Web-Scale Responsive Visual Search at Bing
ABSTRACT
在本文中,我们介绍了一个部署在微软必应(bing)上的网页规模的通用视觉搜索系统。该系统在索引中容纳数百亿幅图像,每个图像有数千个特征,可以在不到200毫秒内作出响应。为了克服如此大规模数据的相关性、延迟性和可扩展性方面的挑战,我们采用了基于各种最新深度学习可视化特性的级联learning-to-rank框架,并部署在分布式异构计算平台上。定量和定性实验表明,我们的系统能够支持Bing网站和apps上的各种应用。
1 INTRODUCTION
视觉搜索,或基于内容的图像检索,是一个流行且长期存在的研究领域[1,12,18,23,25]。给定一幅图像,视觉搜索系统返回视觉上相似的图像的排序列表。它将查询图像与返回图像的已知信息相关联,从而派生出各种应用程序,例如,[5]定位照片的拍摄位置,以及从自拍照[14]中识别时尚物品。这使得视觉搜索在工业界也很受关注。
相关性是视觉搜索的主要目标和衡量标准。随着[20]深度学习的最新发展,视觉搜索系统在相关性方面也得到了改进,并且对一般消费者来说变得更容易获得。行业参与者对视觉搜索系统的探索[23,25]更多地关注于垂直特定系统的可行性,例如Pinterest或eBay上的图像,而缺乏对更高级目标的讨论,如相关性、延迟和存储。在这篇文章中,我们对微软必应的视觉搜索系统做了一个概述,希望能对如何构建一个相关的、响应性的、可扩展的网页规模的视觉搜索引擎提供一些见解。据作者所知,这是第一个介绍通用网络规模的视觉搜索引擎。
网页规模的视觉搜索引擎不仅仅是扩展现有的视觉搜索方法到一个更大的数据库。这里的网络规模是指数据库不局限于某个垂直或某个特定的网站,而是来自一个通用的网络搜索引擎的spider。通常数据库包含数百亿的图像,甚至更多。有了这么多的数据,主要的挑战来自三个方面:
- 首先,许多可能适用于较小数据集的方法变得不切实际。例如,Bag of Visual Words [17]通常需要在内存中存储inverted索引,以便高效检索。假设每幅图像只有100个特征点,那么反向索引的大小约为4TB,更不必说有效聚类和量化产生合理的视觉词的挑战了。
- 其次,即使使用了适当的分片,存储可扩展性仍然是个问题。假设我们只使用一个可视化特性,即4096维的AlexNet [11] fc7特性,并将特性存储分片到100台机器,那么每台机器仍然需要存储1.6 TB的特性。请注意,这些特性不能存储在普通硬盘中,否则低随机访问性能将使延迟不可接受。
- 第三,现代视觉搜索引擎通常使用一种“learning-to-rank”架构[3,10],利用来自多个特征的互补信息来获得最佳相关性。在web规模的数据库中,这对延迟提出了另一个挑战。尽管图像的检索可以并行化,但查询特征提取、分片实例之间的数据流控制以及最终的数据聚合都需要复杂的算法和工程优化。
