目录:
第1章 三剑客之一 awk
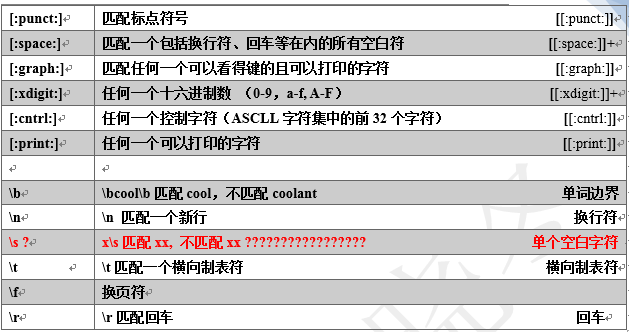
1.1 awk字符参数统计表
1.2 参数字符举例
第2章 三剑客之二 sed
2.1 sed字符参数统计表
2.2 参数字符举例
第3章 三剑客之三 grep
3.1 参数字符统计表
3.2 参数字符举例
第4章 通配符
4.1 通配符统计表格
4.2 通配符举例
第5章 特殊符号
5.1 特殊符号统计表
第6章 三剑客的正则表达式
6.1 正则表达式的定义
6.2 正则表达式的运用区分通配符
6.3 正则表达式的注意事项
6.4 正则表达式的分类
6.5 三剑客正则表达式字符统计表
三剑客特殊字符及参数归档
第1章 三剑客之一 awk
命令解释:awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
1.1 awk字符参数统计表

1.2 参数字符举例
1.2.1 NR例
题意:取出ett.txt 中第25行到第30行
[root@oldboy34 data]# awk 'NR>=25&&NR<=30' ett.txt
25
26
27
28
29
30
1.2.2 ! 例
awk '!/oldboy/' test.txt
test
liyao
1.2.3 '{print $2,$3}' 列
表示取出第2例和第3例
[root@oldboy-muban data]# ls -l total 20 drwxr-xr-x. 2 root root 4096 Jan 6 17:56 a drwxr-xr-x. 2 root root 4096 Jan 6 17:56 b drwxr-xr-x. 2 root root 4096 Jan 6 17:56 c drwxr-xr-x. 2 root root 4096 Jan 6 17:56 d -rw-r--r--. 1 root root 97 Dec 23 19:45 oldboy.txt [root@oldboy-muban data]# ls -l |awk '{print $2,$3}' 20 2 root 2 root 2 root 2 root 1 root
1.2.4 . (点) 例
取全部
1.2.5 '$2>1' 例
ls -l |awk '$2>1' 显示出第二列数值>1 的每行
[root@oldboy-muban ~]# ls -l |awk '$2>1'
total 36
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 a
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 b
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 c
1.2.6 -F "" 例
常用格式 awk -F " 指定内容" '{print $4第四行,$6 }’ oldboy.txt
[root@oldboy-muban oldboy]# cat oldboy.txt
I am oldboy,myqq is 31333741
[root@oldboy-muban ~]# awk -F "[ ,]" '{print $3,$6}' /oldboy/oldboy.txt
oldboy 31333741
1.2.7 -F "[ ]" 例
-F "[空格 ,]" 指定多把菜刀 分别以 空格和 ,号当分割符号
[root@oldboy-muban ~]# awk -F "[ ,]" '{print $3,$6}' /oldboy/oldboy.txt
oldboy 31333741
1.2.8 '{print $3" 12345 "$6}'例
显示列中插入 12345 但是显示内容要加 '' "
[root@oldboy-muban oldboy]# awk -F "[ ,]" '{print $3" 12345 "$6}' oldboy.txt
