有台服务器故障期间的现象:
1、 可以正常ping通
2、 telnet服务端口报Too many connections错误
3、 ssh连接不上
查看MHA的管理日志,在强制关机前的health check都是正常的

这点比较奇怪,因此在测试集群上模拟生产的问题做了测试
1、 模拟压测制造master Too many connections

2、 观察MHA管理日志,与生产环境相似
3、 查看HealthCheck.pm代码,原来是长连接
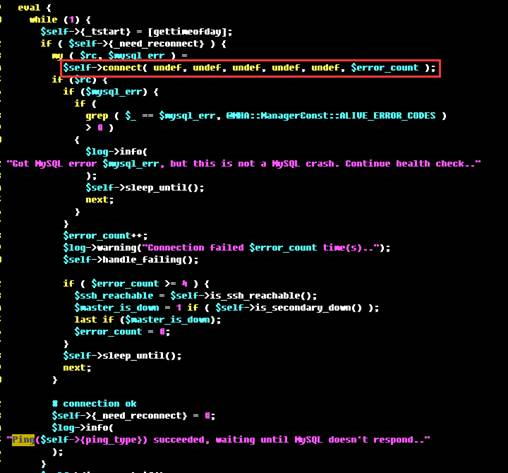
【测试kill掉health check长连接】
管理日志中记录建立连接时Too many connections的报错,但不会发生切换,每隔10秒做一次ping检测

【测试kill掉health check长连接&停止MHA管理进程】
再次启动MHA管理进程时会报错

【解决思路】
1、 已发生Too many connections的问题,想办法尽快把master搞死
尝试ssh连接到本机上shutdown mysql服务,ssh连接不上的情况下,联系NOC重启或关机
2、 每台服务器本地部署一个检测和扩连接的脚本
3、 还有一个思路是,改进当前调整connections的逻辑,对每台服务器维护一个连接池或建立一个长连接
4、 最佳的方案是不采用one-thread-per-connection的连接方式,改用pool-threads。
遗憾的是在MySQL官方版本上这个是收费的,一些公司使用的是Percona。