题,其目标是通过降低与查询的相似性来对数据库图像进行排序。最近的深度图像检索模型通过利用排序定制损失函数,效果已经超过了传统方法,但重要的理论和实践问题仍然存在。首先,它们不是直接优化全局排序,而是最小化基本损失的上限,这并不一定会得到最佳的mean average precision(mAP)。其次,这些方法需要大量的工程努力才能发挥良好的作用,例如,特殊的预训练和难负样本采样。在本文中,我们建议通过利用最近在listwise loss公式上的进展,直接优化全局mAP。使用histogram binning approximation,可以区分AP,从而用于端到端学习。与现有的损失相比,该方法在每次迭代时同时考虑数千张图像,并消除了使用特殊技巧的需要。它还在许多标准检索基准上得到了最新效果。模型可见https://europe.naverlabs.com/Deep-Image-Retrieval/.
1. Introduction
图像检索包括查找大型数据库中包含相关内容的所有图像。这里的相关性是在实例级定义的,检索通常包括用与查询中相同的对象实例对数据库图像进行排序。这项重要的技术为一些流行的应用程序,如基于图像的物品识别(例如,时尚物品[12,35,60]或产品[53])和自动个人照片[19]组织提供了基础。
大多数实例检索方法依赖于计算图像签名,这些签名对于视点变化和其他类型的噪声是健壮的。有趣的是,由深度学习模型提取的签名最近的表现优于基于关键点的传统方法[16,17,46]。这种良好的性能是由于深度模型能够利用一组非常适合排序问题的损失函数。与以前用于检索的成功率较低的分类损失相比[3,4,47],基于排序的函数直接对最终任务进行优化,强制执行类内区分和更细粒度的实例级图像表征[17]。到目前为止,排序损失可以考虑图像对 [45], triplets [17], quadruplets [10], or n-tuples [52]。它们的共同原则是子采样一组小样本图像,验证它们局部是否符合排序目标,如果不符合则进行小的模型更新,重复这些步骤直到模型收敛。
尽管它们很有效,但重要的理论和实践问题仍然存在。特别地,它已经表明,这些排名损失是一个称为本质损失[34]的量的上界,而本质损失[34]又是一个标准检索度量的上界,如mean average precision(mAP)[33]。因此,优化这些排名损失并不能保证得到同样优化mAP的结果。因此,没有理论保证这些方法在实际系统中产生良好的性能。也许是出于这个原因,要获得好的结果需要很多技巧,比如分类预训练[1,17],组合多重损失[9,11],以及使用复杂的硬负样本挖掘策略[14,20,37,38]。这些工程启发式算法涉及到额外的超参数,而且实现和调优都非常复杂[24,58]。
在本文中,我们研究了一种新的排序损失,它通过直接优化mAP来解决这些问题(见图1)。它不是一次只考虑几张图片,而是同时优化成千上万张图片的全局排序。这实际上使前面提到的技巧变得没有必要,同时又提高了性能。具体来说,我们利用了listwise loss函数的最新进展,该函数允许使用柱状图binning[23,24,58]重新制定AP。AP通常是非光滑的,不可微的,不能在基于梯度的框架中直接优化。然而,直方图binning(或soft-binning)是可微的,可以用来替代AP中不可微的排序操作,使其服从于深度学习。He等人[24]最近在基于该技术的patch验证、patch检索和图像匹配方面取得了突出的成果。
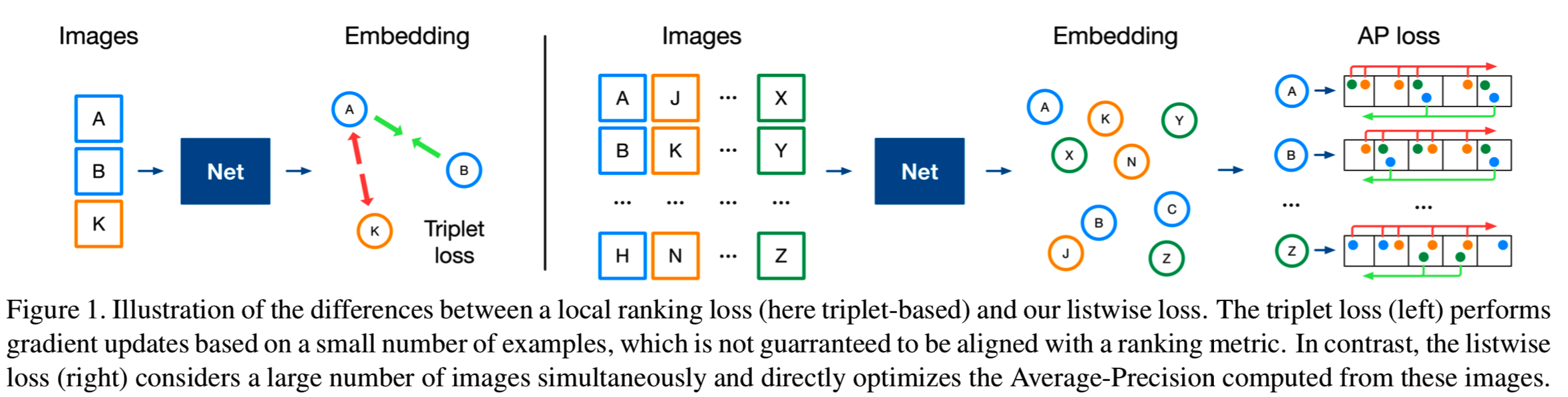
在这项工作中,我们遵循相同的路径,并提出了一种直接为mAP优化的图像检索方法。为了达到这个目的,我们训练了大量的高分辨率图像,这些图像通常会大大超过GPU的内存。因此,我们引入了一个优化方案,使训练可行的任意批大小,图像分辨率和网络深度。综上所述,我们作出了三大贡献:
- 我们首次提出了一种利用listwise排序损失直接优化mAP的图像检索方法。它依赖于一个专门的优化方案,可以处理任意图像分辨率和网络深度的超大批处理数据。
- 通过对损失的ceteris paribus分析,我们展示了在编码工作量、训练预算和最终性能方面使用listwise损失的许多好处。
- 对于可比的训练集和网络,我们的表现超过了最先进的结果。
本文组织如下:第2节讨论相关工作,第3节描述提出的方法,第4节提出实验研究,第5节提出我们的结论。
2. Related work
早期的实例检索工作依赖于局部patch描述符(例如,SIFT[36]),使用bag-of-words表征[13]或更精细的方案进行聚合[15,18,55,29],以获得图像级的签名,然后可以相互比较,以找到它们的最接近匹配。最近,利用CNN提取的图像特征已经成为一种替代方法。虽然最初的工作使用了从预先训练分类的现成网络中提取的神经元激活[3,4,45,47,56],但后来的研究表明,可以使用siamese网络以端到端方式专门为实例检索任务训练网络[17,46]。关键是利用优化排名的损失函数而不是分类的损失函数。这类方法代表了使用全局表征进行图像检索的最新技术[17,46]。
图像检索确实可以看作是一个学习排序问题[6,8,34,57]。在这个框架中,任务是确定训练集中的元素应该以何种(部分)顺序出现。采用度量学习和适当的排序损失相结合的方法求解。图像检索中的大多数工作都考虑了pairwise(例如contrastive[45])或tuplewise(例如triplet-based[16,50],基于n-tuple-based[52])的损失函数,我们称其为局部损失函数,因为它们在计算梯度之前作用于固定且有限数量的例子。对于这种损失,训练包括对随机且困难的成对或三个一幅图像进行重复采样,计算损失,并反向传播其梯度。然而,一些研究[14,24,27,40,48]指出,适当地优化局部损失可能是一项具有挑战性的任务,原因有几个:首先,它需要一些特殊的预先操作,如分类的预训练模型[1,17]、要结合几种损失[9,11],并通过挖掘hard或semi-hard的负样本来偏置图像对的采样[14,20,37,38]。除了不平凡之外[21,51,59],挖掘困难的例子通常是很费时的。到目前为止,另一个被忽视的主要问题是局部损失函数只优化真实排序损失的上界[34,58]。因此,没有理论保证损失的最小值实际上对应于真实排名损失的最小值。
在本文中,我们采用不同的方法直接优化mean average precision (mAP)度量。虽然AP是一个非光滑且不可微的函数,但He等人[23,24]最近表明,它可以根据[58]中提出的直方图binning(也用于[7])的可微逼近来逼近。这种方法与基于局部损失的方法有根本不同。在[34]中,使用直方图近似来映射的方法叫做listwise,因为loss函数同时取一个数量不定(可能很大)的例子,共同优化它们的排名。He等人引入的AP损失[23]是特别定制的,用于处理在图像哈希环境中自然发生的与汉明距离相关的得分关系。有趣的是,同样的公式在[24]的patch匹配和检索中也被证明是成功的。然而,它们的关联感知公式提出了重要的收敛问题,并需要几种近似才能在实践中使用。相比之下,我们提出了一个简单的公式的AP损失是稳定的,表现更好。我们将其应用于图像检索,这是一个相当不同的任务,因为它涉及到具有显著的杂乱背景、大视点变化和更深的网络等影响的高分辨率的图像。
