# def aaa(func): # def bbb(*args,**kwargs): # res=func(*args,**kwargs) # return res # return bbb # def auth2(x,y,z): # def auth(func): # def wrapper(*args,**kwargs): # #认证功能 # res=func(*args,**kwargs) # return res # return wrapper # return auth # # # # @auth(1,2,3) # def index(): # print('from index') # # index() import time from functools import wraps # def timmer(func): @wraps(func)#解决,返回帮助信息是原函数的帮助信息的问题,确保,引用返回原函数,帮助信息 def wrapper(*args,**kwargs): 'sssssssssssss' start_time=time.time() func(*args,**kwargs) #home(name) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) return wrapper @timmer def func(x): 'func test' print(x) func(1) print(func.__doc__) # print(help(func))
迭代器
# l=['a','b','c','d','e'] # i=0 # while i < len(l): # print(l[i]) # i+=1 # # for i in range(len(l)): # print(l[i]) #迭代器 列表,元组,字符串有索引,下标,所以是可以用索引来循环, 但是,字典,文件,集合没有索引下标,怎么来遍历取值呢,就用到迭代器,只要有iter方法,就是一个迭代器,取到iter之后,再next方法就 可以遍历完 #可迭代的:只要对象本身有__iter__方法,那它就是可迭代的 # d={'a':1,'b':2,'c':3} # d.__iter__ #iter(d) # # #执行对象下的__iter__方法,得到的结果就是迭代器 # i=d.__iter__() # # print(i.__next__()) # print(i.__next__()) # print(i.__next__()) # print(i.__next__()) # d={'a':1,'b':2,'c':3} # i=iter(d) # # while True: # # try: # # print(next(i)) # # except StopIteration: # # break # # # # l=['a','b','c','d','e'] # i=l.__iter__() # while True: # try: # print(next(i)) # except StopIteration: # break 异常捕捉,的语法 try: #正常的定义一个监视器,监视下面一句话 pass except 异常抛出: 执行异常抛出后,你定义的语句
# d={'a':1,'b':2,'c':3} # d.__iter__ # # # for k in d: #d.__iter__() 注意这里出现for的经典,这里的d,就是做了一个迭代器的功能,然后,每次,next取值,这里要放可迭代对像 # print(k) # # # s={1,2,3,4} # for i in s: # print(i) # with open('a.txt','r') as f: # for line in f: # print(line) # f=open('a.txt','r') # f.__next__ # f.__iter__ # print(f) # print(f.__iter__()) # # for line in f: #f.__iter__() # print(line) # i=f.__iter__() # while True: # try: # print(next(i)) # except StopIteration: # break #为什么要用迭代器: #优点 # 1:迭代器提供了一种不依赖于索引的取值方式,这样就可以遍历那些没有索引的可迭代对象了(字典,集合,文件) # 2:迭代器与列表比较,迭代器是惰性计算的,更节省内存,(迭代器有next方法,指向的就是一个地址,每次next才会把元素 取出来,你比如在for循环文件就是一行行的执行,) #缺点: # 1:无法获取迭代器的长度,使用不如列表索引取值灵活 # 2:一次性的,只能往后取值,不能倒着取值 # l=[1,2,3] # # print(len(l)) # i=iter(l) # # print(next(i)) # print(next(i)) # print(next(i)) # # print(next(i)) # # # for x in i: # print(x) # # for x in i: # print(x) # # for x in i: # print(x) # for x in i: # print(x) #查看可迭代对象与迭代器对象 from collections import Iterable,Iterator s='hello' l=[1,2,3] t=(1,2,3) d={'a':1} set1={1,2,3,4} f=open('a.txt') #都是可迭代的,列表,元组,集合,字典,文 件 # s.__iter__() # l.__iter__() # t.__iter__() # d.__iter__() # set1.__iter__() # f.__iter__() # print(isinstance(s,Iterable)) 正确 # print(isinstance(l,Iterable)) 正确 # print(isinstance(t,Iterable)) 正确 # print(isinstance(d,Iterable)) 正确 # print(isinstance(set1,Iterable)) 正确 # print(isinstance(f,Iterable)) 正确 #查看是否是迭代器,只有文件本身是迭代器,其他,列表,元组,字典,集合,都是可迭代对像,要调用iter方法,转换为迭代器 print(isinstance(s,Iterator)) False print(isinstance(l,Iterator)) False print(isinstance(t,Iterator)) False print(isinstance(d,Iterator)) False print(isinstance(set1,Iterator)) False print(isinstance(f,Iterator)) True
#生成器与return有何区别? #return只能返回一次函数就彻底结束了,而yield能返回多次值 生成器也是一次性的, 生成器就是个迭代器,把函数变成迭代器, #yield到底干了什么事情: #1.yield把函数变成生成器-->迭代器,这样就可以用for来循环了, #用return返回值能返回一次,而yield返回多次 #函数在暂停以及继续下一次运行时的状态是由yield保存,每次next取值执行,执行,碰到一个yield就停下来,下次next,又碰到yield停下来 from collections import Iterator #生成器就是一个函数,这个函数内包含有yield这个关键字 def test(): print('one') yield 1 #return 1 print('two') yield 2 #return 2 print('three') yield 3 #return 2 print('four') yield 4 #return 2 print('five') yield 5 #return 2 g=test() # print(g) # print(isinstance(g,Iterator)) # g.__iter__() # g.__next__() # res=next(g) # print(res) # # res=next(g) # print(res) # # res=next(g) # print(res) # # res=next(g) # print(res) # # res=next(g) # print(res) # # for i in g: # print(i) def countdown(n): print('start coutdown') while n > 0: yield n #1 n-=1 print('done') g=countdown(5) # print(g) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) # for i in g: #iter(g) # print(i) # while True: # try: # print(next(g)) # except StopIteration: # break # # def func(): # n=0 # while True: # yield n # n+=1 # # f=func() # print(next(f)) import time def tail(file_path): with open(file_path,'r') as f: f.seek(0,2) while True: line=f.readline() if not line: time.sleep(0.3) continue else: # print(line) yield line tail('/tmp/a.txt')
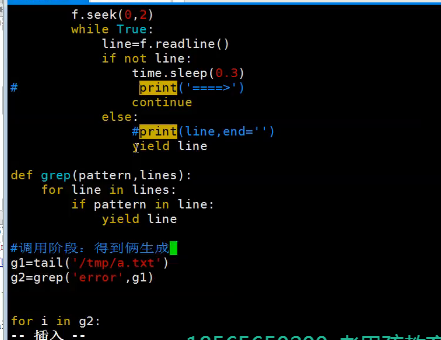
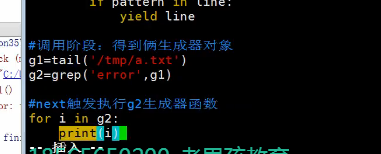
#如果在一个函数内部yield的使用方式是表达式形式的话,如x=yield,那么该函数成为协程函数 def eater(name): print('%s start to eat food' %name) food_list=[] while True: food=yield food_list print('%s get %s ,to start eat' %(name,food)) food_list.append(food) print('done') e=eater('钢蛋') # print(e) print(next(e)) print(e.send('包子')) print(e.send('韭菜馅包子')) print(e.send('大蒜包子')) #为什么叫协程? #协程怎么用?