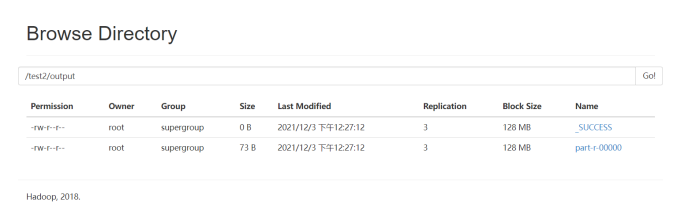
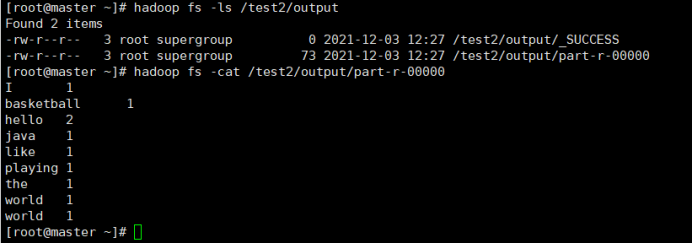
词频统计
示例文档
text1_2.txt
hello world
I like playing basketball
hello java
the world
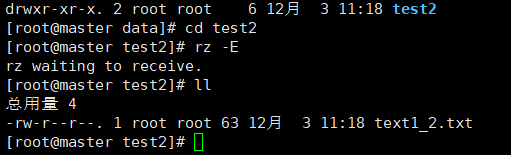
上传文档


实验代码
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.edu.bupt.wcy</groupId> <artifactId>wordcount</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>wordcount</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.1</version> </dependency> </dependencies> </project>
WordCountMapper.java
package mapreduce; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //super.map(key, value, context); //String[] words = StringUtils.split(value.toString()); String[] words = StringUtils.split(value.toString(), " "); for(String word:words) { context.write(new Text(word), new LongWritable(1)); } } }
WordCountReducer.java
package mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text arg0, Iterable<LongWritable> arg1, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //super.reduce(arg0, arg1, arg2); int sum=0; for(LongWritable num:arg1) { sum += num.get(); } context.write(arg0,new LongWritable(sum)); } }
WordCountRunner.java
package mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountRunner { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(WordCountRunner.class); job.setJobName("wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.109.10:9000/test2/in/")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.109.10:9000/test2/output/")); job.waitForCompletion(true); } }
设置输入输出路径
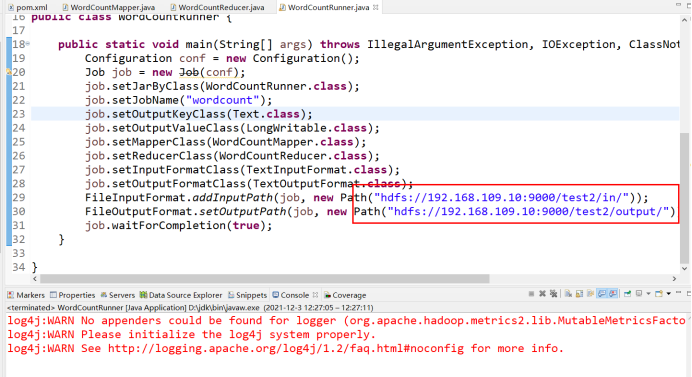
运行结果