- 除了前面提到的三个困难,还有一个独特的挑战,对于一般的搜索引擎。特定于垂直的搜索引擎通常拥有一个具有良好组织元数据(metadata)的受控图像数据库。然而,对于一般的视觉搜索引擎来说,情况并非如此,如果不是不可用的话,其中的元数据通常是无序的。这就更加强调了理解图像内容的能力。
换句话说,在一个web规模的可视化搜索系统中同时实现高相关性、低延迟和高存储可扩展性是非常具有挑战性的。我们建议用智能工程的权衡来解决这一困境。具体来说,我们建议使用级联learning-to-rank框架来权衡相关性和延迟,使用Product Quantization (PQ) [4] 来权衡相关性和存储,并使用配备分布式固态驱动器(distributed Solid State Drive,SSD)的集群来权衡延迟和存储可扩展性。在级联learning-to-rank框架中,首先使用一个分片inverted索引来有效地过滤掉“hopeless”数据库图像,并生成一个候选列表。然后,更具有描述性、也更昂贵的视觉特征被用来进一步重新排序候选对象,然后将其top结果传递给最终的等级排序者。在最终的level ranker中,提取完整的视觉特征,并将其输入Lambda-mart排名模型[2]中,获得查询与每个候选图像之间的相似度评分,并根据此评分生成排序列表。
本文的其余部分组织如下。在第2节中,我们将给出整个系统的工作流程概述。然后,我们将在第3节中详细介绍系统的工程实现,然后在第4节中介绍应用程序。第5节将提供所提出系统在相关性,延迟和存储可扩展性方面定量和定性的结果,结论在第6节。
2 SYSTEM OVERVIEW
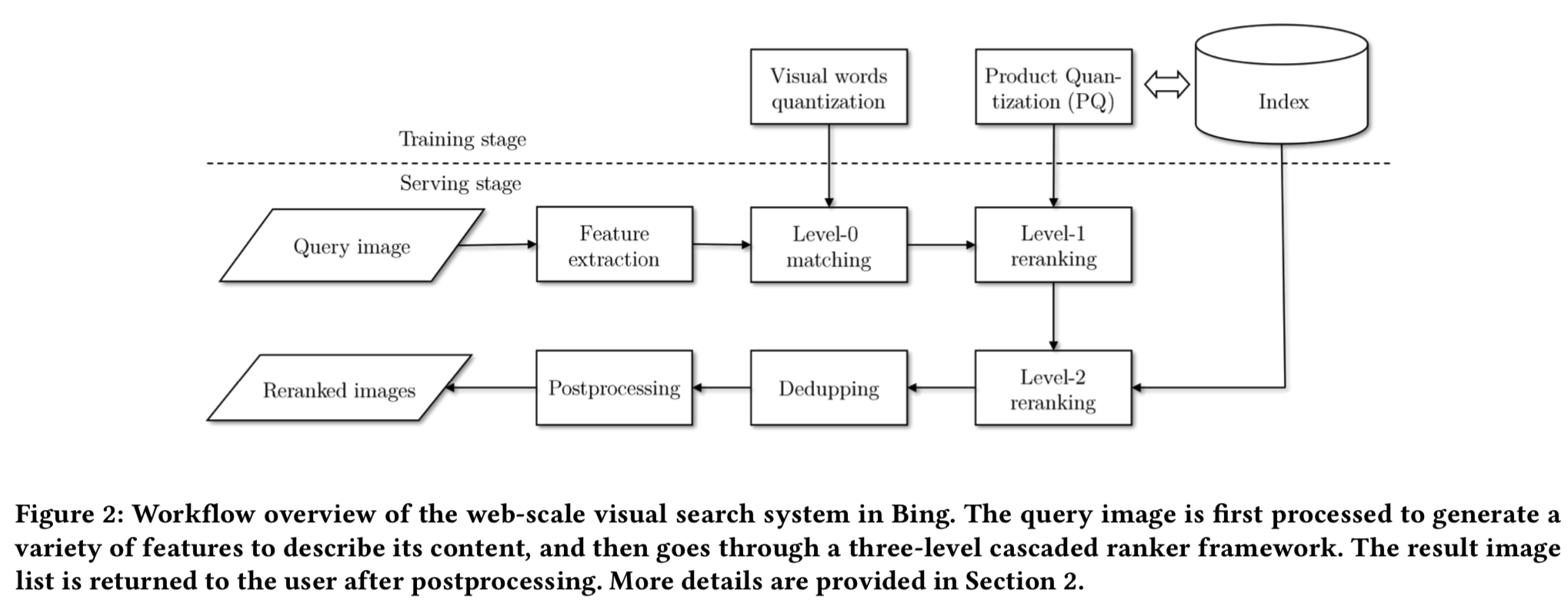
在深入了解系统是如何构建的之前,让我们先介绍一下工作流。当用户在Bing Visual Search提交一个他/她从网上发现或使用一个相机拍摄得到的查询图像,看起来很相似的图像和产品将被识别给用户去搜索或购买(例子在图1所示)产品。Bing Visual Search系统包括如下所述的三个主要阶段/组件,图2说明了一个查询图像如何得到最后结果图像的一般处理流程。
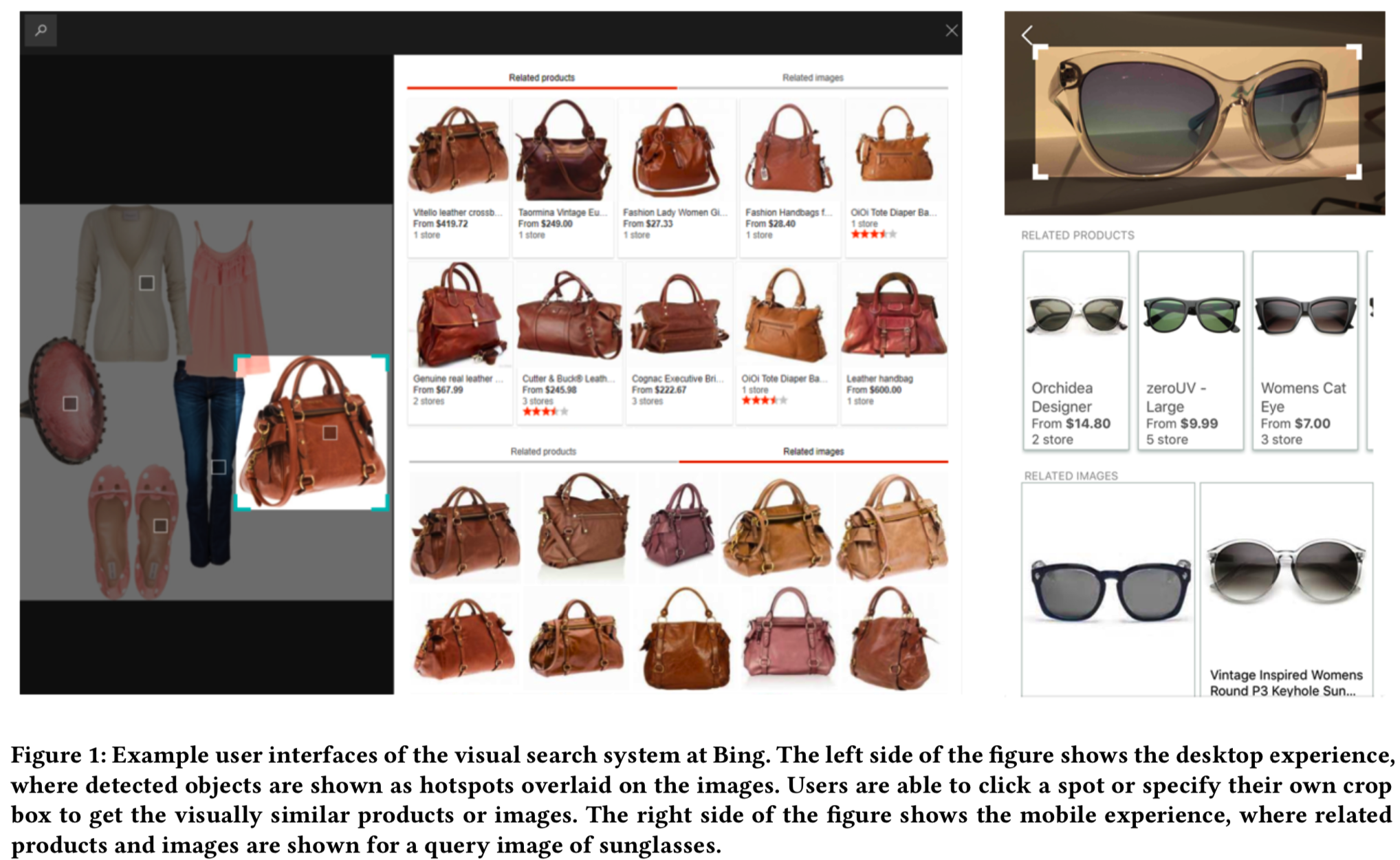
Query understanding: 我们从查询图像中提取各种特征来描述其内容,包括深度神经网络(DNN)编码器、类别识别特征、人脸识别特征、颜色特征和重复检测特征。我们还生成了一个图像标题,它可以识别查询图像中的关键概念。然后调用场景触发模型,以确定是否在视觉搜索中调用不同的场景。例如,当从查询中检测到购物意图时,搜索将被导向显示特定的体验,即特定的购物环节。图1显示了相关产品购物场景的用户界面示例。Bing Visual Search返回带有购物信息的结果,比如商店网站链接和价格。用户可以通过链接在商店网站上完成购买。物体检测模型也会运行来检测物体,用户可以点击自动标记的物体来查看相关的产品和图片。
