什么是缓存(cache):
在项目中没有必要每次请求都查询数据库的情况就可以使用缓存,让每次请求先查询缓存,如果命中,就直接返回缓存结果,如果没有命中,就查询数据库, 并将查询结果放入缓存,下次请求时查询缓存命中,直接返回结果,就不用再次查询数据库。
缓存的作用?
缓和较慢存储的高频请求,缓解数据库压力,提升响应速率。
为什么缓存可以提高响应速度?
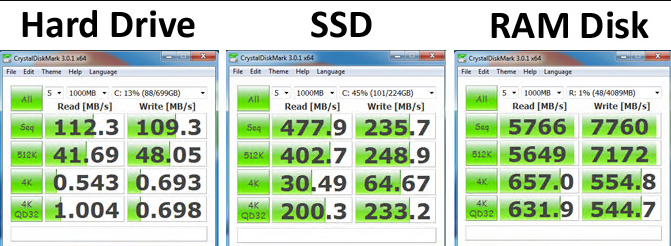
因为缓存时基于内存的存储的,内存的读写速率是普通SSD硬盘的至少十倍,更何况机械硬盘了:看对比图
缓存介质?
web项目中常用的缓存是memcached和redis,它们都支持分布式存储
缓存一定能给项目响应速率带来较大提升吗?
答案是不见得,要根据项目实际情况分析,有没有使用缓存的不要。在考虑使用缓存前,不妨先问问自己:
1. 项目的读写操作比例为多少,如果是写多读少,那缓存真的不一定能帮助你,此时不妨考虑数据库分库分表,然后做MySQL的分布式集群,或者简单直接,将硬盘全部替换为SSD(如果你的公司财大气粗),反之,以读为主的项目就比较适合加缓存了
2. 项目的访问频率高不高(用户多不多)?如果用户区区几千人或几万人,全然没有必要使用缓存,这点访问量经过网络后几乎不会造成并发,即使偶出现几万的并发,MySQL也是扛得住的,强行使用缓存反而会增加代码复杂度,甚至不容易维护,得不偿失。
3. 数据是否要求强一致性?如果项目涉及到金钱或者重要数据,且数据频繁发生变化,不允许存在一点差异,那是否使用缓存就要慎重慎重再慎重!因为缓存适用的是对数据一致性不是特别高的项目,如果使用,需要对缓存的设计有很好的方案,非常考验技术功底
说了这么多,进入正题吧,我们通过代码来模拟一下缓存的使用:
redis版本:
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 import functools 4 import redis 5 import time 6 import json 7 """ 8 使用redis做缓存,这里模拟一个web接口缓存的例子 9 """ 10 11 # 这里使用redis连接池,管理redisservice的所有连接,避免每次创建关闭连接的开销 12 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) 13 redis_cli = redis.Redis(connection_pool=pool) 14 15 def redis_cache(func): 16 @functools.wraps(func) # 为了保留原函数的属性,因为被装饰的函数对外暴露的是装饰器的属性 17 def wrapper(*args,**kargs): 18 start_time = time.time() 19 _key = 'function-name:{},args:{},kargs:{}'.format(func.__name__,args,kargs) #定义key的形式:函数名加与参数组成唯一的key 20 result = redis_cli.get(_key) 21 if result: # redis查找到对应的key,直接返回结果 22 result = json.loads(result) 23 print(type(result)) 24 print('redis find:{},result:{}'.format(_key,result)) 25 else: # redis没有查找到对应key,查询执行函数,查询mysql 26 print('redis not find:{}'.format(_key)) 27 result = func(*args,**kargs) 28 redis_cli.setex(_key,json.dumps(result),5) #将mysql结果写入redis,并设置过期时间 单位s 29 print("final result:{}".format(result)) 30 end_time = time.time()-start_time 31 print("Total time of this query:{}".format(end_time)) 32 return result 33 return wrapper 34 35 36 @redis_cache 37 def mysql_dispose(name,age): 38 time.sleep(2) 39 result = {'name:':name,'age':age} 40 print('mysql-result:{}'.format(result)) 41 return(result) 42 43 44 if __name__ == '__main__': 45 mysql_dispose('zz3',45) 46 47 48 out-put>>>: 49 第一次执行: 50 redis not find:function-name:mysql_dispose,args:('zz3', 45),kargs:{} 51 mysql-result:{'name:': 'zz3', 'age': 45} 52 final result:{'name:': 'zz3', 'age': 45} 53 Total time of this query:2.0049448013305664 54 55 第二次执行(距第一次5秒内执行): 56 <class 'dict'> 57 redis find:function-name:mysql_dispose,args:('zz3', 45),kargs:{},result:{'name:': 'zz3', 'age': 45} 58 Total time of this query:0.005013942718505859 59 60 第三次执行(5秒后)因为redis key过期被删除,所以无法命中,请求会再次查询数据库,然后添加缓存: 61 redis not find:function-name:mysql_dispose,args:('zz3', 45),kargs:{} 62 mysql-result:{'name:': 'zz3', 'age': 45} 63 final result:{'name:': 'zz3', 'age': 45} 64 Total time of this query:2.0038458017378002
