参考:https://blog.csdn.net/u013733326/article/details/79971488
希望大家直接到上面的网址去查看代码,下面是本人的笔记
到目前为止,我们一直在使用numpy来自己编写神经网络。现在我们将一步步的使用深度学习的框架来很容易的构建属于自己的神经网络。我们将学习TensorFlow这个框架:
- 初始化变量
- 建立一个会话
- 训练的算法
- 实现一个神经网络
使用框架编程不仅可以节省你的写代码时间,还可以让你的优化速度更快。
1.导入TensorFlow库
import numpy as np import h5py import matplotlib.pyplot as plt import tensorflow as tf from tensorflow.python.framework import ops import tf_utils import time #%matplotlib inline #如果你使用的是jupyter notebook取消注释 np.random.seed(1)
2.说明TensorFlow代码的实现流程
对于Tensorflow的代码实现而言,实现代码的结构如下:
-
创建Tensorflow变量(此时,尚未直接计算)
-
实现Tensorflow变量之间的操作定义
-
初始化Tensorflow变量
-
创建Session
-
运行Session,此时,之前编写操作都会在这一步运行。
1)所以举例如果要计算损失函数:
![]()
实现流程为:
#首先创建变量,这里设置了常量 y_hat = tf.constant(36,name="y_hat") #定义y_hat为固定值36 y = tf.constant(39,name="y") #定义y为固定值39 #实现变量之间的操作定义,即损失函数的计算 loss = tf.Variable((y-y_hat)**2,name="loss" ) #为损失函数创建一个变量 #声明变量的初始化操作 init = tf.global_variables_initializer() #运行之后的初始化(session.run(init)) #创建session,并打印输出 #损失变量将被初始化并准备计算 with tf.Session() as session: #初始化变量 session.run(init) #运行session,这样之前定义的变量间的操作都会在这里运行,打印损失值 print(session.run(loss))
返回9
查看初始化和运行前后变量的变化:
#首先创建变量 y_hat = tf.constant(36,name="y_hat") #定义y_hat为固定值36 y = tf.constant(39,name="y") #定义y为固定值39 #实现变量之间的操作定义,即损失函数的计算 loss = tf.Variable((y-y_hat)**2,name="loss" ) #为损失函数创建一个变量 print(y_hat) print(y) print(loss) #声明变量的初始化操作 init = tf.global_variables_initializer() #运行之后的初始化(session.run(init)) #创建session,并打印输出 #损失变量将被初始化并准备计算 with tf.Session() as session: #初始化变量 session.run(init) print(y_hat) print(y) print(loss) #运行session,这样之前定义的变量间的操作都会在这里运行,打印损失值 print(session.run(loss)) print(y_hat) print(y)
返回:
Tensor("y_hat_2:0", shape=(), dtype=int32) Tensor("y_2:0", shape=(), dtype=int32) <tf.Variable 'loss_2:0' shape=() dtype=int32_ref> Tensor("y_hat_2:0", shape=(), dtype=int32) Tensor("y_2:0", shape=(), dtype=int32) <tf.Variable 'loss_2:0' shape=() dtype=int32_ref> 9 Tensor("y_hat_2:0", shape=(), dtype=int32) Tensor("y_2:0", shape=(), dtype=int32)
再运行一遍,可见版本号会变:
Tensor("y_hat_3:0", shape=(), dtype=int32) Tensor("y_3:0", shape=(), dtype=int32) <tf.Variable 'loss_3:0' shape=() dtype=int32_ref> Tensor("y_hat_3:0", shape=(), dtype=int32) Tensor("y_3:0", shape=(), dtype=int32) <tf.Variable 'loss_3:0' shape=() dtype=int32_ref> 9 Tensor("y_hat_3:0", shape=(), dtype=int32) Tensor("y_3:0", shape=(), dtype=int32)
如果注释掉初始化就会报错:
#首先创建变量 y_hat = tf.constant(36,name="y_hat") #定义y_hat为固定值36 y = tf.constant(39,name="y") #定义y为固定值39 #实现变量之间的操作定义,即损失函数的计算 loss = tf.Variable((y-y_hat)**2,name="loss" ) #为损失函数创建一个变量 print(y_hat) print(y) print(loss) #声明变量的初始化操作 #init = tf.global_variables_initializer() #运行之后的初始化(session.run(init)) #创建session,并打印输出 #损失变量将被初始化并准备计算 with tf.Session() as session: #初始化变量 #session.run(init) #运行session,这样之前定义的变量间的操作都会在这里运行,打印损失值 print(session.run(loss)) print(y_hat) print(y)
返回:
Tensor("y_hat_5:0", shape=(), dtype=int32) Tensor("y_5:0", shape=(), dtype=int32) <tf.Variable 'loss_5:0' shape=() dtype=int32_ref> ... FailedPreconditionError: Attempting to use uninitialized value loss_5 [[{{node _retval_loss_5_0_0}} = _Retval[T=DT_INT32, index=0, _device="/job:localhost/replica:0/task:0/device:CPU:0"](loss_5)]]
因此,当我们为损失函数创建一个变量时,我们简单地将损失定义为其他数量的函数,但没有评估它的价值。
为了评估它,我们需要运行init=tf.global_variables_initializer(),初始化损失变量,在最后一行,我们最后能够评估损失的值并打印它的值。
所以init=tf.global_variables_initializer()的作用对应的是声明为变量的损失函数loss = tf.Variable((y-y_hat)**2,name="loss" )
2)另外一个更简单的函数
#创建变量 a = tf.constant(2) b = tf.constant(10) #实现变量之间的操作定义 c = tf.multiply(a,b) print(c)
返回:
Tensor("Mul:0", shape=(), dtype=int32)
正如预料中一样,我们并没有看到结果20,不过我们得到了一个Tensor类型的变量,没有维度,数字类型为int32。我们之前所做的一切都只是把这些东西放到了一个“计算图(computation graph)”中,而我们还没有开始运行这个计算图,为了实际计算这两个数字,我们需要创建一个会话并运行它:
#创建会话 sess = tf.Session() #使用会话运行操作 print(sess.run(c)) #返回20
⚠️因为这里没有声明变量,所以不用使用init=tf.global_variables_initializer()来初始化变量
总结一下,记得初始化变量,然后创建一个session来运行它。
3.会话
可以使用两种方法来创建并使用session
方法一:
sess = tf.Session() result = sess.run(...,feed_dict = {...}) sess.close()
方法二:
with tf.Session as sess: result = sess.run(...,feed_dict = {...})
4.占位符(placeholder)
占位符是一个对象,它的值只能在稍后指定,要指定占位符的值,可以使用一个feed_dict变量来传入,接下来,我们为x创建一个占位符,这将允许我们在稍后运行会话时传入一个数字。
#利用feed_dict来改变x的值 x = tf.placeholder(tf.int64,name="x") print(x) print(sess.run(2 * x,feed_dict={x:3})) sess.close()
返回:
Tensor("x:0", dtype=int64) 6
当我们第一次定义x时,我们不必为它指定一个值。 占位符只是一个变量,我们会在运行会话时将数据分配给它。
5.线性函数
让我们通过计算以下等式来开始编程:Y=WX+b,W和X是随机矩阵,b是随机向量。
我们计算WX+b,其中W,X和b是从随机正态分布中抽取的。 W的维度是(4,3),X是(3,1),b是(4,1)。
我们开始定义一个shape=(3,1)的常量X:
X = tf.constant(np.random.randn(3,1), name = "X")
代码:
def linear_function(): """ 实现一个线性功能: 初始化W,类型为tensor的随机变量,维度为(4,3) 初始化X,类型为tensor的随机变量,维度为(3,1) 初始化b,类型为tensor的随机变量,维度为(4,1) 返回: result - 运行了session后的结果,运行的是Y = WX + b """ np.random.seed(1) #指定随机种子 X = np.random.randn(3,1) W = np.random.randn(4,3) b = np.random.randn(4,1) Y = tf.add(tf.matmul(W,X),b) #tf.matmul是矩阵乘法 #Y = tf.matmul(W,X) + b #也可以以写成这样子 #创建一个session并运行它 sess = tf.Session() result = sess.run(Y) #session使用完毕,关闭它 sess.close() return result