Image retrieval: 在图像检索模块中,根据提取的特征和意图来检索视觉上相似的图像。如前所述,图像检索过程采用级联框架,将整个过程划分为Level-0匹配阶段、Level-1排序阶段和Level-2排序阶段。模块的细节将在第3.2小节中介绍。在排序列表生成后,我们做后处理(postprocessing),以删除重复和成人内容。然后将最后的结果集返回给用户。
Model training: 检索过程中使用的多个模型需要一个训练阶段。首先,在我们的系统中利用了几个DNN模型来提高相关性。由于训练数据、网络结构和损失函数不同,每个DNN模型各自提供互补信息。其次,利用联合k-Means算法[22]构建0级匹配的inverted索引。第三,采用PQ改进了DNN模型的服务延迟,且不存在太多的相关性妥协。我们还利用对象检测模型来改善用户体验。下面几节将介绍这些模型的详细信息。
3 APPROACH
在本节中,我们将详细介绍如何处理相关性、延迟和存储可扩展性,包括一些额外的特性,如对象检测。
3.1 Relevance
为了优化搜索相关性,我们使用了多个特征,其中DNN特征最为突出。我们使用几种最先进的DNNs,包括AlexNet[11]、ZFSPPNet[6,24]、GoogleNet[8,19]和ResNet[7]。最后的隐藏层作为深度embedding特征。我们使用从多种来源收集的训练数据来训练网络,包括人标记的数据和从网络抓取的数据。还可以利用开源数据集。我们的训练数据集广泛地涵盖了日常生活中的数千个主要类别,深度训练数据集也为特定领域收集,如购物。我们采用损失、pairwise损失和triplet损失等多种损失函数来监督DNN的训练。表1总结了我们使用的一组完整的特性。
图3展示了我们使用的DNN模型的三个示例。
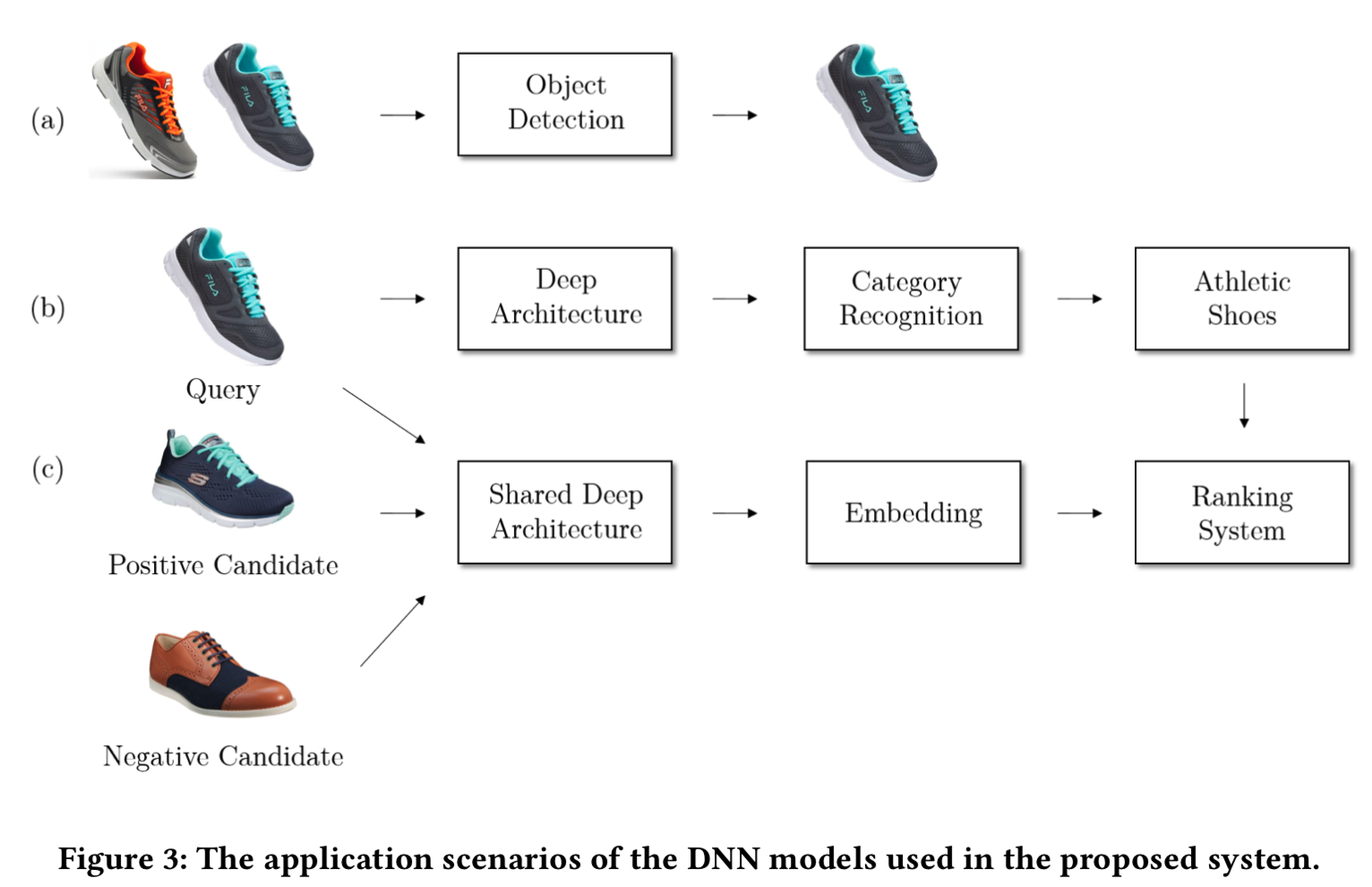
图3(a)是一个目标检测模型,对查询图像进行目标定位和相应的语义类别分类(即b)。图3(b)是一个softmax损失的产品分类网络。我们使用特定的细分存储库生成产品类别分类和训练数据,这些存储库涵盖时尚、家居家具、电子产品等。类别集包括数千个细粒度的类别,例如帽子和帽子(包括棒球帽、太阳帽和软呢帽)中的10个子类别。我们使用incepton-BN网络来获得准确性和延迟之间的平衡。使用各种学习超参数组合从头开始训练网络。在视觉搜索排序器中使用了pool5层DNN特征和softmax层类别特征。图3(c)是一个三元网络,它直接从图像学习到欧氏空间的embedding(这样训练得到一个网络,能够得到embedding特征),在欧氏空间中特征点之间的距离对应图像的不同程度。网络训练在大量的由人类labelers标记好的图像triplets(Q, I1、I2)中,其中每个labelers回答图像I1、I2哪个与Q更像的问题。 我们使用ImageNet数据集在预训练的DNN网络上微调triplet网络,损失被最小化,如下所示:
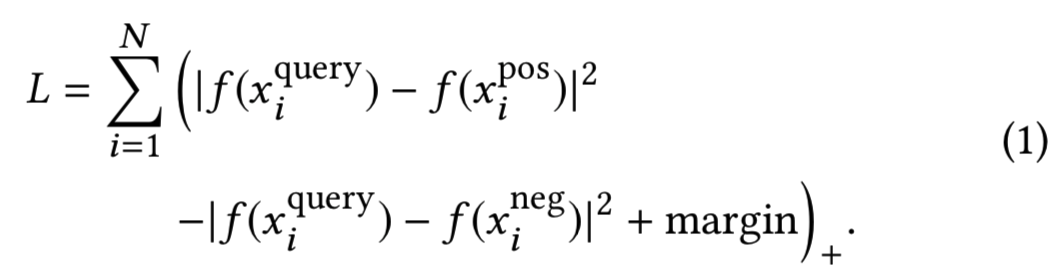
这里f (x)表示原始DNN中最后一个全连接层之后的一个紧凑embedding层,该嵌入层作为视觉搜索中的另一个DNN特征。
将各种DNN特征、非DNN视觉特征、目标检测和文本匹配特征聚合并利用在视觉搜索排序器中。表1列出了更多细节。我们还使用局部特性[21]来删除重复的图像。Lambda-mart排序模型是一个已知的具有排序损失函数的多元回归树模型,它取特征向量并生成最终的排序得分。最终的结果图像根据排名分数进行排序,并返回给用户。排序器训练数据的收集过程类似于三个一组训练数据的收集。一个额外的回归模型被用来将原始的成对判断转换为列表判断,就像Lambda-mart排名模型训练ground-truth一样。
3.2 Latency
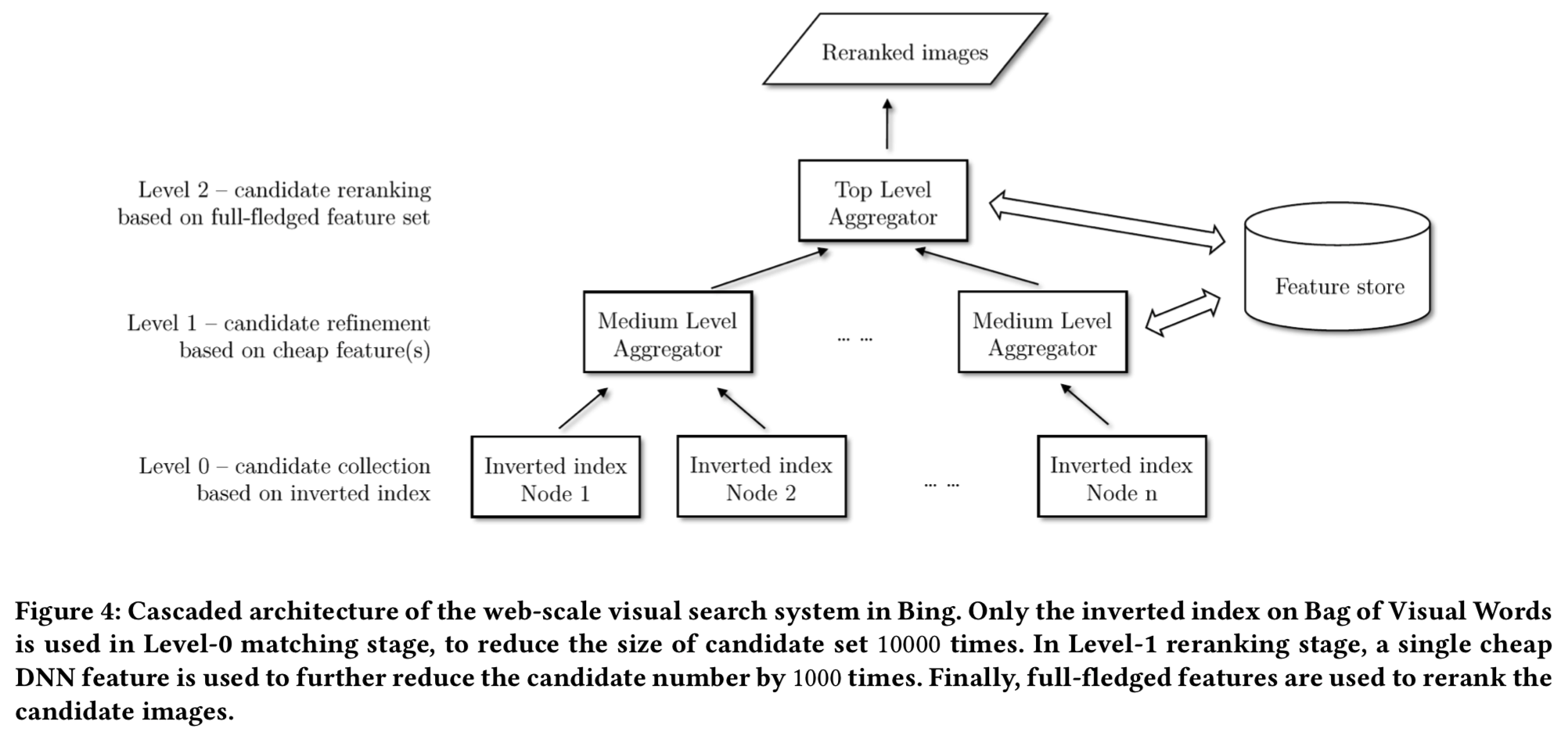
图像索引包含数百亿的图像。因此,提供响应式用户体验是非常具有挑战性的。级联排序框架的设计目的是在相关性和延迟之间实现良好的平衡。直觉告诉我们,过滤掉“hopeless”的候选人要比检索视觉上相似的图像容易得多。因此,可以使用cheap特性来显著减少搜索空间,然后使用更昂贵和富有表现力的特性来进行高质量的重新排序。可以使用inverted索引来生成初始候选集。
如图4所示,级联排序框架包括level-0匹配、level-1排序和level-2排序。level-0匹配基于inverted索引(其实就是视觉词)生成初始候选集。跟随Arandjelovic等人[1],我们使用由联合k -Means训练出来的视觉词作为图像的cheap表征(使用的可能是Bag of Visual Words方法),其细节如图5所示。量化后,每幅图像用N个视觉词表示。只保留与查询图像匹配的带有视觉词的索引图像,然后将该结果发送给level-1排序器。

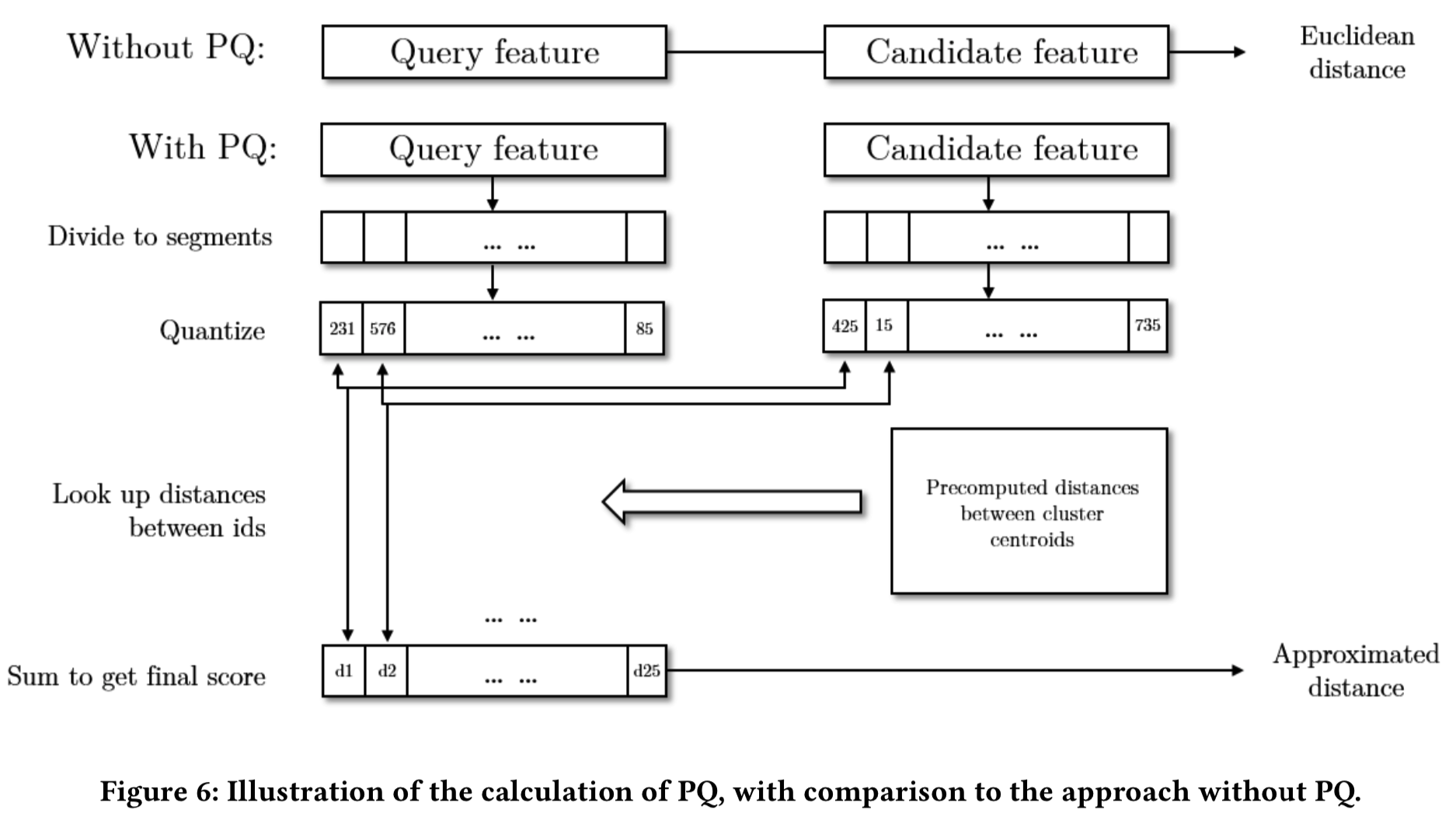
视觉词在几毫秒内将一组候选集从数十亿缩小到数百万。然而,应用上一节所讨论的full-fledged排序器仍然是不切实际的。因此,我们使用一个轻量级的level-1排序器来进一步减少候选的数量。计算一个单一的DNN特征作为level-1排序器,进一步减少候选索引图像的数量。由于存储特征和计算特征之间的欧氏距离的代价,我们在这里使用PQ。直觉其类似于Bag of Visual Words。我们使用聚类中心来近似特征向量,而不是处理高维特征。由于可以预先计算集群中心之间的距离,大大降低了距离计算的时间成本。空间成本也可以节省,因为字典中只需要存储ID(其实就是PQ向量,叫PQ IDs)。图6展示了一个高维向量分解成许多低维子向量,从而形成一个PQ向量。首先通过主成分分析(PCA)将DNN特征降至4n维。