除了[23,24]之外,文献中还提出了几种可替代得公式,以便直接优化AP[5,22,24,26,39,54,61]。Yue等人[61]提出在使用线性支持向量机的结构化学习框架下,通过[22]损失增广推理问题来优化AP。Song等人[54]随后将该框架扩展到与非线性模型一起工作。然而,两种工作都假设在结构化支持向量机公式中损失增广推理中的推理问题能够被有效地解决。此外,他们的技术需要使用动态编程的方法,这需要改变优化算法本身,使其通用的应用复杂化。直到最近,AP损失才被用于任意学习算法训练的深度神经网络的一般情况[24,26]。Henderson和Ferrari[26]直接对AP进行优化,用于目标检测,He等[24]对patch验证、检索和图像匹配进行优化。
在图像检索方面,必须清除额外的障碍。直接优化mAP确实会带来内存问题,因为在训练和测试时通常使用高分辨率图像和非常深的网络[16,45]。为了解决这个问题,智能多阶段反向传播方法已经被开发用于图像triplets[17]的情况下,我们表明,在我们的设置中,可以利用稍微更精细的算法来实现同样的目标。
3. Method
本节将介绍基于AP的训练损失的数学框架以及我们针对高分辨率图像所采用的适应训练程序。
3.1. Definitions
我们首先定义下面公式的数学标识。![]() 表示图像空间,
表示图像空间,![]() 表示C维空间的单位超平面,即
表示C维空间的单位超平面,即![]() 。使用深度前向网络
。使用深度前向网络![]() 抽取图像embedding,其中
抽取图像embedding,其中![]() 表示网络中可学习的参数。我们假设
表示网络中可学习的参数。我们假设![]() 配备了L2归一化输出模块,所以embedding
配备了L2归一化输出模块,所以embedding ![]() 有着单位范数。这两个图像的相似度能够自然地在embedding空间,使用cosine相似度来评估:
有着单位范数。这两个图像的相似度能够自然地在embedding空间,使用cosine相似度来评估:
![]()
我们的目标是对每个给定的查询图像![]() ,训练参数
,训练参数![]() 去排序其与来自一个大小为N的数据集
去排序其与来自一个大小为N的数据集![]() 的每张图的相似度。通过我们网络的一个前向传播来计算关于所有图像的embedding,每个数据库项与查询图像的相似度
的每张图的相似度。通过我们网络的一个前向传播来计算关于所有图像的embedding,每个数据库项与查询图像的相似度![]() 使用等式(1)在embedding空间中被有效测量,其中
使用等式(1)在embedding空间中被有效测量,其中![]() 。然后数据库图像根据他们的相似度反向排序。让
。然后数据库图像根据他们的相似度反向排序。让![]() 表示排序函数,其中
表示排序函数,其中![]() 是第i高的
是第i高的![]() 值的索引。经过扩展,
值的索引。经过扩展,![]() 表示数据库索引的排序列表。排序
表示数据库索引的排序列表。排序![]() 的质量能够根据ground-truth图像相关性来进行评估,在
的质量能够根据ground-truth图像相关性来进行评估,在![]() 中表示为
中表示为![]() ,其中如果数据库中的图像
,其中如果数据库中的图像![]() 与查询图像
与查询图像![]() 相关,则
相关,则![]() 为1;否则为0。
为1;否则为0。
排序评价是用信息检索(IR)指标之一进行的,如mAP, F-score和discounted cumulative gain。在实践中(尽管存在一些缺点[32]),当ground truth标签是二进制的时候,AP已经成为IR事实上的标准度量。与召回率或F-score等其他排名指标相比,AP不依赖于阈值、排名位置或相关图像的数量,因此使用起来更简单,更善于针对不同的查询进行泛化。我们可以将AP写成带有![]() 和
和![]() 的函数:
的函数:
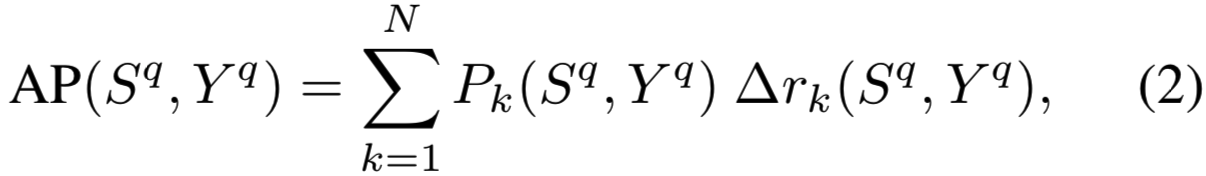
其中![]() 是排序k个图像的精确度,即在排序的前k位中与查询图像q相关的项的比例,如下:
是排序k个图像的精确度,即在排序的前k位中与查询图像q相关的项的比例,如下:
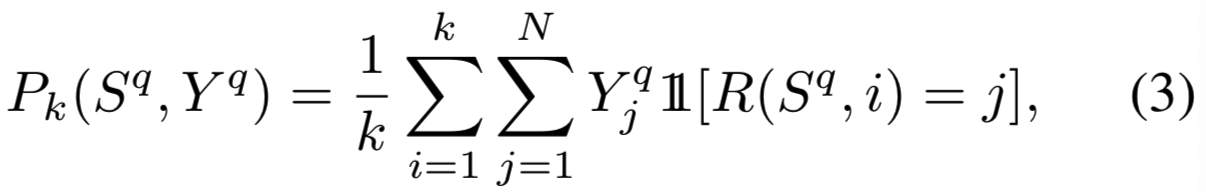
![]() 表示的是从排序k-1到k的增量召回(incremental recall),即在排序k个图像中发现的总
表示的是从排序k-1到k的增量召回(incremental recall),即在排序k个图像中发现的总![]() 相关项的比例,如下:
相关项的比例,如下:
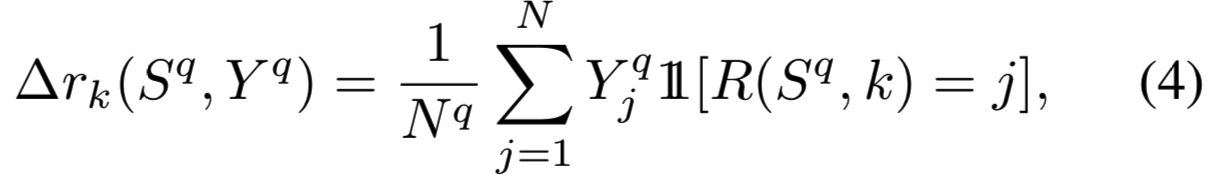
其中![]() 表示指示函数
表示指示函数
3.2. Learning with average precision
理想情况下,![]() 的参数应该使用随机优化来训练,这样能够在训练集中最大化AP。对于原始AP公式来说这是不灵活的,因为使用了指示函数
的参数应该使用随机优化来训练,这样能够在训练集中最大化AP。对于原始AP公式来说这是不灵活的,因为使用了指示函数![]() 。具体来说,函数
。具体来说,函数![]() 在
在![]() 时有导数,在
时有导数,在![]() 时导数没定义。因此该导数没有为优化提供信息。
时导数没定义。因此该导数没有为优化提供信息。
受直方图[58]的listwise loss启发,最近提出了一种计算AP的替代方法,并应用于描述符哈希[23]和patch匹配[24]的任务。关键是通过对AP进行松弛训练,通过将hard赋值![]() 替换为函数
替换为函数![]() 来获得AP,函数
来获得AP,函数![]() 的导数可以向后传播,它将soft赋值相似度值到固定数量的桶中。在这一节中,为了简单起见,我们几乎在任何地方都将可微的函数称为可微的。
的导数可以向后传播,它将soft赋值相似度值到固定数量的桶中。在这一节中,为了简单起见,我们几乎在任何地方都将可微的函数称为可微的。
Quantization function. 对于一个给定的正整数M,我们将间隔[-1,1]分区成M-1个等量的间隔,每个大小为![]() 且(从左到右)被bin中心
且(从左到右)被bin中心![]() 限制,其中
限制,其中![]() 。在等式(2)中,我们在
。在等式(2)中,我们在![]() 中每k个排序中评估精确度和增量召回。我们松弛训练的第一步是在每个bin中计算:
中每k个排序中评估精确度和增量召回。我们松弛训练的第一步是在每个bin中计算:
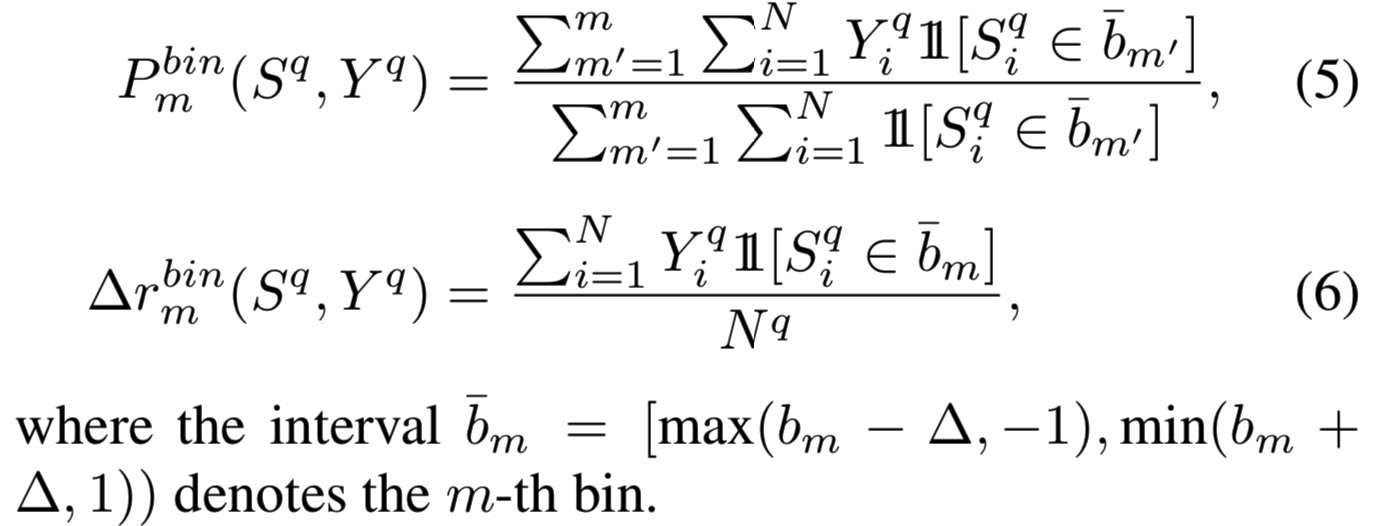
第二步是使用soft赋值作为指示函数的替代函数。与[23]相似,我们定义函数为![]() ,每个
,每个![]() 是集中在bm的三角核且宽度为
是集中在bm的三角核且宽度为![]() ,即:
,即:
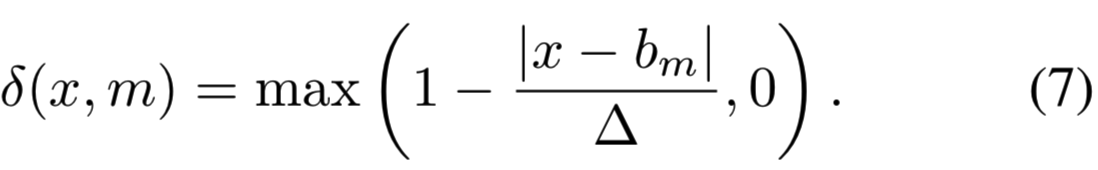
![]() 是一个x的soft binning,当
是一个x的soft binning,当![]() 时趋近指示函数
时趋近指示函数![]() ,同时对于x可微:
,同时对于x可微:
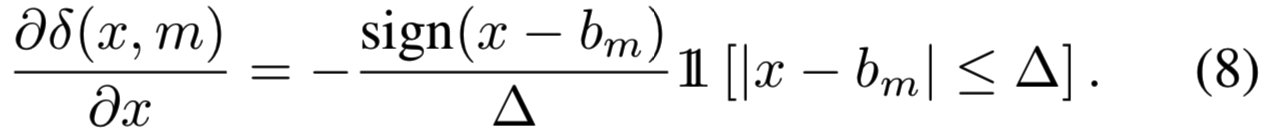
通过扩展标识,![]() 是
是![]() 中的一个向量,用于指示到bin
中的一个向量,用于指示到bin ![]() 的
的![]() 的soft 赋值。
的soft 赋值。
因此,![]() 的量化
的量化![]() 是指示函数的一个平滑的替代。它允许我们重计算精确度和增量召回的近似值来作为量化函数,如之前等式(3)和(4)所示那样。因此,对于每个bin m,量化精确度
是指示函数的一个平滑的替代。它允许我们重计算精确度和增量召回的近似值来作为量化函数,如之前等式(3)和(4)所示那样。因此,对于每个bin m,量化精确度![]() 和增量召回
和增量召回![]() 可计算为:
可计算为:
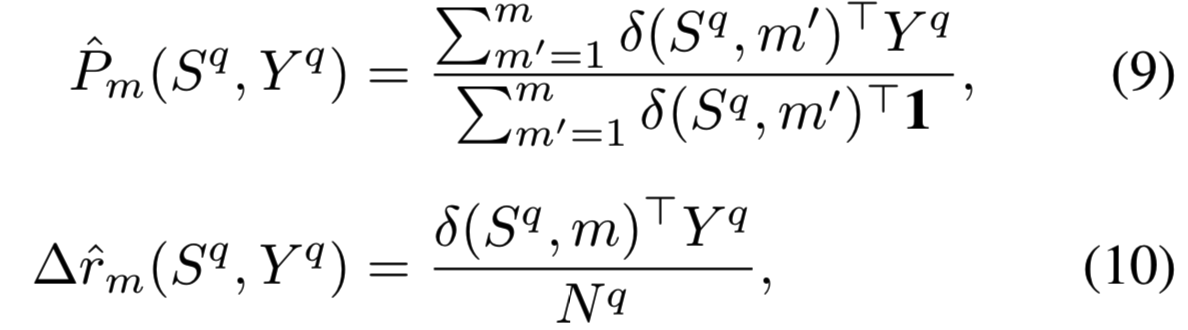
最后的量化平均精确度,表示为![]() ,这是一个关于
,这是一个关于![]() 的平滑函数,如下:
的平滑函数,如下:

Training procedure. 训练过程和损失都定义如下。![]() 表示标签为
表示标签为![]() 的一个batch的图像,然后
的一个batch的图像,然后![]()
![]() 是它们相关的描述符。在每个训练迭代中,我们计算每个batch的平均
是它们相关的描述符。在每个训练迭代中,我们计算每个batch的平均![]() 。对于该目标,我们考虑batch图像的每个图像为潜在的查询图像,并将其与其他batch图像比较。对于查询图像
。对于该目标,我们考虑batch图像的每个图像为潜在的查询图像,并将其与其他batch图像比较。对于查询图像![]() 的相似度分数被定义为
的相似度分数被定义为![]() ,即与图像
,即与图像![]() 的相似度。同时,用
的相似度。同时,用![]() 表示相关的二进制ground-truth,其中
表示相关的二进制ground-truth,其中![]() 。我们计算量化mAP,使用
。我们计算量化mAP,使用![]() 表示,对于batch数据如下表示:
表示,对于batch数据如下表示:

因为我们想要在训练集中最大化mAP,所以很自然地将损失定义为![]()
3.3. Training for high-resolution images
He等人[24]已经表明,在patch检索的情况下,对于大batch size的patch可以达到最佳性能。在图像检索中,同样的方法不能直接应用。实际上,批处理占用的内存要比patch占用的内存大几个数量级,这使得反向传播在任意数量的gpu上都很难处理。这是因为(i)通常用高分辨率图像训练网络,(ii)实际使用的网络要大得多(ResNet-101有大约44M的参数,而[24]中使用的L2-Net仅有大约26K的参数)。在训练和测试[17]时,使用高分辨率图像进行训练对于取得良好的性能是至关重要的。通常,输入到网络的训练图像分辨率约为1Mpix(与[24]中的51×51 patch相比)。
通过利用链式法则(chain-rule),我们设计了一个多阶段的反向传播,解决了这个内存问题,并允许训练一个有着任意深度、任意图像分辨率和batch size的网络,且不近似损失。该算法如图2所示,分为三个阶段。

在第一阶段,我们计算一个batch的所有图像的描述符,丢弃内存中的中间张量(在评估模式下进行该操作,即设置net.eval(),因为这里不需要后向传播。我看代码,感觉这个中间参数是即输入的图像数据,即图像输入网络得到描述符后,就将其从内存中删除,即del img,因为第三步中还要再算一遍并存储)。在第二阶段,我们计算分数矩阵S (等式1)和损失![]()
![]() ,并计算损失关于描述符的梯度
,并计算损失关于描述符的梯度![]() 。换句话说,我们在进入网络之前停止反向传播(即这里就是得到描述符的梯度,没有更新网络参数)。由于所考虑的所有张量都是紧凑的(描述符、分数矩阵),这个操作只消耗很少的内存。在最后一个阶段,我们重新计算图像描述符,这次存储中间张量(即输入图像img不从内存删除)。由于此操作(即网络计算描述符的操作)占用大量内存,因此我们将逐个图像执行此操作。给定图像
。换句话说,我们在进入网络之前停止反向传播(即这里就是得到描述符的梯度,没有更新网络参数)。由于所考虑的所有张量都是紧凑的(描述符、分数矩阵),这个操作只消耗很少的内存。在最后一个阶段,我们重新计算图像描述符,这次存储中间张量(即输入图像img不从内存删除)。由于此操作(即网络计算描述符的操作)占用大量内存,因此我们将逐个图像执行此操作。给定图像![]() 的描述符di,以及描述符的梯度
