https://ceyuan.me/SemanticHierarchyEmerge
Abstract
尽管生成对抗网络(GANs)在图像合成方面取得了成功,但对于生成模型在深层生成表征中学到了什么,以及如何由最近GANs引入的分层随机性构成逼真的图像,人们还缺乏足够的理解。在这项工作中,我们展示了将高度结构化的语义层次作为从最先进的GAN模型(如StyleGAN和BigGAN)的生成表征得到的合成场景的变量因素。通过在不同的抽象级别上探索具有广泛语义集的分层表示,我们能够量化在输出图像中发生的激活和语义之间的因果关系。这样的量化确定了GANs在构建场景时学习到的人类可理解的变量因素。定性和定量的结果进一步表明,被带有分层潜在编码的GANs学习得到的生成表征专门合成了不同的层次语义:早期层往往决定了空间布局和配置,中间层控制分类对象,和后来的层最后渲染场景属性以及配色方案。识别这一组可操作的潜在变化因素有助于语义场景操作
1 Introduction
深度神经网络的成功源于表示学习,它识别了高维观察数据[5]背后的解释因素。之前的研究表明,许多概念检测器会自发地出现在为分类任务而训练的深层表征中。例如,Gonzalez-Garcia等[10]研究表明,用于物体识别的网络能够检测出具有语义的物体部分,Bau等[3]证实,来自分类图像的深度表示能够在不同的层次上检测出不同的分类概念。
通过对深层表征及其结构的分析,可以了解深层特征[22]的泛化能力以及特征在不同任务[37]之间的可转移性。但目前对深层表征的解释主要集中在判别模型上[41,10,39,1,3]。最近的生成对抗网络(GANs)[11,16,17,6]能将随机噪声转换成高质量的图像,然而,可学习的生成表征的特性以及一个真实图像是如何由GAN的生成器的不同层组合而成的仍较少探讨。
众所周知,卷积神经网络(CNNs)的内部单元在训练对场景[41]进行分类时,可以作为物体检测器。代表和检测最有信息的对象到一个特定类别提供了一个用于分类场景的理想的解决方案,如沙发和电视这两个对象代表客厅这个类,而床和灯是卧室。然而,场景的合成需要更多的知识来学习深层生成模型。具体地说,为了绘制高度多样化的场景图像,像我们人类,可能需要深度表征不仅学会生成与一个特定的场景类别相关的每个对象,还要能决定底层房间布局以及呈现各种场景属性,例如,照明条件和配色方案。最近解释GANs[4]的研究在可视化 说明中间层的内部过滤器是专门用于生成某些对象的,但如果仅从对象方面研究场景合成,这将难以充分了解GAN是如何组成一个写实的图像的,因为它包含多种来自布局级别,类别级别和属性级别的变量因素。原始的StyleGAN的研究[17]指出,分层潜在编码实际上控制着从粗到细的合成,但这些变化因素如何组合在一起以及如何量化这些语义信息仍然是未知的。不同的是,这项工作在层次生成表征上给出了一个更深层次的解释,在这个意义上,我们在多个抽象层次,包括布局,分类对象,属性,和色彩方案将这些分层的变量因素与人类可以理解的场景变化匹配起来。图1显示了正确识别相应层时在不同级别上的操作结果。

以最先进的StyleGAN模型[17]为例,我们揭示了高度结构化的语义层次从深度生成表征中出现,这些表征带有经过训练的用于合成场景的分层随机性,甚至没有使用任何外部监督。分层表示首先用不同抽象层次上的一组广泛的视觉概念来探讨。通过量化分层激活和出现在输出图像的语义之间的因果关系,我们能够确定在使用分层潜在编码的GAN模型的不同层之间最相关的变量因素:早期层指定空间布局,中间层组成category-guided对象,后层渲染整个场景的属性和配色方案。我们进一步表明,从布局,对象,场景属性和色彩方案识别这样一组可操作的变量因素,有利于语义图像处理(如图1所示),具有很大的多样性。提出的操作技术进一步推广到其他GANs,如BigGAN[6]和ProgressiveGAN[16]。
2 Related Work
Deep representations from classifying images. 许多人尝试研究为分类任务而训练的CNN的内部表征。Zhou等人[41]通过简化输入图像分析了隐藏单位,看看哪个上下文区域给予最高的响应,Simonyan等[31]应用反向传播技术计算特定图像类的特点映射,Bau等[3]在分割掩模的援助下解释隐藏表征,Alain和Bengio[2]训练独立线性探针分析不同层之间信息的分离性。也有一些研究转移CNN的特征来验证学习的表征如何适合不同的数据集或任务[37,1]。此外,通过将给定的表征回图像空间来反转特征提取过程[39,23,21],还可以了解CNN在区分不同类别时实际上学习了什么。然而,这些为分类网络开发的解释技术不能直接应用于生成模型。