然后将每个新的4n维DNN特征划分为n个四维向量,确定在PQ模型中每个四维向量距离最近的聚类质心(即所有数据的第ni个4维向量聚类得到K个簇,假设K=256,那么某个图像该ni的值即通过计算其这个位置的4维向量和哪个簇的质心最近,设最近质心为52,即该ni值为该质心的值,这样某张图像的特征最后就能够转变成n个质心值组成最后的n个字节的PQ向量)。最后每个DNN编码器都可以用n个质心表示,它只占用n个字节,形成一个PQ向量。然后特征距离就可以近似为计算query图像的PQ向量![]() 和候选图像PQ向量
和候选图像PQ向量![]() 之间的距离。注意,每个
之间的距离。注意,每个![]() 和
和![]() 之间的欧式距离可以预先计算和预先存储。
之间的欧式距离可以预先计算和预先存储。
作为level-1排序的结果,候选集可以从数百万减少到数千。此时,将调用上一节中讨论的更昂贵的level-2排序器来更准确地对图像进行排序。使用在level-2排序器中的所有的DNN特征也用PQ进行加速。
3.3 Storage
级联框架中使用的所有特征都需要存储在内存中以实现高效检索。我们将DNN特征表示为PQ IDs而不是真实值,这大大降低了存储需求。例如,通过PCA和PQ方法,将一个2048维的ResNet DNN编码器中每张图像的空间需要从8 KB(2048*32bit / 8bit = 8KB,一个浮点数占32bit)减少到25字节,假设每次4维向量聚类使用256(2^8=256,即一个字节)个簇,PQ中n = 25,所以需要25个字节。在匹配步骤中,还使用了视觉单词来减少存储需求。具体来说,一组视觉单词对于每个图像只占用64字节。最后,我们将所有的特征,包括视觉词(也叫inverted索引)和PQ IDs(也叫PQ向量)分片到多个(最多数百个)机器中,以进一步节省计算和存储负担。正如在第3.2小节中所介绍的,我们使用三层架构来有效地管理分布式索引。
3.4 Object Detection
我们利用最先进的目标检测技术,为用户提供简单、准确的视觉搜索入口引导。例如,如果用户在搜索引擎中寻找服装的灵感,我们会预测用户的搜索/购物意图(即看用户输入的图像中有什么内容,比如上衣、裙子,包包等),并自动检测出几个用户感兴趣的对象,并对其进行标记,这样用户就不必再摆弄边框了。为了平衡速度和精度,我们从几种基于DNN的目标检测框架中选择了两种方法:Faster R-CNN[15]和Single Shot Multi-box detection (SSD)[13]。在模型训练过程中,通过对各种主干结构和大量参数的调整,得到了具有最佳精度和召回率的模型。时尚和家庭家具是我们的目标检测模型的前两个部分。对象检测模型将只在查询图像中检测到特定的视觉意图时运行,以节省计算成本。除了提供准确的边界框定位,对象检测模块还提供推断的对象类别。我们利用检测到的类别与索引中已有的图像类别进行匹配,进一步提高相关性。
3.5 Engineering
我们分析了整个视觉搜索过程,发现最耗时的过程是特征提取和类似的图像检索(level-0、level-1、level-2步骤)。因此,我们在这两个模块中利用广泛的工程优化来减少系统延迟并提高开发的灵活性。