oldboy 12345 31333741
1.2.9 NR $n组合 例
print 和NR 组合为输出的列显示行号
NR表示行号(第几行) $0 表示整列(表示取第几列)
[root@oldboy-muban logs]# echo stu{1..6} |xargs -n2 >ett.txt 插入两行
[root@oldboy-muban logs]# cat ett.txt
stu1 stu2
stu3 stu4
stu5 stu6
[root@oldboy-muban ~]# awk '{print NR,$0}' nginx.conf (NR表示第几行开始标记行号$0表示全部列)
1 stu1 stu2
2 stu3 stu4
3 stu5 stu6
[root@oldboy-muban ~]# awk '{print NR,$2}' nginx.conf ($2 第二列 并默认从头行标号)
1 stu2
2 stu4
3 stu6
[root@oldboy-muban ~]# awk '{print NR==1,$2}' nginx.conf (NR==1给指定行标注1 )
1 stu2
0 stu4
0 stu6
1.2.10 '/ ^d/' 例
awk '/ ^d/' ( ^ 特殊字符 表示以d开头的文件或字符)
所以:ls -l | awk '/^d /'
[root@oldboy-muban ~]# ls -l
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 a
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 b
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 c
-rw-r--r--. 1 root root 0 Jan 3 10:15 jeacen
-rw-r--r--. 1 root root 0 Jan 9 16:35 nginx.conf
drwxr-xr-x. 7 root root 4096 Jan 3 10:15 oldboy
[root@oldboy-muban ~]# ls -l |awk '/^d/'
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 a
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 b
drwxr-xr-x. 2 root root 4096 Jan 3 10:11 c
第2章 三剑客之二 sed
命令解释:sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
2.1 sed字符参数统计表

2.1.2 指定范围
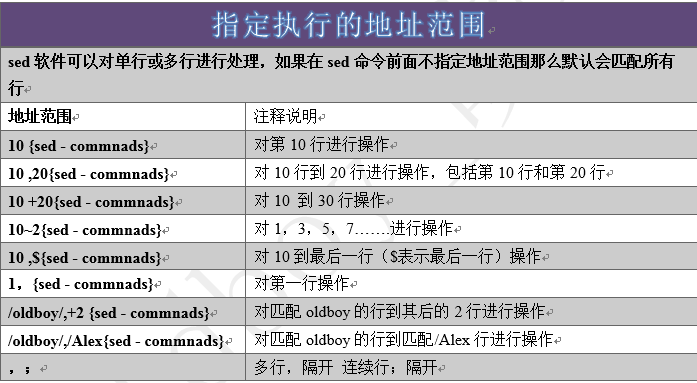
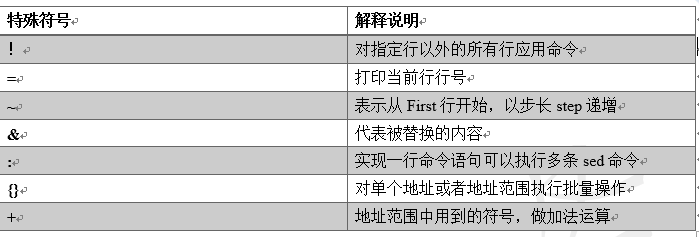
2.1.3特殊符号小结
2.2 参数字符举例
2.2.1 用sed 删除文件1.txt中的空行
##删除文件中的空行两种方法
方法一: sed -r '/^$|^[ ]+$/d
方法二: sed -r '/^[ ]*$/d'
环境如下
[root@oldboy-muban ~]# cat 1.txt
oldboy
zhabanzhang
zbanz
oldboy
[root@oldboy-muban ~]# cat -A 1.txt
oldboy$
$
zhabanzhang$
^I^I^I$
^Izbanz$
$
oldboy$
方法一:
[root@m01 ~]# sed -r '/^$|^[ ]+$/d' 1.txt
oldboy
zhabanzhang
zbanz
oldboy
方法二:
[root@m01 ~]# sed -r '/^[ ]*$/d' 1.txt