不难看出,原本需要2秒才能完成的数据库查询动作,再有了redis缓存后可以直接返回结果,提高了响应速率
memcached版本(与上面代码大同小异,但是会有坑,注意红色标记部分)
#!/usr/bin/python # -*- coding: UTF-8 -*- import functools #要使用这个库,需要先安装:pip install Python-memcached import memcacheimport time import json """ 使用memcache做缓存,这里模拟一个web接口缓存的例子 """ # 连接到memcached服务器 conn = memcache.Client(['localhost:11211']) def redis_cache(func): @functools.wraps(func) # 为了保留原函数的属性,因为被装饰的函数对外暴露的是装饰器的属性 def wrapper(*args,**kargs): start_time = time.time() _key = 'function-name:{},args:{},kargs:{}'.format(func.__name__,args,kargs) #定义key的形式 result = conn.get(_key) if result: # memcached查找到对应的key,直接返回结果 result = json.loads(result) print(type(result)) print('memcached find:{},result:{}'.format(_key,result)) else: # memcached没有查找到对应key,查询执行函数,查询mysql print('memcached not find:{}'.format(_key)) result = func(*args,**kargs) conn.set(_key,json.dumps(result),5) #将mysql结果写入memcached,并设置过期时间 单位s print("final result:{}".format(result)) end_time = time.time()-start_time print("Total time of this query:{}".format(end_time)) return result return wrapper @redis_cache def mysql_dispose(name,age): time.sleep(2) result = {'name:':name,'age':age} print('mysql-result:{}'.format(result)) return(result) if __name__ == '__main__': mysql_dispose('zz3',45)
当我将redis换为memcache后,运行发现居然报错了!:
Traceback (most recent call last): File "memcache_cache.py", line 50, in <module> mysql_dispose('zz3',45) File "memcache_cache.py", line 25, in wrapper result = conn.get(_key) File "C:Userssys_syscafhostAppDataLocalProgramsPythonPython36libsite-packagesmemcache.py", line 888, in get return self._get('get', key) File "C:Userssys_syscafhostAppDataLocalProgramsPythonPython36libsite-packagesmemcache.py", line 837, in _get self.check_key(key) File "C:Userssys_syscafhostAppDataLocalProgramsPythonPython36libsite-packagesmemcache.py", line 1053, in check_key "Control characters not allowed") memcache.MemcachedKeyCharacterError: Control characters not allowed
说明我们的key有空格字符,what?redis版本中一点问题没有,这里却说不允许,先打印出来看看:
_key : function-name:mysql_dispose,args:('zz3', 45),kargs:{}
原来是'zz3',和45之间有空格,'所以大家要注意,memcached key不能包含空格,但是这是python args自动解析填写的,怎么办?