Feature extraction on CPU: 当这个项目开始的时候GPU加速还不常见,一个被大量优化的名为Neural Network Tool Kit (NNTK)的库被开发来优化CPU上的DNN模型部署。所有核心操作如矩阵乘法和卷积都是用汇编语言编写的,使用最新的向量化指令。卷积层的前向传播也为不同的通道大小和特征映射大小精心优化,以使它们缓存友好。我们还使用线程级、机器级并行化和负载平衡来进一步提高吞吐量。
考虑到不同的应用场景可能需要不同的特性,为了允许灵活地重新组织特征提取管道,而不需要花费时间重新编译,我们开发了一种Domain Specific Language (DSL)。DSL由图形执行引擎执行,以动态地确定需要执行哪些操作才能获得所请求的特征,然后在多个线程中执行。为了实现最大的可靠性和灵活性,我们使用Microsoft ServiceFabric,一个micro-service框架实现了特征提取系统,并将其部署在Microsoft Azure云服务上。我们还使用缓存层存储索引中所有图片的特征,以及用户最近访问的所有图片。
Feature extraction on GPU: 随着像Microsoft Cognitive Toolkit (CNTK) [16]和Caffe[9]这样高质量的GPU加速DNN框架的出现,我们是第一批在GPU上部署web级视觉搜索系统服务堆栈的团队之一。基于GPU的DNN评估可以根据模型的不同,将特征提取速度提高10到20倍。我们在Azure上的弹性GPU集群上部署了对延迟敏感的模型,比如对象检测,并实现了40毫秒的延迟。适当的缓存系统能够进一步减少延迟和成本。
Efficient distributed retrieval: 除了级联框架外,我们还使用分布式框架来加速图像检索和重新排序系统,其瓶颈是level-0匹配和特征检索。level-0匹配中的inverted索引检索阶段在数百台机器上并行执行,并带有主动超时机制。这些特征存储在SSDs中,SSDs比常规硬盘具有更好的随机访问性能。
4 APPLICATIONS
Bing视觉搜索已经被部署到Bing.com和Bing应用程序中。在这两种情况下,查询图像可以是网页类型的图像,也可以是从手机捕捉到的照片。Bing视觉搜索允许用户在默认情况下指定整个图像作为搜索查询。它还支持感兴趣的区域,因此图像的一部分也可以作为查询。
4.1 Bing.com
在Bing.com中,有四个入口点可以调用视觉搜索。
假设Alice在Bing图片搜索中寻找厨房装修的灵感,有一张图片吸引了她的注意。她单击图像,并进入图像详细信息页面(Image Details Page)。然后,她可以在图像详细信息页面(Image Details Page)右侧的相关图像部分(Related Images,参见图1的中间图像右下选项)中找到类似的图像。