oldboy
zhabanzhang
zbanz
oldboy
2.2.2 删除连续多行演示 ,号
[root@oldboy-muban ~]# sed 'd' person.txt
[root@oldboy-muban ~]# sed '2,3d' person.txt
101,oldboy,CEO
104,yy,CFO
105,feixue,CIO
[root@oldboy-muban ~]# sed '2,3!d' person.txt
102,zhangyao,CTO
103,Alex,COO
2.3.3 删除不连续行 ;号
[root@oldboy-muban ~]# sed '3d;5d' person.txt
101,oldboy,CEO
102,zhangyao,CTO
104,yy,CFO
注意:正则不确定性 工作中用数字删
2.2.4 w另存
[root@oldboy-muban ~]# sed 'w oldboy123.txt' person.txt
101,oldboy,CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy-muban ~]# ls
01 1.txt.bak anaconda-ks.cfg install.log oldboy123.txt pass.txt person.txt wangxiaog.txt wxd.sh
2.2.5 -n p 例
该命令一起使用表示只打印那些发生替换的行(取消默认输出)
格式:sed -n ' 20p'
只查看ett.txt文件(共100行)内第20到第30行的内容
[root@oldboy34 data]# sed -n '20,30p' ett.txt
20
21
22
23
24
25
26
27
28
29
30
2.2.6 's###g' 例
[root@oldboy-muban data]# cat ett.txt
I am oldboy,myqq is 31333741
[root@oldboy-muban data]# sed "s#,myqq is# #g" ett.txt |sed "s#I am##g"
oldboy 31333741
2.2.7 sed -r 's#.(.).(.).(.)#123#g' 例
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.)....#1#g'
2
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.).(.).(.)#123#g'
246
|
反向引用的两组字符中可以插入内容 |
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.).(.).(.)#1,2#g'
2,4
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.).(.).(.)#1,2,3#g'
2,4,6
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.).(.).(.)#1:2:3#g'
2:4:6
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.).(.).(.)#1+2+3#g'
2+4+6
|
反向引用出来的字符后也可以插入内容 |
[root@oldboy-muban oldboy]# echo "123456"|sed -r 's#.(.).(.).(.)#1,2#g'
2,2
2.2.8 sed -r 反向引用调换passwd 首列和尾列
[root@oldboy-muban oldboy]# head -1 passwd
root:x:0:0:root:/root:/bin/bash
[root@oldboy-muban oldboy]# sed -r 's#(^root)(:.*:)(/b.*sh$)#321#g' passwd |head -1
/bin/bash:x:0:0:root:/root:root
[root@oldboy-muban oldboy]# sed -r 's#(root)(:x.*:)(/b.*sh$)#321#g' passwd |head -1
/bin/bash:x:0:0:root:/root:root
2.2.9 删除文件每行的第二个字符
[root@oldboy-muban ~]# sed -r 's#.##2' /etc/passwd |head -5
rot:x:0:0:root:/root:/bin/bash
bn:x:1:1:bin:/bin:/sbin/nologin
demon:x:2:2:daemon:/sbin:/sbin/nologin
am:x:3:4:adm:/var/adm:/sbin/nologin
l:x:4:7:lp:/var/spool/lpd:/sbin/nologin
2.2.10 删除文件每行的倒数第二个字符
[root@oldboy-muban ~]# sed -r 's#.(.)$##g' /etc/passwd |head -5
root:x:0:0:root:/root:/bin/ba
bin:x:1:1:bin:/bin:/sbin/nolog
daemon:x:2:2:daemon:/sbin:/sbin/nolog
adm:x:3:4:adm:/var/adm:/sbin/nolog
lp:x:4:7:lp:/var/spool/lpd:/sbin/nolog
2.2.11 删除文件每行的第二个单词
[root@oldboy-muban ~]# sed -r 's#[a-z]+##2' /etc/passwd |head -5
root::0:0:root:/root:/bin/bash
bin::1:1:bin:/bin:/sbin/nologin
daemon::2:2:daemon:/sbin:/sbin/nologin
adm::3:4:adm:/var/adm:/sbin/nologin
lp::4:7:lp:/var/spool/lpd:/sbin/nologin
[root@oldboy-muban ~]#
2.2.12 删除倒数第二单词
方法一
[root@oldboy-muban ~]# sed -r 's#[a-z]+/([a-z]+$)#/1#g' /etc/passwd |head -1
root:x:0:0:root:/root://bash
方法二
[root@oldboy-muban ~]# sed -r 's#[a-z]+##5' /etc/passwd |head -1
root:x:0:0:root:/root://bash
2.2.13 交换每行的第一个字符和第二个字符
[root@oldboy-muban ~]# sed -r 's#(^.)(.)#21#g' /etc/passwd |head -1
orot:x:0:0:root:/root:/bin/bash
2.2.14 交换每行的第一个字符和第二个单词。
2.2.15 删除每行开头的所有空格
sed -r 's#[ ]+##g' /etc/passwd
2.2.16 用制表符替换文件中出现的所有空格
sed -r 's#[ ]+# #g' /etc/passwd
2.2.17 把所有大写字母用括号()括起来
sed -r 's#([ A-Z])#(1)#g' /etc/passwd
2.2.18 &符号表示被替换的内容
[root@oldboy-muban ~]# sed -r 's#(.*),(.*),(.*)#&.................1 2 3#g' person.txt
101,oldboy,CEO.................101 oldboy CEO
102,zhangyao,CTO.................102 zhangyao CTO
