一.类
1 #coding=utf-8 2 class Animal(object): 3 def __init__(self, name): 4 self.name = name 5 zebra = Animal("Jeffrey") 6 print zebra.name 7 8 #override 9 class Employee(object): 10 def __init__(self, emplotee_name): 11 self.employee_name = emplotee_name 12 def calculate_wage(self, hours): 13 self.hours = hours 14 return hours * 20.0 15 16 class PartTimeEmployee(Employee): 17 def calculate_wage(self, hours): 18 self.hours = hours 19 return hours * 12.0 20 def full_time_wage(self, hours): 21 return super(PartTimeEmployee, self).calculate_wage(hours) 22 milton = PartTimeEmployee("Li") 23 print milton.full_time_wage(10) #200 24 print milton.calculate_wage(10) #120 25 26 class Car(object): 27 condition = "new" 28 my_car = Car() 29 print my_car.condition #new 30 31 class A(object): 32 def __init__(self, n): 33 self.__n = n 34 aa = A(10) 35 aa #__n是私有变量,对象无法访问
二.文件
1 #coding=utf-8 2 """ 3 w wb (+)写 4 r rb (+)读 5 a ab (+)追加 6 """ 7 my_List = [i**2 for i in range(1, 11)] 8 f = open("output.txt", 'w') 9 for item in my_List: 10 f.write(str(item) + ' ') 11 f.close() 12 13 print f.readline() #一行 14 print f.read() #全部 15 16 with open("text.txt", 'w') as textfile: 17 textfile.write("success!") 18 19 if textfile.closed == False: 20 textfile.close() 21 print textfile.closed
1 #coding=utf-8 2 import os 3 import shutil 4 import glob 5 """ 6 文件夹操作 7 """ 8 print os.getcwd() 9 os.mkdir("D:\cwd") 10 print os.path.exists("D:\cwd") 11 os.chdir("D:\cwd") 12 print os.getcwd() 13 f = file("a.txt", "w") 14 f.close() 15 shutil.copy("E:\b.txt", "D:\cwd\b.txt") 16 shutil.copy("E:\b.txt", "D:\cwd\c.txt") 17 shutil.copy("E:\b.txt", "D:\cwd\d.txt") 18 os.remove("a.txt") 19 os.rename("b.txt", "e.txt") 20 21 """ 22 文件夹遍历 23 """ 24 for root, dirs, files in os.walk(os.getcwd()): 25 print files 26 break 27 28 for file in os.listdir(os.getcwd()): 29 if os.path.isfile(os.path.join(os.getcwd(), file)): 30 print file 31 32 print glob.glob("*.txt") 33 os.chdir("D:\") 34 shutil.rmtree("D:\cwd") 35 #os.removedirs("D:\cwd") error,删除多层空文件夹 36 #os.rmdir("D:\cwd") error,只适用于空文件夹

三.struct,pack,unpack

1 #coding=utf-8 2 import struct 3 a = 1 4 b = 2 5 c = 'sss' 6 d = 1.1 7 e = [a, b, c, d] 8 ss = struct.pack('ii3sf', a, b, c, d) 9 a, b, c, d = struct.unpack('ii3sf', ss) 10 print a, b, c, d #1 2 sss 1.10000002384 11 12 ss = struct.pack('ii3sf', *e) 13 a, b, c, d = struct.unpack('ii3sf', ss) 14 print a, b, c, d #1 2 sss 1.10000002384 15 16 x = [1, 2, 3] 17 y = [4, 5, 6] 18 xyz = zip(x, y) 19 print zip(x, y) #[(1, 4), (2, 5), (3, 6)] 20 print zip(x) #[(1,), (2,), (3,)] 21 print zip(*xyz) #[(1, 2, 3), (4, 5, 6)] 22 """ 23 [(1, 2, 3), (4, 5, 6), (7, 8, 9)] 24 25 一般认为这是一个unzip的过程,它的运行机制是这样的: 26 27 在运行zip(*xyz)之前,xyz的值是:[(1, 4), (2, 5), (3, 6)] 28 29 那么,zip(*xyz) 等价于 zip((1, 4), (2, 5), (3, 6)) 30 31 所以,运行结果是:[(1, 2, 3), (4, 5, 6)] 32 """
