58.1 互联网
互联网络( internetwork),或更一般地,互联网( internet,小写的 i),会将不同的计算机网络连接起来并允许位于网络中的主机相互之间进行通信。换句话说,一个互联网是由计算机网络组成的一个网络。术语子网络,或子网,用来指组成因特网的其中一个网络。互联网的目标是隐藏不同物理网络的细节以便向互联网络中的所有主机呈现一个统一的网络架构,例如,这意味着可以使用单个地址格式来标识互联网上的所有主机。
尽管已经设计出了多种互联网互联协议,但 TCP/IP 已经成了使用为最广泛的协议套件了,它甚至已经取代了之前在局域网和广域网中常见的私有联网协议了。术语 Internet(大写的 I)被用来指将全球成千上万的计算机连接起来的 TCP/IP 互联网。 图 58-1 给出了一个简单的互联网。在这幅图中,机器 tekapo 是一种路由器,它一台将一个子网络连接到另一个子网络并在它们之间传输数据的计算机。除了需要理解所使用的互联网协议之外,一台路由器还必须要理解它连接的各个子网所使用的(可能)不同的数据链路层协议。 一台路由器拥有多个网络接口,每个接口都连接到一个子网上。更通用的术语“多宿主机”用来指拥有多个网络接口的任意主机——不必是一台路由器。 (另一种描述路由器的方式是说它是将包从一个子网转发到另一个子网的一台多宿主机。 )一个多宿主机的各个接口上的网络地址是不同的(即其连接的各个子网的地址是不同的)。
58.2 联网协议和层
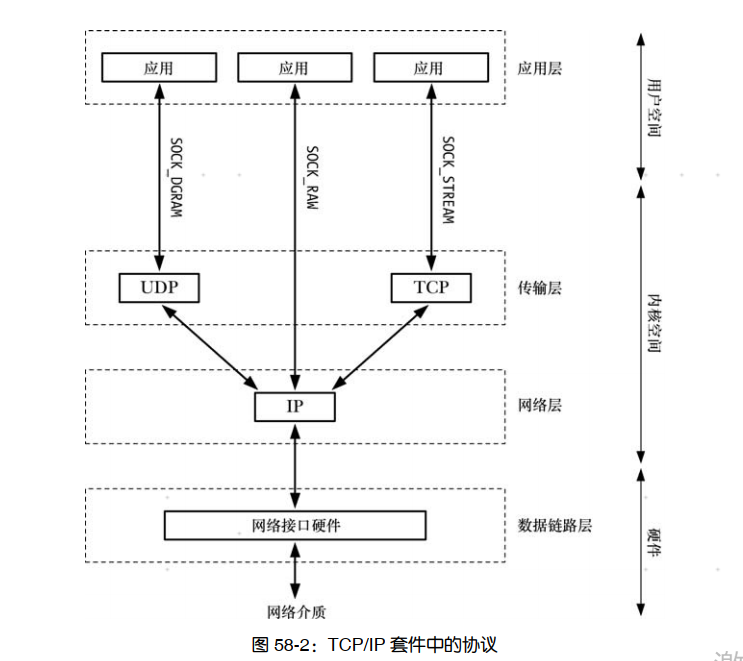
一个联网协议是定义如何在一个网络上传输信息的一组规则。联网协议通常会被组织成一系列的层,其中每一层都构建于下层之上并提供特性以供上层使用。 TCP/IP 协议套件是一个分层联网协议(图 58-2),它包括因特网协议( IP)和位于其上层的各个协议层。(实现这些层的代码通常被称为协议栈。 )名字 TCP/IP 是从传输控制协议( TCP)是使用最为广泛的传输层协议这样一个事实而得出来的。
协议分层如此强大和灵活的其中一个原因是透明——每一个协议层都对上层隐藏下层的操作和复杂性,如一个使用 TCP 的应用程序只需要使用标准的 socket API 并清楚自己正在使用一项可靠的字节流传输服务,而无需理解 TCP 操作的细节。
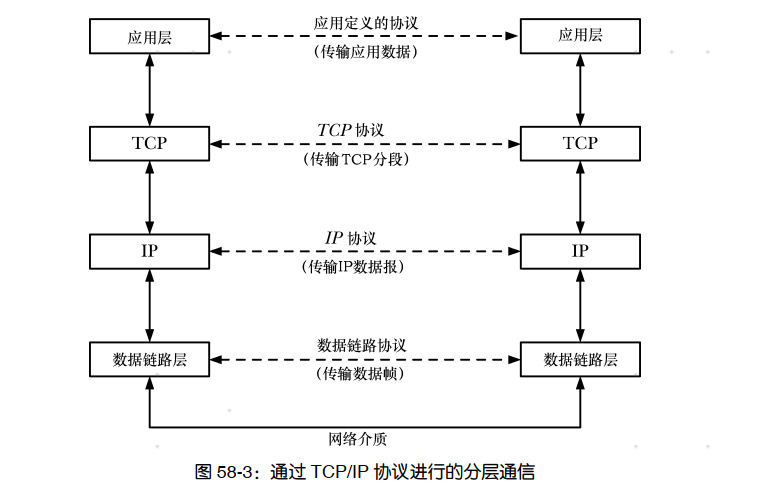
应用程序也无需知道 IP 和数据链路层的操作细节。从应用程序的角度来讲,它就像是通过 socket API 直接与其他层进行通信了,如图 58-3 所示,其中虚横线表示对应应用程序之间的虚拟通信路径以及两个主机上的 TCP 和 IP 实体。
封装
封装是分层联网协议中的一个重要的原则。图 58-4 给出了 TCP/IP 协议层中的封装。封装中的关键概念是低层会将从高层向低层传递的信息(如应用程序数据、 TCP 段、 IP 数据报)当成不透明的数据来处理。换句话说,低层不会尝试对高层发送过来的信息进行解释,而只会将这些信息放到低层所使用的包中并在将这个包向下传递到低层之前添加自身这一层的头信息。当数据从低层传递到高层时将会进行一个逆向的解包过程。

58.3 数据链路层