Alice对图片中漂亮的枝形吊灯特别感兴趣。她可以点击图片右上方的视觉搜索按钮,这是第二个触发视觉搜索的地方。它将在图像上显示一个视觉搜索框。Alice可以拖动和调整盒子,使其只覆盖枝形吊灯。它将触发相关图像搜索。Bing还可以自动检测用户的搜索意图。当检测到有购物意图时,除了常规的图片搜索,Bing还会运行产品搜索(product search,图1中间图左下选项Related Products)来寻找匹配的产品。在本例中,Bing将返回一个吊灯产品列表。Alice可以简单地点击适合她的吊灯,在相关的产品区挑选最好的商家,最后完成她的购买。每当她调整视觉搜索框时,bing就会自动使用图片的选定部分作为查询重新运行视觉搜索。
在图像细节页面(Image Details Page),Bing也自动检测对象,并使用覆盖热点(红点)标记它们。因此,Alice不必手动调整边界框。她只需点击热点,就可以触发视觉搜索。这被认为是第三个入口点。
除了上述三种情况,用户还可以到Bing图片搜索页面,通过点击搜索栏内的摄像头按钮,上传图片或粘贴图片URL。然后将显示视觉搜索结果。
4.2 Bing App
我们以两种方式支持手机上的视觉搜索。首先,我们在m.Bing.com上提供了与Bing.com相同的视觉搜索功能。其次,用户可以安装Bing的手机app。m.Bing.com和Bing app都支持使用相册中已有的照片进行视觉搜索,或者直接使用手机摄像头拍照。除了展示相关产品(Related Products)和相关图片(Related Images)外,其基本目标是利用视觉搜索技术挖掘图片背后的知识。
5 EXPERIMENTS
在本节中,我们将对部署在Bing上的提出的系统进行评估。根据主要的动机,我们使用相关性、延迟和存储消耗来评估一个通用的网页级视觉搜索引擎。我们也提供一些定性的结果,以显示一般的结果质量和提出的系统的体验效果。
Relevance: 使用Normalized discounted cumulative gain (NDCG)来评估相关性。从bing的搜索日志中抽取数以千计的查询,准备一个测量集。通过图像查询,我们可以从Bing和其他搜索引擎中获得最相关的候选图像。然后,我们要求人类标签者基于计算的ground truth排序对候选图像的相关性进行两两判断(用来作为ground-truth数据)。基于此测量集,利用视觉搜索系统对候选图像进行重新排序,并计算NDCG@5作为最终的度量。
这种度量方法有其优点和缺点。评估搜索引擎相关性的一个理想方法是在某个查询和索引中的所有图像之间得到一个ground truth排序。由于索引中有数百亿幅图像,这显然是不可行的。这就是在受限测量集上提出的NDCG的优势所在:该方法使相关性评估在可接受的标签工作量下可行。但是,在分析数字的时候,我们还需要注意的是,在这个过程中只评估了level-2重新排序模块,而索引大小、level-0匹配和level-1重新排序并不影响NDCG数字。
