2020
Towards Universal Representation Learning for Deep Face Recognition
Abstract
识别自然环境下的人脸是非常困难的,因为它们会出现各种各样的变化。传统的方法要么使用来自目标域的特定标注的变化数据进行训练,要么通过引入未标记的目标变化数据来适应训练数据。相反,我们提出了一个通用的表示学习框架,它可以处理给定训练数据中看不到的更大的变化,而不需要利用目标领域的知识。我们首先将训练数据和一些语义上有意义的变化综合在一起,如低分辨率、遮挡和头姿势。然而,直接输入扩充后的训练数据并不会让网络很好地收敛,因为新引入的样本大多是困难样本。我们建议将嵌入的特征分解成多个子嵌入,并将每个子嵌入与不同置信值关联起来,使训练过程更加平滑。通过将变化分类损失和变化对抗损失在不同的分区上正则化,来进一步去相关子嵌入。实验表明,该方法在LFW和MegaFace等一般人脸识别数据集上取得了较好的性能,在TinyFace和IJB-S等极端基准上取得了较好的性能。
1. Introduction
深度人脸识别试图将输入图像映射到具有较小的身份内距离和较大的身份间距离的特征空间,之前的工作通过损失设计和具有丰富的类内变化的数据集实现了这一目标[29,40,17,38,4]。然而,即使是非常大的公共数据集,如MS-Celeb-1M,也表现出强烈的偏向,如种族[33]或头部姿势[20,24](即数据集的人脸数据可能更多是白种人,头更多是正面这种)。这种多样性的缺乏导致了在具有挑战性的测试数据集上性能显著地下降,例如,在IJB-S或TinyFace上先前的最先进的[31]报告的准确率[11,3]在比IJB-A[14]或LFW[10]上的准确率低30%左右。
最近的研究试图通过识别相关的变化因素并通过领域适应方法[33]来扩展数据集来缓解这一问题。有时,这样的变化很难识别,因此使用域适应方法来校准训练域和测试域[28]之间的特征。或者,单个模型可以在不同的数据集和集成上进行训练,从而在每个[19]上获得良好的性能。所有这些方法要么只处理特定的变化,要么需要访问测试数据分布,要么增加额外的运行时复杂性来处理更广泛的变化。相比之下,我们建议学习一个单一的“通用”深层特征表示,它可以处理人脸识别中的变化,而不需要访问测试数据分布,并保持运行时效率,同时在各种情况下实现强大的性能,特别是在低质量的图像上(参见图1):
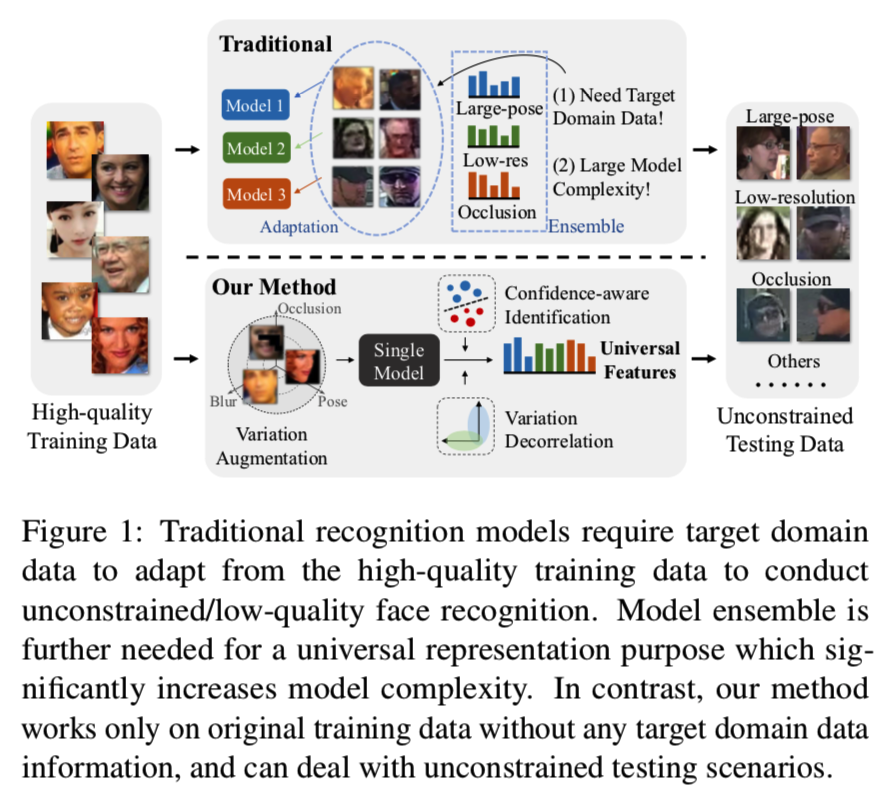
本文在第三节中介绍了几种新的贡献来学习这个普遍表示方法。首先,我们注意到,具有非正面姿态、低分辨率和重遮挡的输入是对“自然环境”应用程序提出挑战的关键可命名因素,对于这些应用程序,可以对训练数据进行综合增强。但是直接在训练中添加困难增强样本会导致一个更困难的优化问题。我们通过提出一种识别损失来缓解这种情况,这种识别损失包括每个样本的置信度来学习概率特征嵌入。其次,我们试图通过将嵌入分解为子嵌入来最大化嵌入的表示能力,每个子嵌入在训练过程中都有一个独立的置信度值。第三,鼓励所有的子嵌入通过对不同分区的两个相反的正则化来进一步去相关,即变化分类损失和变化对抗损失。第四,我们通过挖掘训练数据中的其他变化来进一步扩展去相关正则化,对于这些变化,合成增强不是微不足道的。最后,我们通过一个概率聚合来解释不同因素的不确定性,从而解释子嵌入的不同判别能力。