算了,一种是对_key处理,去掉空格,但是感觉麻烦且别扭,索性取_keyde MD5的结果,这里用到标准库:hashlib
代码修改后为:
#!/usr/bin/python # -*- coding: UTF-8 -*- import functools #要使用这个库,需要先安装:pip install Python-memcached import memcache import hashlib import time import json """ 使用memcache做缓存,这里模拟一个web接口缓存的例子 """ # 连接到memcached服务器 conn = memcache.Client(['localhost:11211']) def redis_cache(func): @functools.wraps(func) # 为了保留原函数的属性,因为被装饰的函数对外暴露的是装饰器的属性 def wrapper(*args,**kargs): start_time = time.time() key = 'function-name:{},args:{},kargs:{}'.format(func.__name__,args,kargs) #定义key的形式 hash_obj = hashlib.md5() hash_obj.update(key.encode(encoding='utf-8')) _key_hash = hash_obj.hexdigest() result = conn.get(_key_hash) if result: # memcached查找到对应的key,直接返回结果 result = json.loads(result) print(type(result)) print('memcached find:{},result:{}'.format(_key_hash,result)) else: # memcached没有查找到对应key,查询执行函数,查询mysql print('memcached not find:{}'.format(_key_hash)) result = func(*args,**kargs) conn.set(_key_hash,json.dumps(result),5) #将mysql结果写入memcached,并设置过期时间 单位s print("final result:{}".format(result)) end_time = time.time()-start_time print("Total time of this query:{}".format(end_time)) return result return wrapper @redis_cache def mysql_dispose(name,age): time.sleep(2) result = {'name:':name,'age':age} print('mysql-result:{}'.format(result)) return(result) if __name__ == '__main__': mysql_dispose('zz3',45)
#这下正常运行了,output>>>
第一次运行:
memcached not find:1477b8c668df1f570293f4c374963638
mysql-result:{'name:': 'zz3', 'age': 45}
final result:{'name:': 'zz3', 'age': 45}
Total time of this query:2.005075693130493
第二次运行(5s内):
<class 'dict'>
memcached find:1477b8c668df1f570293f4c374963638,result:{'name:': 'zz3', 'age': 45}
final result:{'name:': 'zz3', 'age': 45}
Total time of this query:0.004010915756225586
第三次(5s后):
memcached not find:1477b8c668df1f570293f4c374963638
mysql-result:{'name:': 'zz3', 'age': 45}
final result:{'name:': 'zz3', 'age': 45}
Total time of this query:2.015402317047119
接下来就是项目中使用缓存不得不考虑的问题了,也是缓存的三大问题:
1.缓存穿透,
2.缓存过期(击穿),
3.缓存雪崩
这里用一张表(students)做描述:
s_id, s_name, s_birth, s_sex
01赵雷1990-01-01男
02钱电1990-12-21男
03孙风1990-05-20男
04李云1990-08-06男
05周梅1991-12-01女
06吴兰1992-03-01女
07郑竹1989-07-01女
08王菊1990-01-20女
缓存穿透:
也就是指查询目标不在缓存,也不在数据库中存在:比如:某个用户请求查询name=‘夏雨’的记录:
先会在redis cache中查找,没有值,再查数据库中也找不到结果,这就造成了数据会穿透redis cache而每次命中mysql
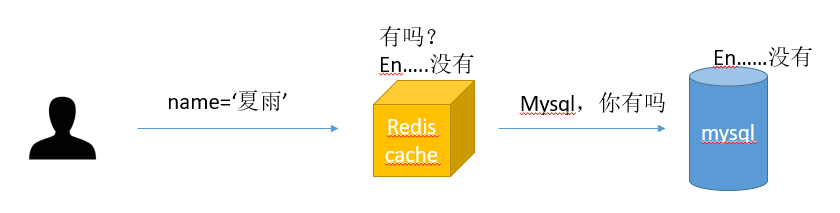
试想:如果有用户恶意攻击怎么办?故意发起10W次并发请求怎么办?所有的请求都会穿过redis cache而次次命中mysql,对mysql造成了非常大的压力,甚至可能会出现宕机.
怎么办呢?一般来说,两种处理方式:
1. redis cache缓存空数据,也就是,即使mysql未查询到结果,也将这个请求与参数保存在redis,key=xxxxxxnameis夏雨,vaule=None,下次同样的请求直接redis返回None,不再查询数据库
这样的方法比较挫,因为虽然省事,但是势必会在缓存中增加很多无用的信息,这种时间最好设置key的过期时间,使无用的key在一段短时间内自动删除,当然,这种方法适用于无效key较少的情况使用
2. 使用BloomFilter(布隆过滤器)
