//创建一个名叫suoyin的索引 curl -XPUT http://localhost:9200/suoyin
//创建一个名叫megacorp的索引
curl -XPUT http://localhost:9200/megacorp
//设置索引的属性信息 curl -XPOST http://localhost:9200/suoyin/fulltext/_mapping -d' { "fulltext": { "_all": { "analyzer": "ik_max_word", "search_analyzer": "ik_max_word", "term_vector": "no", "store": "false" }, "properties": { "content": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word", "include_in_all": "true", "boost": 8 } } } }' //创建一个名叫megacorp的索引,文件类型为megacorp,并向索引里插入数据 curl -XPOST http://localhost:9200/megacorp/employee/1 -d' { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] }' curl -XPOST http://localhost:9200/megacorp/employee/2 -d' { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] }' curl -XPOST http://localhost:9200/megacorp/employee/3 -d' { "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about": "I like to build cabinets", "interests": [ "forestry" ] }' curl -XPOST http://localhost:9200/suoyin/fulltext/_search -d' { "query": { "match": { "last_name": "smith" } } }' //查询数据 http://localhost:9200/suoyin1/fulltext/_search?q=last_name:Smith
使用DSL语句查询
查询字符串搜索便于通过命令行完成特定(ad hoc)的搜索,但是它也有局限性(参阅简单搜索章节)。Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。我们可以这样表示之前关于“Smith”的查询:
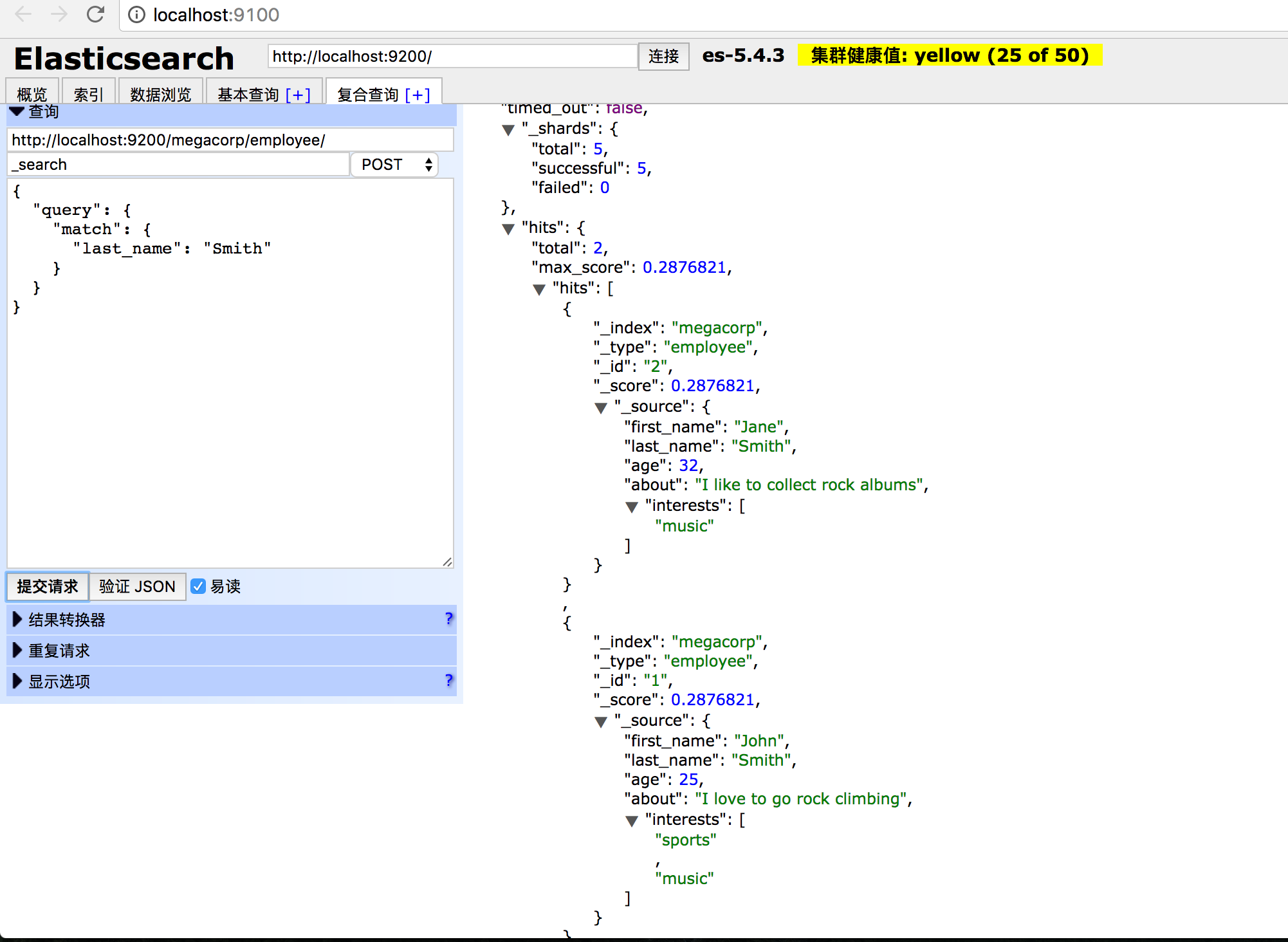
这会返回与之前查询相同的结果。你可以看到有些东西改变了,我们不再使用查询字符串(query string)做为参数,而是使用请求体代替。这个请求体使用JSON表示,其中使用了match语句(查询类型之一,具体我们以后会学到)。
全文搜索
到目前为止搜索都很简单:搜索特定的名字,通过年龄筛选。让我们尝试一种更高级的搜索,全文搜索——一种传统数据库很难实现的功能。
我们将会搜索所有喜欢“rock climbing”的员工:
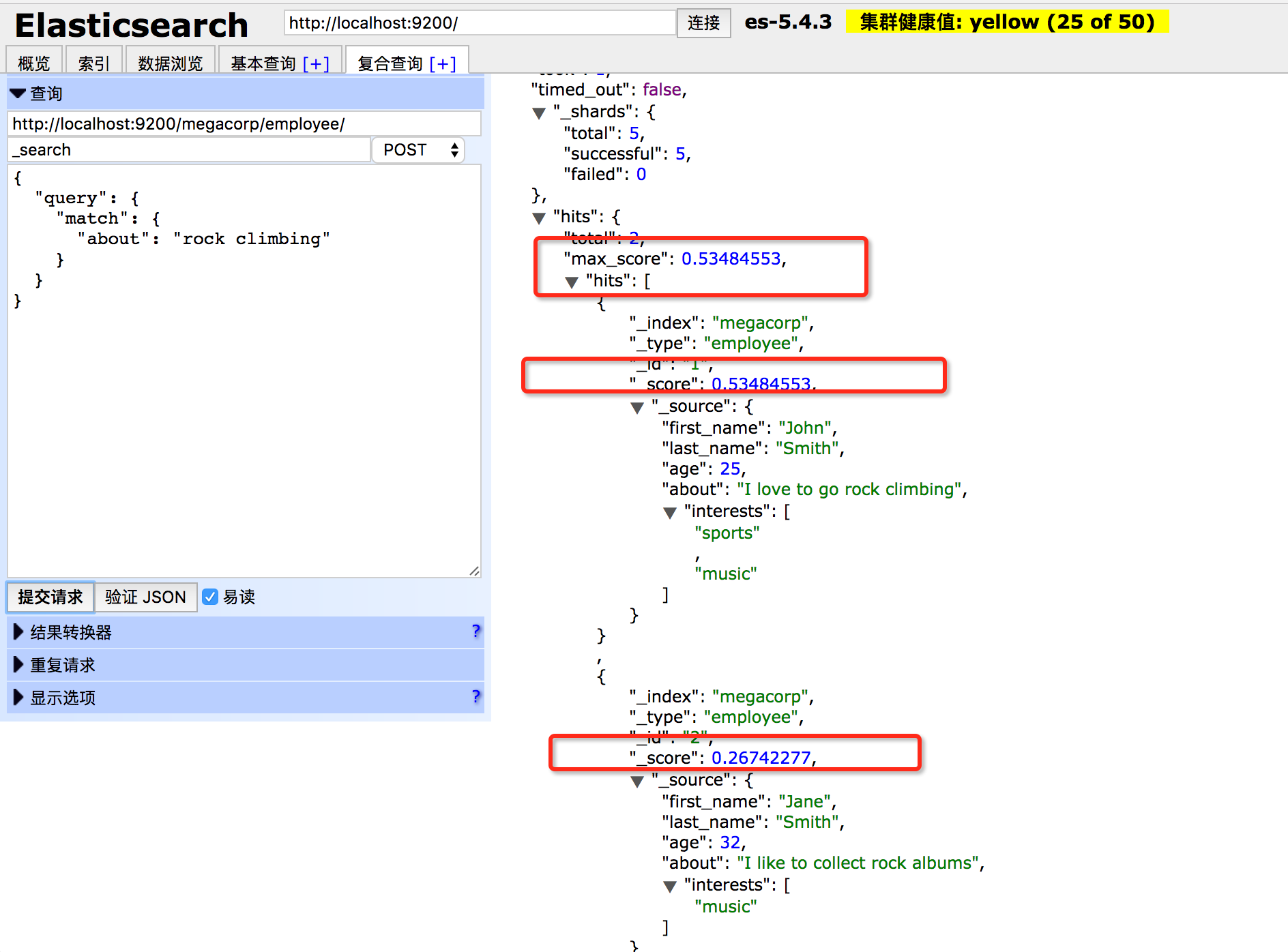
你可以看到我们使用了之前的match查询,从about字段中搜索"rock climbing",我们得到了两个匹配文档.