四.拷贝
1 #coding=utf-8 2 import copy 3 a = [1, 2, 3] 4 b = a 5 b[0] = 4 6 print a #[4, 2, 3] 7 a[0] = 1 8 print b #[1, 2, 3] 9 10 b = copy.deepcopy(a) 11 b[0] = 4 12 print a #[1, 2, 3] 13 14 a = {'a':1, 'b':2, 'c':3} 15 b = a 16 b['a'] = 4 17 print a #{'a': 4, 'c': 3, 'b': 2} 18 b.clear() 19 print a #{} 20 21 a = {'a':1, 'b':2, 'c':3} 22 b = a.copy() 23 b['a'] = 4 24 print a #{'a': 1, 'c': 3, 'b': 2} 25 b.clear() 26 print a #{'a': 1, 'c': 3, 'b': 2}
五.集合
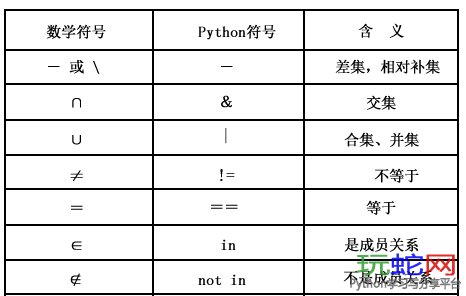
1 #coding=utf-8 2 #in, not in, <, > 3 aSet = set([1, 2, 3, 4]) 4 bSet = set([3, 4, 5]) 5 print aSet #set([1, 2, 3, 4]) 6 7 print aSet.intersection([3, 4, 5]) #set([3, 4]) 8 print aSet & bSet #set([3, 4]) 9 print aSet.union([5, 6]) #set([1, 2, 3, 4, 5, 6]) 10 print aSet.difference([3, 4, 5]) #set([1, 2]) 11 print aSet.issubset(bSet) #False 12 13 aSet.add(5) 14 print aSet #set([1, 2, 3, 4, 5]) 15 aSet.remove(5) 16 print aSet #set([1, 2, 3, 4]) 17 aSet.update(bSet) 18 print aSet #set([1, 2, 3, 4, 5]) 19 20 """ 21 python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算. 22 23 sets 支持 x in set, len(set),和 for x in set。作为一个无序的集合,sets不记录元素位置或者插入点。因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作。 24 25 26 27 下面来点简单的小例子说明把。 28 29 >>> x = set('spam') 30 >>> y = set(['h','a','m']) 31 >>> x, y 32 (set(['a', 'p', 's', 'm']), set(['a', 'h', 'm'])) 33 34 再来些小应用。 35 36 >>> x & y # 交集 37 set(['a', 'm']) 38 39 >>> x | y # 并集 40 set(['a', 'p', 's', 'h', 'm']) 41 42 >>> x - y # 差集 43 set(['p', 's']) 44 45 记得以前个网友提问怎么去除海量列表里重复元素,用hash来解决也行,只不过感觉在性能上不是很高,用set解决还是很不错的,示例如下: 46 47 >>> a = [11,22,33,44,11,22] 48 >>> b = set(a) 49 >>> b 50 set([33, 11, 44, 22]) 51 >>> c = [i for i in b] 52 >>> c 53 [33, 11, 44, 22] 54 55 很酷把,几行就可以搞定。 56 57 1.8 集合 58 59 集合用于包含一组无序的对象。要创建集合,可使用set()函数并像下面这样提供一系列的项: 60 61 62 63 s = set([3,5,9,10]) #创建一个数值集合 64 65 t = set("Hello") #创建一个唯一字符的集合 66 67 68 69 与列表和元组不同,集合是无序的,也无法通过数字进行索引。此外,集合中的元素不能重复。例如,如果检查前面代码中t集合的值,结果会是: 70 71 72 73 >>> t 74 75 set(['H', 'e', 'l', 'o']) 76 77 78 79 注意只出现了一个'l'。 