图 58-2 中的最低层是数据链路层,它由设备驱动和到底层物理媒介(如电话线、同轴电缆、或光纤)的硬件接口(网卡)构成。数据链路层关注的是在一个网络的物理链接上传输数据。 要传输数据,数据链路层需要将网络层传递过来的数据报封装进被称为帧的一个一个单元。除了需要传输的数据之外,每个帧都会包含一个头,如头中可能包含了目标地址和帧的大小。数据链路层在物理链接上传输帧并处理来自接收者的确认。
这一层可能会进行错误检测、重传以及流量控制。一些数据链路层还可能会将大的网络包分割成多个帧并在接收者端对这些帧进行重组。 从应用程序编程的角度来讲通常可以忽略数据链路层,因为所有的通信细节都是由驱动和硬件来处理的。 对于有关 IP 的讨论来讲,数据链路层中比较重要的一个特点是最大传输单元( MTU)。数据链路层的 MTU 是该层所能传输的帧大小的上限。不同的数据链路层的 MTU 是不同的
58.4 网络层: IP
位于数据链路层之上的是网络层,它关注的是如何将包(数据)从源主机发送到目标主机。这一层执行了很多任务,包括以下几个。 1.将数据分解成足够小的片段以便数据链路层进行传输(如有必要的话)。 2.在因特网上路由数据。 3.为传输层提供服务。 在 TCP/IP 协议套件中,网络层的主要协议是 IP。
图 58-2 给出了一个裸 socket( SOCK_RAW),它允许应用程序直接与 IP 层进行通信。这里不会对裸 socket 的使用进行描述,因为大多数应用程序会使用基于其中一种传输层协议(TCP或 UDP)之上的 socket。
IP 传输数据报
IP以数据报(包)的形式来传输数据。在两个主机之间发送的每一个数据报都是在网络上独立传输的,它们经过的路径可能会不同。一个 IP 数据报包含一个头,其大小范围为 20 字节到 60 字节。这个头中包含了目标主机的地址,这样就可以在网络上将这个数据报路由到目标地址了。此外,它还包含了包的源地址,这样接收主机就知道数据报的源头
一个 IP 实现可能会给它所支持的数据报的大小设定一个上限。 所有 IP 实现都必须做到数据报的大小上限至少与规定的 IP 最小重组缓冲区大小( minimum reassembly buffer size)一样大。在 IPv4 中,这个限制值是 576 字节;在 IPv6 中,这个限制值是 1500 字节。
IP 是无连接和不可靠的
IP 是一种无连接协议,因为它并没有在相互连接的两个主机之间提供一个虚拟电路。 IP也是一种不可靠的协议:它尽最大可能将数据报从发送者传输给接收者,但并不保证包到达的顺序会与它们被传输的顺序一致,也不保证包是否重复,甚至都不保证包是否会达到接收者。 IP 也没有提供错误恢复(头信息错误的包会被静默地丢弃)。可靠性是通过使用一个可靠的传输层协议(如 TCP)或应用程序本身来保证的。
IP 可能会对数据报进行分段
IPv4 数据报的最大大小为 65 535 字节。在默认情况下, IPv6 允许一个数据报的最大大小为 65 575 字节( 40 字节用于存放头信息, 65 535 字节用于存放数据),并且为更大的数据报(所谓的 jumbograms)提供了一个选项。 之前曾经提过大多数数据链路层会为数据帧的大小设定一个上限( MTU)。如在常见的以太网架构中这个上限值是 1500 字节(比一个 IP 数据报的最大大小要小得多)。 IP 还定义了路径 MTU 的概念,它是源主机到目的主机之间路由上的所有数据链路层的最小 MTU。 