的描述符di,以及描述符的梯度![]() ,我们就能够继续网络的后向传播了(可见这里就是将计算损失梯度和梯度后向传播更新两步拆开了,第二阶段得到的描述符的梯度对应的就是第三阶段计算的描述符,因为网络没有变化,所以描述符还是相同的,所以梯度和描述符是对应的。第二阶段的作用就是能够计算每个图像与其他batch_size-1个图像的相似度和损失,然后用于第三阶段去更新参数)。然后累积每张图像的梯度,最后用来更新网络权重(就是一张张图像地去更新网络参数,求得的关于参数的梯度一张张加起来,等所有图像都更新后再将累积的更新梯度用来更新网络参数,而不是一张图计算后就更新)。多阶段后向传播的伪码可在补充材料中找到。
,我们就能够继续网络的后向传播了(可见这里就是将计算损失梯度和梯度后向传播更新两步拆开了,第二阶段得到的描述符的梯度对应的就是第三阶段计算的描述符,因为网络没有变化,所以描述符还是相同的,所以梯度和描述符是对应的。第二阶段的作用就是能够计算每个图像与其他batch_size-1个图像的相似度和损失,然后用于第三阶段去更新参数)。然后累积每张图像的梯度,最后用来更新网络权重(就是一张张图像地去更新网络参数,求得的关于参数的梯度一张张加起来,等所有图像都更新后再将累积的更新梯度用来更新网络参数,而不是一张图计算后就更新)。多阶段后向传播的伪码可在补充材料中找到。

4. Experimental results
我们首先讨论实验中使用的不同数据集。然后我们在这些数据集上报告了实验结果,研究了提出的方法的关键参数,并与目前的研究状况进行了比较。
4.1. Datasets
Landmarks. 原始的地标数据集[4]包含213,678张图像,分成672个类。然而,由于这个数据集是通过查询搜索引擎半自动创建的,因此它包含大量错误标记的图像。在[16]中,Gordo等人提出了一种自动清理流程来清理该数据集以用于他们的检索模型,并将清理后的数据集公开。这个Landmarks-clean数据集包含42,410张图像和586个地标,我们在所有实验中都使用这个版本来训练我们的模型。
Oxford and Paris Revisited. Radenović等人最近修订了Oxford [42] 和Paris [43] 建筑数据集,更正了注释错误,增加他们的大小,为他们提供新的评估协议[44]。Revisited Oxford (ROxford)和Revisited Paris (RParis)数据集分别包含4,993和6,322张图片,每一张图片都有70张图片作为查询(例如图3的查询样本)。这些图像进一步根据识别所描述的地标的难度进行标记。然后这些标签被用来为这些数据集确定三种评估协议:简单,中等和困难。可以选择的是,可以向每个数据集添加一组100万张干扰图像(R1M),以使任务更加真实。由于这些新数据集本质上是原始Oxford和Paris数据集的更新版本,具有相同的特征但更可靠的ground-truth,我们在我们的实验中使用这些重新修订的版本。

4.2. Implementation details and parameter study
我们使用随机梯度和Adam[31]在公共Landmarks-clean数据集[16]上训练我们的网络。在所有的实验中,我们使用预先在ImageNet[49]上训练的ResNet-101[25]作为主干。我们附加了一个generalized-mean(GeM)层[46],它最近被证明比R-MAC池更有效[17,56]。GeM的能量是通过沿其他权重的反向传播来训练的。除非另有说明,我们使用以下参数:我们设置权重衰减为10−6,并应用标准数据增强方法(例如,颜色抖动、随机缩放、旋转和裁剪)。训练图像裁剪成800×800的固定大小,在测试时,我们将原始图像(未缩放、未扭曲)输入网络。我们在测试时尝试使用多种尺度,但没有观察到任何显著的改善。由于我们在单一尺度上操作,这本质上使我们的描述符提取比最先进的方法快3倍[17,44],对于一个可比的网络骨干。根据不同的实验研究,讨论了其他参数的选择。