Deep representations from synthesizing images. 生成式对抗网络(GANs)[11]极大地促进了图像的合成。一些最近的模型[16,6,17]能够生成逼真的人脸、物体和场景,使GANs适用于真实世界的图像编辑任务,如图像处理[29,34,32,36]、图像绘制[4,25]和图像样式转换[43,8]。尽管取得了如此巨大的成功,但GANs究竟学会了什么,才能制作出如此多样而又真实的图像,这一点仍然不确定。Radford等人[27]指出了GAN潜在空间中的矢量算法现象,然而,如何发现训练良好的模型中存在何种语义以及如何构造这些语义来合成高质量的图像仍然是一个未解决的问题。最近的一项工作[4]分析了GAN中生成器的单个单元,发现它们学会自发地合成信息丰富的视觉内容,如物体和纹理。同时进行的工作[14,9]也分别通过学习语义对GANs的可操纵性和记忆性进行了探索。与它们不同的是,我们的工作定量探讨了在分层生成表征中多层语义的出现。
Scene manipulation and editing. 之前的工作还包括编辑场景图像。Laffont et al[18]定义了40个瞬时属性,并设法将类似场景的外观转移到图像中进行编辑。Cheng等[7]提出了言语引导图像解析来识别和操纵室内场景中的物体。Karacan等人学习了一种基于预定义布局和属性的条件GAN来合成室外场景。还有一些作品[19,43,13,20]研究了图像到图像的转换,可以用来将一个场景的风格转换到另一个场景。与他们不同的是,我们通过解释从受过良好训练的GANs的生成表示中出现的层次语义来实现场景操作。除了图像编辑之外,这种解释也让我们更好地了解生成模型是如何产生逼真的合成效果的。
3 Variation Factors in Generative Representations
3.1 Multi-Level Variation Factors for Scene Synthesis
想象一位艺术家在画一幅客厅的画。在画每一个物体之前,第一步是选择一个透视图,建立房间的布局。在空间结构设置好之后,下一步就是添加一些通常会出现在客厅里的物品,比如沙发和电视。最后,艺术家会用特定的装饰风格来提炼画面的细节,例如,暖色或冷色,自然照明或室内照明。上面的过程反映了一个人如何从多个抽象层次解释一个场景。同时,给定一幅场景图像,我们可以提取多个层次的属性,如图2所示。相比之下,像GANs这样的生成模型是完全端到端训练的场景合成方式,不需要事先了解绘制技巧和相关概念。尽管如此,经过训练的GANs还是能够制作出逼真的场景,这让我们怀疑GANs是否已经掌握了任何人类可以理解的绘画知识,以及自然地掌握了场景的变量因素。

3.2 Layer-wise Generative Representations
一般来说,现有的生成模型采用随机采样的潜在编码作为输入,输出尽可能真实的图像合成。这种从潜在编码到合成图像的一对一映射非常类似于判别模型中的特征提取过程。因此,在本作品中,我们将输入的潜在代码作为生成表征,它将唯一地决定输出场景的外观和属性。另一方面,目前最先进的GAN模型(如StyleGAN[17]和BigGAN[6])引入分层随机性,以提高训练稳定性和综合质量。如图3所示,与仅将潜在编码作为第一层输入的常规生成器相比,具有分层随机性的改进生成器将随机潜在编码带入所有层。因此,我们将它们视为分层的生成表征。值得一提的是,越来越多的最新GAN模型继承了使用分层潜码实现更好生成质量的设计,如SinGAN[28]和HoloGAN[24]。

为了探究GANs如何通过学习分层变化因素来产生高质量的场景合成,以及每一层的生成表征在这个过程中起着什么作用,本工作旨在建立变化因素与生成表征之间的关系。Karras等[17]已经指出,分层随机度的设计实际上控制了从粗到细的合成,然而,“粗”和“细”到底指的是什么仍然不确定。不同的是,为了使变化因素与人的感知相一致,我们将它们分为四个抽象层次,包括布局、分类对象、场景属性和配色方案。我们在第4节进一步提出了一个框架,以量化输入生成表征和输出变异因素之间的因果关系。我们惊奇地发现GAN以一种与人类高度一致的方式合成了一个场景。在所有的卷积层上,GAN设法分层地组合这些多层次的抽象。其中,GAN在前期构建空间布局,在中期综合指定类别的对象,在后期呈现场景属性和配色方案。
4 Identifying the Emergent Variation Factors
如第3节所述,我们的目标是从四个不同的抽象层次解释场景合成模型学习到的潜在语义。先前在几个场景理解数据库上的努力[42,33,18,26]使一系列分类器能够预测场景属性和类别。此外,我们还使用几个现有的主要用于布局检测[40]和语义分割[35]的分类器,来帮助分析合成的场景图像。具体来说,给定一个图像,我们能够使用这些分类器来获得关于各种语义的响应分数。然而,仅仅预测语义标签远不能识别GANs从训练数据中捕捉到的变量因素。更具体地说,在所有的多层次候选概念中,并不是所有的概念都对一个特定的场景合成模型有意义。例如,“室内照明(indoor lighting)”永远不会出现在桥、塔等室外场景中,而“封闭区域(enclosed area)”则总是出现在卧室、厨房等室内场景中。因此,我们提出了一种方法来定量地识别出现在学习的生成表征内部的最相关和可操作的变量因素。图4说明了识别过程,包括两个步骤,即探查(4.1节)和验证(4.2节)。这样的识别使不同的场景操作成为可能(第4.3节)。