当一个 IP 数据报的大小大于 MTU 时, IP 会将数据报分段(分解)成一个个大小适合在网络上传输的单元。这些分段在达到最终目的地之后会被重组成原始的数据报。(每个 IP 分段本身就是包含了一个偏移量字段的 IP 数据报,该字段给出了一个该分段在原始数据报中的位置。 ) IP 分段的发生对于高层协议层是透明的,并且一般来讲也并不希望发生这种事情。这里的问题在于由于 IP 并不进行重传并且只有在所有分段都达到目的地之后才能对数据报进行组装,因此如果其中一些分段丢失或包含传输错误的话就会导致整个数据报不可用。
在一些情况下,这会导致极高的数据丢失率(适用于不进行重传的高层协议,如 UDP)或降低传输速率(适用于进行重传的高层协议,如 TCP)。现代 TCP 实现采用了一些算法(路径 MTU 发现)来确定主机之间的一条路径的 MTU,并根据该值对传递给 IP 的数据进行分解,这样 IP 就不会碰到需要传输大小超过 MTU 的数据报的情况了。 UDP 并没有提供这种机制,在58.6.2 节中将会考虑基于 UDP 的应用程序如何处理 IP 分段的情况。
58.5 IP 地址
一个 IP 地址包含两个部分: 一个是网络 ID, 它指定了主机所属的网络; 另一个是主机 ID,它标识出了位于该网络中的主机。
IPv4 地址
一个 IPv4 地址包含 32 位(图 58-5)。当以人类可读的形式来表示时,这些地址通常的书写通常采用点分十进制标记法,即将地址的 4 个字节写成一个十进制数字,中间以点号隔开
当一个组织为其主机申请一组 IPv4 地址时, 它会收到一个 32 位的网络地址以及一个对应的 32 位的网络掩码。在二进制形式中,这个掩码最左边的位由 1 构成,掩码中剩余的位用 0填充。这些 1 表示地址中哪些部分包含了所分配到的网络 ID,而这些 0 则表示地址中哪些部分可供组织用来为网络中的主机分配唯一的 ID。 掩码中网络 ID 部分的大小会在分配地址时确定。由于网络 ID 部分总是占据着掩码最左边的部分,因此可以通过下面的标记法来指定分配的地址范围。 这里的/24 表示分配的地址的网络 ID 由最左边的 24 位构成, 剩余的 8 位用于指定主机 ID。或者在这种情况下也可以说网络掩码的点分十进制标记是 255.255.255.0。 拥有这个地址的组织可以将 254 个唯一的因特网地址分配给其计算机——204.152.189.1 到204.152.189.254。有两个地址是无法分配给计算机的,其中一个地址的主机 ID 的位都是 0,它用来标识网络本身,另一个地址的主机 ID 的位都是 1——在本例中是 204.152.189.255——它是子网广播地址。 一些 IPv4 地址拥有特殊的含义。特殊地址 127.0.0.1 一般被定义为回环地址,它通常会被分配给主机名 localhost。(网络 127.0.0.0/8 中的所有地址都可以被指定为 IPv4 回环地址,但通常会选择 127.0.0.1。 )发送到这个地址的数据报实际上不会到达网络,它会自动回环变成发送主机的输入。使用这个地址可以便捷地在同一主机上测试客户端和服务器程序。
在 C 程序中定义了整数常量 INADDR_LOOPBACK 来表示这个程序。
常量 INADDR_ANY 就是所谓的 IPv4 通配地址。通配 IP 地址对于将 Internet domainsocket 绑定到多宿主机上的应用程序来讲是比较有用的。如果位于一台多宿主机上的应用程序只将 socket 绑定到其中一个主机 IP 地址上, 那么该 socket 就只能接收发送到该 IP 地址上的 UDP 数据报和 TCP 连接请求。但一般来讲都希望位于一台多宿主机上的应用程序能够接收指定任意一个主机 IP 地址的数据报和连接请求,而将 socket 绑定到通配 IP 地址上使之成为了可能。 SUSv3 并没有为 INADDR_ANY 规定一个特定的值,但大多数实现将其定义成了0.0.0.0(全是 0)。 一般来讲, IPv4 地址是划分子网的。划分子网将一个 IPv4 地址的主机 ID 部分分成两个部分:一个子网 ID 和一个主机 ID(图 58-6)。
子网划分的原理在于一个组织通常不会将其所有主机接到单个网络中。相反,组织可能会开启一组子网(一个“内部互联网络”),每个子网使用网络 ID 和子网 ID 组合起来标识。这种组合通常被称为扩展网络 ID。在一个子网中,子网掩码所扮演的角色与之前描述的网络掩码的角色是一样的,并且可以使用类似的标记法来表示分配给一个特定子网的地址范围。 例如假设分配到的网络 ID 是 204.152.189.0/24,这样可以通过将主机 ID 的 8 位中的 4 位划分成子网 ID 并将剩余的 4 位划分成主机 ID 来对这个地址范围划分子网。在这种情况下,子网掩码将由 28 个前导 1 后面跟着 4 个 0 构成, ID 为 1 的子网将会被表示为 204.152.189.16/28
IPv6 地址
IPv6 地址的原理与 IPv4 地址是类似的,它们之间关键的差别在于 IPv6 地址由 128 位构成,其中地址中的前面一些位是一个格式前缀,表示地址类型。( IPv6 地址通常被书写成一系列用冒号隔开的 16 位的十六进制数字,如下所示。 IPv6 地址通常包含一个 0 序列,并且为了标记方便,可以使用两个分号( ::)来表示这种序列。因此上面的地址可以被重写成: 在 IPv6 地址中只能出现一个双冒号标记,出现多次的话会造成混淆。 IPv6 也像 IPv4 地址那样提供了环回地址( 127 个 0 后面跟着一个 1,即::1)和通配地址(所有都为 0,可以书写成 0::0 或::)。 为允许 IPv6 应用程序与只支持 IPv4 的主机进行通信, IPv6 提供了所谓的 IPv4 映射的 IPv6地址,图 58-7 给出了这些地址的格式。 图 58-7: IPv4 映射的 IPv6 地址的格式 在书写 IPv4 映射的 IPv6 地址时,地址的 IPv4 部分(即最后 4 个字节)会被书写成 IPv4的 点 分 十 进 制 标 记 。 因 此 与 204.152.189.116 等 价 的 IPv4 映 射 的 IPv6 地 址是::FFFF:204.152.189.116
58.6 传输层
在 TCP/IP 套件中使用广泛的两个传输层协议如下。 1.用户数据报协议( UDP)是数据报 socket 所使用的协议。 2.传输控制协议( TCP)是流 socket 所使用的协议。 在介绍这些协议之前首先需要对两个协议都用到的端口号这个概念进行介绍。
58.6.1 端口号
传输层协议的任务是向位于不同主机(或有时候位于同一主机)上的应用程序提供端到端的通信服务。为完成这个任务,传输层需要采用一种方法来区分一个主机上的应用程序。在 TCP 和 UDP 中,这种区分工作是通过一个 16 位的端口号来完成的
众所周知的、注册的以及特权端口
有些众所周知的端口号已经被永久地分配给特定的应用程序了(也称为服务)。例如 ssh(安全的 shell)daemon 使用众所周知的端口 22, HTTP( Web 服务器和浏览器之间通信时所采用的协议)使用众所周知的端口 80。众所周知的端口的端口号位于 0~1023 之间,它是由中央授权机构互联网号码分配局( IANA)来分配的。一个众所周知的端口号的分配是由一个被核准的网络规范(通常以 RFC 的形式)来规定的。 IANA 还记录着注册端口,将这些端口分配给应用程序开发人员的过程就不那么严格了(这也意味着一个实现无需保证这些端口是否真正用于它们注册时申请的用途)。 IANA 注册的端口范围为 1024~41951。 IANA 众所周知的更新列表和注册端口分配情况可以在 http://www.iana.org/assignments/port-numbers 上找到。 在大多数 TCP/IP 实现(包括 Linux)中,范围在 0 到 1023 间的端口号也是特权端口,这意味着只有特权( CAP_NET_BIND_SERVICE)进程可以绑定到这些端口上,从而防止了普通用户通过实现恶意程序(如伪造 ssh)来获取密码。(有些时候,特权端口也被称为保留端口。 ) 尽管端口号相同的 TCP 和 UDP 端口是不同的实体, 但同一个众所周知的端口号通常会同时被分配给基于 TCP 和 UDP 的服务,即使该服务通常只提供了其中一种协议服务。这种惯例避免了端口号在两个协议中产生混淆的情况。
临时端口
如果一个应用程序没有选择一个特定的端口(即在 socket 术语中, 它没有调用 bind()将其 socket 绑定到一个特定的端口上),那么 TCP 和 UDP 会为该 socket 分配一个唯一的临时端口(即存活时间较短)。在这种情况下,应用程序—通常是一个客户端—并不关心它所使用的端口号,但分配一个端口对于传输层协议标识通信端点来讲是有必要的。这种做法的另一个结果是位于通信信道另一端的对等应用程序就知道如何与这个应用程序通信了。 TCP 和 UDP 在将 socket 绑定到端口 0 上时也会分配一个临时端口号。 IANA 将位于 49152 到 65535 之间的端口称为动态或私有端口, 这表示这些端口可供本地应用程序使用或作为临时端口分配。然后不同的实现可能会在不同的范围内分配临时端口。 在 Linux 上,这个范围是由包含在文件/proc/sys/net/ipv4/ip_local_port_range 中的两个数字来定义的(可通过修改这两个数字来修改范围)。
58.6.2 用户数据报协议( UDP)
UDP 仅仅在 IP 之上添加了两个特性: 端口号和一个进行检测传输数据错误的数据校验和。与 IP 一样, UDP 也是无连接的。由于它并没有在 IP 之上增加可靠性,因此 UDP 是不可靠的。如果一个基于 UDP 的应用程序需要确保可靠性,那么这项功能就必须要在应用程序中予以实现。如果剔除不可靠这个特点的话,在有些时候可能倾向于使用 UDP 而不是 TCP,具体原因可以在 61.12 节中找到
选择一个 UDP 数据报大小以避免 IP 分段
在 58.4 节中描述过 IP 分段机制并指出过通常应该尽可能地避免 IP 分段。 TCP 提供了避免 IP 分段的机制,但 UDP 并没有提供相应的机制。使用 UDP 时如果传输的数据报的大小超过了本地数据链接的 MTU,那么很容易就会导致 IP 分段。 基于 UDP 的应用程序通常不会知道源主机和目的主机之间的路径的 MTU。一般来讲,基于 UDP 的应用程序会采用保守的方法来避免 IP 分段,即确保传输的 IP 数据报的大小小于IPv4 的组装缓冲区大小的最小值 576 字节。(这个值很有可能是小于路径 MTU 的。 )在这 576字节中,有 8 个字节是用于存放 UDP 头的,另外最少需要使用 20 个字节来存放 IP 头,剩下的 548 字节用于存放 UDP 数据报本身。在实践中,很多基于 UDP 的应用程序会选择使用一个更小的值 512 字节来存放数据报。
58.6.3 传输控制协议( TCP)
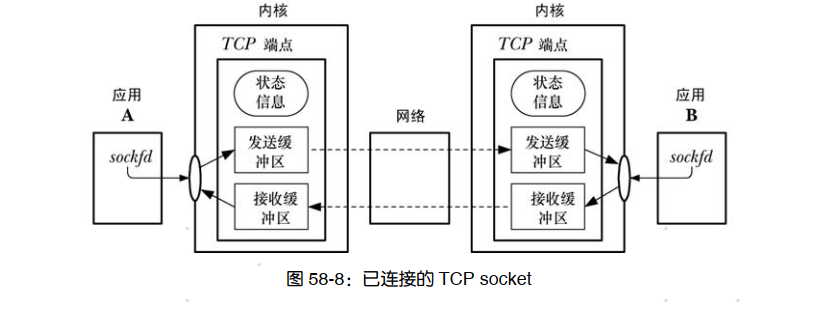
TCP 在两个端点(即应用程序)之间提供了可靠的、面向连接的、双向字节流通信信道,如图 58-8 所示。为提供这些特性, TCP 必须要执行本节中描述的任务。
这里使用术语 TCP 端点来表示 TCP 连接一端的内核所维护的信息。 这部分信息包括连接这一端的发送和接收缓冲区以及维护的用来同步两个已连接的端点的操作的状态信息。在本书余下的部分中将使用术语接收 TCP 和发送 TCP 来表示一个用来在特定方向上传输数据的流 socket 连接两端的接收和发送应用程序。
连接建立
在开始通信之前, TCP 需要在两个端点之间建立一个通信信道。在连接建立期间,发送者和接收者需要交换选项来协商通信的参数。
将数据打包成段
数据会被分解成段,每一个段都包含一个校验和,从而能够检测出端到端的传输错误。每一个段使用单个 IP 数据报来传输。
确认、重传以及超时
当一个 TCP 段无错地达到目的地时,接收 TCP 会向发送者发送一个确认,通知它数据发送递送成功了。如果一个段在到达时是存在错误的,那么这个段就会被丢弃,确认信息也不会被发送。为处理段永远不到达或被丢弃的情况,发送者在发送每一个段时会开启一个定时器。如果在定时器超时之前没有收到确认,那么就会重传这个段。
排序
在 TCP 连接上传输的每一个字节都会分配到一个逻辑序号。这个数字指出了该字节在这个连接的数据流中所处的位置。 (这个连接中的两个流各自都有自己的序号计数系统。 )
当传输一个 TCP 分段时会在其中一个字段中包含这个段的第一个字节的序号。在每一个段中加上一个序号有几个作用。 1.这个序号使得 TCP 分段能够以正确的顺序在目的地进行组装, 然后以字节流的形式传递给应用层。(在任意一个时刻, 在发送者和接收者之间可能存在多个正在传输的 TCP分段,这些分段的到达顺序可能与被发送的顺序可能是不同的。 )
2.由接收者返回给发送者的确认消息可以使用序号来标识出收到了哪个 TCP 分段。
3.接收者可以使用序号来移除重复的分段。发生重复的原因可能是因为 IP 数据段重复,也可能是因为 TCP 自己的重传算法会在一个段的确认丢失或没有按时收到时重传一个成功递送出去的段。
