反向传播
In PyTorch, Tensor is the important component in constructing dynamic computational graph. It contains data and grad, which storage the value of node and gradient w.r.t (with respect to) loss respectively.
if autograd mechanics are required, the element variable requires_grad of Tensor has to be set to True.
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
Define the linear model:
[hat y = x * w
]
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
Then train and predict.
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # Forward, compute the loss.
l.backward() # Backward, compute grad for Tensor whose requires_grad set to True.
print(' grad:', x, y, w.grad.item()) # The grad is also a Tensor, use item() to get the scalar.
w.data = w.data - 0.01 * w.grad.data # Data of Tensor will not be added to the computational graph.
w.grad.data.zero_() # The grad computed by backward() will be accumulated.
print('progress:', epoch, l.item())
print("predict (after training)", 4, forward(4).item())
线性回归
PyTorch Fashion
-
Prepare dataset
import torch x_data = torch.Tensor([[1.0], [2.0], [3.0]]) y_data = torch.Tensor([[2.0], [4.0], [6.0]]) -
Design model using Class
class LinearModel(torch.nn.Module): # The nn.Module is Base class for all neural network modules. def __init__(self): super(LinearModel, self).__init__() self.linear = torch.nn.Linear(1, 1) # Class nn.linear contain two member Tensors: weight and bias. def forward(self, x): y_pred = self.linear(x) # Class nn.Linear has implemented the magic method __call__(). return y_pred model = LinearModel() # Create an instance of class LinearModel, it is also callable. -
Construct loss and optimizer
criterion = torch.nn.MSELoss(size_average = False) # Class nn.MSELoss is also inherited from nn.Module. optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)Some kinds of optimizer:
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.Adamax
- torch.optim.ASGD
- torch.optim.LBFGS
- torch.optim.RMSprop
- torch.optim.Rprop
- torch.optim.SGD
-
Training cycle
for epoch in range(100): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch, loss) optimizer.zero_grad() loss.backward() optimizer.step()
加载数据集
Terminology