在第5节中,我们对公共数据集上提出的方法进行了广泛的评估。与我们的基线模型相比,该方法在LFW和YTF等一般人脸识别基准上保持了较高的准确性,同时显著提高了IJB-C、IJB-S等具有挑战性的数据集的性能,实现了新的最先进的性能。详细的ablation研究显示了上述各方面的贡献对获得这些优异性能的影响。
综上所述,本文的主要贡献有:
- 一个人脸表示学习框架,通过将通用特征与不同的变化联系起来来学习通用特征,从而改进了对不同测试数据集的泛化。
- 一个置信度感知的识别损失,在训练中利用样本置信度从困难样本中学习特征。
- 一种特征去相关正则化,它将变化分类损失和变化对抗损失应用于子嵌入的不同分区,从而提高了性能。
- 一种训练策略,有效地结合合成的数据,训练出适用于原始训练分布之外的图像的人脸表示。
- 在IJB-A、IJB-C、TinyFace和IJB-S等几个具有挑战性的基准测试中,获得了最先进的结果。
2. Related Work
Deep Face Recognition: 深度神经网络被广泛应用于正在进行的人脸识别研究中[35,34,29,20,17,8,25,37,4]。Taigman等人提出了第一个用于人脸识别的深度卷积神经网络。接下来的工作是探索不同的损失函数来提高特征表示的分辨能力。Wen等人提出了center损失来减少类内差异。已有一系列研究提出使用度量学习方法进行人脸识别[29,32]。最近的工作试图用一个单一的识别损失函数实现有区别的嵌入,其中使用proxy/prototype向量来表示嵌入空间中的每个类[17,37,38,25,4]。
Universal Representation: 通用表示是指可以应用于不同视觉域(通常是不同的任务)的单个模型,例如对象、字符、路标,同时保持使用一组特定于域的模型的性能[1,26,27,39]。通过这样一个单一模型学习到的特性被认为比领域特定的模型更通用。与领域泛化[13,22,15,16,36]不同的是,领域泛化的目标是通过学习不同的领域来适应不可见的领域,而通用表示不涉及对不可见领域的再训练。这些方法大多侧重于通过使用诸如条件化的BatchNorm[1]和residual适配器等技术来减少域转移,从而提高参数效率[26,27]。Wang等人在SE模块[9]的基础上,提出了一种面向通用对象检测网络中间(隐藏)特征的领域关注模块。我们的工作与这些方法在两个方面不同:(1)它是一种用于相似度度量学习的方法,而不是用于检测或分类任务;(2)它是与模型无关的。通过计算不可见类样本之间的两两相似度,我们的模型所获得的特征可以直接应用于不同的领域。
3. Proposed Approach
在本节中,我们首先介绍三种可扩展的变化,即模糊,遮挡和头部姿势,以增加训练数据。增强数据的可视化示例如图2所示,详细信息可以在第4节中找到:

然后在3.1节中,我们引入了一个置信度感知的识别损失来学习困难的样本,在3.2节中,我们通过将特征向量分割成具有独立置信度的子嵌入来进一步扩展。在3.3节中,我们将应用介绍的可扩展的变化来进一步去关联特性嵌入。提出了一种不可扩展的变化发现方法来探索更多的变化以获得更好的去相关。最后,提出了一种不确定性引导的两两度量方法进行推理。
3.1. Confidence-aware Identification Loss
我们研究了给定输入样本xi被分类给身份j∈{1,2,…, N}(即N个类)的后验概率。表示样本i的特征嵌入为fi,第j个身份原型向量为wj,即身份模板特征。概率嵌入网络θ在特征空间中将每个示例xi表示为高斯分布N (fi,σi2I)。xi为第j类样本的概率为:
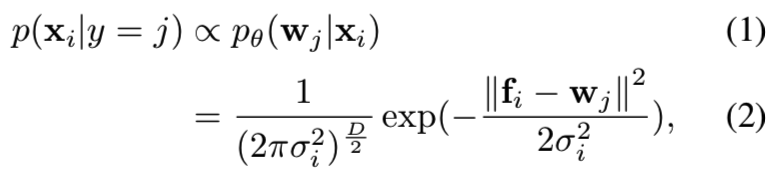
其中D为特征维数。进一步假设分配样本到任意身份(即类)的先验相等,则属于第j类的xi的后验可得:
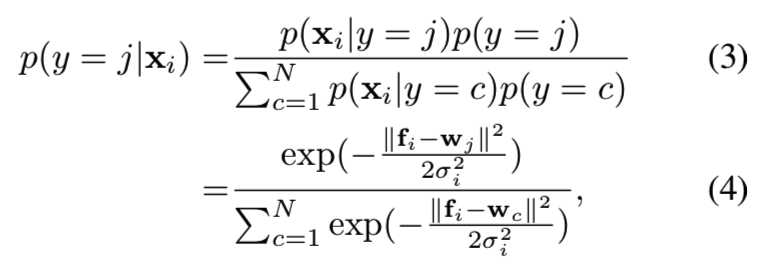
为了简化,定义置信度值为![]() 。限制fi和wj在L2正则化单位球中,则得到式子
。限制fi和wj在L2正则化单位球中,则得到式子![]() 和:
和:
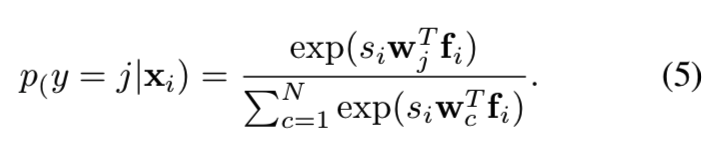
方程5中置信度感知后验的效果如图4所示:
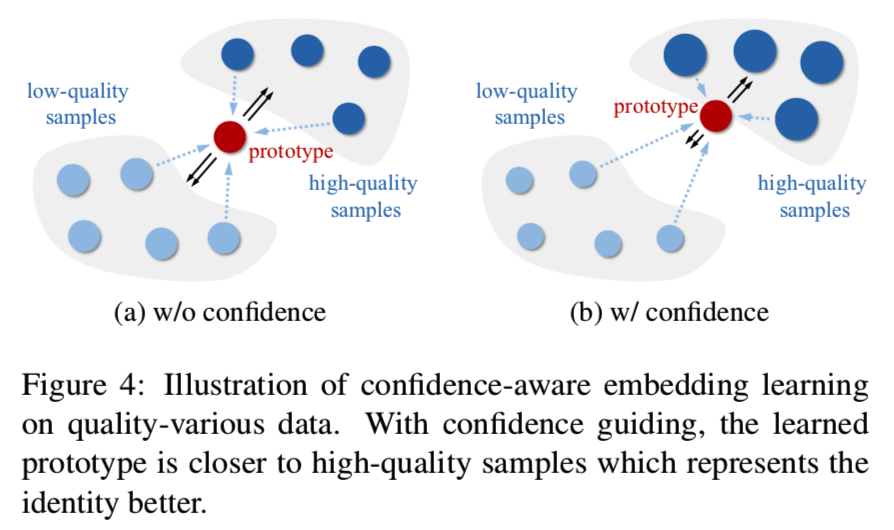
当在不同质量的样本之间进行训练时,如果我们假设所有样本的置信度相同,那么所学习的原型(prototype)将位于所有样本的中心(如图4的a)。这并不理想,因为低质量的样本传达的身份信息更加模糊。相比之下,如果我们建立特定于样本的置信度si,高质量样本有更高的置信度,它推动原型(prototype)wj更接近高质量样本,以最大化后验(如图4的b)。同时,在嵌入fi的更新过程中,更有力的推动了低质量fi更接近原型。
在指数logit上增加损失margin[38]已被证明能有效地缩小类内分布。我们也把它纳入我们的损失:
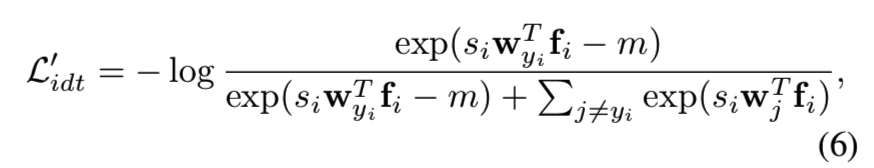
在这里,yi是xi的真实标签。我们的置信度感知识别损失(C-Softmax)与Cosine损失[38]主要的不同如下:(1)每个图像有一个独立的和动态的si,而不是一个常数共享标量s;(2)边距参数m没有乘以si。si的独立性使得它能够以一种特定于样本的方式对网络训练中wj和fi的梯度信号进行门控,因为训练样本的置信度(变化度)可能会有很大的差异。虽然样本是特定的,我们的目标是追求一个同构的特征空间,这样不同身份的度量应该是一致的。因此,允许si补偿样本的置信差,我们期望m在所有身份(即类)中一致地共享。
3.2. Confidence-aware Sub-Embeddings
虽然通过特定于样本的门控si学习的嵌入fi可以处理样本级别的变化,但我们认为fi本身的entries之间的相关性仍然很高。为了最大限度地提高表示能力并实现紧凑的特征大小,需要对嵌入entries进行去相关处理。这鼓励我们进一步将整个嵌入fi分解为分区的子嵌入,每个子嵌入都进一步分配一个标量置信值。
