无论何时,只要执行了系统调用或者库函数,检查调用的返回状态以确定调用是否成功,这是一条编程铁律
3.1 系统调用
系统调用是受控的内核入口,借助于这一机制,进程可以请求内核以自己的名义去执行某些动作。
以应用程序编程接口(API)的形式,内核提供有一系列服务供程序访问。这包括创建新进程、执行 I/O,以及为进程间通信创建管道等
在深入系统调用的运作方式之前,务必关注以下几点。 系统调用将处理器从用户态切换到核心态,以便 CPU 访问受到保护的内核内存。 系统调用的组成是固定的,每个系统调用都由一个唯一的数字来标识。 (程序通过名称来标识系统调用,对这一编号方案往往一无所知。 ) 每个系统调用可辅之以一套参数,对用户空间(亦即进程的虚拟地址空间)与内核空间之间(相互)传递的信息加以规范
1. 应用程序通过调用 C 语言函数库中的外壳( wrapper)函数,来发起系统调用。 2. 对系统调用中断处理例程来说,外壳函数必须保证所有的系统调用参数可用。通过堆栈,这些参数传入外壳函数,但内核却希望将这些参数置入特定寄存器。因此,外壳函数会将上述参数复制到寄存器。 3. 由于所有系统调用进入内核的方式相同,内核需要设法区分每个系统调用。为此,外壳函数会将系统调用编号复制到一个特殊的 CPU 寄存器( %eax)中。 4. 外壳函数执行一条中断机器指令( int 0x80),引发处理器从用户态切换到核心态,并执行系统中断 0x80 (十进制数 128)的中断矢量所指向的代码
5. 为响应中断 0x80,内核会调用 system_call()例程来处理这次中断,具体如下。 a) 在内核栈中保存寄存器值。 b) 审核系统调用编号的有效性。 c) 以系统调用编号对存放所有调用服务例程的列表(内核变量 sys_call_table)进行索引,发现并调用相应的系统调用服务例程。若系统调用服务例程带有参数,那么将首先检查参数的有效性。例如,会检查地址指向用户空间的内存位置是否有效。随后,该服务例程会执行必要的任务,这可能涉及对特定参数中指定地址处的值进行修改,以及在用户内存和内核内存间传递数据。最后,该服务例程会将结果状态返回给 system_call()例程。 d) 从内核栈中恢复各寄存器值,并将系统调用返回值置于栈中。 e) 返回至外壳函数,同时将处理器切换回用户态。 6. 若系统调用服务例程的返回值表明调用有误, 外壳函数会使用该值来设置全局变量 errno。然后,外壳函数会返回到调用程序,并同时返回一个整型值,以表明系统调用是否成功。
3.2 库函数
一个库函数是构成标准 C 语言函数库的众多库函数之一。库函数的用途多种多样,可用来执行以下任务:打开文件、将时间转换为可读格式,以及进行字符串比较等。
许多库函数(比如,字符串操作函数)不会使用任何系统调用。另一方面,还有些库函数构建于系统调用层之上。例如,库函数 fopen()就利用系统调用 open()来执行打开文件的实际操作。往往,设计库函数是为了提供比底层系统调用更为方便的调用接口。例如, printf()函数可提供格式化输出和数据缓存功能,而 write()系统调用只能输出字节块。同理,与底层的 brk()系统调用相比, malloc()和 free()函数还执行了各种登记管理工作,内存的释放和分配也因此而容易许多。
3.3 标准C语言函数库glibc
标准 C 语言函数库的实现随 UNIX 的实现而异。 GNU C 语言函数库(glibc)是 Linux 上最常用的实现
确定系统的glibc版本
find / -name libc.so.6
/lib64/libc.so.6
3.4 处理系统调用和库函数错误
3.4.1 系统调用的失败
系统调用失败时,会将全局整形变量 errno 设置为一个正值,以标识具体的错误。程序应包含<errno.h>头文件,该文件提供了对 errno 的声明,以及一组针对各种错误编号而定义的常量。所有这些符号名都以字母 E 打头。
如果调用系统调用和库函数成功, errno 绝不会被重置为 0,故此,该变量值不为 0,可能是之前调用失败造成的。此外, SUSv3 允许在函数调用成功时,将 errno 设置为非零值。因此,在进行错误检查时,必须坚持首先检查函数的返回值是否表明调用出错,然后再检查 errno 确定错误原因。 少数系统调用(比如, getpriority())在调用成功后,也会返回-1。要判断此类系统调用是否发生错误,应在调用前将 errno 置为 0,并在调用后对其进行检查(上述手法同样适用于某些库函数)。 系统调用失败后,常见的做法之一是根据 errno 值打印错误消息。提供库函数 perror()和strerror(),就是出于这一目的
3.4.2 处理来自库函数的错误