103,Alex,COO.................103 Alex COO
104,yy,CFO.................104 yy CFO
105,feixue,CIO.................105 feixue CIO
[root@oldboy-muban ~]# sed -r 's#(.*),(.*),(.*)#&.................1 2 3#' person.txt
101,oldboy,CEO.................101 oldboy CEO
102,zhangyao,CTO.................102 zhangyao CTO
103,Alex,COO.................103 Alex COO
104,yy,CFO.................104 yy CFO
105,feixue,CIO.................105 feixue CIO
2.2.19 例 rename "" "" file*
[root@oldboy-muban test]# ls |xargs -n1
stu_102999_1_finished.jpg
stu_102999_2_finished.jpg
stu_102999_3_finished.jpg
stu_102999_4_finished.jpg
stu_102999_5_finished.jpg
[root@oldboy-muban test]# ls |xargs -n1 |sed -r 's#(.*)_(.*)_(.*)_(.*)#mv & 1_2_3.jpg #g' |bash
[root@oldboy-muban test]# ls
stu_102999_1.jpg stu_102999_2.jpg stu_102999_3.jpg stu_102999_4.jpg stu_102999_5.jpg
[root@oldboy-muban test]# ls -l
total 0
-rw-r--r-- 1 root root 0 Feb 22 15:22 stu_102999_1.jpg
-rw-r--r-- 1 root root 0 Feb 22 15:22 stu_102999_2.jpg
-rw-r--r-- 1 root root 0 Feb 22 15:22 stu_102999_3.jpg
-rw-r--r-- 1 root root 0 Feb 22 15:22 stu_102999_4.jpg
-rw-r--r-- 1 root root 0 Feb 22 15:22 stu_102999_5.jpg
2.2.20 按正则输出行
[root@oldboy-muban ~]# sed -rn '/oldboy|Alex/p' person.txt
101,oldboy,CEO
103,Alex,COO
[root@oldboy-muban ~]#
2.2.21 例:sed -r 's#(.*),(.*),(.*)
题:如下取出 第一行 和 uid后面的数字
[root@fifi tmp]# cat /tmp/test.txt
//xcbb_web/mobileLive/searchRecentUserLiveResult channel=App%20Store&clientType=1&packageName=com.prsoft.vncShow&page=1&pageSize=50&province=%E7%83%AD%E9%97%A8&sex=2&token=TWpBd05UZ3lNVFRDcDNScmQyeHlNM3BtYTNVeE5UQTFNVFF4TURnNU5ESTR3cWN4TlRFeE16WTRNalEzTURBMw%3D%3D&type=3&uid=20058214&version=1.1.1 "-"
//xcbb_web/business/mobile/api/getActiviWeekStarTask uid=20016107&token=TWpBd01UWXhNRGZDcHpOMmVEQjZhakYwZW5JeE5EazRPRGN3TURVME9Ua3d3cWN4TlRFeE56a3pPVEU0TURNdw==
方法:
[root@fifi tmp]# sed -r 's#(^//.*)/.*uid=(.*).&(.*$)#1,2#g' /tmp/test.txt |awk -F "[ / ,]+" '{print $2,$NF }'
xcbb_web 2005821
xcbb_web 2001610
2.2.22 sed -nr '/ /,/ /p'
sed -n '/2018-06-21 09:10:43/,/2018-06-21 09:50:/p' catalina.out > /tmp/1.txt
第3章 三剑客之三 grep
命令解释:grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
3.1 参数字符统计表

3.2 参数字符举例
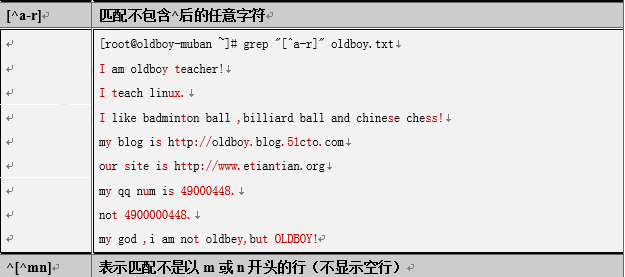
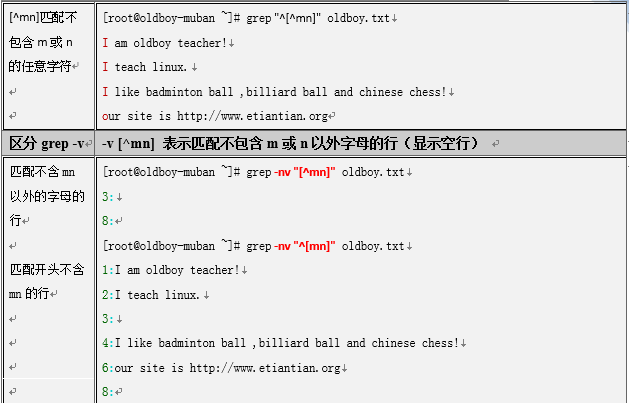
3.2.1 -v例
grep -v "oldboy" test.txt
root@oldboy34 ~]# cat text.txt
test
liyao
oldboy
[root@oldboy34 ~]# grep -v "oldboy" text.txt
test
liyao
3.2.2 -A 、-B、-C 例
-A 10 after 显示你要找的行,及他后面的10行
-B 10 before 显示你要找的行,及他前面的10行
-C 10 context 找到你要找的行,及他前面的10行和后面的10行
[root@oldboy-muban ~]# grep -A 5 10 oldgil.txt
10
11
12
13
14
15
3.2.3 配合 cat-n
来使用 表示插入行号
[root@oldboy-muban ~]# cat -n oldboy.txt| grep -A 2 7
7 jfdslj
8 jsdl
3.2.4 -i 例
grep -i 不区分大小写
oldpwd = cd -
root@oldboy-muban oldboy]# pwd
/oldboy
[root@oldboy-muban oldboy]# cd -
/tmp
[root@oldboy-muban tmp]# env |grep -i "oldpwd"
OLDPWD=/oldbo
3.2.5 -n "." 例
grep -n 过滤后标注行号
[root@oldboy-muban ~]# grep -n "stu" nginx.conf
1:stu1
2:stu2
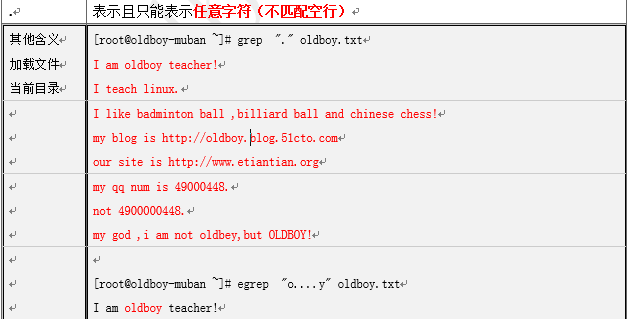
[root@oldboy-muban ~]# grep -n "." nginx.conf (.表示当前列中的任意字符)
1:stu1
2:stu2
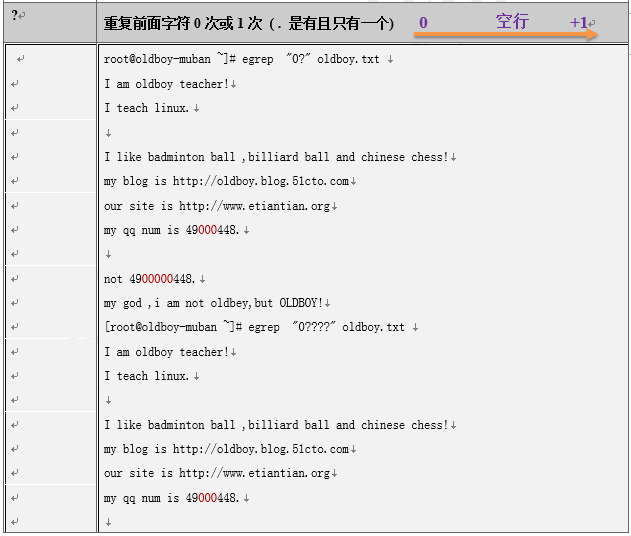
3.2.6 egrep = grep -E 例 (取多行)
[root@oldboy-muban oldboy]# cat oldboy.txt
I am oldboy,myqq is 31333741
[root@oldboy-muban ~]# awk -F "[ ,]" '{print $3,$6}' /oldboy/oldboy.txt|grep -E "oldboy|31333741 "
oldboy 31333741
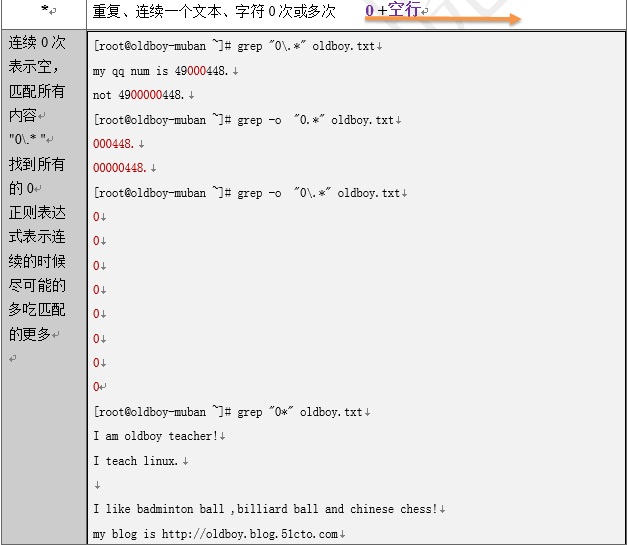
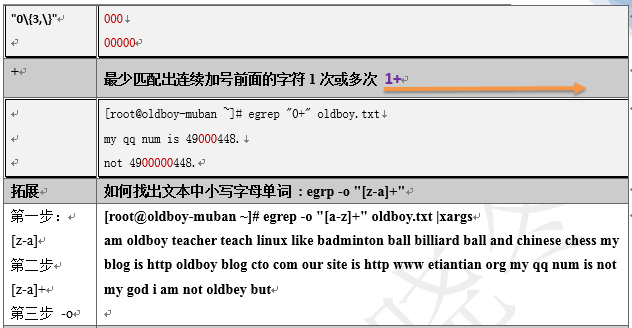
3.2.7 grep -o 和egrep -o 例