如图3所示:
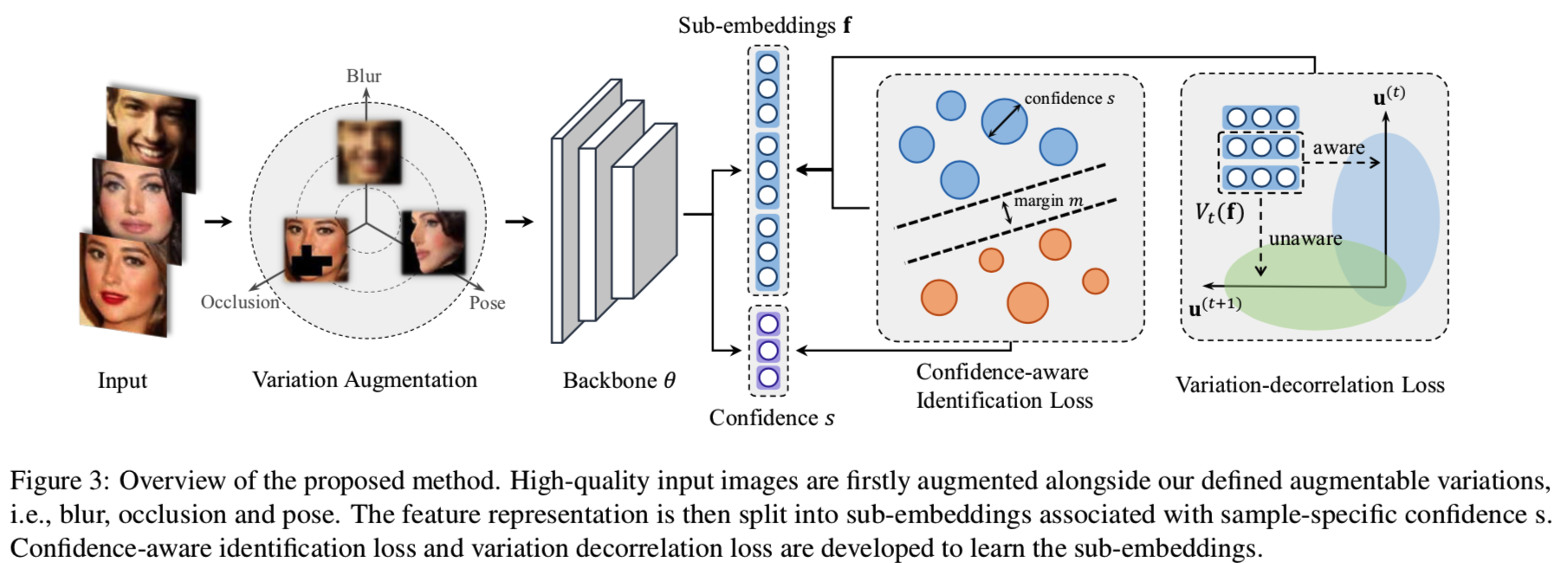
我们将整个特征嵌入fi分割成K个等长子嵌入,如式7所示。据此,将原型向量wj和置信标量si被划分为大小相同的K组:
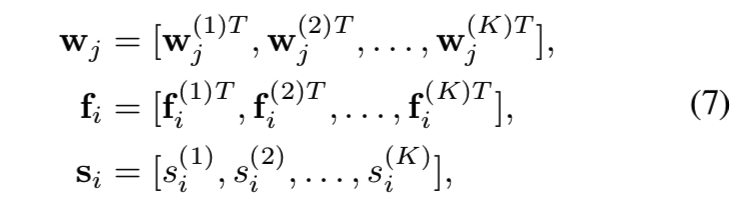
将每组次嵌入fi(k)分别L2归一化到单位球上。因此,最后的判别损失为:
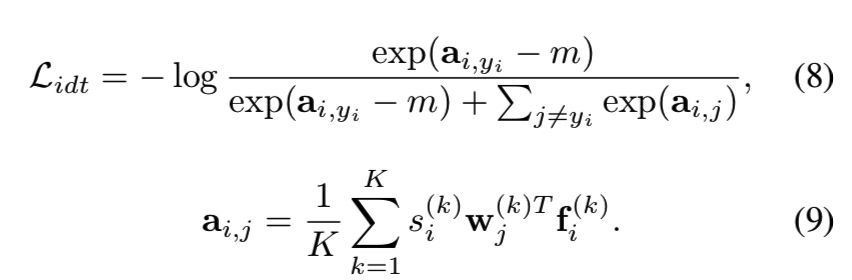
一个在神经网络中常见的问题是他们在预测[6]中都倾向于“过度自信”。我们添加一个附加的正则化来限制置信度任意地过大增长:
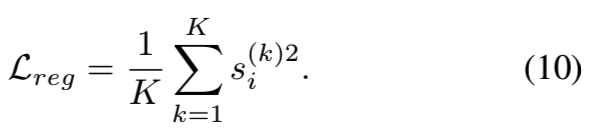
3.3. Sub-Embeddings Decorrelation
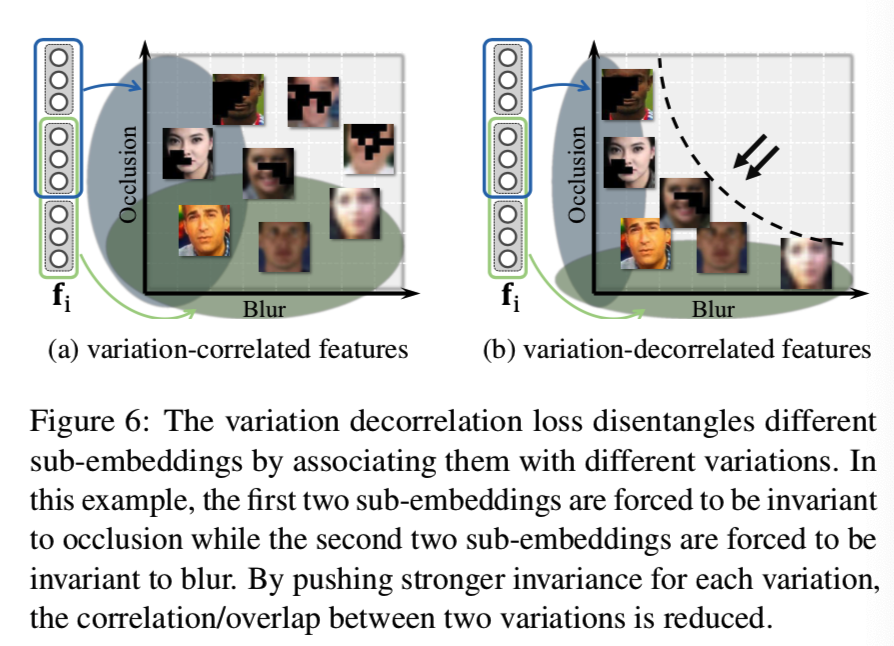
单独设置多个子嵌入并不能保证不同组中的特性是学习互补信息的。可见图5:
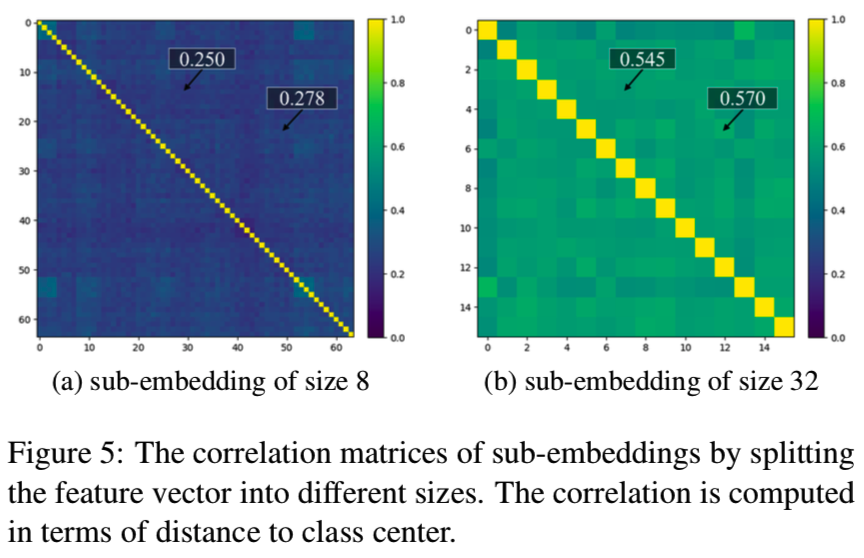
我们发现子嵌入仍然是高度相关的,即, fi分为16组,所有子嵌入的平均相关系数为0.57。如果用不同的正则化方法对子嵌入进行惩罚,可以降低它们之间的相关性。通过将不同的子嵌入与不同的变化联系起来,我们对所有子嵌入的一个子集对于某个变化类型进行变化分类损失,同时对其他变化类型进行变化对抗性损失(这样就能够将该自己与某个变化相互关联起来了)。给定多个变化,这两个正则化项被强制放在不同的子集上,从而得到更好的子嵌入去相关。
对于每个可增强的变化t∈{1,2,…,M},我们生成一个二进制掩码Vt,它从所有子嵌入中选择随机K/2个子集,同时将另一半置为零。masks在训练开始时生成,并在训练期间保持固定。我们保证对于不同的变化,masks是不同的。我们期望Vt(fi)反映第t个变化,而对其他变化是不变的。因此,我们构建了一个多标签二进制判别器C,通过学习来预测每个masked子集的所有变化:
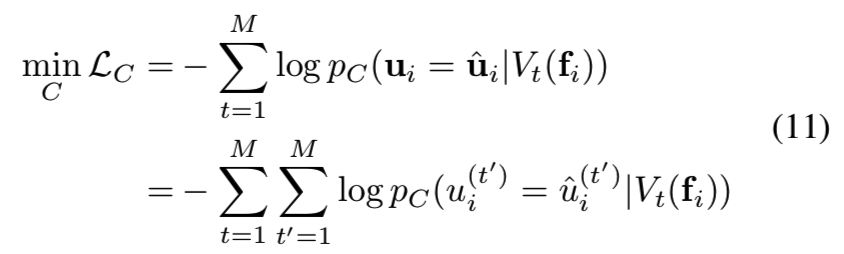
其中ui = [ui(1), ui(2),…, ui(M)]是已知变化的二进制标签(0/1),uiˆ则是真实的标签。例如,如果t = 1对应于分辨率,uiˆ(1)的值在高/低分辨率图像上分别为1和0。等式11仅用于训练判别器c,相应的嵌入网络的分类和对抗性损失为:
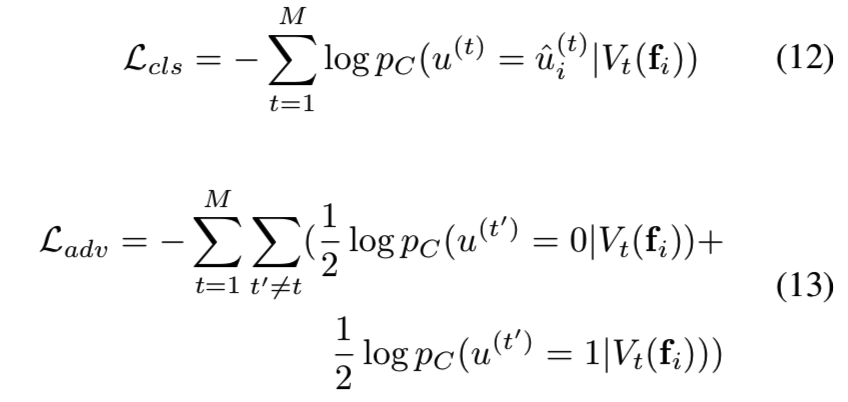
分类损失是一种鼓励Vt与特定变化相关的损失,而Ladv是一种鼓励其他变化不变的对抗性损失。只要没有两个masks相同,就可以保证所选的子集Vt在功能上与其他Vt'不同。因此,我们实现了Vt和Vt'之间的去相关。每个样本的总损失函数为:
![]()
在优化过程中,将等式(14)在mini-batch中取样本的平均值。
3.4. Mining More Variations
