概述
数据结构是组织存储数据,以便我们有效的访问、更改数据。堆栈、队列是计算机中定义最早的数据结构。堆栈是后进先出(左端固定固定右端浮动,堆栈是右进右出),队列是先进先出的数据组织和存储形式。
详解
堆、栈
栈是先进后出的数据结构,一端固定另一端浮动 如列表的数据类型就是模拟栈。堆是树形数据结构就行图书馆里的书每个节点都有书,没有顺序之分如字典。
相同点:他们所达到的最终目的相同都是先进后出结构,一端固定另一端浮动。
不同点:
1)缓存
栈采用一级缓存,处于存储空间中,调用完毕后释放空间
堆采用二级缓存,生命周期垃圾回收决定
2)释放
栈区(stack):生命周期随线程周期,编译器自动释放
堆区(heap):程序员释放或由os垃圾回收释放
堆栈关系:所有线程共享堆
3)存放内容
栈:存放函数参数名、局部变量名(基本数据类型、调用对象等)。
堆:存放数组、对象(用new来创建对象如 new String('asd'))。
4)性能
栈:速度快、内存大小固定好的、自由度小。
堆:速度慢、容易产生内存碎片、自由度大。
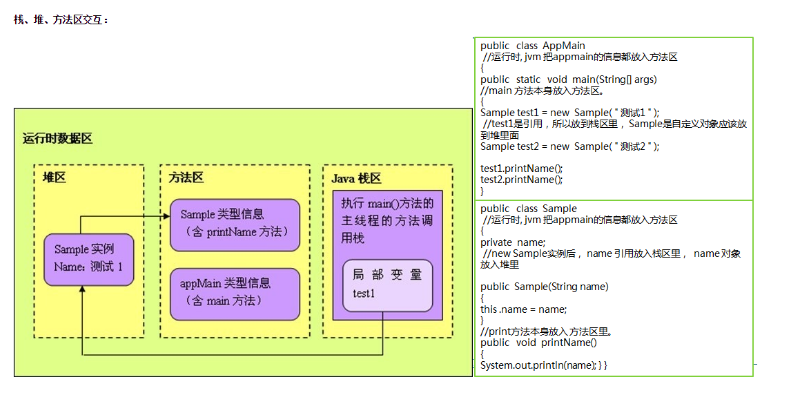
进程/线程/堆/栈之间的关系
进程线程针对系统而言的和数据结构无关。进程是一段代码,是操作系统资源分配基本概念、是调度和运行的基本单位,进程可以有多个任务每个任务是一个线程;
堆栈针对的是数据结构。栈是右进右出函数变量、局部变量都属于栈,堆是树形结构类似于字典的目录对象数组都属于堆,线程中会用到栈和堆。
代码
栈code
数据结构是从右往左进,右进右出。
lists = [] #定义空的堆栈,可以把它理解成一个地铁(这个地铁只有一侧门出入)
lists.append('a') #堆栈添加数据,可以把它理解成一个挤进地铁的人最新进入的认会被挤到最后头
lists.append('b')
lists.append('f')
lists.append('g')
last_out = lists.pop() #pop出最后一个进入列表的‘g’栈(最后挤入地铁的那个人)
print last_out
last_out = lists.pop() #pop出倒数第二个进入列表的‘f’栈(刚才已经出去了一个)
print last_out
代码写到这里想到列表中的偏移量就代表了堆栈的先后出的元素,先出的偏移量就是-1 (最后一个元素)。
堆
堆是树形数据结构就行图书馆里的书每个节点都有书,没有顺序之分如字典。
队列
数据结构是从右往左进,右进左出
fruits = []
fruits.append('apple')
fruits.append('banana')
fruits.append('oragin')
fruits.append('grapes')
first_out = fruits.pop(0) #pop出‘grapes’
print fruits
first_out = fruits.pop(0) #pop出‘oragin’
print fruits
参考链接:
https://www.jianshu.com/p/c990427ca608
https://baike.baidu.com/item/%E5%A0%86%E6%A0%88/1682032?fr=aladdin