不同的库函数在调用发生错误时,返回的数据类型和值也各不相同。从错误处理的角度来说,可将库函数划分为以下几类。 某些库函数返回错误信息的方式与系统调用完全相同—返回值为-1,伴之以 errno号来表示具体错误。 remove()便是其中一例,可使用该函数来删除文件(调用 unlink()系统调用)或目录(调用 rmdir()系统调用)。对此类函数所发生的错误进行诊断,其方式与系统调用完全相同。 某些库函数在出错时会返回-1 之外的其他值,但仍会设置 errno 来表明具体的出错情况。例如, fopen()在出错时会返回一个 NULL 指针,还会根据出错的具体底层系统调 用来设置 errno。函数 perror()和 strerror()都可用来诊断此类错误。 还有些函数根本不使用 errno。对此类函数来说,确定错误存在与否及其起因的方法各不相同,可见诸于相应函数的手册页中,不应使用 errno、 perror()或 strerror()来诊断错误。
3.5 本书示例程序的注意事项
本节会就本书所载程序示例所普遍采用的各种惯例及特性加以介绍。
3.5.1 命令行选项及参数
本书所载的许多程序示例都会依照命令行选项及参数来决定其行为。 传统的 UNIX 命令行选项由一个连字符( -)、表示选项的英文字母,以及一个可选参数组成。 ( GNU 实用工具则对选项语法有所扩展,以两个连字符开头( --),紧跟用来标识选项和可选参数的字符串。 )可使用标准库函数 getopt()(参见附录 B)对命令行选项进行解析。 这些示例之中,但凡命令行语法颇为周正的,都为用户提供有一个简单的帮助工具:在以--help 选项调用程序时,会显示用法信息,就命令行选项和参数的语法加以说明。
3.5.2 常用的函数及头文件
本书的大多数程序示例都包括有一个头文件,内含常用的各种定义。这些示例同样使用了一系列常用函数。本节会对这些头文件及函数进行讨论。
/** lib/tlpi_hdr.h 常用函数及头文件 */ #ifndef TLPI_HDR_H #define TLPI_HDR_H /* 防止意外的多次引入 */ #include <sys/types.h> /* 类型定义 */ #include <stdio.h> /* 标准IO */ #include <stdlib.h> /* 常用库函数原型,包括EXIT_SUCCESS、EXIT_FAILURE常量 */ #include <unistd.h> /* 系统调用原型 */ #include <errno.h> /* 声明errno,并定义错误常量 */ #include <string.h> /* 常用字符串方法 */ #include <stdbool.h> /* bool类型加true、false常量 */ #include "get_num.h" /* 声明了用于处理数字的函数,如getInt()、getLong() */ #include "error_functions.h" /* 声明了错误处理函数 */ /* 如果某些UNIX已经定义了TRUE、FALSE,需要取消它的定义*/ #ifdef TRUE #undef TRUE #endif #ifdef FALSE #undef FALSE #endif /* 定义Boolean类型 */ typedef enum { FALSE, TRUE } Boolean; /* 定义min、max方法 */ #define min(m,n) ((m) < (n) ? (m) : (n)) #define max(m,n) ((m) > (n) ? (m) : (n))
函数errMsg()会在标准错误设备上打印消息。 除了将一个终止换行符自动追加到输出字符串尾部以外,该函数的参数列表与 printf()所用相同。 errMsg()函数会打印出与当前 errno 值相对应的错误文本,其中包括了错误名(比如, EPERM)以及由 strerror()返回的错误描述,外加由参数列表指定的格式化输出。
函数errExit()函数的操作方式与 errMsg()相似,只是还会以如下两种方式之一来终止程序。其一,调用 exit()退出。其二,若将环境变量 EF_DUMPCORE 定义为非空字符串,则调用 abort()退出,同时 生成核心转储(core dump文件,供调试器调试之用。
函数 err_exit()类似于 errExit(),但存在两方面的差异。打印错误消息之前, err_exit()不会刷新标准输出。err_exit()避免了对子进程继承自父进程(即调用进程)的 stdio缓冲区副本进行刷新,且不会调用由父进程所建立的退出处理程序。
函数errExitEN()函数与 errExit()大体相同,区别仅仅在于:与 errExit()打印与当前errno 值相对应的错误文本不同, errExitEN()只会打印与 errnum 参数中给定的错误号相对应的文本。
函数 fatal()用来诊断一般性错误,其中包括未设置 errno的库函数错误。除了将一个终止换行符自动追加到输出字符串尾部以外,fatal()的参数列表与 printf()基本相同。该函数会在标准错误上打印格式化输出,然后,像errExit()那样终止程序。