由于可扩展变化的数量有限(在我们的方法中为3个,即模糊、分辨率和头姿势),导致去相关效果有限,因为Vt的数量太小。为了进一步增强去相关,并引入更多的变化以获得更好的泛化能力,我们的目标是探索更多的语义变化。请注意,并不是所有的变化都容易进行数据扩充,例如微笑或不微笑是很难扩充的。对于这种变化,我们尝试从原始训练数据中挖掘出变化标签。特别是,我们利用一个现成的属性数据集CelebA[18]训练带有身份对抗损失的属性分类模型θA:
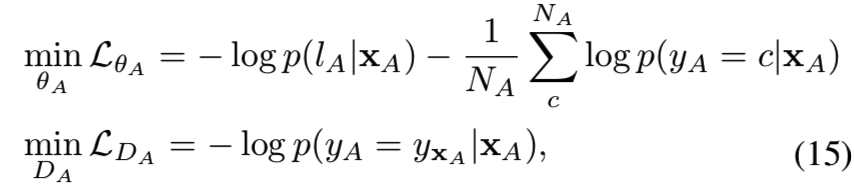
其中lA是属性标签,yA是身份标签。xA为输入的人脸图像,NA为CelebA数据集中的身份数(即多少个不同的人)。第一项惩罚特征对人脸属性进行分类,第二项惩罚特征对身份保持不变性。
然后将上面训练好的属性分类器应用于识别训练集,生成T个新的soft变化标签,如微笑或不微笑、年轻或年老。这些附加的变化二值标签与原始的可扩展变化标签合并为:ui = [ui(1),…,ui(M),ui(M+1),…,ui(M+T)],然后合并到3.3节的去相关学习框架中。
3.5. Uncertainty-Guided Probabilistic Aggregation
考虑用于推理的度量,简单地取学习到的子嵌入的平均值是次优的方法。这是因为不同的子嵌入对不同的变量有不同的识别能力。它们的重要性应该根据给定的图像对而有所不同。受[31]的启发,我们考虑应用与每个嵌入相关的不确定性来为成对的相似度评分:
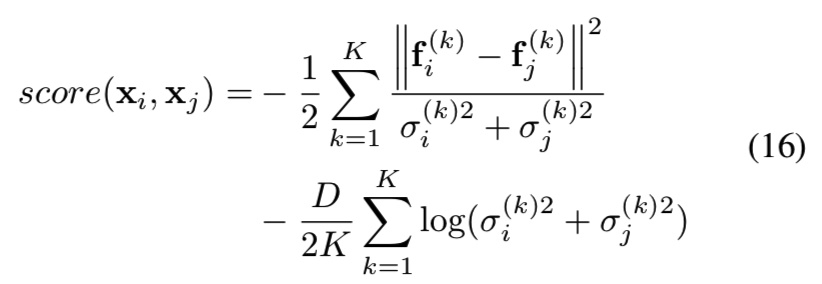
即计算两个输入图像xi和xj的得分来判断他们两是不是同一个人,即求他们两对应的不同变化的子嵌入的差别。
尽管使用等式10实现正则化,我们经验发现从识别损失学习的置信度仍然倾向于过于自信,因此不能直接用于等式16,所以我们微调原来的置信度分支去预测σ,同时修复其他部分。关于微调的训练细节,我们建议读者参考[31]。
4. Implementation Details
Training Details and Baseline. 所有的模型都是用Pytorch v1.1实现的。我们使用ArcFace[4]中MS-Celeb-1M[7]的clean list获得训练数据。在用测试集清理了重叠的被检测者后,我们得到了76.5K类的480万张图像。我们使用[44]中的方法进行人脸对齐,并将所有的图像裁剪成110×110的大小。训练和测试时分别采用随机裁剪和中心裁剪,将图像变换为100×100。我们使用[4]中修改的100层ResNet作为我们的架构。所有模型的嵌入尺寸为512,多嵌入方法将特征分为16组。模型C是一个线性分类器。实验中的基线模型使用CosFace损失函数进行训练[38,37],其在一般的人脸识别任务中取得了最先进的性能。对无域扩展的模型进行18个epoch的训练,对有域扩展的模型进行27个epoch的训练以保证收敛。我们根据经验设置参数λreg,λcls和λadv分别为0.001,2.0和2.0。根据经验,边际m设为30。对于不可增加的变化,我们选择T = 3个属性,即微笑、年轻和性别。