Learning rate. 我们发现,不导致分歧的最高学习率会得到最好的结果。我们使用从10-4开始的线性衰减率,在200次迭代后下降到0。
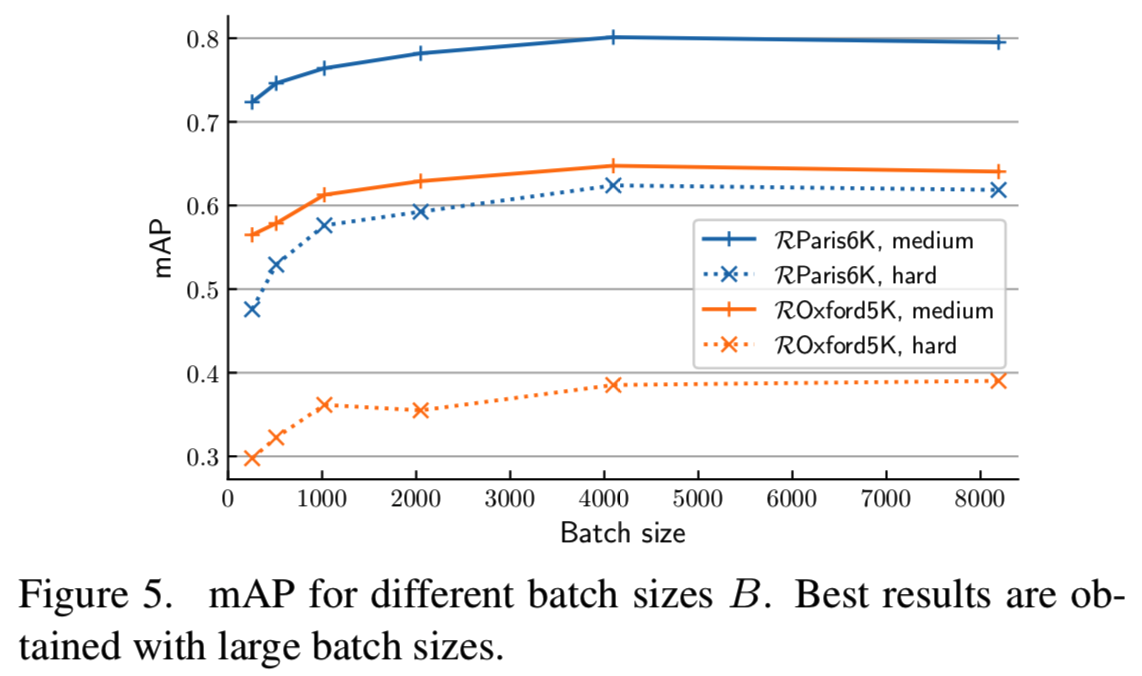
Batch size. 正如[24]指出的那样,我们发现更大的batch size会产生更好的结果(见图5)。在4096之后,性能会达到饱和,训练速度也会显著减慢。在随后的所有实验中,我们使用B = 4096。
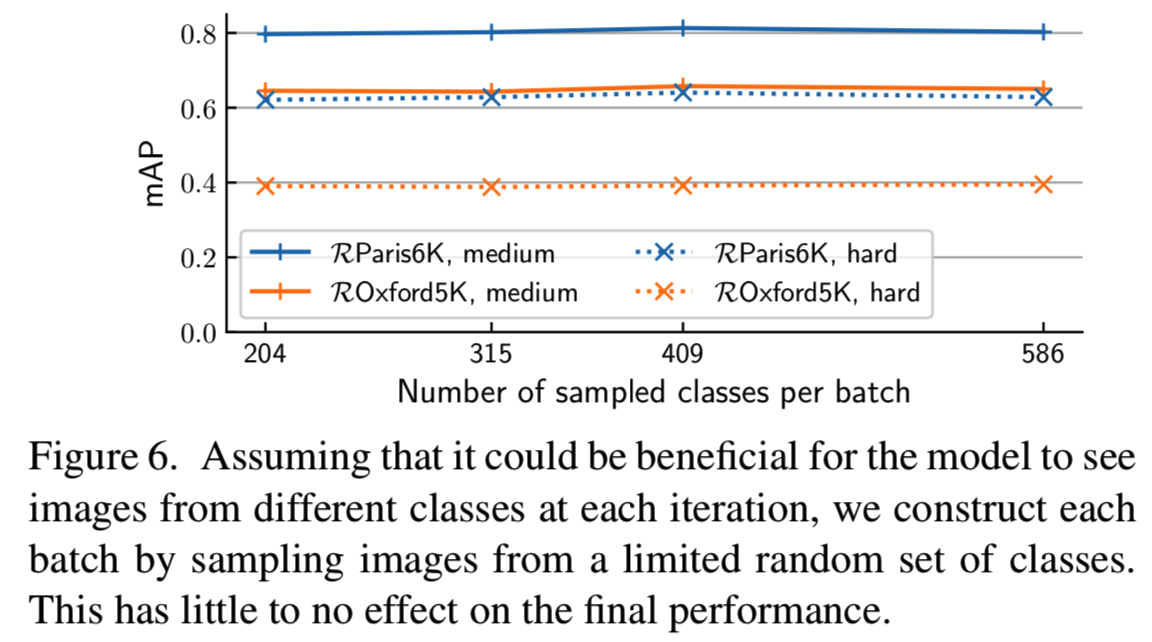
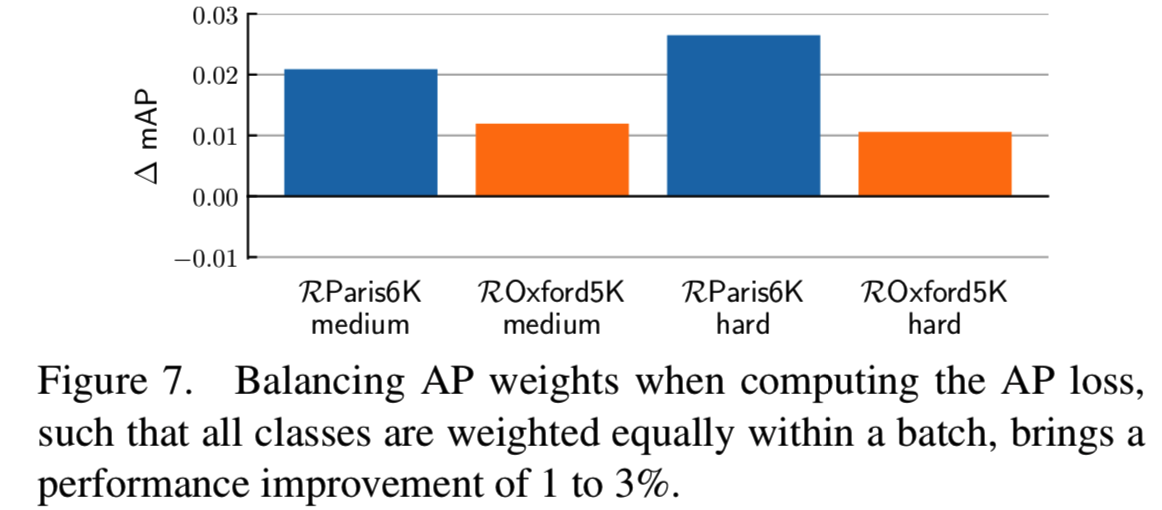
Class sampling. 我们通过从每个数据集类中随机采样图像来构建每个batch(因此所有类都在单个batch中出现)。我们也尝试了对类进行抽样,但没有观察到任何差异(见图6)。由于数据集不平衡,某些类在batch级别经常被过度表示。为了平衡这种情况,我们在等式12)中引入一个权重,以平等地对batch中的所有类进行加权。我们训练了有和没有这个(加权)选项的两个模型,结果如图7所示。类权重在mAP上的提升约为+2%,显示了这种平衡的重要性。
Tie-aware AP. 在[23]中,一个关联感知(tie-aware)的mAPQ损失版本被开发用于对整数值汉明距离进行排序的特定情况。[24]对实数值欧几里得距离使用相同版本的AP。我们使用简化的关联感知AP损失(参见[23]的附录F.1)来训练模型,除了原始的mAPQ损失外,还用mAPT表示。我们写的mAPT类似于等式(11),但用一个更精确的近似代替精度:
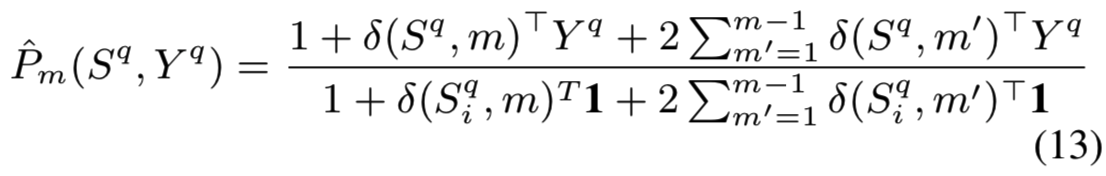
图8显示了mAP上的绝对差值。我们发现,直接由AP定义推导出来的mAPQ损失始终比关联感知公式的表现好,差距虽小,但非常显著。这可能是由于在实际实现中使用的关联感知公式实际上是理论关联感知AP的近似值(参见[23]中的附录)。我们在随后的所有实验中都使用了mAPQ损失。
Score quantization.我们的mAPQ损失取决于等式(7)中量化bin M的数量。我们在图4中绘制了不同M值下的性能。与之前的研究结果一致[24,58],该参数对性能的影响很小。在所有其他实验中,我们使用M = 20量化bins。
Descriptor whitening. 因为这是一种常见的做法[28,44],我们在评价之前白化我们的描述符。首先,我们从地标数据集中提取的描述符学习PCA。然后,我们使用它来归一化化每个基准数据集的描述符。在[28]中,我们使用平方根的主成分分析。我们在随后的所有实验中都使用了白化。
4.3. Ceteris paribus analysis
在本节中,我们将更详细地研究使用提议的listwise损失相对于最先进的损失的好处。为此,我们将我们的方法中提出的mAPQ损失替换为[17]中描述的triplet损失(TL)和hard negative mining(HNM)(即一个batch使用64个triplets)。然后我们对模型进行重新训练,保持管道的一致性,并分别重新调整所有超参数,如学习率和权值衰减。收敛后的性能如表1的前两行所示。我们实现的triplet损失,表示为“GeM (TL-64)”,与[17]效果相当或更好,这可能是由于从R-MAC切换到GeM池化方法[46]。更重要的是,我们观察到在使用提议的mAPQ损失(效果优化高达3% mAP)时,即使没有采用hard negative mining方案,也有显著的改进。我们强调,使用更大的batches(即在更新模型之前看到更多的triplets)进行训练,如GeM (TL-512)和GeM (TL-1024),并不能提高性能,如表1所示。注意,TL-1024对应于每个模型更新看到1024×3 = 3072个图像,这大致相当于我们的mAPQ损失的一个batch size B = 4096。这表明mAPQ损失的良好性能不仅仅是因为使用了更大的训练batches。