函数 usageErr()
long getLong(const char *arg, int flags, const char *name); int getInt(const char *arg, int flags, const char *name);
static long getNum(const char *fname, const char *arg, int flags, const char *name) { long res; char *endptr; int base; if (arg == NULL || *arg == '�') gnFail(fname, "null or empty string", arg, name); /** * 这个地方比较难懂,解读一下,三个常量的定义如下: * #define GN_ANY_BASE 0100 * #define GN_BASE_8 0200 * #define GN_BASE_16 0400 * 都是八进制,按位与自己得到的还是自己,因此如果 * flags=GN_ANY_BASE,base=0 * flags=GN_BASE_8 ,base=8 * flags=GN_BASE_16 ,base=16 * 以上所有都不是,base=10 * strtol()函数base=0或10的时候按照10进制处理,base=8按照8进制,base=16按照十六进制 */ base = (flags & GN_ANY_BASE) ? 0 : (flags & GN_BASE_8) ? 8 : (flags & GN_BASE_16) ? 16 : 10; errno = 0; res = strtol(arg, &endptr, base); if (errno != 0) gnFail(fname, "strtol() failed", arg, name); if (*endptr != '�') gnFail(fname, "nonnumeric characters", arg, name); if ((flags & GN_NONNEG) && res < 0) gnFail(fname, "negative value not allowed", arg, name); if ((flags & GN_GT_0) && res <= 0) gnFail(fname, "value must be > 0", arg, name); return res; } /* 将字符串转Long类型 */ long getLong(const char *arg, int flags, const char *name) { return getNum("getLong", arg, flags, name); } /* 将字符串转换为Int类型. */ int getInt(const char *arg, int flags, const char *name) { long res; res = getNum("getInt", arg, flags, name); if (res > INT_MAX || res < INT_MIN) gnFail("getInt", "integer out of range", arg, name); return (int) res; }
3.6 可移植性问题
3.6.1 特性测试宏
系统调用和库函数 API 的行为受各种标准的制约
编写可移植性应用程序时,有时会希望各个头文件只显露遵循特定标准的定义(常量、函数原型等)。要达到这一目的,在编译程序时需要定义下列一个或多个特性测试宏。方式之一是在程序源码包含1任何头文件之前,定义如下宏
define _BSD_SOURCE 1
BSD_SOURCE 一经定义,开启对 BSD 定义的支持。此外,只要定义了该宏,便以值 199506 定义了POSIX_C_SOURCE。极少数的情况下,当标准之间发生冲突时,显式设置该宏会导致系统向 BSD 定义倾斜
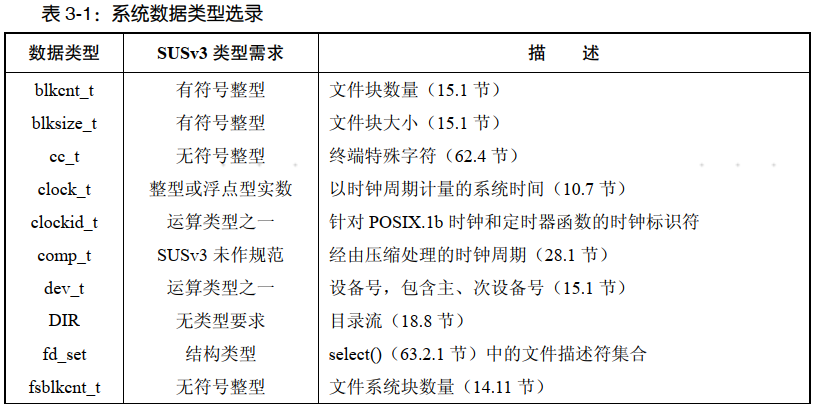
3.6.2 系统数据类型
SUSv3 规范了各种标准系统数据类型,并要求各个实现适当加以定义和使用。每种类型的定义均使用 C 语言的 typedef 特性。例如, pid_t 数据类型用以表示进程 ID,在 Linux/x86-32 上,其类型定义如下:
typedef int pid_t;
标准系统数据类型中的大多数,其命名均以_t 结尾。其中的许多都声明于头文件<sys/types.h>中,余下的少量则定义于其他头文件中。 应用程序应采用这些类型定义来声明其使用的变量,才能保证可移植性。例如,如下声明将允许应用程序在任何符合 SUSv3 标准的系统上正确表示进程 ID。
pid_t mypid;