- Epoch: One forward pass and one backward pass of all the training examples.
- Batch-Size: The number of training examples in one forward backward pass.
- Iteration: Number of passes, each pass using batch-size number of examples.
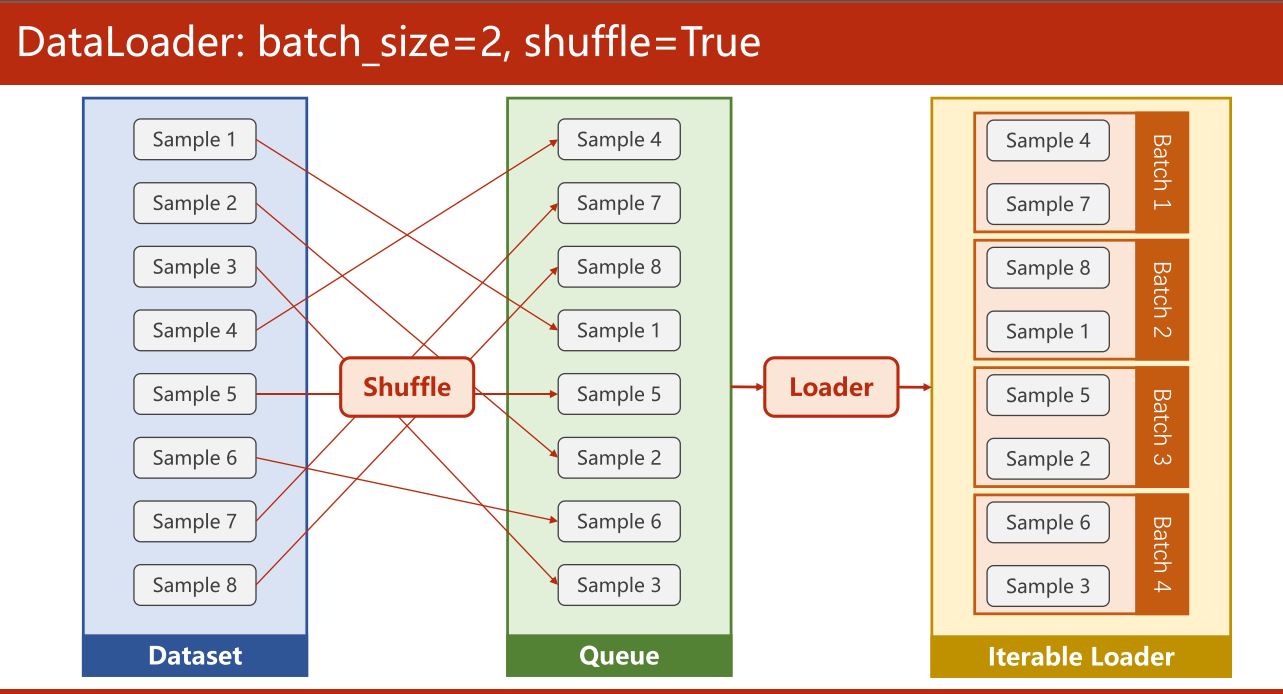
Define your Dataset
import torch
from torch.utils.data import Dataset # Dataset is an abstract class. We can define our class inherited from this class.
from torch.utils.data import DataLoader # DataLoader is a class to help us loading data in PyTorch.
class DiabetesDataset(Dataset): # DiabetesDataset is inherited from abstract class Dataset.
def __init__(self):
pass
def __getitem__(self, index): # The expression, dataset[index], will call this magic function.
pass
def __len__(self): # This magic function returns length of dataset.
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 0) # Process number for DataLoader to read Dataset.
if __name__ == '__main__': # It's necessary in windows.
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
pass
多分类问题
Cross Entropy in PyTorch
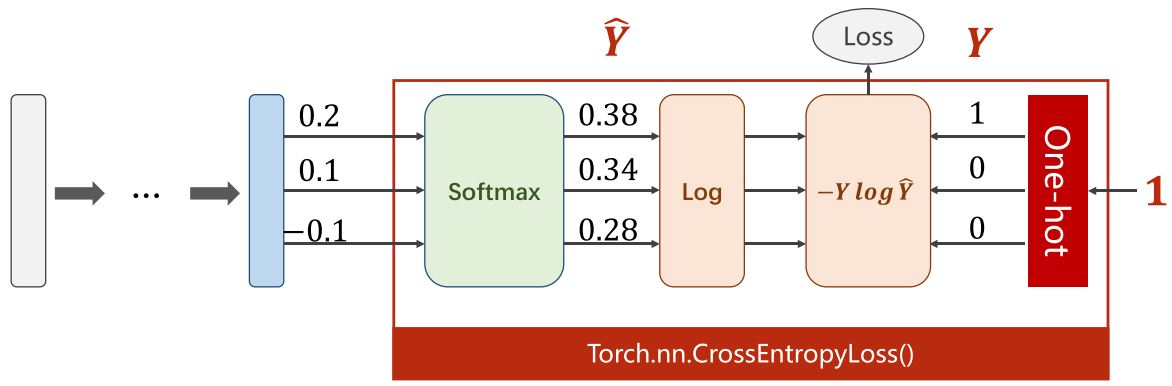
import torch
y = torch.LongTensor([0])
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)
Implementation of classifier to MNIST dataset
-
Import Package
import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F # For using function relu(). import torch.optim as optim -
Prepare Dataset
batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307), (0.3081)) ]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform) test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) -
Design Model
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.l1 = torch.nn.Linear(784, 512) self.l2 = torch.nn.Linear(512, 256) self.l3 = torch.nn.Linear(256, 128) self.l4 = torch.nn.Linear(128, 64) self.l5 = torch.nn.Linear(64, 10) def forward(self, x): x = x.view(-1, 784) x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) return self.l5(x) model = Net() -
Construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) -
Train and Test
def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0 def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total)) if __name__ == '__main__': for epoch in range(10): train(epoch) test()