JVM垃圾收集器:
串行垃圾收集器:
串行回收器是指使用单线程进行垃圾回收的回收器。每次回收时,串行回收器只有一个工作线程,对于并发能力较弱的计算机来说,
串行回收器的专注性和独占性往往有更好的性能表现。

特点
1 它仅仅使用单线程进行垃圾回收
2 它是独占式的垃圾回收在串行收集器进行垃圾回收时,JAVA 应用程序中的线程都需要暂停,等待垃圾回收完成。如上图所示。
这种现象称之为Stop-The-Word。会造成非常糟糕的用户体验,在实时性较高的应用场景中,这种现象往往是不能接受的。
并行(Parallelism)垃圾收集器
ParNew收集器
用于新生代,用户响应时间比较短,适用于server。是CMS默认的新生代收集器
Parallel Scavenge收集器
用于新生代,吞吐量比较高,但是用户响应时间比较长,适用于后台。
Parallel Old收集器
用于老年代,响应时间较长,吞吐量较大。适用于后台,和Parallel Scavenge配合使用。
CMS收集器:
一种以获取最短回收停顿时间为目标的收集器。
特点:基于标记-清除算法实现。并发收集、低停顿。
应用场景:适用于注重服务的响应速度,希望系统停顿时间最短,给用户带来更好的体验等场景下。如web程序、b/s服务。
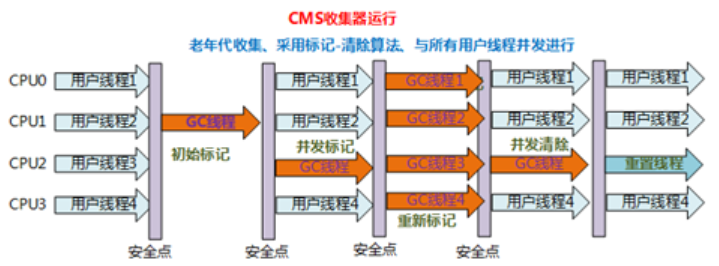
CMS收集器的运行过程分为下列4步:
初始标记:标记GC Roots能直接到的对象。速度很快但是仍存在Stop The World问题。
并发标记:进行GC Roots Tracing 的过程,找出存活对象且用户线程可并发执行。
重新标记:为了修正并发标记期间因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录。仍然存在Stop The World问题。
并发清除:对标记的对象进行清除回收。
CMS收集器的内存回收过程是与用户线程一起并发执行的。
如下图:
CMS收集器的缺点:
-
- 对CPU资源非常敏感。
- 无法处理浮动垃圾,可能出现Concurrent Model Failure失败而导致另一次Full GC的产生。
- 因为采用标记-清除算法所以会存在空间碎片的问题,导致大对象无法分配空间,不得不提前触发一次Full GC。
G1收集器:
一款面向服务端应用的垃圾收集器。
特点如下:
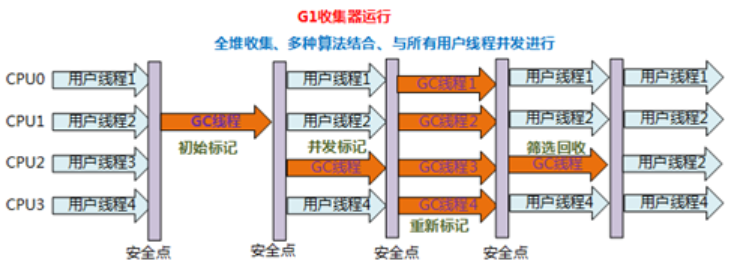
并行与并发:G1能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短Stop-The-World停顿时间。部分收集器原本需要停顿Java线程来执
行GC动作,G1收集器仍然可以通过并发的方式让Java程序继续运行。
分代收集:G1能够独自管理整个Java堆,并且采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次GC的旧对象以获取更好的收集效果。
空间整合:G1运作期间不会产生空间碎片,收集后能提供规整的可用内存。
可预测的停顿:G1除了追求低停顿外,还能建立可预测的停顿时间模型。能让使用者明确指定在一个长度为M毫秒的时间段内,消耗在垃圾收集上的
时间不得超过N毫秒。
G1为什么能建立可预测的停顿时间模型?
因为它有计划的避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的大小,在后台维护一个优先列表,每次根据允许的
收集时间,优先回收价值最大的Region。这样就保证了在有限的时间内可以获取尽可能高的收集效率。
G1与其他收集器的区别:
其他收集器的工作范围是整个新生代或者老年代、G1收集器的工作范围是整个Java堆。在使用G1收集器时,它将整个Java堆划分为多个大小相等的独
立区域(Region)。虽然也保留了新生代、老年代的概念,但新生代和老年代不再是相互隔离的,他们都是一部分Region(不需要连续)的集合。
G1收集器存在的问题:
Region不可能是孤立的,分配在Region中的对象可以与Java堆中的任意对象发生引用关系。在采用可达性分析算法来判断对象是否存活时,得扫描整
个Java堆才能保证准确性。其他收集器也存在这种问题(G1更加突出而已)。会导致Minor GC效率下降。
G1收集器是如何解决上述问题的?
采用Remembered Set来避免整堆扫描。G1中每个Region都有一个与之对应的Remembered Set,虚拟机发现程序在对Reference类型进行写操作时,
会产生一个Write Barrier暂时中断写操作,检查Reference引用对象是否处于多个Region中(即检查老年代中是否引用了新生代中的对象),如果是,便通
过CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set中。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set
即可保证不对全堆进行扫描也不会有遗漏。
如果不计算维护 Remembered Set 的操作,G1收集器大致可分为如下步骤:
初始标记:仅标记GC Roots能直接到的对象,并且修改TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的Region中创建
新对象。(需要线程停顿,但耗时很短。)
并发标记:从GC Roots开始对堆中对象进行可达性分析,找出存活对象。(耗时较长,但可与用户程序并发执行)
最终标记:为了修正在并发标记期间因用户程序执行而导致标记产生变化的那一部分标记记录。且对象的变化记录在线程Remembered Set Logs里面,把Reme
mbered Set Logs里面的数据合并到Remembered Set中。(需要线程停顿,但可并行执行。)
筛选回收:对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。(可并发执行)
G1收集器运行示意图: