

import requests def downLoad_img(url_para,file_path): img_get=requests.get(url=url_para) with open(file_path, 'wb') as f: f.write(img_get.content) # 写入字节码
settings.py:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
CHOUTI='https://dig.chouti.com/'
import requests,os from bs4 import BeautifulSoup import settings from chouti.utils.util import downLoad_img res=requests.get( url=settings.CHOUTI , headers={ 'user-agent':settings.USER_AGENT } ) soup=BeautifulSoup(res.text,'html.parser') item_list=soup.find_all(name='div',attrs={"id":'content-list'}) for item in item_list: item_all = item.find_all(name='div', attrs={'class': 'item'}) for item_obj in item_all: content_list=item_obj.find_all(name='div',attrs={'class':'news-content'}) for content in content_list: href_list=content.find(name='a').attrs.get('href') share_pic=content.find(name='div',attrs={'class':'part2'})['share-pic'] share_title=content.find(name='div',attrs={'class':'part2'})['share-title'] summary=content.find(name='span').text print(href_list) img_name = share_pic.rsplit('/', maxsplit=1)[1] print(share_title) print(summary) file_path=os.path.join('chouti/imgs',img_name) # 下载图片 downLoad_img(share_pic,file_path) # 写入文本 with open('chouti/link.txt','a',encoding='utf-8') as linkf: linkf.write(href_list+' ') linkf.write(share_title+' ') linkf.write(summary+' ')
""" 通过代码进行自动登录,然后进行点赞 """ import requests import settings # ##################### 第一部分:登录 ##################### # 获取登录form页面 r1 = requests.get( url='https://dig.chouti.com/', headers={ 'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
} )
r1_cookie_dict = r1.cookies.get_dict()
print(r1_cookie_dict)
# 提交账号-------------
r2 = requests.post(
url='https://dig.chouti.com/login',
headers={ 'user-agent':settings.USER_AGENT },
data={ 'phone':'86'+'18310189881',
'password':'abcd1234', 'oneMonth':1 },
cookies=r1_cookie_dict ) print(r2.text)
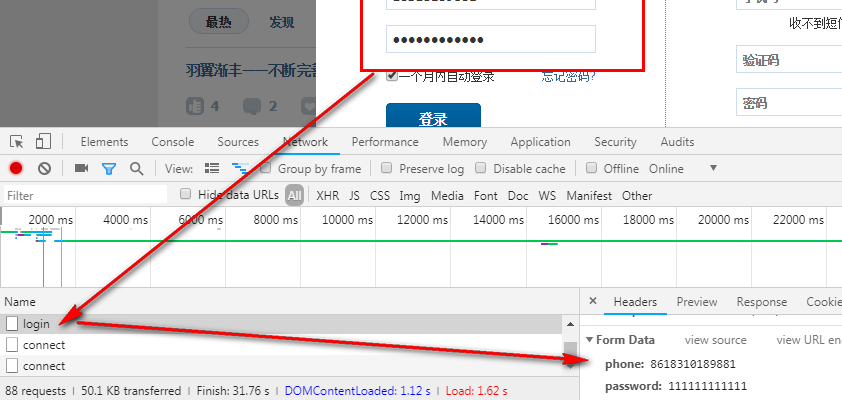
# # ##################### 第二部分:点赞 #####################
r3 = requests.post(
url='https://dig.chouti.com/link/vote?linksId=20868591',
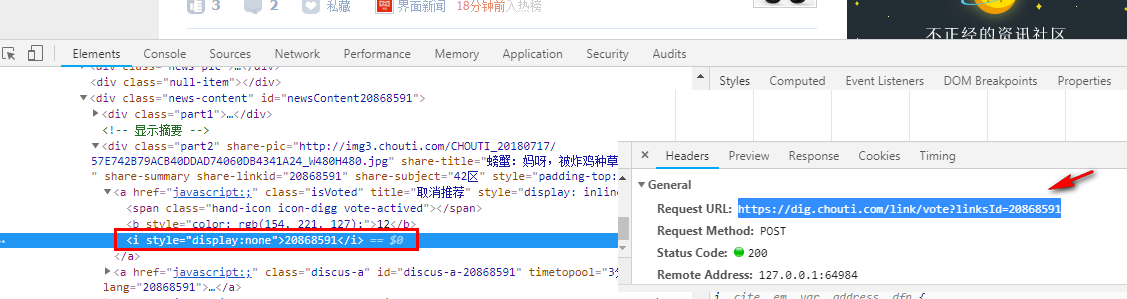
headers={ 'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' },
cookies=r1_cookie_dict )
print(r3.text)