默认情况下,Elasticsearch根据结果相关性评分来对结果集进行排序,所谓的「结果相关性评分」就是文档与查询条件的匹配程度。很显然,排名第一的John Smith的about字段明确的写到“rock climbing”。
但是为什么Jane Smith也会出现在结果里呢?原因是“rock”在她的abuot字段中被提及了。因为只有“rock”被提及而“climbing”没有,所以她的_score要低于John。
这个例子很好的解释了Elasticsearch如何在各种文本字段中进行全文搜索,并且返回相关性最大的结果集。相关性(relevance)的概念在Elasticsearch中非常重要,而这个概念在传统关系型数据库中是不可想象的,因为传统数据库对记录的查询只有匹配或者不匹配。
短语搜索
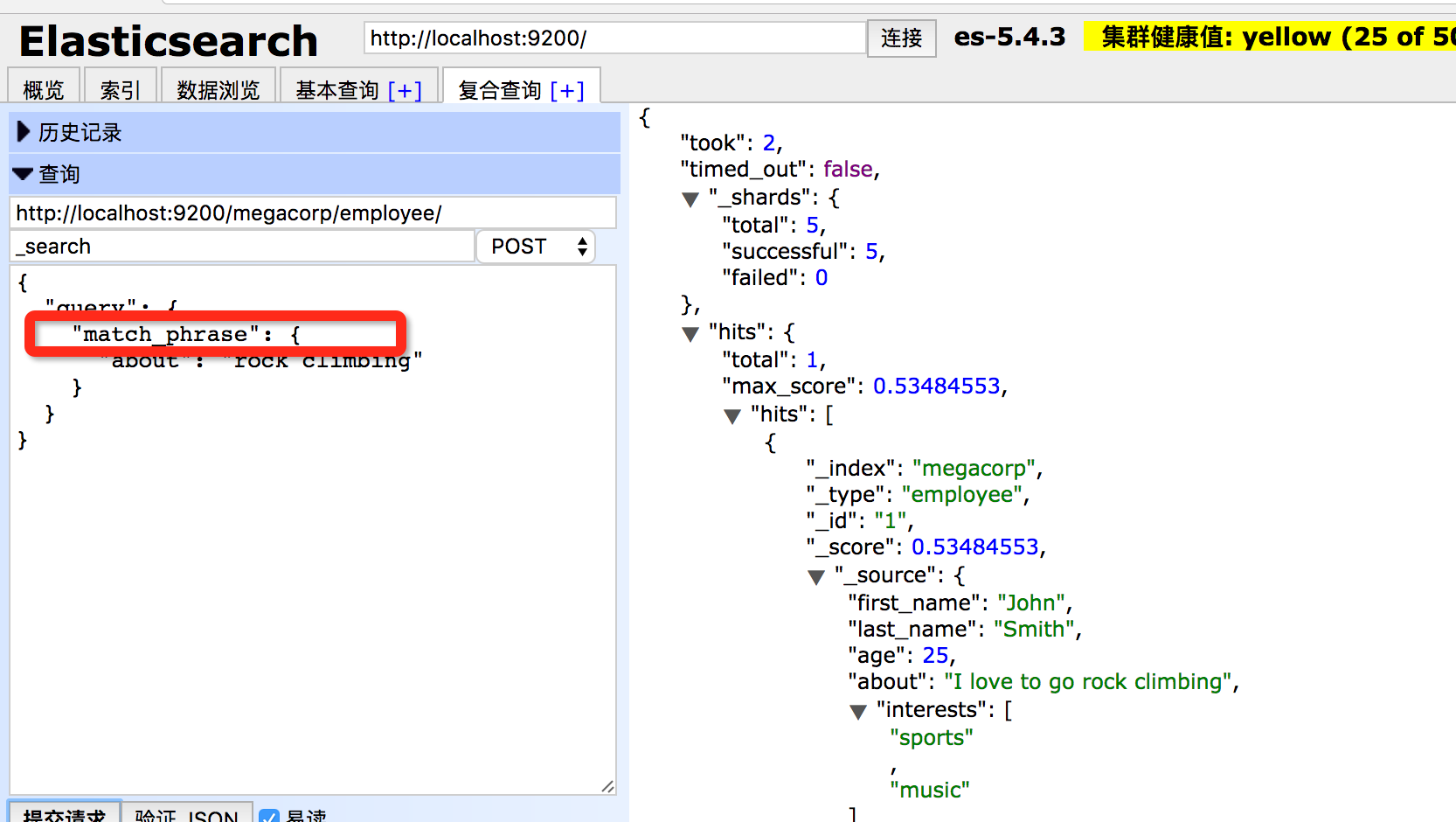
目前我们可以在字段中搜索单独的一个词,这挺好的,但是有时候你想要确切的匹配若干个单词或者短语(phrases)。例如我们想要查询同时包含"rock"和"climbing"(并且是相邻的)的员工记录。
要做到这个,我们只要将match查询变更为match_phrase查询即可:
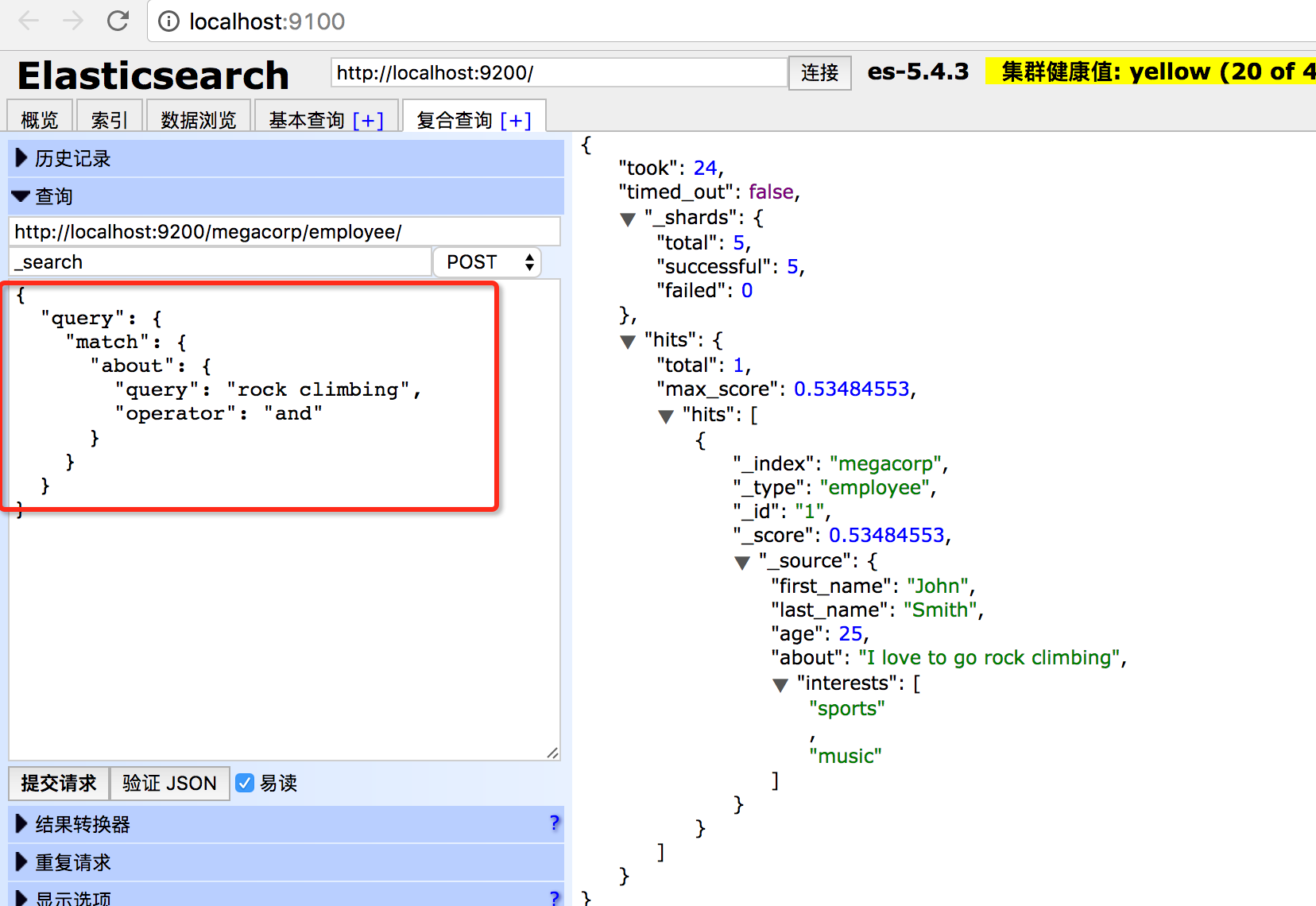
或者这么查询也是可以的:
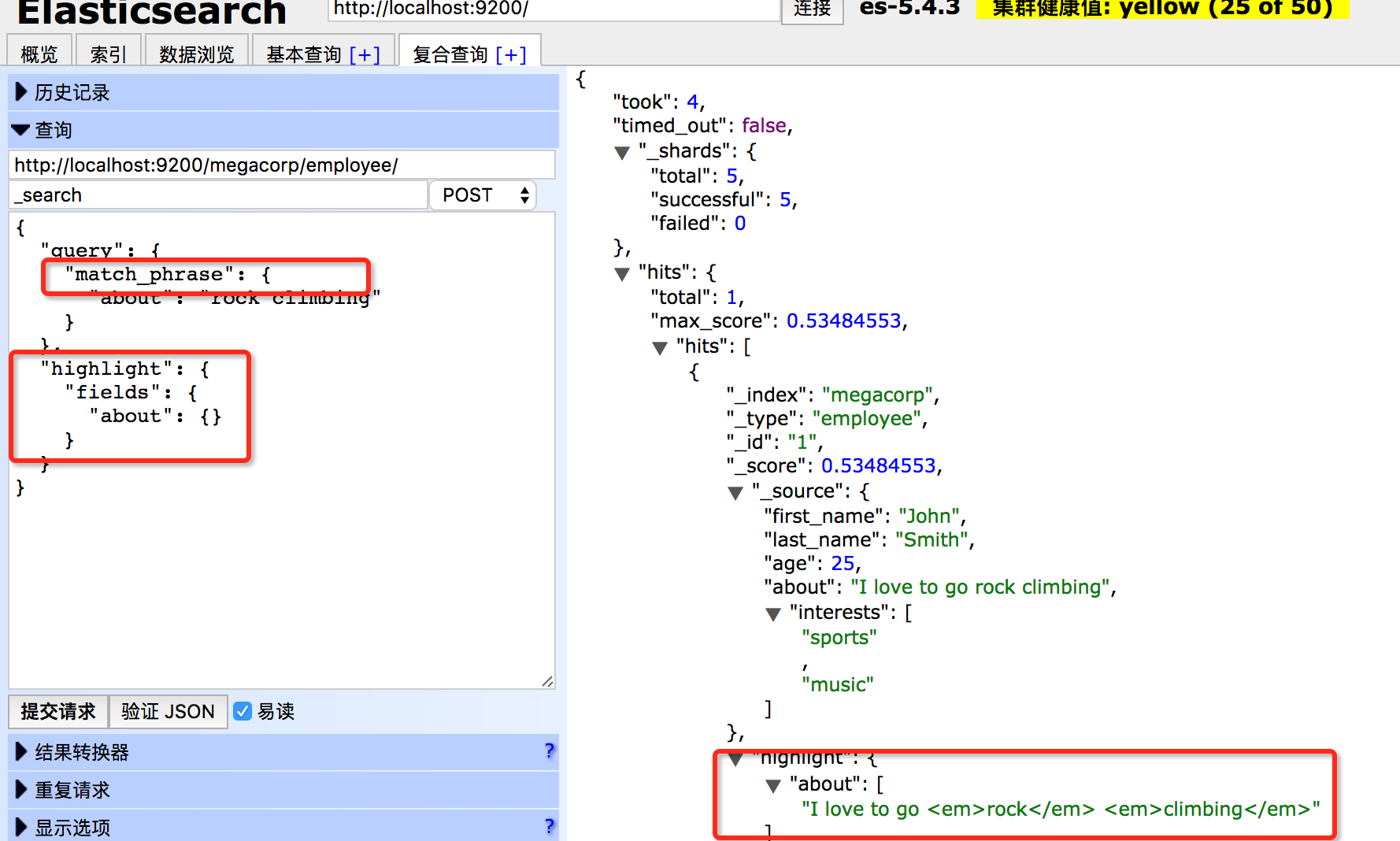
高亮我们的搜索
很多应用喜欢从每个搜索结果中高亮(highlight)匹配到的关键字,这样用户可以知道为什么这些文档和查询相匹配。在Elasticsearch中高亮片段是非常容易的。
让我们在之前的语句上增加highlight参数:
控制精度
在 all 和 any 之间的选择有点过于非黑即白。如果用户指定了5个查询关键字,而一个文档只包含了其中的4个?将'operator'设置为'and'会排除这个文档。
有时这的确是用户想要的结果。但在大多数全文检索的使用场景下,用户想得到相关的文档,排除那些不太可能相关的文档。换句话说,我们需要介于二者之间的选项。
match查询有'minimum_should_match'参数,参数值表示被视为相关的文档必须匹配的关键词个数。参数值可以设为整数,也可以设置为百分数。因为不能提前确定用户输入的查询关键词个数,使用百分数也很合理。
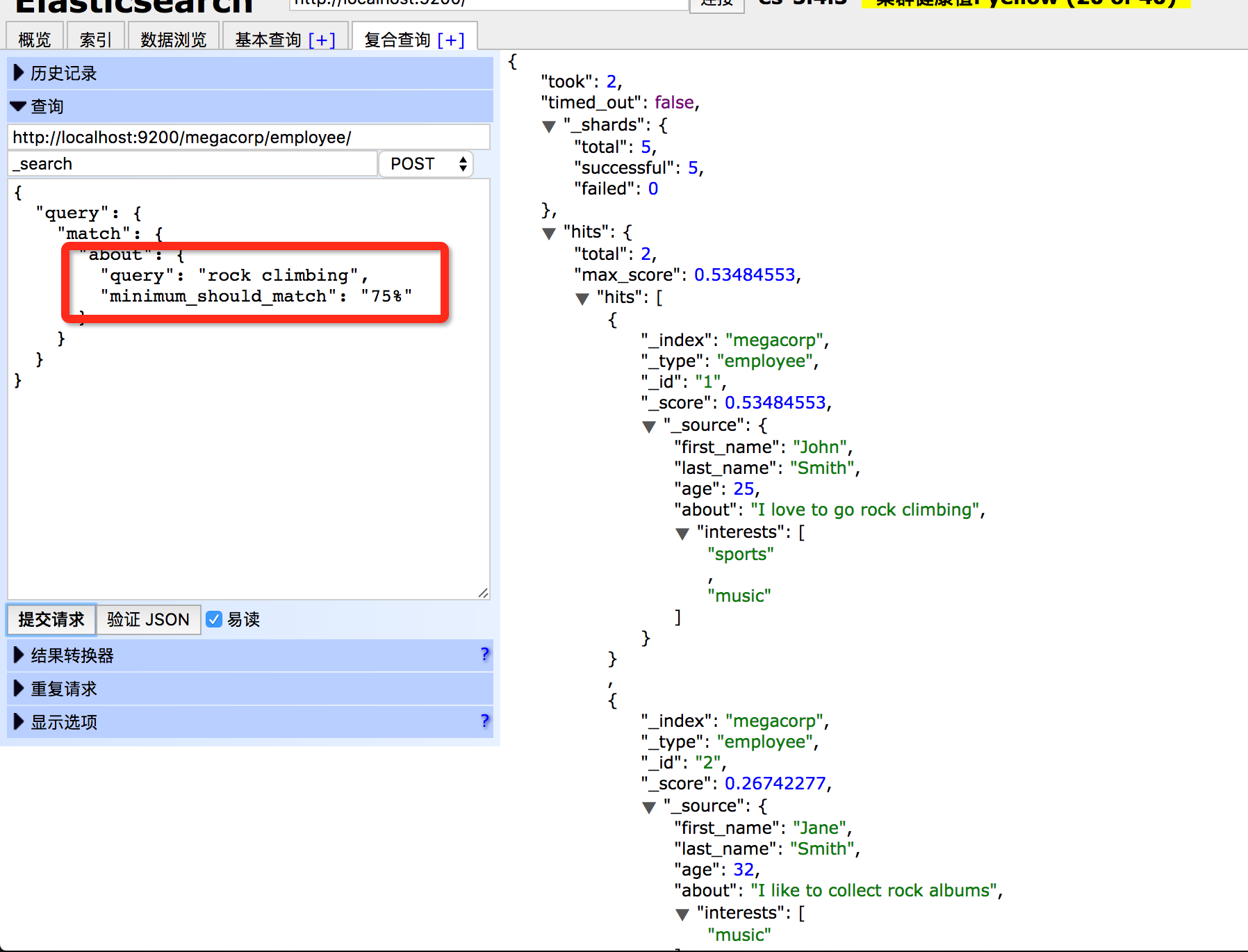
当'minimum_should_match'被设置为百分数时,查询进行如下:在上面的例子里,'75%'会被下舍为'66.6%',也就是2个关键词。不论参数值为多少,进入结果集的文档至少应匹配一个关键词。
[提示]
'minimum_should_match'参数很灵活,根据用户输入的关键词个数,可以采用不同的匹配规则。更详细的内容可以查看文档。
要全面理解match查询是怎样处理多词查询,我们需要了解怎样用bool查询合并多个查询。
组合查询
在《组合过滤》中我们讨论了怎样用布尔过滤器组合多个用and, or, and not逻辑组成的过滤子句,在查询中, 布尔查询充当着相似的作用,但是有一个重要的区别。
过滤器会做一个判断: 是否应该将文档添加到结果集? 然而查询会做更精细的判断. 他们不仅决定一个文档是否要添加到结果集,而且还要计算文档的相关性(relevant).