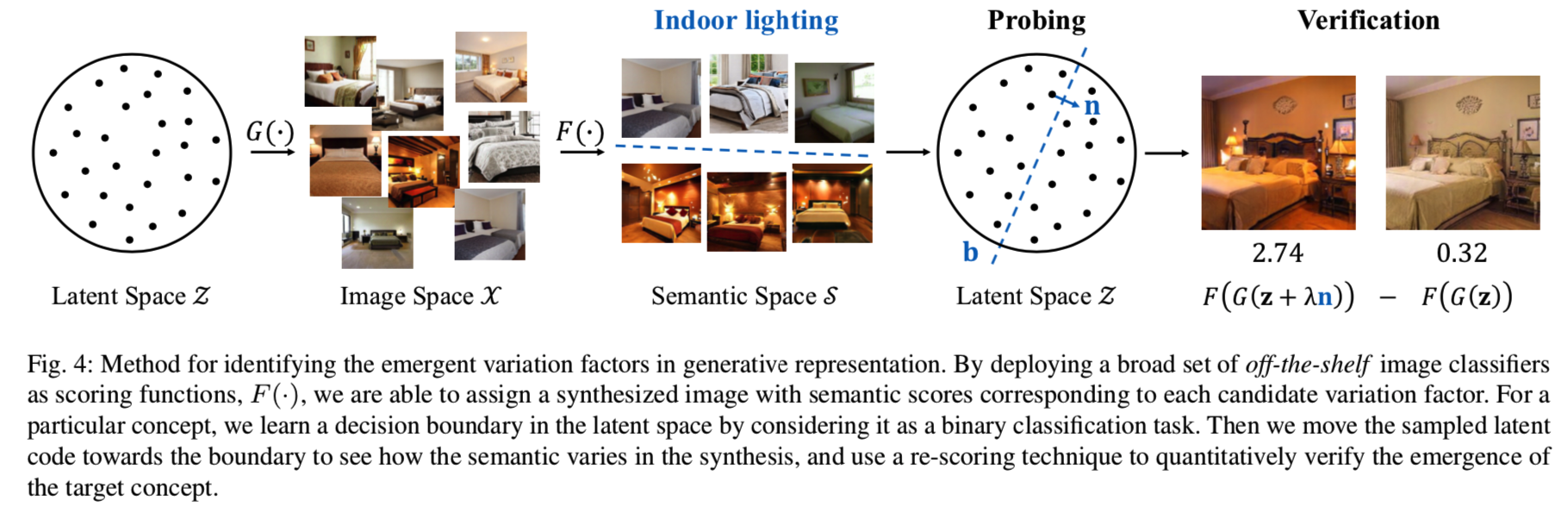
4.1 Probing Latent Space
GAN的生成器G(·)通常学习潜在空间![]() 到图像空间X的映射。潜在向量
到图像空间X的映射。潜在向量![]() 可以认为是GAN学习到的生成表示。要研究Z内部变化因素的出现,首先需要从Z中提取语义信息,这不是小事。为了解决这个问题,我们采用合成图像,x = G (z),作为一个中间步骤,并使用一组广泛的现成的图像分类器来帮助为每个采样的潜在编码z分配语义分数。以“室内照明(indoor lighting)”为例,场景属性分类器能输出一个输入图像看起来像有室内照明的概率,用其作为语义分数(semantic score)。回想一下,我们把场景表现分为布局、对象(类),和属性水平,我们引入布局估计器,场景分类识别器,和属性分类器分别从这些抽象级别预测语义分数,分别形成一个分层语义空间S。在建立一个从潜在空间
可以认为是GAN学习到的生成表示。要研究Z内部变化因素的出现,首先需要从Z中提取语义信息,这不是小事。为了解决这个问题,我们采用合成图像,x = G (z),作为一个中间步骤,并使用一组广泛的现成的图像分类器来帮助为每个采样的潜在编码z分配语义分数。以“室内照明(indoor lighting)”为例,场景属性分类器能输出一个输入图像看起来像有室内照明的概率,用其作为语义分数(semantic score)。回想一下,我们把场景表现分为布局、对象(类),和属性水平,我们引入布局估计器,场景分类识别器,和属性分类器分别从这些抽象级别预测语义分数,分别形成一个分层语义空间S。在建立一个从潜在空间![]() 到语义空间B的一对一的映射后,,我们通过其当做一个bi-classification问题去搜索每个概念的决策边界,如图4中所示。这里以“室内照明(indoor lighting)”为例,边界将隐藏空间
到语义空间B的一对一的映射后,,我们通过其当做一个bi-classification问题去搜索每个概念的决策边界,如图4中所示。这里以“室内照明(indoor lighting)”为例,边界将隐藏空间![]() 划分为两组,即室内照明是否存在。
划分为两组,即室内照明是否存在。
4.2 Verifying Manipulatable Variation Factors
在探索了一组广泛候选概念的潜在空间之后,我们仍然需要找出哪些作为变量因素与生成模型最相关。关键问题是如何定义“相关性”,或者说,如何验证学习的表示是否已经编码了特定的变化因素。我们认为,如果目标概念可以从潜在空间的角度进行操作(例如,通过简单地改变潜在编码来改变合成图像的室内照明状态),那么GAN模型能够在训练过程中捕捉到这些变化因素。
如上面所说,我们已经得到了用于每个候选的分离边界。![]() 表示这些边界的法向量,其中C是候选的总数。对于某边界,如果我们沿着其法向量(正向)的方向移动潜在编码z,语义分数应该相应变化。因此,我们建议对不同的潜在编码重新评分,以量化一个变化因素如何与分析的目标模型相关。如图4所示,该过程可表示为:
表示这些边界的法向量,其中C是候选的总数。对于某边界,如果我们沿着其法向量(正向)的方向移动潜在编码z,语义分数应该相应变化。因此,我们建议对不同的潜在编码重新评分,以量化一个变化因素如何与分析的目标模型相关。如图4所示,该过程可表示为:
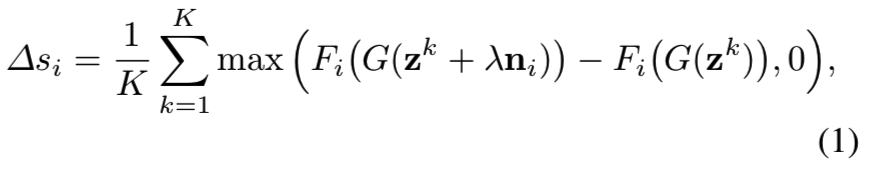
其中![]() 表示K个样本的平均值,使度量更准确。λ是一个固定的移动步长。为了使该度量能够在所有候选中进行对比,所有法向量
表示K个样本的平均值,使度量更准确。λ是一个固定的移动步长。为了使该度量能够在所有候选中进行对比,所有法向量![]() 都归一化到固定norm 1,λ设置为2。使用重新评分技术,我们能够在所有C个概念中简单排序分数
都归一化到固定norm 1,λ设置为2。使用重新评分技术,我们能够在所有C个概念中简单排序分数![]() 去检索最相关的潜在变量因素。
去检索最相关的潜在变量因素。
4.3 Manipulation with Diversity
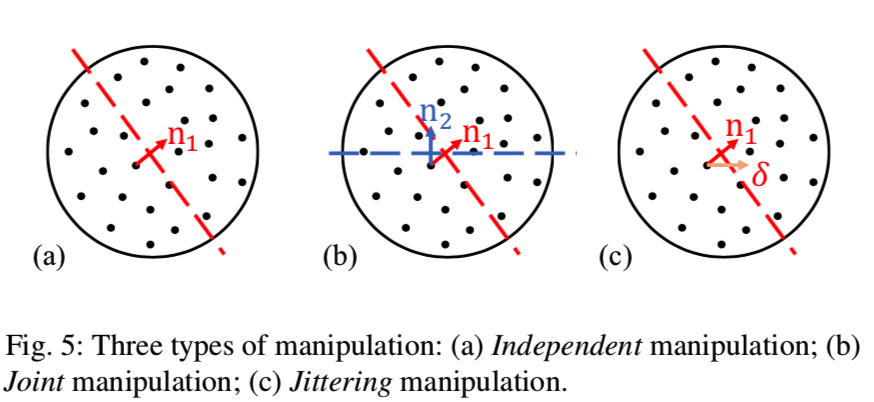
在识别语义变量因素的基础上,提出了进一步操纵图像的几种方法。图5显示了三种类型的场景操作。一种简单而直接的方法,称为Independent操作,是将代码z沿着具有一定语义的法向量ni移动步长λ。操作编码![]() 输入到生成器中去生成新图像。操纵的第二种方法使场景编辑与一个以上的变量因素联合。我们称之为Joint操作。以两个变化因素(法向量n1和n2)为例,将原编码z如