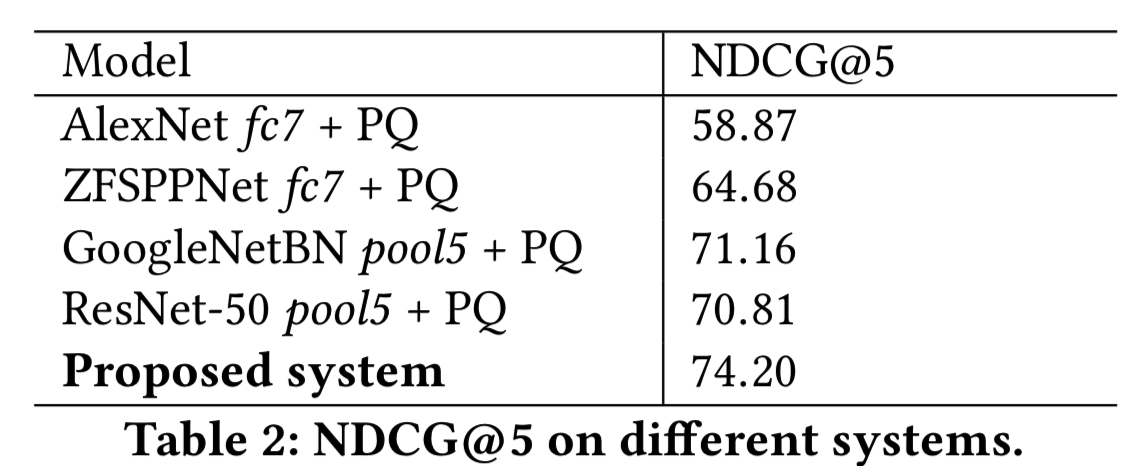
在表2中,我们报告了提议的系统的NDCG@5和只有一个特征的不同基线。表2中列出的所有DNN模型都是使用Bing数据集对数千个类别进行训练的。从表中可以看出,所选择的DNN特征确实提供了补充信息,都有助于提高相关性。我们还分析了存储和相关性之间的权衡如何影响相关性:使用原始DNN特征的系统的NDCG@5,使用PCA降维的DNN特征,以及使用PQ在PCA之上量化的DNN特征,如表3所示。

Latency: 我们在表4中测量并报告了端到端和组件方面的系统延迟。正如第4节所介绍的,从技术角度来看有两种不同的场景。一种是当在索引中查询图像时,可视化发现是预期的用法(即图像是本地的)。另一种是查询图像由用户上传,或者当用户指定一个裁剪框对感兴趣的区域进行视觉搜索时。在前一种情况下,由于我们已经有了视觉特征,可以通过节省网络传输和特征提取时间来减少系统延迟。后一种情况会显示更长的延迟,因为我们必须做全面的特征提取。正如我们从表中看到的,由于对级联重新排序模块进行了积极的优化,延迟的瓶颈实际上是视觉特征的检索或计算,具体取决于场景。注意,目前的特征提取仍然是在CPU上执行的,如果使用GPU,将显著加速。

Storage: 我们将每张图像的存储成本与原始的DNN特征和量化后的PQ ID进行比较,见表5。PQ通常显示节省100到1000倍。

图7展示了必应视觉搜索系统的一些例子,提供了该系统在各种场景下的性能的定性说明,包括有剪切框和没有剪切框的查询、相关图片和相关产品结果。

6 CONCLUSIONS
在这篇文章中,我们介绍了一些方法来克服网络规模的视觉搜索系统在相关性、延迟和存储可扩展性方面的挑战。我们使用最先进的深度学习功能来实现良好的相关性。成对判断形式的训练数据也有助于提高learning-to-rank框架的相关性。我们利用为大规模数据和工程优化量身定制的算法来实现小于200ms的延迟和经济有效的存储。算法示例包括PQ、inverted索引、Lambda-mart排序器和级联排序器结构。工程优化包括GPU/CPU加速、分布式平台和基于云的弹性部署。
基于所提出的系统,可以有许多有趣的方向。第一个是进一步增加索引大小。搜索系统的价值和技术挑战随着规模的增长而急剧增加。如果索引包含的图像超过数千亿幅,则需要更智能的特征编码、更高效的特征检索索引和更高级的模型来实现高相关性。第二个有趣的方向是度量的发展。虽然相关性是用户选择搜索引擎的主要动机,但一系列多样化、有吸引力和个性化的搜索结果也将有助于用户增长。然而,这些期望往往不利于DCG。如何定义一个与用户需求一致的综合度量仍然是一个重要而悬而未决的问题。最后但并非最不重要的是,扩展该系统以利用其他设备,如FPGAs,是另一个充满潜力的方向。在创建Bing Visual Search时,我们学到了很多,也看到了更多的挑战和机遇。