80 81 集合支持一系列标准操作,包括并集、交集、差集和对称差集,例如: 82 83 84 85 a = t | s # t 和 s的并集 86 87 b = t & s # t 和 s的交集 88 89 c = t – s # 求差集(项在t中,但不在s中) 90 91 d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 92 93 94 95 基本操作: 96 97 t.add('x') # 添加一项 98 99 s.update([10,37,42]) # 在s中添加多项 100 101 102 103 使用remove()可以删除一项: 104 105 t.remove('H') 106 107 108 109 len(s) 110 set 的长度 111 112 x in s 113 测试 x 是否是 s 的成员 114 115 x not in s 116 测试 x 是否不是 s 的成员 117 118 s.issubset(t) 119 s <= t 120 测试是否 s 中的每一个元素都在 t 中 121 122 s.issuperset(t) 123 s >= t 124 测试是否 t 中的每一个元素都在 s 中 125 126 s.union(t) 127 s | t 128 返回一个新的 set 包含 s 和 t 中的每一个元素 129 130 s.intersection(t) 131 s & t 132 返回一个新的 set 包含 s 和 t 中的公共元素 133 134 s.difference(t) 135 s - t 136 返回一个新的 set 包含 s 中有但是 t 中没有的元素 137 138 s.symmetric_difference(t) 139 s ^ t 140 返回一个新的 set 包含 s 和 t 中不重复的元素 141 142 s.copy() 143 返回 set “s”的一个浅复制 144 145 146 请注意:union(), intersection(), difference() 和 symmetric_difference() 的非运算符(non-operator,就是形如 s.union()这样的)版本将会接受任何 iterable 作为参数。相反,它们的运算符版本(operator based counterparts)要求参数必须是 sets。这样可以避免潜在的错误,如:为了更可读而使用 set('abc') & 'cbs' 来替代 set('abc').intersection('cbs')。从 2.3.1 版本中做的更改:以前所有参数都必须是 sets。 147 148 另外,Set 和 ImmutableSet 两者都支持 set 与 set 之间的比较。两个 sets 在也只有在这种情况下是相等的:每一个 set 中的元素都是另一个中的元素(二者互为subset)。一个 set 比另一个 set 小,只有在第一个 set 是第二个 set 的 subset 时(是一个 subset,但是并不相等)。一个 set 比另一个 set 打,只有在第一个 set 是第二个 set 的 superset 时(是一个 superset,但是并不相等)。 149 150 子 set 和相等比较并不产生完整的排序功能。例如:任意两个 sets 都不相等也不互为子 set,因此以下的运算都会返回 False:a<b, a==b, 或者a>b。因此,sets 不提供 __cmp__ 方法。 151 152 因为 sets 只定义了部分排序功能(subset 关系),list.sort() 方法的输出对于 sets 的列表没有定义。 153 154 155 运算符 156 运算结果 157 158 hash(s) 159 返回 s 的 hash 值 160 161 162 下面这个表列出了对于 Set 可用二对于 ImmutableSet 不可用的运算: 163 164 运算符(voperator) 165 等价于 166 运算结果 167 168 s.update(t) 169 s |= t 170 返回增加了 set “t”中元素后的 set “s” 171 172 s.intersection_update(t) 173 s &= t 174 返回只保留含有 set “t”中元素的 set “s” 175 176 s.difference_update(t) 177 s -= t 178 返回删除了 set “t”中含有的元素后的 set “s” 179 180 s.symmetric_difference_update(t) 181 s ^= t 182 返回含有 set “t”或者 set “s”中有而不是两者都有的元素的 set “s” 183 184 s.add(x) 185 186 向 set “s”中增加元素 x 187 188 s.remove(x) 189 190 从 set “s”中删除元素 x, 如果不存在则引发 KeyError 191 192 s.discard(x) 193 194 如果在 set “s”中存在元素 x, 则删除 195 196 s.pop() 197 198 删除并且返回 set “s”中的一个不确定的元素, 如果为空则引发 KeyError 199 200 s.clear() 201 202 删除 set “s”中的所有元素 203 204 205 请注意:非运算符版本的 update(), intersection_update(), difference_update()和symmetric_difference_update()将会接受任意 iterable 作为参数。从 2.3.1 版本做的更改:以前所有参数都必须是 sets。 206 207 还请注意:这个模块还包含一个 union_update() 方法,它是 update() 方法的一个别名。包含这个方法是为了向后兼容。程序员们应该多使用 update() 方法,因为这个方法也被内置的 set() 和 frozenset() 类型支持。 208 """
1 aSet = frozenset([1,2,3,4]) 2 bSet = frozenset([3,4,5,6]) 3 a = {aSet:1, bSet:2} 4 print a #{frozenset([1, 2, 3, 4]): 1, frozenset([3, 4, 5, 6]): 2}