Variation Augmentation. 对于低分辨率,我们使用内核大小在3和11之间的高斯模糊生成。对于遮挡,我们将图像分割成7×7块,并随机用黑色masks替换部分图像块。(3)在姿势方面,我们使用PRNet[5]拟合数据集中近正面人脸的3D模型,并将其旋转到一个在40◦和60◦之间的yaw角度。所有的增强都是随机组合的,每个增强的概率是30%。
5. Experiments
在本节中,我们首先介绍不同类型的数据集,这些数据集反映了不同程度的变化。不同的变化程度表示不同的图像质量,从而导致不同的性能。然后,我们对所提出的置信度感知损失和所提出的所有模块进行了详细的ablation研究。此外,我们展示了对这些不同类型的测试数据集的评估,并与最先进的方法进行了比较。
5.1. Datasets
我们在八个人脸识别基准上评估我们的模型,涵盖了不同的真实世界测试场景。这些数据集根据变化程度大致分为三类:
Type I: Limited Variation. LFW[10]、CFP[30]、YTF[41]和MegaFace[12]是广泛应用于一般人脸识别的四个基准。我们相信这些数据集的变化是有限的,因为只有一个或很少的变化被提出。特别是YTF是分辨率相对较低的视频样本;CFP[30]是姿势变化大但分辨率高的人脸图像;MegaFace包括100万个从互联网上抓取的干扰物,其标记图像都是来自FaceScrub数据集[23]的高质量正面人脸。对于LFW和YTF,我们都使用不受限制的验证协议。对于CFP,我们主要关注正脸(FP)协议。我们测试了MegaFace的验证和识别协议。
Type II: Mixed Quality. IJB-A[14]和IJB-C[21]既包括从自然环境下拍摄的高质量名人照片,也包括在光照、遮挡、头部姿势等方面变化很大的低质量视频帧。我们测试了两个基准的验证和识别协议。
Type III: Low Quality. 我们测试了TinyFace[3]和IJB-S[11],这两个极具挑战性的基准测试主要由低质量的面部图像组成。特别是,TinyFace只包含在自然环境下拍摄的低分辨率面部图像,还包括其他变化,如遮挡和姿势。IJB-S是一个视频人脸识别数据集,除了少数每个人的高质量注册照片外,其中所有的图像都是由监控摄像头捕获的视频。这三种类型数据集的示例图像如图7所示。

5.2. Ablation Study
5.2.1 Effect of Confidence-aware Learning
我们通过逐步添加可命名的变化来训练一组模型。“基线”模型是一个18层的ResNet,训练于随机挑选的MS-Celeb-1M子集(0.6M图像)。提出的模型经过置信度感知识别损失和K = 16嵌入组的训练。作为一个对照实验,我们对IJB-A数据集应用相同类型的扩展来合成相应变化的测试数据。在图8中:
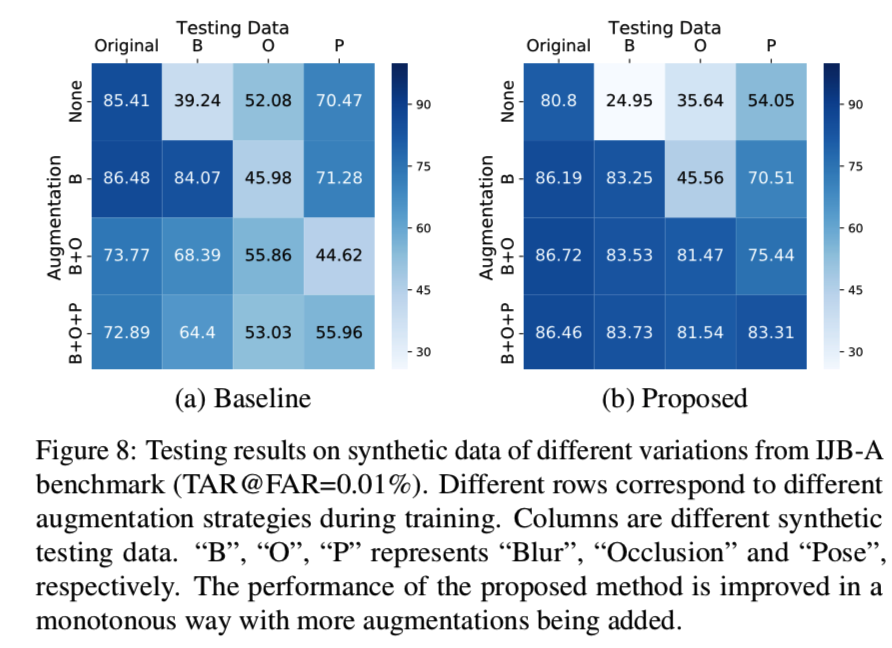
“baseline”模型显示,当网格从顶行到底行逐渐添加新变化时,性能会下降。相比之下,当从上到下添加新的变化时,我们所提出的方法显示出性能的提高,这突出了我们的置信度感知表示学习的效果,并进一步允许在框架训练中添加更多的变化。
我们还可视化带有t-SNE的特征到二维嵌入空间。从图9可以看出:

对于“baseline”模型,随着变异的增大,特征实际上是混合的,因此识别是错误的。而对于“proposed”模型,不同变化增强生成的样本仍然与原始样本聚在一起,这表明身份得到了很好的保留。在与上面相同的设置下,我们还在图10中显示了使用不同数量组的效果:
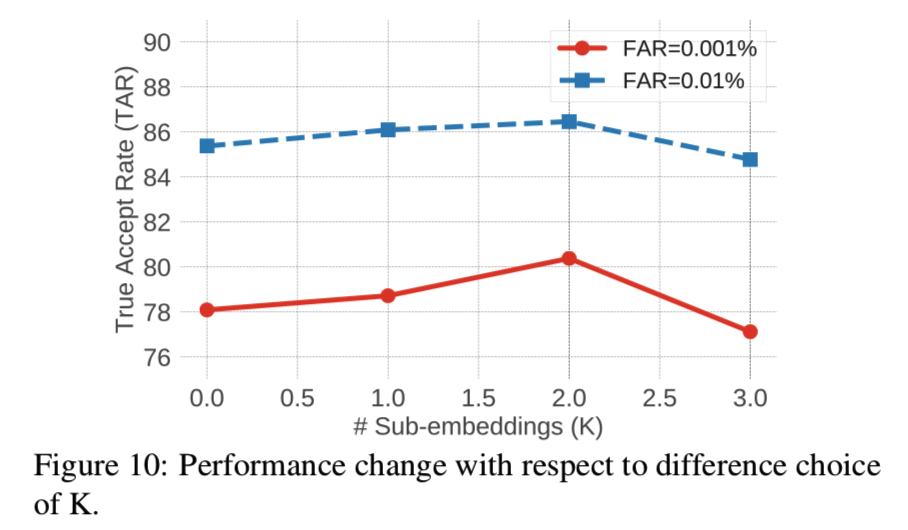
在开始时,将嵌入空间分成更多的组可以提高两个TARs的性能。当每个子嵌入的大小变得太小时,由于每个子嵌入的容量有限,性能开始下降
5.2.2 Ablation on All Modules
我们通过观察表1中的ablative模型来研究每个模块的作用:
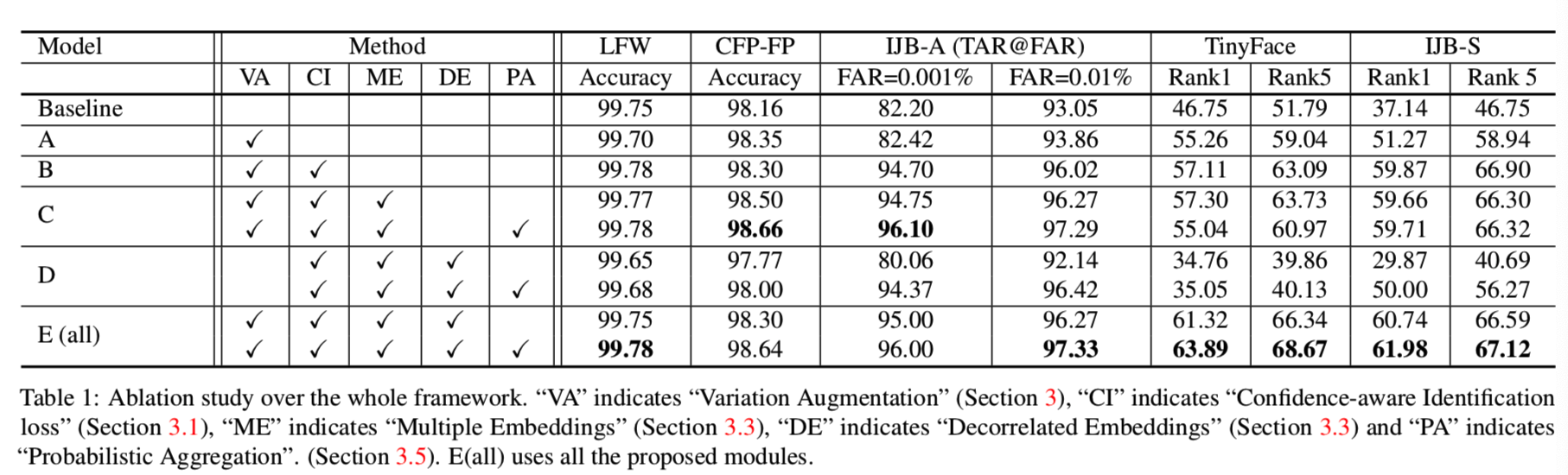
从基线开始,对模型A进行变化增强训练。在模型A的基础上,增加置信度感知识别损失,得到模型B。通过建立多个子嵌入,进一步训练模型C。在模型E中,我们进一步增加了去相关损失。并与模型D进行了比较,其有着除了变化增大外的所有模块。模型C、D和E有多个嵌入,分别测试了w/和w/o概率聚合(PA)。这些方法在两个type I数据集(LFW和CFP-FP)、一个type-II 数据集(IJB-A)和一个type-III数据集(TinyFace)上进行了测试。
如表1所示,与基线相比,增加变化增强可提高CFP-FP、TinyFace和IJBA的性能。这些数据集准确地呈现了数据扩充所带来的变化,即,姿态变化和低分辨率。然而,LFW上的性能与基线相比有波动,因为LFW大多是高质量的图像,几乎没有变化。相比之下,模型B和C能够减少由数据扩充引入的困难样本的负面影响,并在所有基准上实现一致的性能提升。同时,我们观察到单独使用分成多个子嵌入模块并不能显著提高性能(比较B和C的第一行),,这可以解释为在子嵌入中的强相关置信度(参见图5)。然而,带有去相关损失和概率聚合时,不同子嵌入能够学习并结合互补特性进一步提高性能,即,模型E的第二行性能始终优于第一行。
5.3. Evaluation on General Datasets
我们在一般的人脸识别数据集将我们的方法与最先进的方法进行对比,即那些具有有限的变化和高质量的type I 数据集。由于测试图像大多是高质量的,因此我们的方法在处理较大变化时的优势是有限的。尽管如此,如表2所示,我们的方法仍然是最好的,比大多数方法更好,但比ArcFace略差:
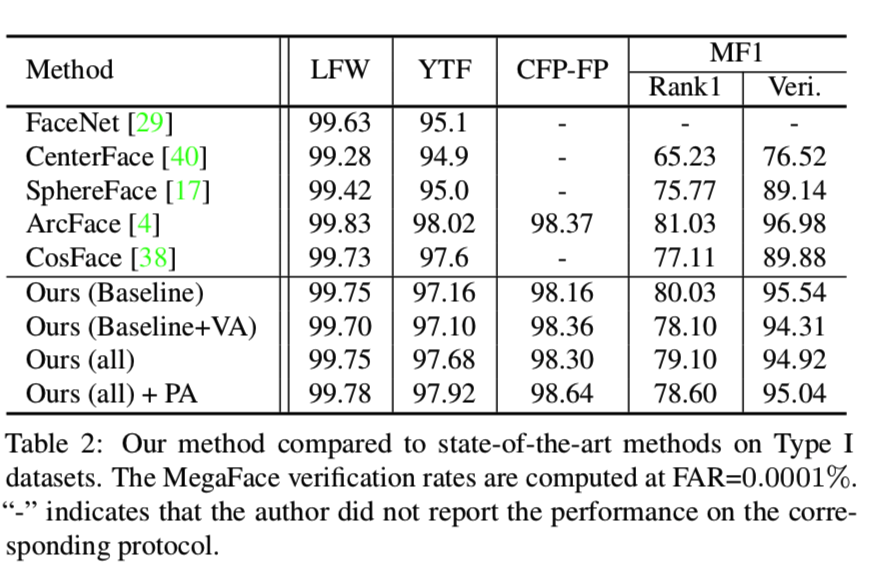
请注意,我们的基线模型已经在所有测试集上获得了良好的性能。它实际验证了type I测试集与训练集之间不存在显著的领域差异,即使不增加变化或嵌入去相关,直接训练也可以获得良好的性能。
5.4. Evaluation on Mixed/Low Quality Datasets
当对更具挑战性的数据集进行评估时,这些最先进的通用方法会遇到性能下降的问题,因为挑战性的数据集存在很大的变化,因此与高质量的训练数据集存在很大的领域差距。表3显示了在三个具有挑战性的基准上的性能:IJB-A、IJB-C和IJB-S:
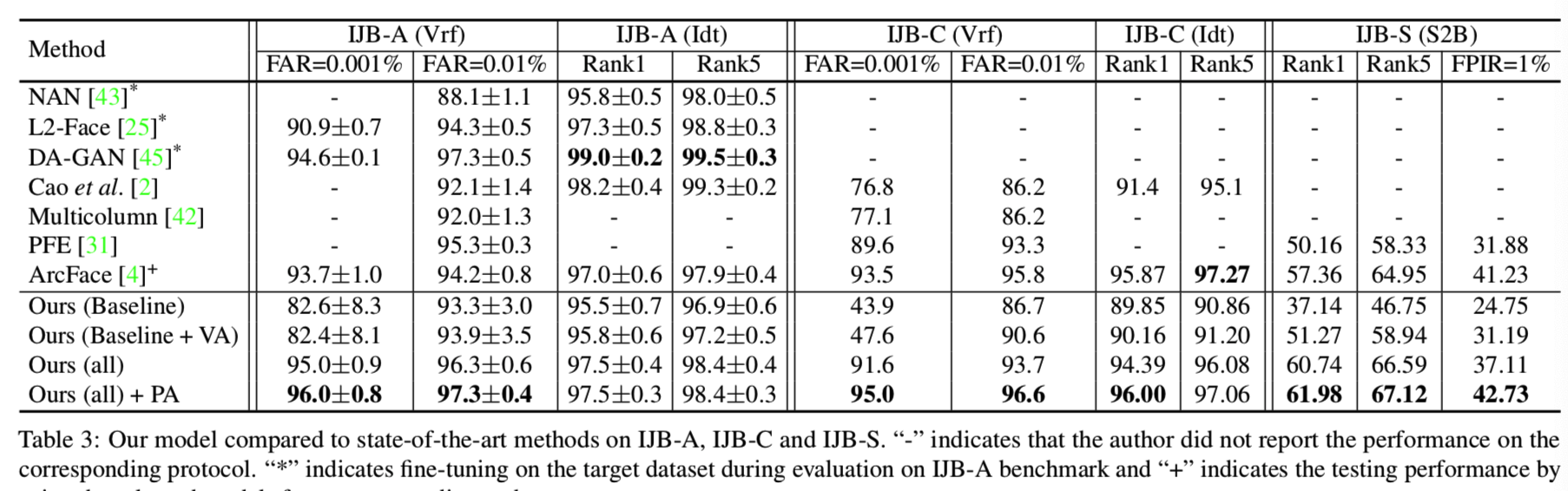