输入到生成器中去生成新图像。操纵的第二种方法使场景编辑与一个以上的变量因素联合。我们称之为Joint操作。以两个变化因素(法向量n1和n2)为例,将原编码z如![]()
![]() 同时沿两个方向移动。其中,λ1和λ2是分别控制这两种语义对应的操作强度的步长参数。由于这两种操作方法能够从多个抽象级别进行更精确的控制,因此我们还将随机性引入操作过程以增加多样性,即Jittering操作。关键思想是用随机采样的噪声
同时沿两个方向移动。其中,λ1和λ2是分别控制这两种语义对应的操作强度的步长参数。由于这两种操作方法能够从多个抽象级别进行更精确的控制,因此我们还将随机性引入操作过程以增加多样性,即Jittering操作。关键思想是用随机采样的噪声![]() 对操纵方向进行细微的渗透。可以表示为
对操纵方向进行细微的渗透。可以表示为![]()
5 Experiments
在生成过程中,每一层的深层表示,特别是StyleGAN[17]和BigGAN[6],实际上是直接从投影的潜在编码派生出来的。因此,我们认为潜在编码是生成表示,它可能与分类网络中的传统定义略有不同。我们对GANs中各层次发电机的变异因子进行了详细的实证分析。我们表明,变异因子的层次出现在深层生成表征作为学习合成场景的结果。
实验部分组织如下:第5.1节介绍了我们的实验细节,包括生成模型,训练数据集和我们使用的现成分类器。第5.2节对最新的StyleGAN模型[17]进行了分层分析,定性和定量地验证了多层变化因素被编码在潜在空间中。在第5.3节中,我们探讨了GANs如何表示分类信息,如卧室和客厅。我们揭示了GAN在一些中间层上合成共享对象。仅通过控制它们的激活,我们可以很容易地覆盖输出图像的类别,比如将卧室变成客厅,同时保留其原有的布局和室内照明等高层属性。第5.4节进一步表明,我们的方法可以忠实地识别与特定场景相关的最相关的属性,促进语义场景操作。第5.5节对重评分技术和分层操作进行了消融研究,以显示我们的方法的有效性。
5.1 Experimental Details
Generator models. 本研究采用最先进的深度生成模型进行高分辨率场景合成实验,包括StyleGAN[17]、BigGAN[6]和PGGAN[16]。其中,PGGAN采用了传统的生成器结构,其潜在编码只被输入到第一层。不同的是,StyleGAN和BigGAN通过向所有卷积层输入潜在编码,引入了分层随机性,如图3所示。我们的分层分析阐明了为什么它是有效的。
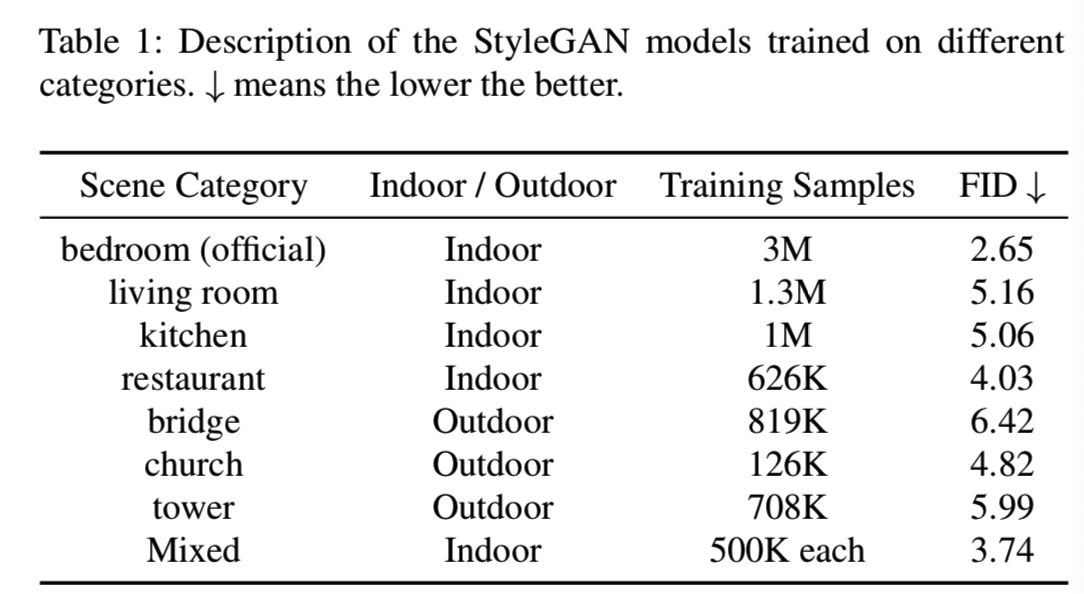
Scene categories. 在上述生成器模型中,PGGAN和StyleGAN实际上是在LSUN数据集[38]上训练的,而BigGAN是在Places数据集[42]上训练的。LSUN数据集包含7个室内场景类别和3个室外场景类别,Places数据集包含1000万幅图像,涉及434个类别。对于PGGAN模型,我们使用官方发布的模型,每个模型都经过训练在LSUN数据集的特定类别中合成场景。对于StyleGAN,只发布了一个与场景合成(即卧室)相关的模型。为了进行更深入的分析,我们使用官方实现来训练其他场景类别的一些附加模型,包括室内场景(客厅、厨房、餐厅)和室外场景(桥、教堂、塔)。我们还训练了一个混合模型,将卧室、客厅、餐厅的图像组合在一起,使用同样的实现设置。该模型专门用于分类分析。表1每个StyleGAN模型表明,类别,训练样本的数量,以及相应的Fre ́chet inception distances(FID)[12],其在某种程度上可以反映出合成质量。对于BigGAN,我们使用作者官方非官方的PyTorch BigGAN实现,以类别标签为约束,在Places数据集[42]上训练一个条件生成模型。以上所有模型合成的场景图像分辨率为256×256。
Semantic Classifiers. 为了从合成图像中提取语义,我们使用一些现成的图像分类器从多个抽象层次,包括布局、类别、场景属性和配色方案,为这些图像分配语义分数。具体来说,我们使用了(1)布局估计器[40],它可以预测一个室内空间结构;(2)场景分类器[42],它可以将一个场景图像分类到365个类别;(3)属性预测器[42],它可以预测SUN属性数据库[26]中的102个预定义场景属性。通过场景图像在HSV空间中的色调直方图提取场景图像的配色方案。其中,类别分类器和属性预测器可以直接输出一幅图像属于某一类别的概率或一幅图像具有某一特定属性的概率。布局估计器只检测室内场所的轮廓结构,如图7中的绿线所示。
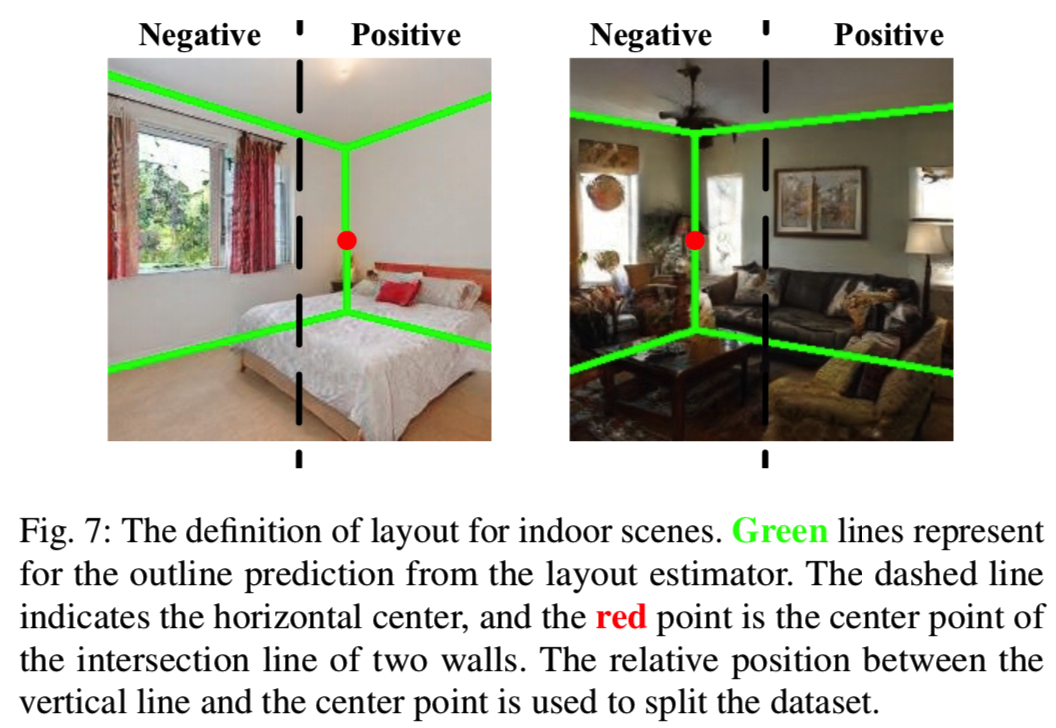