测试:
print("result = " + str(linear_function()))
返回:
result = [[-2.15657382] [ 2.95891446] [-1.08926781] [-0.84538042]]
6.计算sigmoid函数
TensorFlow提供了多种常用的神经网络的函数比如tf.softmax和 tf.sigmoid。
我们将使用占位符变量x,当运行这个session的时候,我们西药使用使用feed_dict来输入z,我们将创建占位符变量x,使用tf.sigmoid来定义操作,最后运行session,我们会用到下面的代码:
- tf.placeholder(tf.float32, name = “x”)
- sigmoid = tf.sigmoid(x)
- sess.run(sigmoid, feed_dict = {x: z})
实现:
def sigmoid(z): """ 实现使用sigmoid函数计算z 参数: z - 输入的值,标量或矢量 返回: result - 用sigmoid计算z的值 """ #创建一个占位符x,名字叫“x” x = tf.placeholder(tf.float32,name="x") #计算sigmoid(z) sigmoid = tf.sigmoid(x) #创建一个会话,使用方法二 with tf.Session() as sess: result = sess.run(sigmoid,feed_dict={x:z}) return result
测试:
print ("sigmoid(0) = " + str(sigmoid(0))) print ("sigmoid(12) = " + str(sigmoid(12)))
返回:
sigmoid(0) = 0.5 sigmoid(12) = 0.9999938
7.计算成本函数
还可以使用内置函数计算神经网络的成本。因此,不需要编写代码来计算成本函数的 a[2](i)
和 y(i),如:
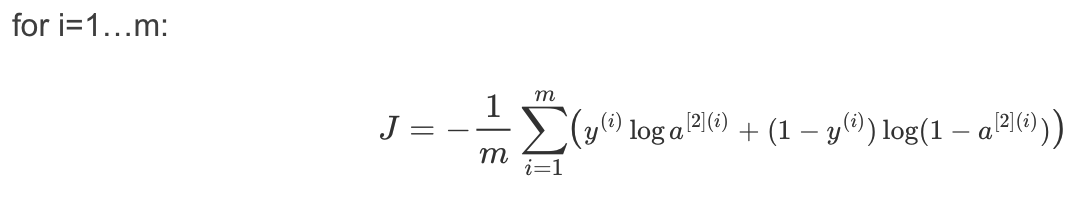
tensorflow提供了用来计算成本的函数:
tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)
logits:前向传播的结果AL,如果使用的是softmax,这里传入的是ZL
labels:真正的结果Y
8.使用独热编码(0,1编码)
很多时候在深度学习中y向量的维度是从0到C−1的,C是指分类的类别数量,如果C=4,那么对y而言你可能需要有以下的转换方式:
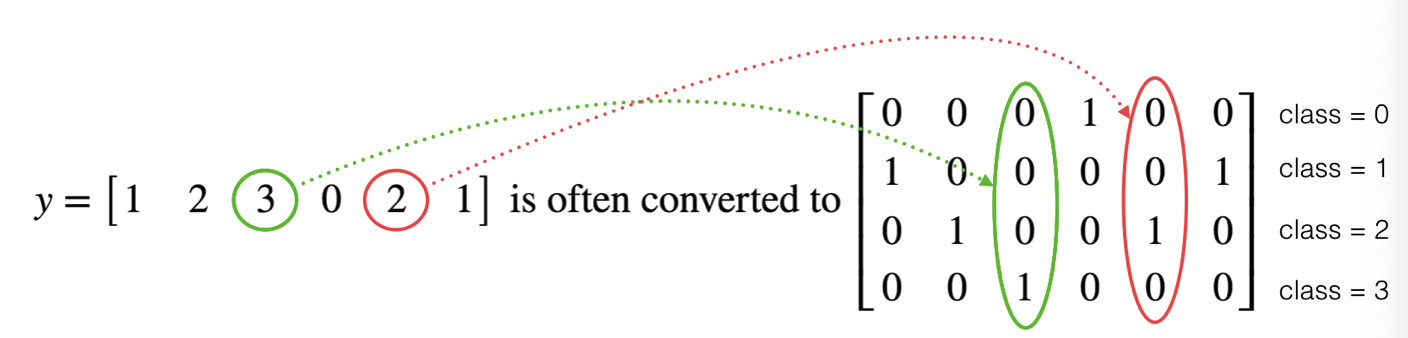
这叫做独热编码(”one hot” encoding),因为在转换后的表示中,每列的一个元素是“hot”(意思是设置为1)。 要在numpy中进行这种转换,您可能需要编写几行代码。 在tensorflow中,只需要使用一行代码:
tf.one_hot(labels,depth,axis)
下面我们要做的是取一个标签矢量(即图片的判断结果)和C类总数,返回一个独热编码。
def one_hot_matrix(lables,C): """ 创建一个矩阵,其中第i行对应第i个类号,第j列对应第j个训练样本 所以如果第j个样本对应着第i个标签,那么entry (i,j)将会是1 参数: lables - 标签向量 C - 分类数 返回: one_hot - 独热矩阵 """ #创建一个tf.constant,赋值为C,名字叫C C = tf.constant(C,name="C") #使用tf.one_hot,注意一下axis one_hot_matrix = tf.one_hot(indices=lables , depth=C , axis=0) #创建一个session sess = tf.Session() #运行session one_hot = sess.run(one_hot_matrix) #关闭session sess.close() return one_hot
测试:
labels = np.array([1,2,3,0,2,1]) one_hot = one_hot_matrix(labels,C=4) print(str(one_hot))
返回:
[[0. 0. 0. 1. 0. 0.] [1. 0. 0. 0. 0. 1.] [0. 1. 0. 0. 1. 0.] [0. 0. 1. 0. 0. 0.]]
9.初始化参数
学习如何用0或者1初始化一个向量,我们要用到tf.ones()和tf.zeros(),给定这些函数一个维度值那么它们将会返回全是1或0的满足条件的向量/矩阵,我们来看看怎样实现它们:
def ones(shape): """ 创建一个维度为shape的变量,其值全为1 参数: shape - 你要创建的数组的维度 返回: ones - 只包含1的数组 """ #使用tf.ones() ones = tf.ones(shape) #创建会话 sess = tf.Session() #运行会话 ones = sess.run(ones) #关闭会话 sess.close() return ones
测试:
print ("ones = " + str(ones([3])))
返回:
ones = [1. 1. 1.]