所提出的模型取得的结果始终比最先进的方法好。特别是,简单地添加变化增强(即“ours(Baseline+ VA)”)实际上会导致IJB-A和IJB-C的性能下降。当变化增强与我们提出的模块(“ours”)相结合时,可以实现显著的性能提升。进一步添加PA到“ours”,我们在所有数据集和协议中实现了更好的性能。注意,IJB-A是一个交叉验证协议。许多工作在评估前对训练分割进行微调(用“*”表示)。尽管如此,我们的方法在没有微调的情况下,仍然比IJB-A验证协议上最先进的方法有显著的优势,这表明我们的方法确实在处理不可见的变化时学习到了表征。
表3最后一列显示了对IJB-S的评估,这是目前为止最具挑战性的基准测试,针对的是真实的监控场景,图像质量非常差。我们展示了IJB-S的Surveillance-to-Booking (S2B) 协议。其他协议结果可在补充(supplementary部分)中找到。由于IJB-S最近才发布,很少有研究对这个数据集进行评估。为了全面评估我们的模型,我们使用ArcFace[4]公开发布的模型进行比较。我们的方法在Rank-1和Rank-5识别协议上取得了一致的较好的性能。对于TinyFace,如表1所示,我们实现了63.89%、68.67%的rank-1和rank-5的准确率,其中[3]的准确率为44.80%、60.40%,ArcFace的准确率为47.39%、52.28%。结合表2,我们的方法在一般识别数据集上达到了顶级精度,在具有挑战性的数据集上获得了更高的精度,这说明了在处理极端或不可见变化时我们方法的优势。
Uncertainty Visualization. 图11显示了将16个子嵌入的不确定度评分重新划分为4×4个网格。高质量和低质量的子嵌入分别以深色、浅色显示。对于不同的变化,不确定度图显示不同的模式。

6. Conclusion
在这项工作中,我们提出了一个通用的人脸表示学习框架来识别各种变化下的人脸。我们首先通过数据扩充将三种可命名的变化引入MS-Celeb-1M训练集。传统的方法在直接将增强后的困难样本输入训练时遇到了收敛问题。提出了一种置信度感知的表示学习方法,将嵌入划分为多个子嵌入,并将嵌入的置信度放宽为特定于样本和子嵌入的置信度。在此基础上,提出了变化分类和变化对抗损失的概念。通过对不确定性模型进行推理,合理地聚合了子嵌入。实验结果表明,该方法在LFW、MegaFace等常规基准测试中取得了顶好的性能,在IJB-A、IJB-C、IJB-S等具有挑战性的基准测试中取得了较好的精度。
Supplementary
B. Additional Implementation Details
嵌入的backbone网络θ是[4]中修改后的100层ResNet。在最后一个卷积层之后,网络被分成两个不同的分支,每个分支包含一个全连接层。第一个分支输出一个512维向量,它被进一步划分为16个子嵌入。另一个分支输出一个16维向量,它是子嵌入的置信值。exp函数用于保证所有的置信值si(k)为正数。θA模型用于挖掘额外的变化,其是一个四层CNN。这四层分别有64、128、256和512个内核,都是3×3的大小。