Semantic Probing and Verification. 给出一个训练有素的GAN模型进行分析,我们首先通过随机采样N个潜在编码生成一组合成的场景图像。为了确保捕捉到所有潜在的变化因素,我们设N = 500,000。然后,我们使用上述图像分类器为每个视觉概念分配语义分数。值得注意的是,我们使用图像水平中心与两面墙相交线的相对位置来量化布局,如图7所示。之后,对于每一个候选样本,我们选择响应最高的2000张作为正样本,响应最低的2000张作为负样本。图6是一些例子,其中客厅和卧室分别被作为积极和消极的场景类别。然后,我们训练一个线性支持向量机,将其作为一个双分类问题(即数据是采样的潜在编码,标签是表示目标语义是否出现在相应的合成中)来得到一个线性的决策边界。最后,我们重新生成K = 1000个样本进行语义验证,如4.2节所述。

5.2 Emerging Semantic Hierarchy
人们通常用语义层次来解释场景,从其布局、底层对象到详细的属性和颜色方案。这里指明的对象指的是与特定类别最相关的一组对象。这部分显示GAN和人类感知一样以类似的方式在图层上组成一个场景。为了对布局和对象进行分析,我们以在室内场景上训练的混合StyleGAN模型作为目标模型。StyleGAN[17]在常规潜在空间![]() 的顶部学习了一个更解纠缠的潜在空间W,并通过不同的转换将潜在编码w∈W输入到每个卷积层,而不是只将其输入到第一层。具体来说,就是对于
的顶部学习了一个更解纠缠的潜在空间W,并通过不同的转换将潜在编码w∈W输入到每个卷积层,而不是只将其输入到第一层。具体来说,就是对于![]() 层,w线性转换成分层转换潜在编码
层,w线性转换成分层转换潜在编码![]() ,即
,即![]() ,其中
,其中![]() 分别是用于风格转换的权重和偏差。因此,我们通过学习等式1中的
分别是用于风格转换的权重和偏差。因此,我们通过学习等式1中的![]() 而不是z来实现分层分析
而不是z来实现分层分析
为了量化每一层相对于每一个变化因素的重要性,我们使用重评分技术来识别分层生成表征![]() 和语义出现之间的因果关系。在图10顶部的规范化得分表明,在GAN中的生成器的层以分层的方式去专门组成语义:即底层确定布局,下层和上层分别控制类别级和属性级的变化,颜色方案主要是呈现在顶部。这与人类的感知是一致的(即先考虑大的布局,然后再考虑细节的内容)。在StyleGAN模型中,经过训练生成256×256的场景图像,总共有14个卷积层。根据我们的实验结果,布局、对象(类别)、属性、配色方案分别对应于最底层、下层、上层和顶层,即[0,2)、[2,6)、[6,12)和[12,14)层。
和语义出现之间的因果关系。在图10顶部的规范化得分表明,在GAN中的生成器的层以分层的方式去专门组成语义:即底层确定布局,下层和上层分别控制类别级和属性级的变化,颜色方案主要是呈现在顶部。这与人类的感知是一致的(即先考虑大的布局,然后再考虑细节的内容)。在StyleGAN模型中,经过训练生成256×256的场景图像,总共有14个卷积层。根据我们的实验结果,布局、对象(类别)、属性、配色方案分别对应于最底层、下层、上层和顶层,即[0,2)、[2,6)、[6,12)和[12,14)层。
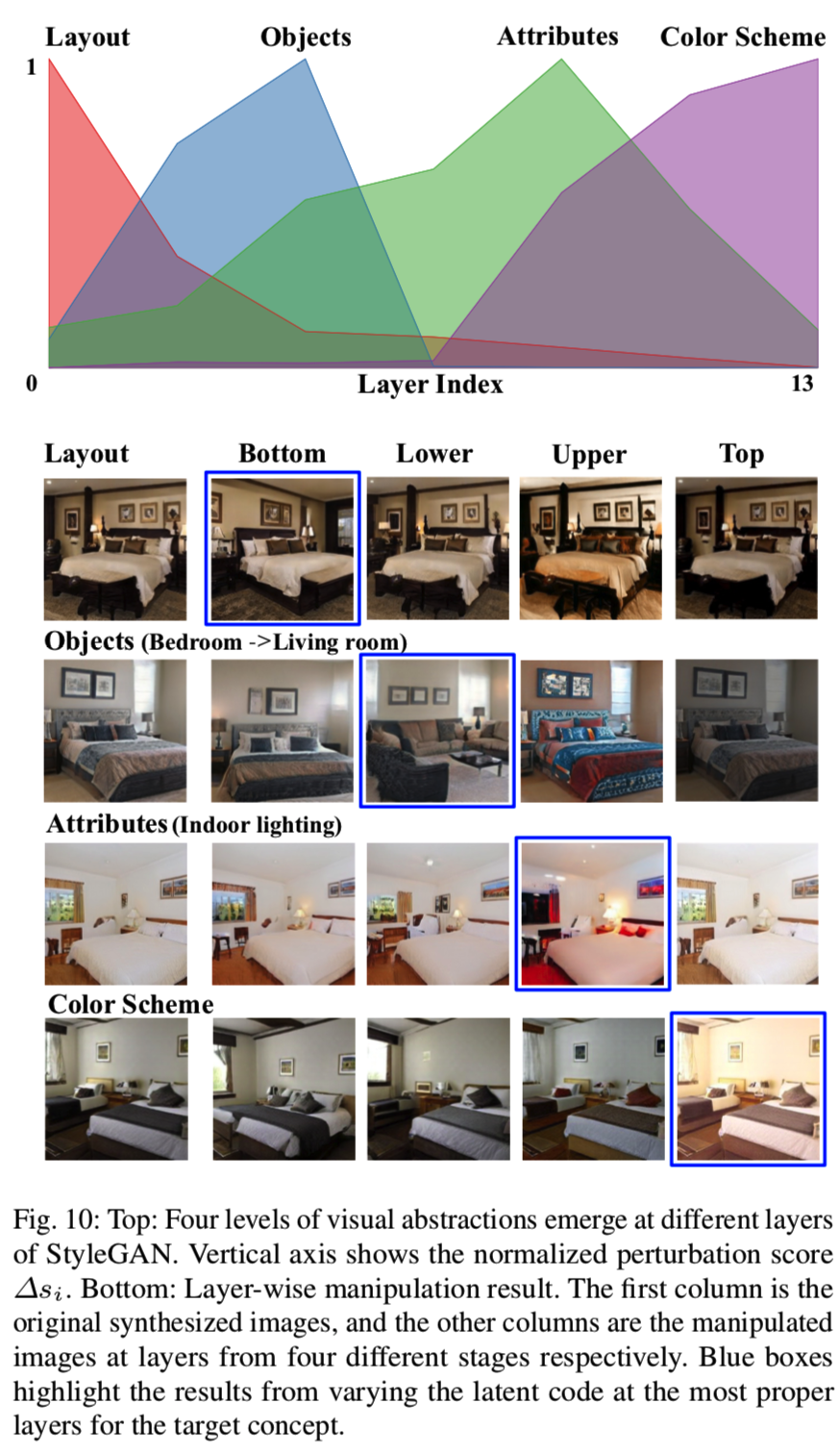
为了直观地检查已识别的变化因素,我们沿着不同层的边界移动潜在向量,以显示合成如何相应地变化。例如,给定一个关于房间布局的边界,我们分别在底层、下层、上层和顶层按法向量方向改变潜在代码。图10底部为几个概念的定性结果。我们看到,出现的变化因素遵循高度结构化的语义层次,例如,布局在早期可以得到最好的控制,而配色方案只能在最后阶段进行改变。此外,在不适当的图层上改变潜码也会改变图像内容,但这种改变可能与期望的输出不一致。例如,在第二行中,为category调整底层的代码只会导致场景视点的随机变化。
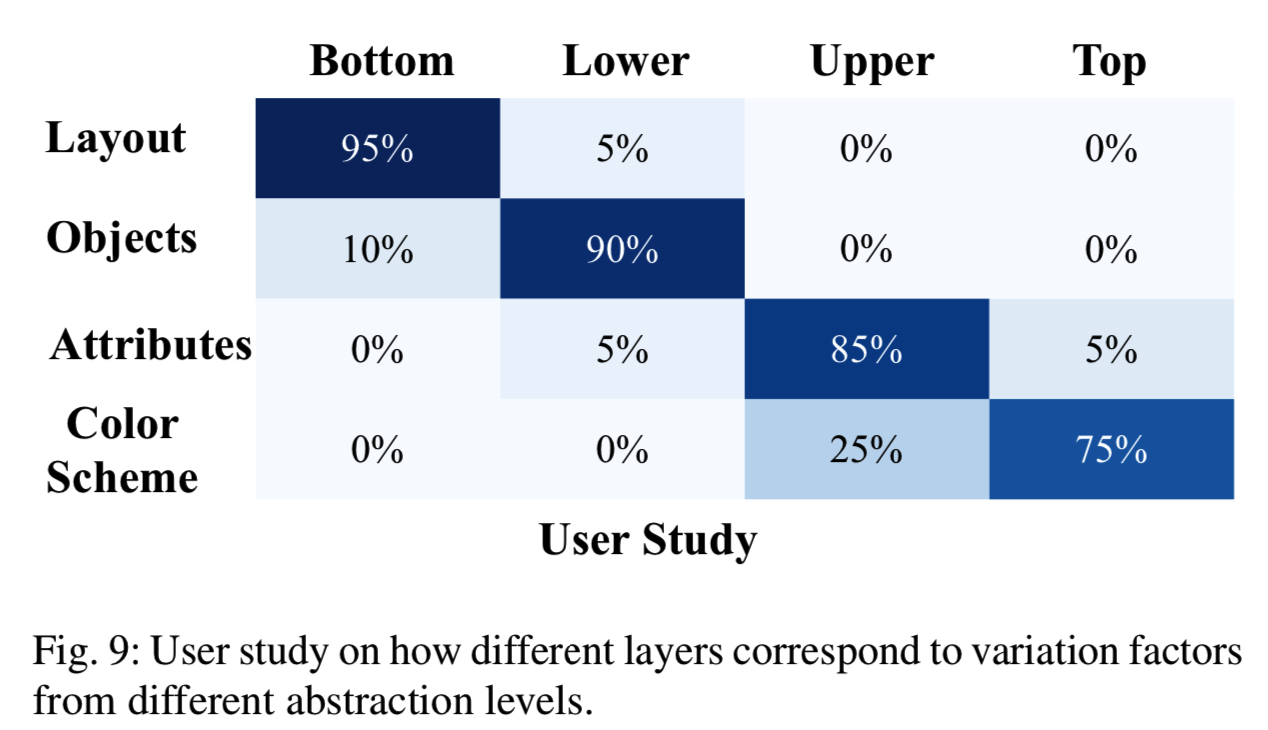
为了更好地评估跨层的可操作性,我们进行了用户研究。我们首先生成500个样本,并根据不同层次上的几个概念对它们进行操作。对于每个概念,20个用户被要求选择最合适的层进行操作。图9显示了用户研究的结果,大多数人认为底层最符合布局,下层控制场景类别等。这与我们在图10中的观察结果一致。该结果说明了在场景合成的生成表征中出现层次变化因素。我们的重新评分方法确实有助于从广泛的语义集合中识别变量因素。
识别语义层次和跨层的变化因素有助于语义场景操作。我们可以简单地将隐藏的代码推向适当层中所需属性的边界。从图8(a)可以看出,我们可以分别改变装饰风格(粗糙到光滑),家具材质(布到木),甚至清洁(整洁到凌乱)。此外,我们可以共同操纵层级变化因素。在图8(b)中,我们同时在底层改变房间布局(旋转视点),在中间层改变场景类别(将卧室转换为客厅),在随后的层改变场景属性(增加室内照明)。

5.3 What Makes a Scene?
如上所述,用于场景合成的GAN模型能够在生成表示中对层次语义进行编码,即从布局、对象(类别)到场景属性和配色方案。GAN最显著的特性之一是它的中间层实际上针对不同的场景类别合成了不同的对象。这就提出了一个问题:是什么让一个场景成为客厅而不是卧室?因此,我们进一步深入GANs中分类信息的编码,以量化GAN如何解释场景类别,以及场景类别如何从物体视角转换。
我们采用以卧室、客厅和餐厅为对象的StyleGAN模型,然后在每两个类别之间寻找语义边界。为了从合成图像中提取目标,我们采用了语义分割模型[35],它可以分割出150个目标(电视、沙发等)和物体(天花板、地板等)。具体来说,我们首先随机合成500幅客厅图像,然后依次按照“客厅-卧室”边界和“卧室-餐厅”边界改变相应的潜码。我们对操作前后的图像进行分割,得到分割掩模,如图11所示。在操作过程中通过图像坐标跟踪每个像素的标签映射后,我们就可以计算出物体随类别变化的变化统计量,观察类别变化时物体的变化情况。
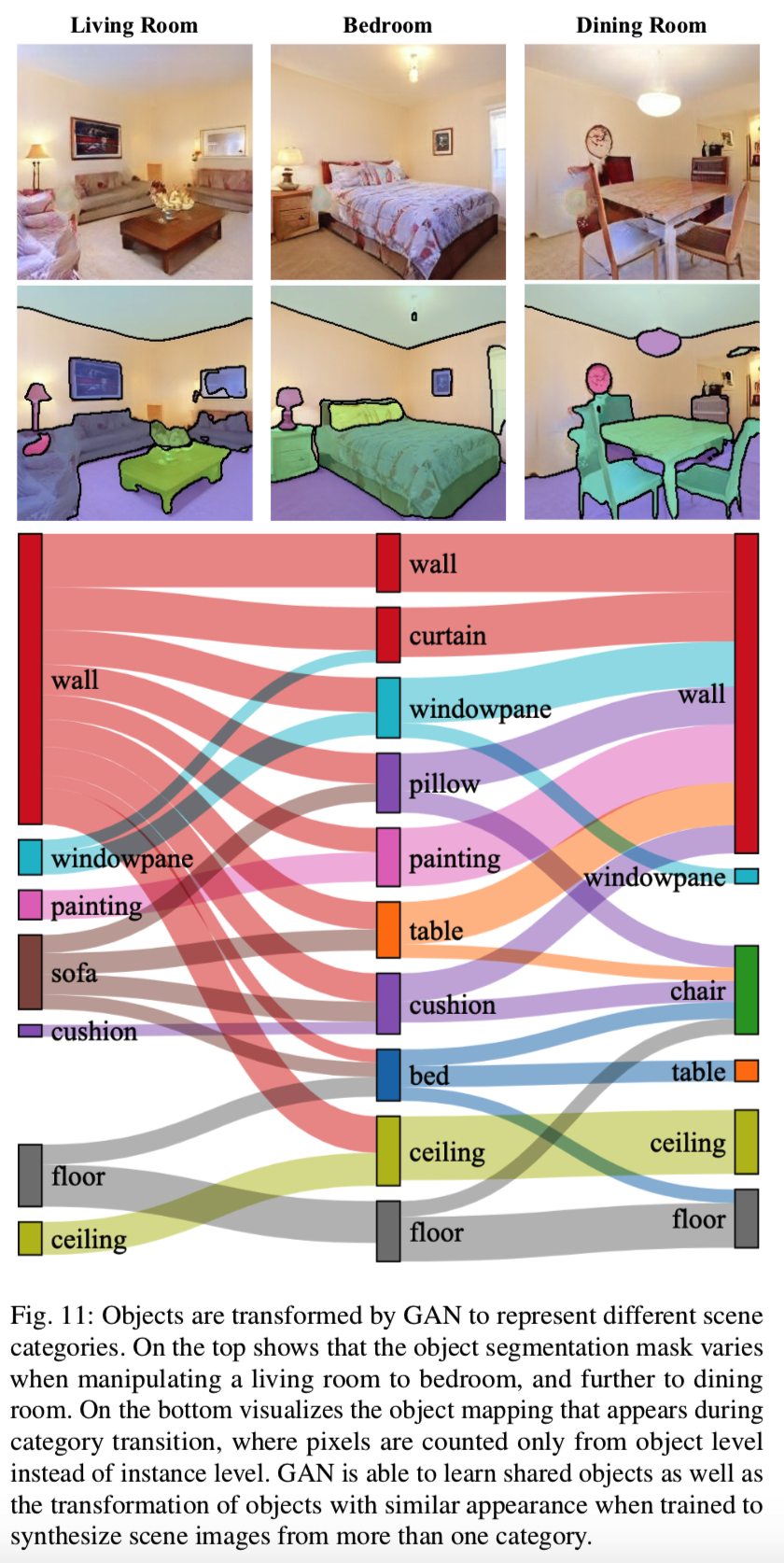
图11显示了类别转换过程中的对象映射。我们可以看到(1)当在不同类别之间操作图像时,大多数stuff类(例如天花板和地板)保持不变,但有些对象被映射到其他类中。例如客厅的沙发映射到卧室的枕头和床上,卧室的床进一步映射到餐厅的桌子和椅子上。之所以会出现这种现象,是因为沙发、床、餐桌和椅子分别是客厅、卧室和餐厅可区分的物品。因此,当类别发生变化时,代表对象也应该发生变化。(2)一些对象是可以在不同场景类别之间共享的,GAN模型能够发现这些属性并学会在不同的类之间生成这些共享对象。例如,客厅(图像左侧边界)的灯在图像转换为卧室后仍然保留,特别是保留在相同的位置。(3)通过学习对象映射以及跨不同类共享对象的能力,我们能够将无条件的GAN转换为能够控制类别的GAN。通常,为了让GAN从不同类别生成图像,必须将类标签输入生成器以学习分类嵌入,比如BigGAN[6]。我们的结果提出了另一种方法。
5.4 Diverse Attribute Manipulation
Attribute Identification. 场景合成中变化因素的出现取决于训练数据。在这里,我们将我们的方法应用到一个StyleGAN模型集合中,以捕获在SUN属性数据库[26]中预定义的102个场景属性中的广泛可操作属性。每个styleGAN都受过训练,可以合成特定类别的场景图像,包括室外场景(桥、教堂、塔)和室内场景(客厅、厨房)。图12显示了每个模型的前10个相关语义。我们可以看到,“sunny”在所有户外类别中得分较高,而“lighting”在所有室内类别中得分较高。此外,“boating”被定义为桥梁模型,“touring”被定义为教堂和塔,“reading”被定义为客厅,“eating”被定义为厨房,“socializing”被定义为餐厅。这些结果与人的感知高度一致,表明了所提出的量化方法的有效性。
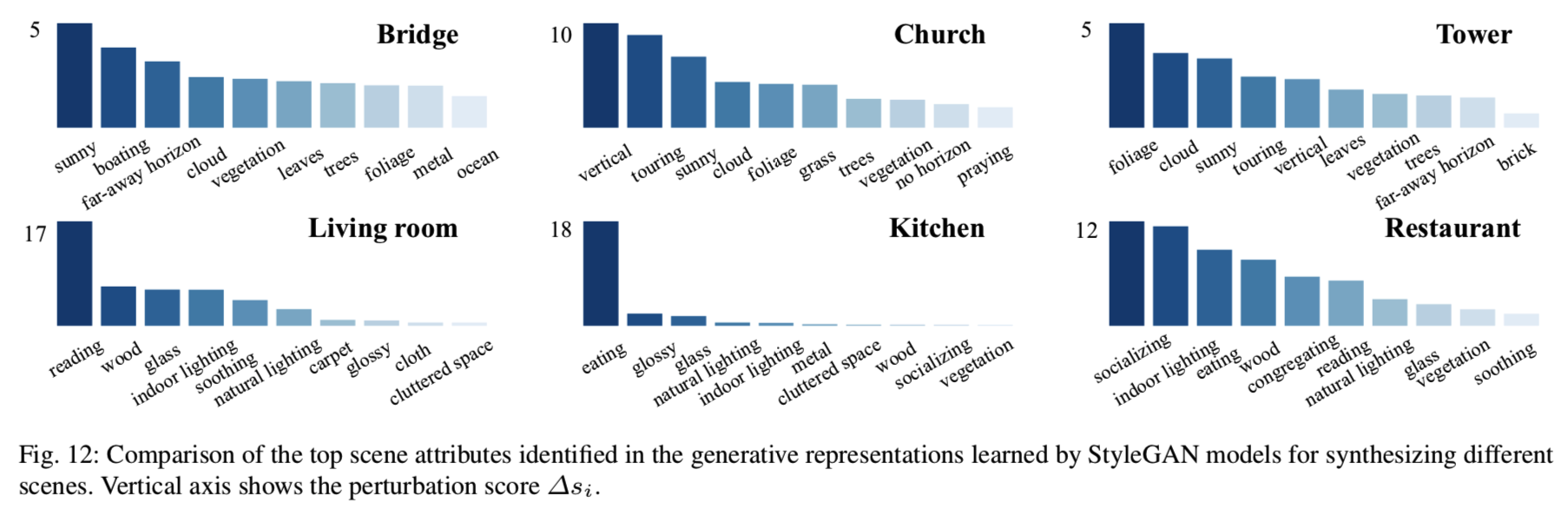
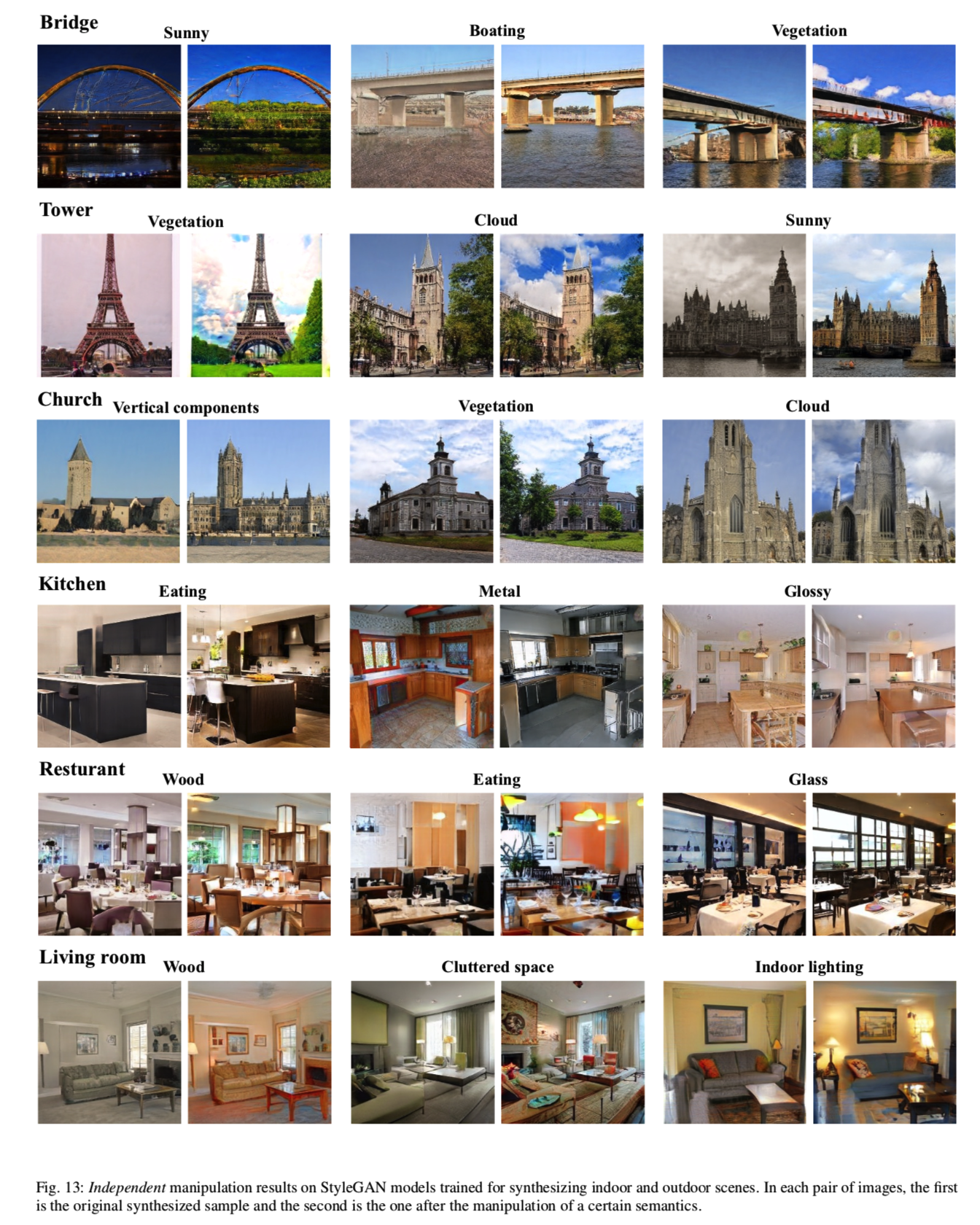
