1:原理理解
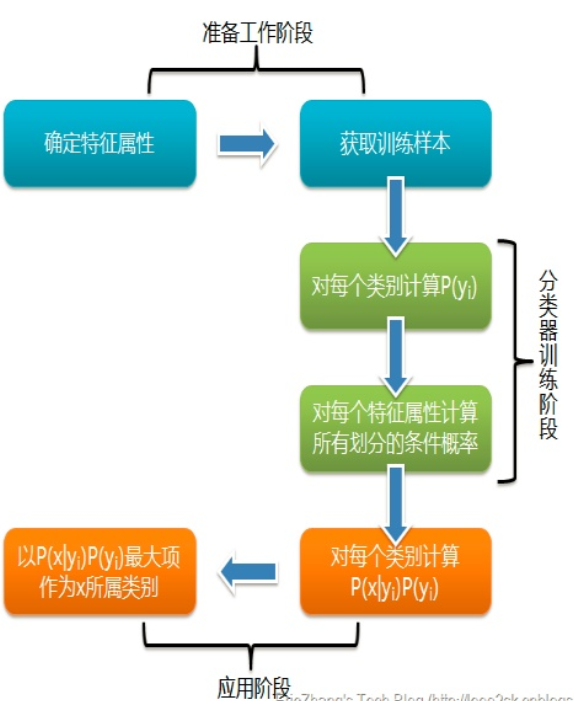
举个形象的例子,若我们走在街上看到一个黑皮肤的外国友人,让你来猜这位外国友人来自哪里。十有八九你会猜是从非洲来的,因为黑皮肤人种中非洲人的占比最多,虽然黑皮肤的外国人也有可能是美洲人或者是亚洲人。但是在没有其它可用信息帮助我们判断的情况下,我们会选择可能出现的概率最高的类别,这就是朴素贝叶斯的基本思想。值得注意的是,朴素贝叶斯分类并非是瞎猜,也并非没有任何理论依据。它是以贝叶斯理论和特征条件独立假设为基础的分类算法。想要弄明白算法的原理,首先需要理解什么是“特征条件独立假设”以及“贝叶斯定理”,而贝叶斯定理又牵涉到“先验概率”、“后验概率”及“条件概率”的概念,如下图所示,虽然概念比较多但是都比较容易理解,下面我们逐个详细介绍。

特征条件独立假设是贝叶斯分类的基础,意思是假定该样本中每个特征与其他特征之间都不相关。例如在预测信用卡客户逾期的例子中,我们会通过客户的月收入、信用卡额度、房车情况等不同方面的特征综合判断。两件看似不相关的事情实际上可能存在内在联系,就像蝴蝶效应一样。普遍情况下,银行批给收入较高的客户的信用卡额度也比较高。同时收入高也代表这个客户更有能力购买房产,所以这些特征之间存在一定的依赖关系,某些特征是由其他特征决定的。然而在朴素贝叶斯算法中,我们会忽略这种特征之间的内在关系,直接认为客户的月收入、房产与信用卡额度之间没有任何关系,三者是各自独立的特征。
2:真假概率
首先我们进行一个小实验。假设将一枚质地均匀的硬币抛向空中,理论上,因为硬币的正反面质地均匀,落地时正面朝上或反面朝上的概率都是50%。这个概率不会随着抛掷次数的增减而变化,哪怕抛了10次结果都是正面朝上,下一次是正面朝上的概率仍然是50%。
但在实际测试中,如果我们抛100次硬币,正面朝上和反面朝上的次数通常不会恰好都是50次。有可能出现40次正面朝上和60次反面朝上的情况,也有可能出现35次正面朝上和65次反面朝上的情况。
只有我们一直抛,抛了成千上万次,硬币正面朝上与反面朝上的次数才会逐渐趋向于相等。
因此,我们说“正面朝上和反面朝上各有50%的概率”这句话所指的概率是理论上的客观概率。只有当抛掷次数接近无数次时,才会达到这种理想中的概率。在理论概率下,尽管抛10次硬币,前面5次都是正面朝上,第6次是反面朝上的概率仍然是50%。
但是在实际中,抛过硬币的人都有这样的感觉,如果出现连续5次正面朝上的情况,下一次是反面朝上的可能性极大,大到什么程度?有没有什么方法可以求出实际的概率呢?
为了解决这个问题,一位名叫托马斯·贝叶斯(ThomasBayes)的数学家发明了一种方法用于计算“在已知条件下,另外一个事件发生”的概率。该方法要求我们先预估一个主观的先验概率,再根据后续观察到的结果进行调整,随着调整次数的增加,真实的概率会越来越精确。
3:使用
import numpy as np import sklearn.naive_bayes as sk_bayes import sklearn.datasets as datasets iris = datasets.load_iris() # 鸟分类数据集 X = iris['data'] y = iris['target'] from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) print("训练集:",X_train.shape,y_train.shape) print("测试集:",X_test.shape,y_test.shape)
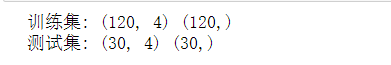
model = sk_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None) #多项式分布的朴素贝叶斯 # model = sk_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class_prior=None) #伯努利分布的朴素贝叶斯 model = sk_bayes.GaussianNB()#高斯分布的朴素贝叶斯 model.fit(X_train,y_train) acc=model.score(X_test,y_test) #根据给定数据与标签返回正确率的均值 print('n朴素贝叶斯(高斯分布)模型评价:',acc)