需要在redis cache之前再加一层,
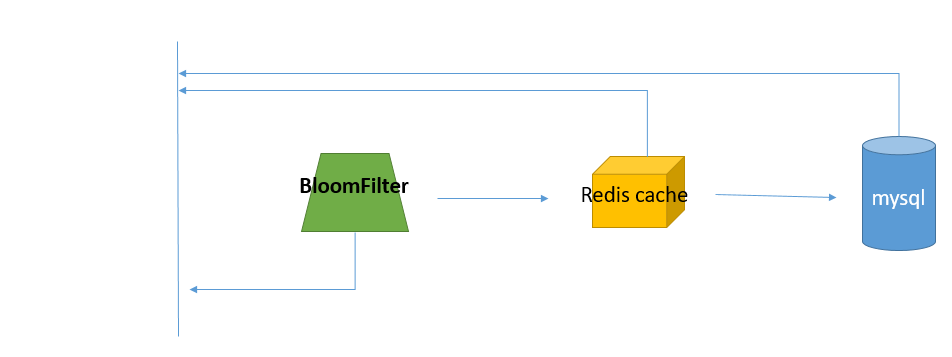
当name=‘夏雨’的请求再次要求查询时,先查询BloomFilter中key是否存在,不存在就直接返回none,存在,再走redis查询
缓存过期:
我们在设置缓存的key--value时,会设置一个过期时间,再有效期内,大量的查询都会被redis拦截处理,并返回结果,但是,当大量请求持续查询redis某个key时比如name=‘赵雷’,正好redis的这个key到了过期时间,被自动删除了,那redis查不到了,大量的查询请求就会到mysql这边,而mysql给第一次请求查询时用了2秒才返回,并写入redis cache,那这2秒之内,redis还未重新更新数据,剩下的大量查询还时指向了mysql,造成mysql的IO阻塞,数据库可能宕机.,且这些查询mysql后会重复写redis。
解决方法:
1. 业务逻辑控制>>>从缓存拿数据时获取剩余剩余有效时间,如果小于1s,就重新设置有效时间,流程和代码如下:
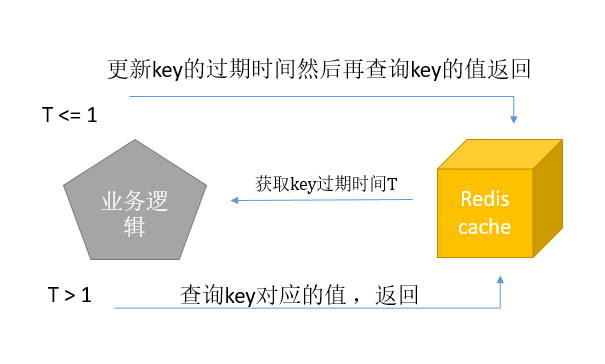
代码:我们对上述代码做一个简单修改:
def redis_cache(func): @functools.wraps(func) # 为了保留原函数的属性,因为被装饰的函数对外暴露的是装饰器的属性 def wrapper(*args,**kargs): start_time = time.time() _key = 'function-name:{},args:{},kargs:{}'.format(func.__name__,args,kargs) #定义key的形式 period_time = redis_cli.ttl(_key) if period_time: # 获取key的过期时间,如果key不存在,redis存储器会返回-2,我们python redis库封装后返回None if period_time <= 1: redis_cli.expire(_key,5) result = redis_cli.get(_key) # redis查找到对应的key,直接返回结果 result = json.loads(result) print(type(result)) print('redis find:{},result:{}'.format(_key,result)) else: # redis没有查找到对应key,查询执行函数,查询mysql print('redis not find:{}'.format(_key)) result = func(*args,**kargs) redis_cli.setex(_key,json.dumps(result),5) #将mysql结果写入redis,并设置过期时间 单位s print("final result:{}".format(result)) end_time = time.time()-start_time print("Total time of this query:{}".format(end_time)) return result return wrapper
2. 加锁
对于key失效的情况,如果有100个请求同时要求查询:第一个请求发现缓存中没有这个key,就上锁,然后去查询mysql数据库,其他请求被阻塞,等第一个请求拿到mysql,并更新到缓存后,释放锁。阻塞的99个请求此时查询缓存,全部命中,这样就保护了mysql。
模拟这样情况 代码如下:
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 import functools 4 import redis 5 import time 6 import json 7 import threading 8 9 """ 10 使用redis做缓存,这里模拟一个web接口缓存的例子 11 """ 12 13 # 这里使用redis连接池,管理redisservice的所有连接,避免每次创建关闭连接的开销 14 pool = redis.ConnectionPool(host='127.0.0.1', port=6379) 15 redis_cli = redis.Redis(connection_pool=pool) 16 17 18 def redis_cache(func): 19 @functools.wraps(func) # 为了保留原函数的属性,因为被装饰的函数对外暴露的是装饰器的属性 20 def wrapper(*args, **kargs): 21 start_time = time.time() 22 _key = 'function-name:{},args:{},kargs:{}'.format(func.__name__, args, kargs) # 定义key的形式 23 result = redis_cli.get(_key) # redis查找到对应的key,直接返回结果 24 if result: 25 result = json.loads(result) 26 print(type(result)) 27 print('redis find:{},result:{}'.format(_key, result)) 28 else: # redis没有查找到对应key,查询执行函数,查询mysql 29 lock.acquire() #1 30 result = redis_cli.get(_key) #2 31 if result: #3 32 print('Value to be found in the redis·························') 33 else: #4 34 print('redis not find:{}, find from mysql·······················'.format(_key)) 35 result = func(*args, **kargs) 36 redis_cli.setex(_key, json.dumps(result), 5) # 