Attribute Manipulation. 回顾第4.3节中的三种手法:Independent手法、Joint手法和Jittering手法。我们首先用我们的方法识别出的最相关的场景属性对3个室内和3个室外场景进行独立操作。图13显示了原始合成(每对图中左侧图像)沿正(右)方向进行操作的结果。我们可以看出,编辑过的图像仍然是高质量的,而且目标属性确实按照需要发生了变化。然后,我们使用图14所示的桥梁合成模型联合操作两个属性。3×3图像网格的中心图像为原始合成,第二行和第二列分别为对“vegetation”和“cloud”属性的独立操作结果,四角上的其他图像为联合操作结果。结果表明,我们很好地控制了这两种语义,它们似乎几乎没有相互影响。然而,并不是所有的变化因素都表现出如此强烈的分离。从这个角度来看,我们的方法也提供了一个新的度量来帮助测量两个变化因素之间的纠缠,这将在第6节中讨论。最后,我们通过在“cloud”操纵中引入噪声来评估提出的Jittering操纵。从图15中,我们观察到新引入的噪声确实增加了操作的多样性。有趣的是,引入的随机性不仅会影响添加的云的形状,还会改变合成塔的外观。但这两种情况都保留了主要目标,即编辑云的程度。

5.5 Ablation Studies
Re-scoring Technique. 在执行所提出的重评分技术之前,我们还有两个步骤:(1)为综合样本分配语义评分,(2)训练SVM分类器搜索语义边界。我们想验证重新评分技术在识别可操作语义方面的重要性。我们对用于合成卧室的StyleGAN模型进行了消融研究。如图16所示,左图根据标记为正样本的样本数量对场景属性进行排序,中间图根据经过训练的SVM分类器的准确率进行排序,右图根据我们提出的量化度量进行排序。
在左图中,“no-horizon”、“man-made”和“enclosed area”是百分比最高的属性。然而,所有这三个属性都是卧室的默认属性,因此不可操纵。相反,通过验证的重评分技术,我们的方法成功地过滤掉了这些不变的候选词,并揭示了更有意义的语义,如“wood”和“indoor lighting”。此外,我们的方法还设法识别一些不太常见但实际可操作的场景属性,如“cluttered space(杂乱空间)”。
在中间的图中,几乎所有的属性都得到相似的分数,使得它们无法区分。实际上,即使最差的SVM分类器(即“railroad”)也能达到72.3%的准确率。这是因为即使一些变化因素没有被编码到潜在表示中(或者说,不能操纵),相应的属性分类器仍然会给合成图像赋不同的分数。在这些不准确的数据上训练SVM也会产生一个分离边界,即使它不被期望作为目标概念。因此,仅依靠SVM分类器不足以检测出相关的变化因素。相比之下,我们的方法更注重改变潜码后的分数调节,而不受属性分类器的初始响应和支持向量机性能的影响。因此,我们能够彻底而精确地从一个广泛的候选集检测潜在空间的变化因素。

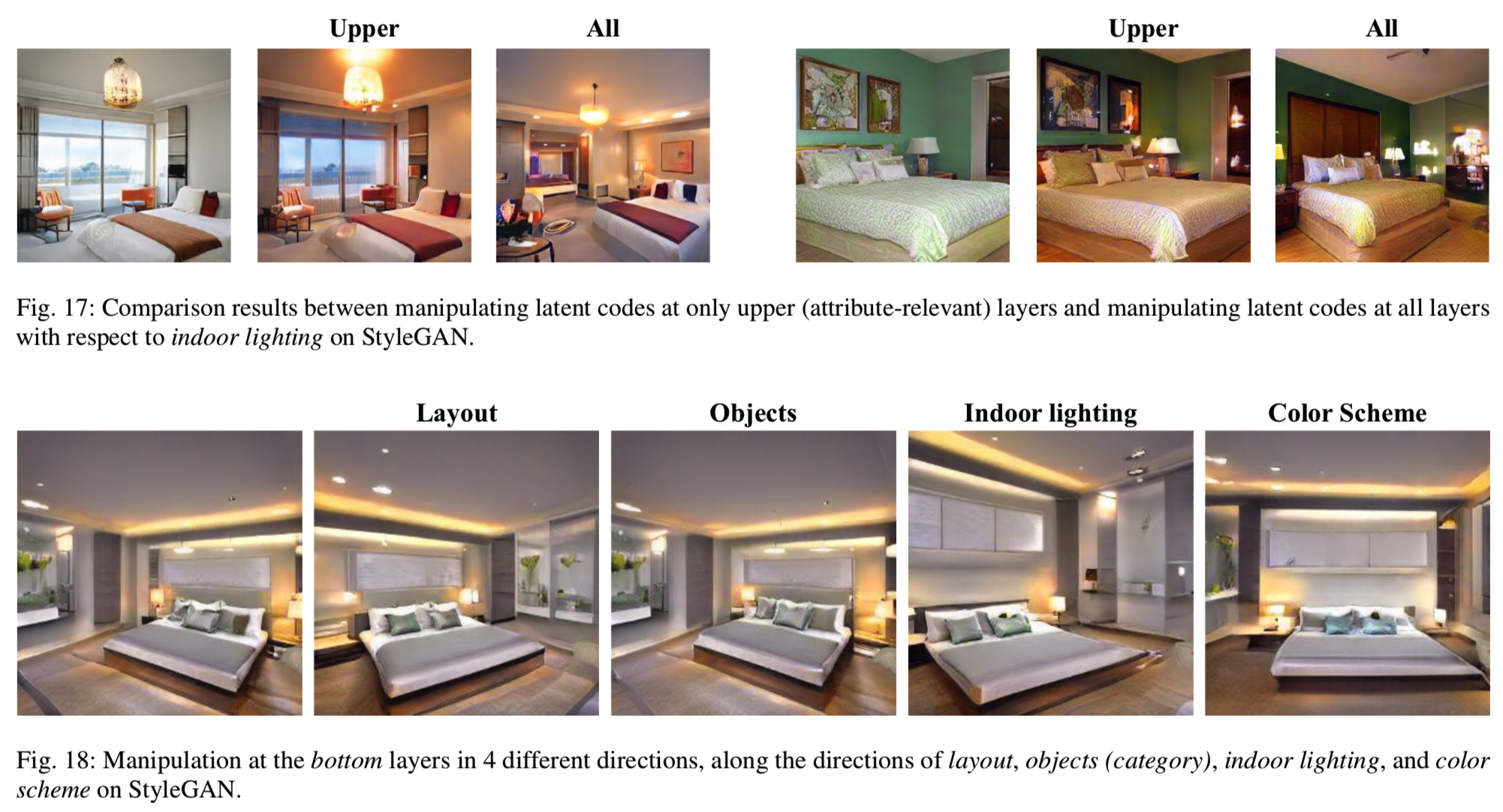
Layer-wise Manipulation. 为了进一步验证语义层次的出现,我们利用StyleGAN模型对分层操作进行了消融研究。首先,我们选择“indoor lighting”作为目标语义,只在上层(属性相关) v.s 所有层上改变潜在代码。从图17中我们可以很容易的看出,在对各个图层进行“indoor lighting”的操作时,室内的物体也发生了变化。相比之下,仅在属性相关的图层上操纵隐藏的代码可以在不影响其他因素的情况下令人满意地增加室内照明。其次,我们选择底层作为目标层,并从所有四个抽象层中选择边界进行操作。如图18所示,无论我们选择什么层次的语义,只要在底层(与布局相关的)层修改潜在代码,只改变布局而不改变其他语义。这两个实验进一步验证了我们关于语义层次出现的发现,即早期的层次往往决定空间布局和配置,而不是其他抽象层次语义。