我们也在表1中显示每个方法相对于基本实现的训练工作(后向和前向传播的数量,更新的数量,总训练时间)以及超参数的数量和额外的代码行数(更多的细节见补充材料)。正如可以观察到的,我们的方法导致的权重更新比使用局部损失时要少得多。它还会显著减少前向和后向传递。这支持了我们的主张,即同时考虑所有图像的列表损失是更有效的。总的来说,我们的模型的训练速度是triplet损失的三倍。
这些方法还可以根据所涉及的工程量进行比较。例如,hard negative mining很容易需要数百个额外的行,并附带许多额外的超参数。相比之下,提出的backprop方法的PyTorch代码仅仅多了5行的代码,AP损失本身可以在10行内实现,且我们的方法只需要2个超参数(bins的数量和batch size B),有安全的defaults和对变化不是很敏感。
4.4. Comparison with the state of the art
现在我们将通过我们的模型得到的结果与最先进的结果进行比较。表2的上半部分总结了4.1节中列出的数据集在没有查询扩展情况下的最佳性能方法的性能。我们使用[44]的标识,因为这有助于我们阐明每种方法的重要点。主要来说,就是将generalized-mean pooling [46]用GeM表示,R-MAC池[56]用R-MAC表示。用于训练模型的损失函数类型为:contrastive损失用(CL)表示,triplet损失用(TL)表示,mAPQ损失用(AP)表示,如果不使用损失(即现成的特征)用(O)表示。
总的来说,我们的模型在大多数数据集和协议上的性能比最先进的水平高出1%到5%。例如,我们的模型比ROxford和RParis的hard协议[46]的最佳报告结果领先4个百分点以上。这是值得注意的,因为我们的模型在测试时使用单一尺度(即原始测试图像),而其他方法通过汇集在几个尺度上计算的图像描述符来提高性能。此外,我们的网络不经过任何特殊的预训练步骤(我们用ImageNet-trained初始化我们的网络),这也是与大多数先进的竞争对手不同的点。根据经验,我们观察到mAPQ的损失使这些训练前的阶段变得过时。最后,训练时间也大大减少:在一个P40 GPU上从零开始训练我们的模型需要几个小时。我们的模型将在接受后公开供下载。
我们还在表2的底部使用查询扩展(QE)并报告结果,这是文献[2,17,44,46]中的常见做法。我们使用了α-weighted版本[46],即α= 2和k = 10的最近邻。在8个协议中,我们的QE模型在6个协议中优于其他同样使用QE的方法。我们注意到,我们的结果与Noh等人[41]提出的基于局部描述符的方法相当。尽管我们的方法依赖于全局描述符(因此缺乏任何几何验证),但在没有额外干扰的情况下,它仍然比它在ROxford和RParis数据集上表现更好。

5. Conclusion
在本文中,我们提出了一种应用于图像检索任务的排序损失。我们直接优化mAP的可微宽松版本,我们称之为mAPQ。与用于此任务的标准损失函数相比,mAPQ不需要对图像样本进行昂贵的挖掘或仔细的预训练。此外,我们使用多阶段优化方案有效地训练我们的模型,该方案允许我们在任意批大小的高分辨率图像上学习模型,并在多个基准中获得最先进的结果。我们相信我们的发现可以通过展示目标度量中优化的好处来指导更好的图像检索模型的发展。我们的工作还鼓励了对实例级以外的图像检索的探索,因为我们利用了一种度量,这种度量可以同时从任意大小的排序列表中学习,而不是依赖于本地排序。