一. 编码介绍
计算机只能处理数字(最底层的0和1),如果要处理文本,就必须将文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以一个字节能表示的最大整数就是255(二进制11111111 = 十进制255),如果要表示更大的整数,就需要更多的字节,比如两个字节可以表示的最大整数为 65535 , 4个字节可以表示的最大整数就是 4294967295.
bit :(b)
“位”或“比特”, 是计算机运行的基础,属于二进制的范畴。bit的值为0或1。缩写为 b.
byte:(B)
“字节”,是计算机文件大小的基本计算单位,1 byte = 8 bit (1B= 8b)。缩写为 B。1byte 是一个字节, 2bytes 是两个字节,bytes只是byte的复数形式,没有特别的意义。
比特和字节的区别:
比特(bit)通常用来作数据传输的单位,因为物理层,数据链路层的传输对于用户是透明的,而这种通信传输是基于二进制的传输。
字节(byte)在应用层通常使用字节作为单位,表示文件的大小,在用户看来就是可见的数据大小,比如一个字符就是1 byte,如果是汉字就是2byte.
ASCII 编码:
美国人发明,只有127个字符(大小写英文字母,数字和一些符号),一个字节表示一个字符,比如大写A的编码是65,小写字母z的编码是122,无法显示中文。
GB2312:
中国人发明,将中文编写如ASCII,一个中文最少用2个字节表示。并且与ASCII编码不冲突。
Unicode :
优点:把所有的语言统一到一套编码内,Unicode标准在不断发展,但是最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节),现在操作系统和大多数变成语言都直接支持Unicode。
缺点:如果文本中基本都是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上十分不划算。
ASCII 和 Unicode 的区别:ASCII编码是1个字节表示1个字符,而Unicode编码通常是2个字节表示1个字符。
UTF-8 编码:
将一个Unicode字符更具不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果要传输的文本包含大量的英文字符,用UTF-8编码就能节省空间。实际上,我们可以将ASCII 看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件都可以再UTF-8编码下继续工作。
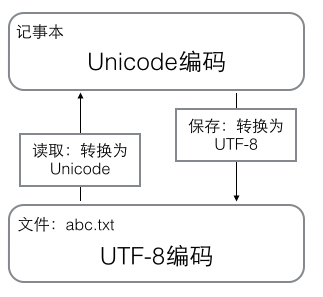
在计算机内存中,统一使用Unicode编码,需要保存到硬盘或者需要传输的时候,就会转换为UTF-8编码。用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再吧Unicode转换为UTF-8保存到文件:浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。所以在很多网页的源码中会有类似于 <meta charset='UTF-8' />的信息,表示该网页使用UTF-8编码的。

字符串编码
在Python3中,字符串是以Unicode编码的,所以,Python的字符串支持多种语言。
字符串编码转换函数:
- ord() # 获取字符的整数表示
- chr() # 把编码转换为对应的字符
>>> ord('a')
97
>>> chr(97)
'a'
>>> ord('你')
20320
>>> chr(20320)
'你'
由于Python的字符串类型是 str , 在内存中以 Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把 str 转换为以字节为单位的 bytes。
Python对 bytes 类型的数据用带 b 前缀的单引号或双引号表示: x = b'abc'
编码和解码
- encode() # 以Unicode表示的字符串通过encode()方法可以编码为指定的字节。
- decode() # 将字节变成字符串,也就是解码

Unicode 是最底层,最基础的,会根据终端的编码进行转化展示。一般硬盘存储或传输为utf-8(节省空间和带宽),读入内存为Unicode。
Python2版本虽然也支持Unicode,但是在语法上需要'xxx'和u'xxx'两种字符串来表示。
# Python2.X版本
>>>u'中文'.encode('gb2312')
>>>'xd6xd0xcexc4'
# Python3.X版本,统一改成了unicode编码,写不写前缀u 都是一样的,而以字节形式表示的字符串则必须加上 b 前缀 :b'xxx'。
>>>u'中文'.encode('gb2312')
>>>'xd6xd0xcexc4'
>>>'中文'.encode('gb2312')
>>>'xd6xd0xcexc4'