6 Discussions
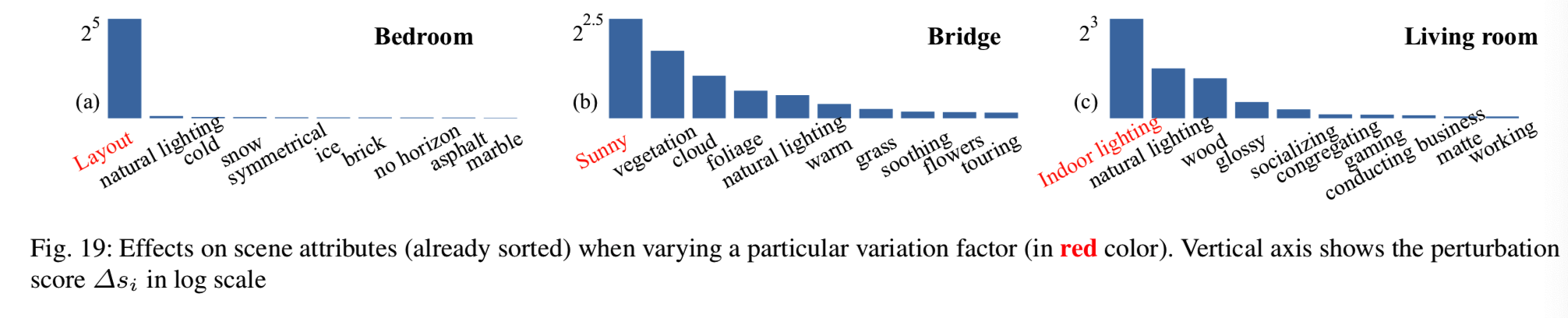
Disentanglement of Semantics. 我们在生成表征中检测到的一些变化因素比其他语义更加解耦。与Karras等人[17]中描述的感知路径长度和线性可分性以及Shen等人[30]中提出的余弦相似度相比,我们的工作为解耦分析提供了一个新的度量。特别是,我们沿着一个语义方向移动潜在代码,然后检查其他因素的语义分数如何相应变化。如图19(a)所示,当我们修改空间布局时,所有场景属性几乎没有受到影响,说明GAN学会了将布局级语义与属性级语义分离。然而,也有一些场景属性(来自相同的抽象级别)相互纠缠。以图19(c)为例,在调制“indoor lighting”时,“natural lighting”也会发生变化。这也符合人类的感知,进一步证明了我们提出的量化度量的有效性。
Application to Other GANs. 我们进一步将我们的方法应用于另外两个GAN结构,即PGGAN[16]和BigGAN[6]。这两个模型分别在LSUN数据集[38]和Places数据集[42]上进行训练。与StyleGAN相比,PGGAN只向第一个卷积层提供潜在向量,因此不支持分层分析。但所提出的重新评分方法仍可用于帮助识别可操作语义,如图20(a)所示。BigGAN是最先进的条件GAN模型,它在将潜在向量输入生成器之前,将其与类引导的嵌入代码连接起来,而且它还允许像StyleGAN那样的分层分析。图20(b)给出了属性层对BigGAN的分析结果,从图中可以看出,场景属性在上层修改的效果比在低层或所有层中修改效果好。分辨率为256×256的BigGAN模型,共有12个卷积层。由于类别信息已经编码在“class”代码中,我们只将层分为两组,即较低(底部6层)和较高(顶部6层)。与此同时,定量曲线显示出与StyleGAN发现结果一致的结果,如图10(a)所示。这些结果证明了我们的方法的泛化能力,以及在其他GANs中可操纵因素的出现。

Limitation. 对于未来的改进有几个限制。首先,布局分类器只能检测到室内场景的布局结构。但是当用于室内外场景类别的一般化分析时,其缺乏对空间布局的统一定义。例如,我们的框架不能改变室外教堂图像的布局。在未来的工作中,我们将利用计算摄影工具来恢复图像的三维相机姿态,从而为合成图像提取更通用的视点表示。其次,我们提出的重新评分技术依赖于现有分类器的性能。对于某些属性,分类器并不那么精确,导致操作边界不佳。这个问题可以用更强大的判别模型来解决。第三,为了简单起见,我们只使用线性支持向量机进行语义边界搜索。这就限制了我们对具有复杂非线性结构的潜在语义子空间的解释。
7 Conclusion
在本文中,我们展示了高度结构化变化因素在具有分层随机性的GANs学会的深层生成表征中出现。特别是GAN模型在训练场景合成时,会自发地学习在早期层中设置布局,在中间层生成分类对象,在后期层中渲染场景属性和配色方案。提出了一种重新评分的方法来定量地识别一个训练有素的模型中的可操作语义概念,从而实现逼真的场景操作。在未来的工作中,我们将探索如何扩展GANs的这种操作能力,以用于真实的图像编辑。