一个流的初始序号( ISN)不是从 0 开始的,相反,它是通过一个算法来生成的,该算法会递增分配给后续 TCP 连接的 ISN。这个算法也使得猜测 ISN 变得困难起来。序号是一个 32 位的值,当到达最大取值时会回到 0。
流量控制
流量控制防止一个快速的发送者将一个慢速的接收者压垮。要实现流量控制,接收 TCP就必须要为进入的数据维护一个缓冲区。(每个 TCP 在连接建立阶段会通告其缓冲区的大小。 ) 当从发送 TCP 端收到数据时会将数据累积在这个缓冲区中,当应用程序读取数据时会从缓冲区中删除数据。在每个确认中,接收者会通知发送者其进入数据缓冲区的可用空间(即发送者可以发送多少字节)。 TCP 流量控制算法采用了所谓的滑动窗口算法,它允许包含总共 N 字节(提供的窗口大小)的未确认段同时在发送者和接收者之间传输。如果接收 TCP 的进入数据缓冲区完全被充满了,那么窗口就会关闭,发送 TCP 就会停止传输数据
拥塞控制:慢启动和拥塞避免算法
TCP 的拥塞控制算法被设计用来防止快速的发送者压垮整个网络。如果一个发送 TCP 发送包的速度要快于一个中间路由器转发的速度,那么该路由器就会开始丢弃包。这将会导致较高的包丢失率,其结果是如果 TCP 保持以相同的速度发送这些被丢弃的分段的话就会极大地降低性能。 TCP 的拥塞控制算法在下列两个场景中是比较重要的。
1.在连接建立之后:此时(或当传输在一个已经空闲了一段时间的连接上恢复时),发送者可以立即向网络中注入尽可能多的分段,只要接收者公告的窗口大小允许即可。(事实上,这就是早期的 TCP 实现的做法。 )这里的问题在于如果网络无法处理这种分段洪泛,那么发送者会存在立即压垮整个网络的风险。
2.当拥塞被检测到时: 如果发送 TCP 检测到发生了拥塞,那么它就必须要降低其传输速率。 TCP 是根据分段丢失来检测是否发生了拥塞,因为传输错误率是非常低的,即如果一个包丢失了,那么就认为发生了拥塞。
TCP 的拥塞控制策略组合采用了两种算法:慢启动和拥塞避免。 慢启动算法会使发送 TCP 在一开始的时候以低速传输分段,但同时允许它以指数级的速度提高其速率,只要这些分段都得到接收 TCP 的确认。慢启动能够防止一个快速的 TCP 发送者压垮整个网络。但如果不加限制的话,慢启动在传输速率上的指数级增长意味着发送者在短时间内就会压垮整个网络。 TCP 的拥塞避免算法用来防止这种情况的发生,它为速率的增长安排了一个管理实体。 有了拥塞避免之后,在连接刚建立时,发送 TCP 会使用一个较小的拥塞窗口,它会限制所能传输的未确认的数据数量。当发送者从对等 TCP 处接收到确认时,拥塞窗口在一开始时会呈现指数级增长。但一旦拥塞窗口增长到一个被认为是接近网络传输容量的阈值时,其增长速度就会变成线性,而不是指数级的。(对网络容量的估算是根据检测到拥塞时的传输速率来计算得出的或者在一开始建立连接时设定为一个固定值。 )
在任何时刻,发送 TCP 传输的数据数量还会受到接收 TCP 的通告窗口和本地的 TCP 发送缓冲器的大小的限制。慢启动和拥塞避免算法组合起来使得发送者可以快速地将传输速度提升至网络的可用容量,并且不会超出该容量。这些算法的作用是允许数据传输快速地到达一个平衡状态,即发送者传输包的速率与它从接收者处接收确认的速率一致。