[root@oldboy-muban logs]# cat ett.txt
stu1 stu2
stu3 stu4
stu5 stu6
[root@oldboy-muban logs]# grep -o "stu4" ett.txt
stu4
[root@oldboy-muban logs]# egrep -o "stu4|stu5" ett.txt
stu4
stu5
第4章 通配符
4.1 通配符统计表格
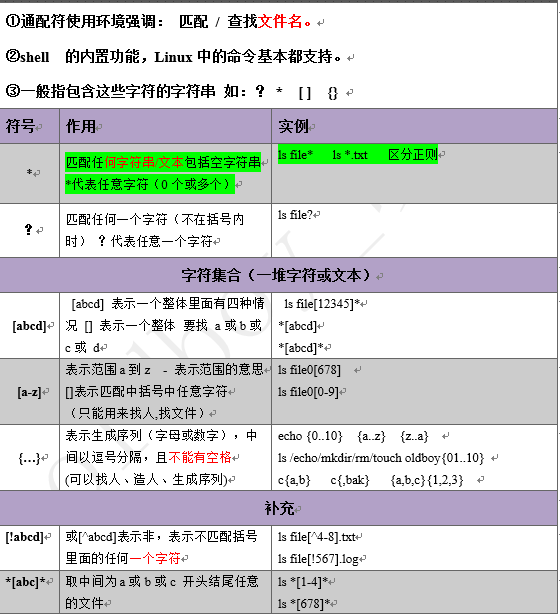
4.2.1 * 例4.2 通配符举例
stu* *.log 以什么开头或以什么结尾的全部文件
[root@oldboy-muban logs]# ls oldboy*
oldboy01.txt oldboy03.txt oldboy05.txt oldboy07.txt oldboy09.txt
oldboy02.txt oldboy04.txt oldboy06.txt oldboy08.txt
[root@oldboy-muban logs]# ls *.txt
ett.txt oldboy02.txt oldboy04.txt oldboy06.txt oldboy08.txt
oldboy01.txt oldboy03.txt oldboy05.txt oldboy07.txt oldboy09.txt
4.2.2 ?? 例
?? ??? 任何一个文本/字符
ls ?
[root@oldboy-muban logs]# ls
1 2 4 ett.txt.bak oldboy02.txt oldboy04.txt oldboy06.txt
1.2 3 ett.txt oldboy01.txt oldboy03.txt
[root@oldboy-muban logs]# ls ?
1 2 3 4
4.2.3 [abcd] 例
[abcd] 表示一个整体里面有四种情况 [] 表示一个整体 要找 a或b或 c或 d
*[abcd]
*[abcd]*
*[abcd]*
[root@oldboy-muban logs]# ls *[1-4]*
oldboy01.txt oldboy02.txt oldboy03.txt oldboy04.txt
stu1:
stu2:
stu3:
stu4:
4.2.4 {…} 例
echo {0..10} {a..z} {z..a} 生成序列一连串的文本
oldboy{01..10} 生成一连串的文件或目录
c{a,b} c{,b} {a,b,c}{1,2,3} 生成的分别匹配的序列
seq 20 120 > ett.txt (生成20-120) seq 1 2 10 |xargs ( 生成奇数)
c{,b}
[root@oldboy-muban logs]# ls
ett.txt stu1 stu2 stu3 stu4 stu5
[root@oldboy-muban logs]# cp ett.txt{,.bak}
[root@oldboy-muban logs]# ls
ett.txt ett.txt.bak stu1 stu2 stu3 stu4 stu5
{1..5}{a..d}
[root@oldboy-muban logs]# touch stu{1..5}{a..d}
[root@oldboy-muban logs]# ls
1.2 ett.txt.bak stu1b stu1d stu2b stu2d stu3b stu3d stu4b stu4d stu5b stu5d
ett.txt stu1a stu1c stu2a stu2c stu3a stu3c stu4a stu4c stu5a stu5c
4.2.5 [!abc] 或[^abc] 例
oldboy[^4-8].txt
[root@oldboy-muban logs]# ls -l oldboy0[^4-8].txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy01.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy02.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy03.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy09.txt
oldboy[^678].txt
[root@oldboy-muban logs]# ls -l oldboy0[^678].txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy01.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy02.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy03.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy04.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy05.txt
-rw-r--r--. 1 root root 0 Jan 10 16:36 oldboy09.txt
4.2.6 注意问题
{无空格要,号}
[root@oldboy-muban logs]# echo {1..5}{ a..f}
1{ 2{ 3{ 4{ 5{ a..f}
{里面不能接路径}
[root@oldboy-muban logs]# cp ett.txt{,/tmp/.bak}
cp: accessing `ett.txt/tmp/.bak': Not a directory
第5章 特殊符号
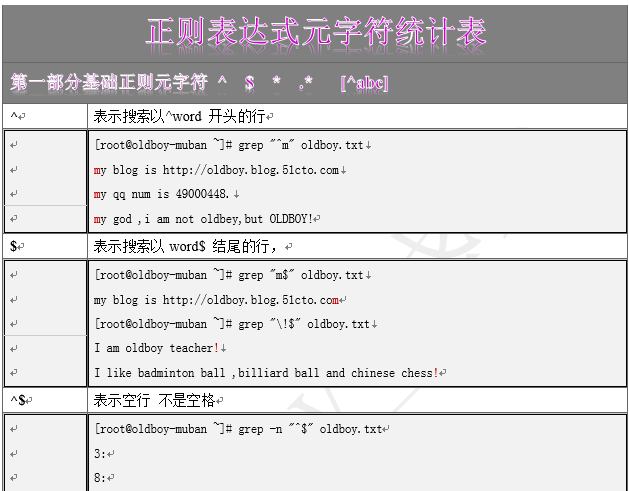
5.1 特殊符号统计表


第6章 三剑客的正则表达式
6.1 正则表达式的定义
广义:
1、正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法。
2、通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串,Linux正则表达式一般以行为单位处理。
简单理解:
1、为处理大量文本|字符串而定义的一套规则和方法
2、以行为单位出来
正则表达式是一种描述一组字符串的模式,;类似于数学表达式,通过各种操作符 组成更小的表达式。
6.2 正则表达式的运用区分通配符
运用:大龄过滤日志工作,化繁为易 更简单,高效,易用。
区分:三剑客都支持,而且运用非常广泛(php per python 都支持)
ls* 支持通配符
正则表达式用来找 文件内容,文本 字符串
通配符用来找文件名或文件普通命令都支持
6.3 正则表达式的注意事项
1、正则表达式是 以行为单位处理字符串
2、颜色别名 一般配合grep egrep 来学习
例:配置别名
[root@oldboy-muban ~]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
3、注意字符集
6.4 正则表达式的分类
①基本正则表达式(BRE —— basic regular expression)
②高级功能扩展正则表达式(ERE —— extended regular expression)
③BRE和ERE 的区别仅仅是元字符的不同
BRE支持的元字符有(^ $ . [ ] * )其他字符识别为普通字符:()
E RE添加了() { } ? + | 等
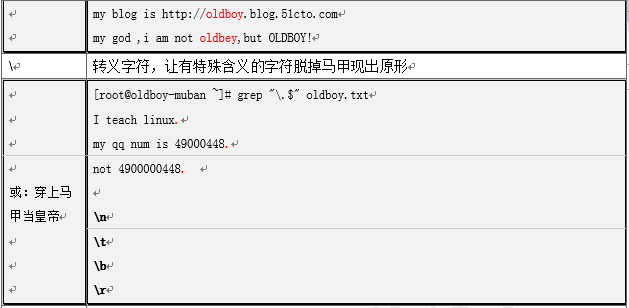
只有在用反斜杠“”进行转义的情况下,字符( ){ } 才会在BRE被当做元字符处理
在ERE中,任何元符号前面加上反斜杠反而会使其被当做普通字符来处理
6.5 三剑客正则表达式字符统计表