将mysql结果写入redis,并设置过期时间 单位s 37 lock.release() # 无论如何,都释放锁 38 print("final result:{}".format(result)) 39 end_time = time.time() - start_time 40 print("Total time of this query:{}".format(end_time)) 41 return result 42 43 return wrapper 44 45 46 @redis_cache 47 def mysql_dispose(name, age): 48 time.sleep(2) 49 result = {'name:': name, 'age': age} 50 print('mysql-result:{}'.format(result)) 51 return (result) 52 53 54 if __name__ == '__main__': 55 lock = threading.Lock() # 创建一个不可重入锁的对象 56 57 # 创建5个线程模拟并发请求 58 t1 = threading.Thread(target=mysql_dispose, args=('zz3', 45,)) 59 t2 = threading.Thread(target=mysql_dispose, args=('zz3', 45,)) 60 t3 = threading.Thread(target=mysql_dispose, args=('zz3', 45,)) 61 t4 = threading.Thread(target=mysql_dispose, args=('zz3', 45,)) 62 t5 = threading.Thread(target=mysql_dispose, args=('zz3', 45,)) 63 64 t1.start() 65 t2.start() 66 t3.start() 67 t4.start() 68 t5.start()
output>>>>
redis not find:function-name:mysql_dispose,args:('zz3', 45),kargs:{}, find from mysql·······················
mysql-result:{'name:': 'zz3', 'age': 45}
final result:{'name:': 'zz3', 'age': 45}
Value to be found in the redis ·······················
final result:b'{"name:": "zz3", "age": 45}'
Total time of this query:2.0075249671936035
Total time of this query:2.0085232257843018
Value to be found in the redis ·······················
final result:b'{"name:": "zz3", "age": 45}'
Value to be found in the redis ·······················
final result:b'{"name:": "zz3", "age": 45}'
Total time of this query:2.0105319023132324
Total time of this query:2.0105326175689697
Value to be found in the redis ·······················
final result:b'{"name:": "zz3", "age": 45}'
Total time of this query:2.0155487060546875
做了哪些改动?看标红的4步
1. 第一个查询没有从redis中查到结果就上锁,
2.再次查询redis,结果还是没找到,
3.那就查询mysql,mysql耗时2秒的查询过程中,锁未释放,而此时,第二个线程第一次查询redis(第23行),结果不存在,就走到else分支,去上锁,发现锁未被第一个线程释放,那就阻塞,其他线程也一样的道理,都阻塞
4. 第一个线程查询完mysql,将结果更新到redis,然后释放锁,第二个线程发现锁被释放,立刻上锁,到第2步,再次查询redis,发现这时redis的key-value存在了,那就直接拿到结果,然后释放锁,不会再查询mysql,其他线程也是这样的过程
不难看出。这样会导致大量的请求阻塞,但是会保护mysql,至于取舍,就看项目需求了
缓存雪崩
雪崩就好理解了,一句话,就是redis挂掉了或者redis的key在同一时刻全部过期了,那所有的请求就会全部查询数据库,可想而知,如果同一时刻有大量请求,那对数据库造成的压力也是非同小可
怎么办?
1.先考虑redis key过期的情况,既然为了防止同时过期,那就可以考虑给key设置过期时间时加上一个随机数,比如,key1的过期时间是600s,随机数为6,那key1的过期时间就是606s,为什么不直接不设置过期时间,使key永不过期呢?嗯。。。。。因为内存空间实在有限且珍贵,很多key在某个时间段后其实就没有了价值,应为用户查询少或者完全不会再次查询,这样的key如果无限制存在于内存中简直是灾难,内存迟早会被吃空!代码稍加修改,在设置过期时间是加上随机数:
import random
random_num = random.randint(1,9) redis_cli.setex(_key, json.dumps(result), 5+random_num) # 将mysql结果写入redis,并设置过期时间 单位s
2. redis挂掉的解决方法:
试想,redis是单节点的时候挂掉,就会出现这种情况,那就应该考虑redis分布式集群,保证至少有一个redis活着,redis的分布式集群这里就不做说明了,可以自己网上搜索
那要是不幸,整个redis集群都挂掉了怎么办?那就应该限流,常见的限流算法有:计数器、漏桶和令牌桶算法。可以自己去了解一下