像过滤器一样, 布尔查询接受多个用must, must_not, and should的查询子句. 例:
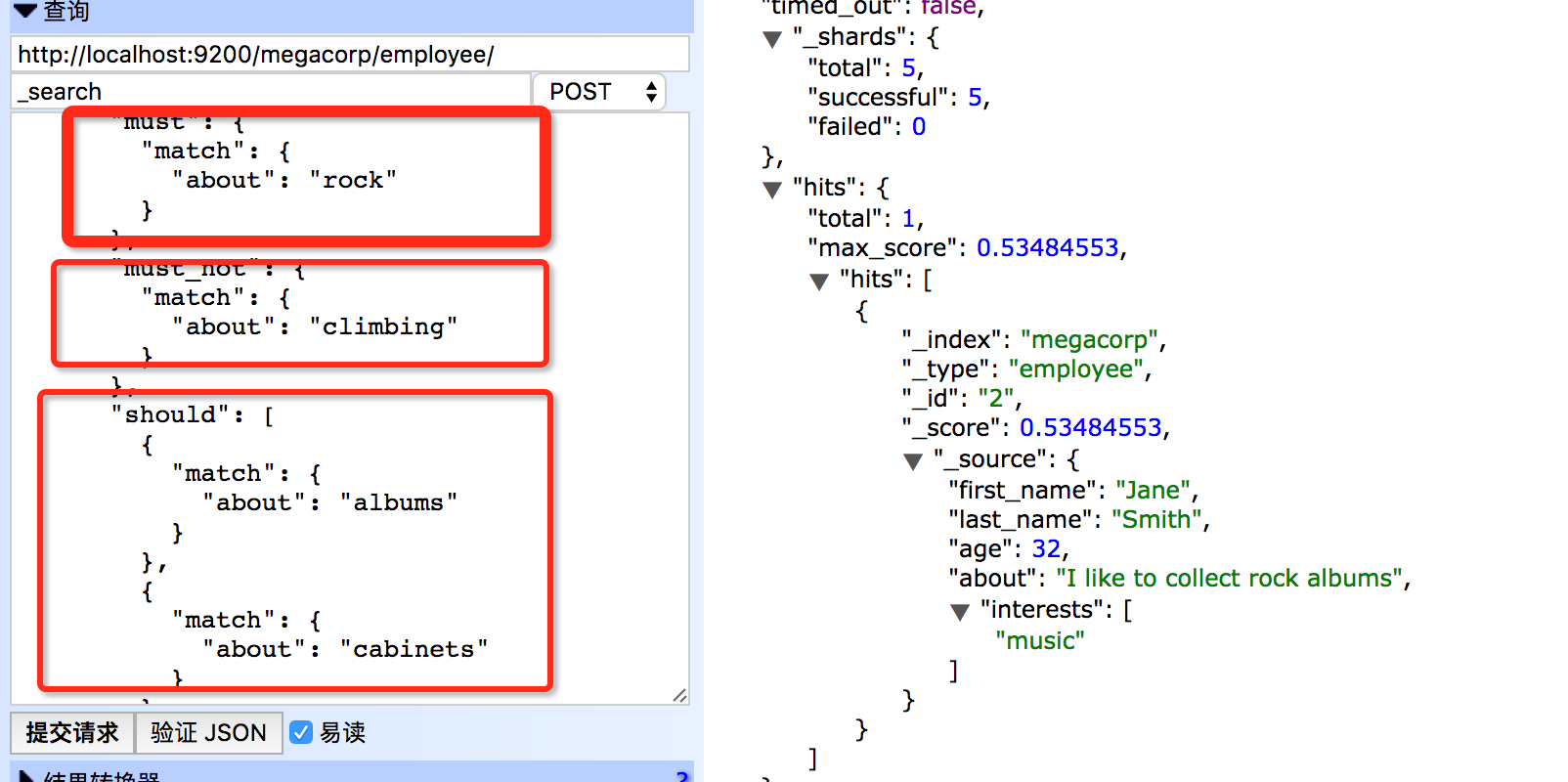
在前面的查询中,凡是满足title字段中包含quick,但是不包含lazy的文档都会在查询结果中。到目前为止,布尔查询的作用非常类似于布尔过滤的作用。
当should过滤器中有两个子句时不同的地方就体现出来了,下面例子就可以体现:一个文档不需要同时包含brown和dog,但如果同时有这两个词,这个文档的相关性就更高
得分计算
布尔查询通过把所有符合must 和 should的子句得分加起来,然后除以must 和 should子句的总数为每个文档计算相关性得分。
must_not子句并不影响得分;他们存在的意义是排除已经被包含的文档。
精度控制
所有的 must 子句必须匹配, 并且所有的 must_not 子句必须不匹配, 但是多少 should 子句应该匹配呢? 默认的,不需要匹配任何 should 子句,一种情况例外:如果没有must子句,就必须至少匹配一个should子句。
像我们控制match查询的精度一样,我们也可以通过minimum_should_match参数控制多少should子句需要被匹配,这个参数可以是正整数,也可以是百分比
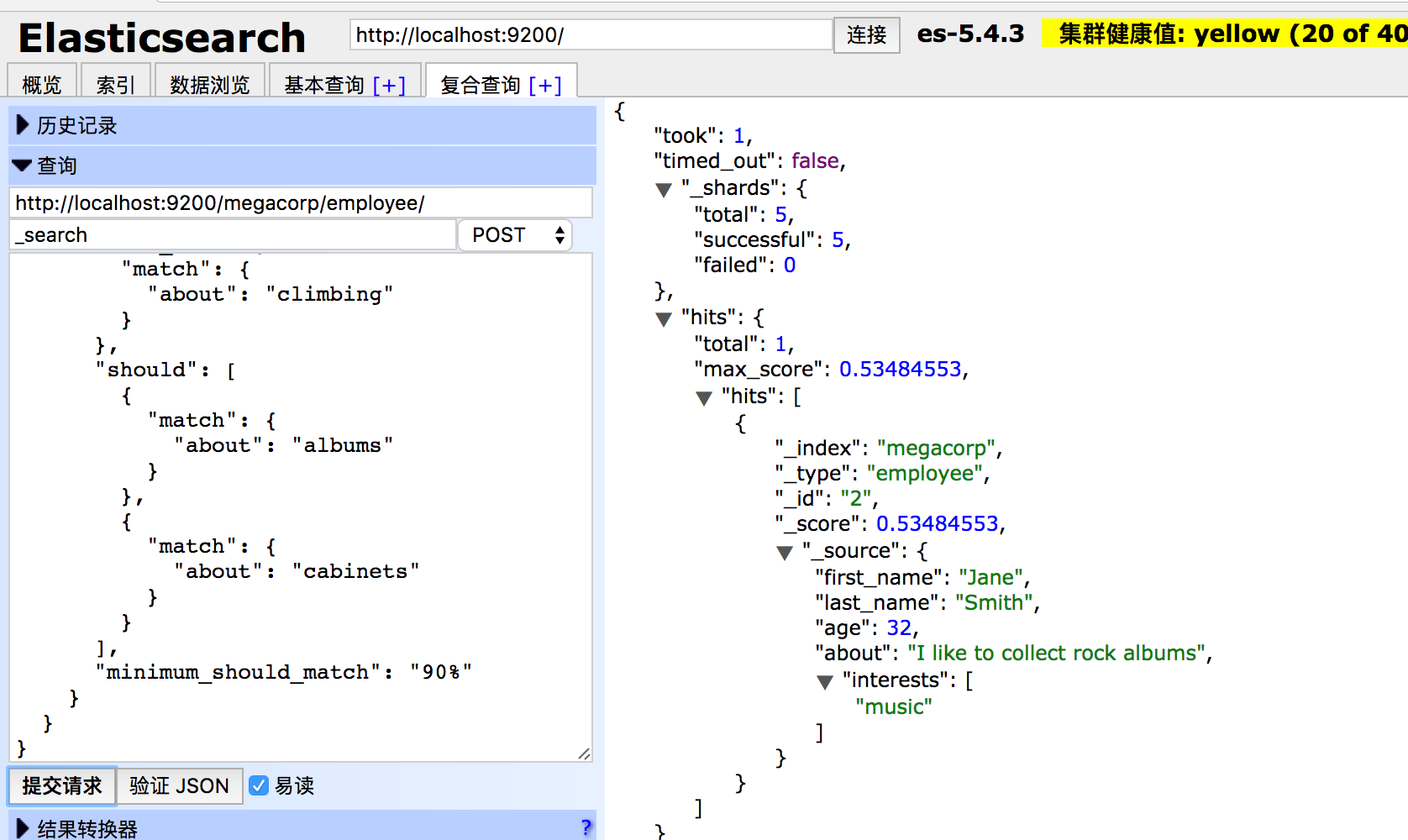
结果集仅包含title字段中有"albums" , "climbing", "cabinets" 。如果一个文档包含上述三个条件,那么它的相关性就会比其他仅包含三者中的两个条件的文档要高。
match匹配怎么当成布尔查询来使用
到现在为止,你可能已经意识到在一个布尔查询中多字段match查询仅仅包裹了已经生成的term查询。通过默认的or操作符,每个term查询都会像一个should子句一样被添加,只要有一个子句匹配就可以了。下面的两个查询是等价的:
{
"match": { "title": "brown fox"}
}
{
"bool": {
"should": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }}
]
}
}
通过and操作符,所有的term查询会像must子句一样被添加,因此所有的子句都必须匹配。下面的两个查询是等价的:
{
"match": {
"title": {
"query": "brown fox",
"operator": "and"
}
}
}
{
"bool": {
"must": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }}
]
}
}
如果minimum_should_match参数被指定,match查询就直接被转换成一个bool查询,下面两个查询是等价的:
{
"match": {
"title": {
"query": "quick brown fox",
"minimum_should_match": "75%"
}
}
}
{
"bool": {
"should": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }},
{ "term": { "title": "quick" }}
],
"minimum_should_match": 2 <1>
}
}
<1>因为只有三个子句,所以 minimum_should_match参数在match查询中的值75%就下舍到了2。3个should子句中至少有两个子句匹配。
当然,我们通常写这些查询类型的时候还是使用match查询的,但是理解match查询在内部是怎么工作的可以让你在任何你需要使用的时候更加得心应手。有些情况仅仅使用一个match查询是不够的,比如给某些查询词更高的权重。这种情况我们会在下一节看个例子。