Serial收集器
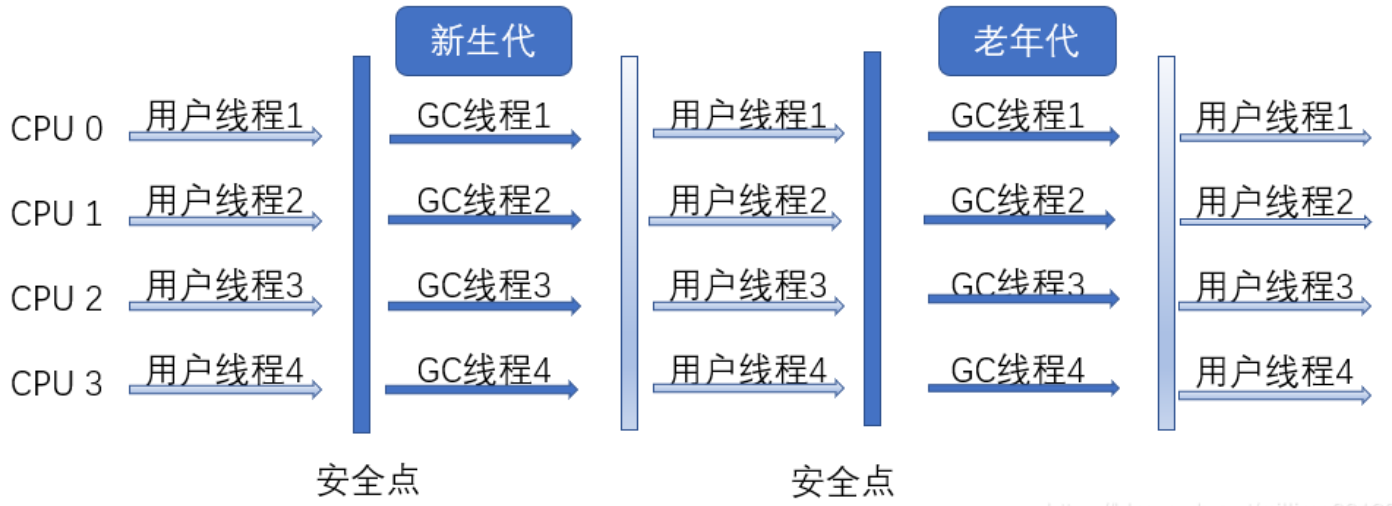
Serial收集器是最基本,发展最悠久的收集器,在JDK1.3.1之前是虚拟机新生代垃圾回收的唯一选择。这个收集器是一个单线程的。它的单线程的意义并不仅仅说明它只会使用一个CPU或者一条收集线程去完成收集工作,最重要的是,它进行垃圾收集时,其他工作线程会暂停,直到收集结束。这项工作由虚拟机在后台自动发起和执行的,在用户不可见的情况下将所有工作线程全部停掉,这对于很多应用程序来说是不可容忍的。我们可以设想一下,我们的计算机在运行1个小时就要停止5分钟的时候,这是什么情况?对于这种设计,虚拟机设计人员表示的也是非常委屈,因为不可能边收集,这边还要不断的产生垃圾对象,这样是清理不完的。
所以从1.3一直到现在,虚拟机的开发团队一直为减少因垃圾回收而产生的线程停顿所努力着,所出现的虚拟机越来越优秀,但直到现在,依然没有完全消除。
讲到这里,貌似Serial收集器已经是"食之无味弃之可惜"了,但实际上,它依然是虚拟机在Client模式下,新生代默认的垃圾收集器。它有相对于其他垃圾收集器的优势,比如由于没有线程之间切换的开销,专心做垃圾收集自然能够收获最高的线程利用效率。在用户桌面应用背景下,一般分配给虚拟机的内存不会太大,收集几十兆或者一两百兆的新生代对象,停顿时间完全可以控制在几十毫秒到一百毫秒之间,这个是可以接受的,只要不是频繁发生。因此,Serial收集器在Client模式下,对于新生代来说依然是一个很好的选择。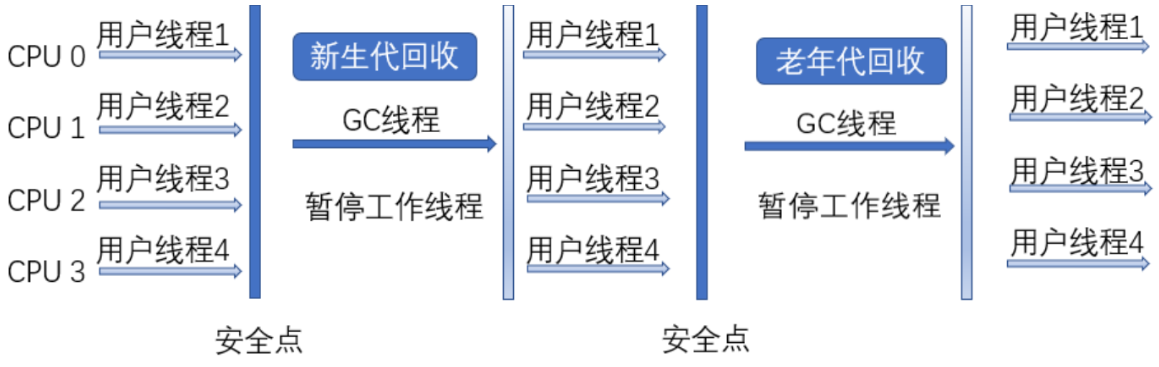
ParNew收集器
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾回收之外,其余可控参数,收集算法,停止工作线程,对象分配原则,回收策略等与Serial收集器完全一致。
除了多线程实现垃圾收集之外,其他没有什么太多创新之处,但是它确实Server模式下的新生代的首选的虚拟机收集器。其中一个重要的原因就是除了Serial收集器外,只有它能与CMS配合使用。在JDK1.5时期,HotSpot推出了一款在强交互应用划时代的收集器CMS,这款收集器是HotSpot第一款真正意义上的并发收集器,第一次实现了垃圾回收与工作线程同时工作的可能性,换而言之,你可以边污染,边收集。
不过CMS作为老年代的收集器,却无法与1.4中发布的最新的新生代垃圾收集器配合使用,反之只能使用Serial或者Parnew中的一个。ParNew收集器可以使用-XX:+UseParNewGC强行指定它,或者使用-XX:+UseConcMarkSweepGC选项后的默认新生代收集器。
ParNew收集器在单CPU环境下绝对不会有比Serial收集器更好的效果,甚至优于存在线程交互开销,该收集器在通过超线程技术实现的两个CPU的环境下都不能保证百分之百超越Serial收集器。当然,随着CPU数量的增加,对于GC时系统的有效资源利用还是很有好处的。在CPU非常多的情况下,可以使用-XX:ParallelGCThreads来限制垃圾回收线程的数量。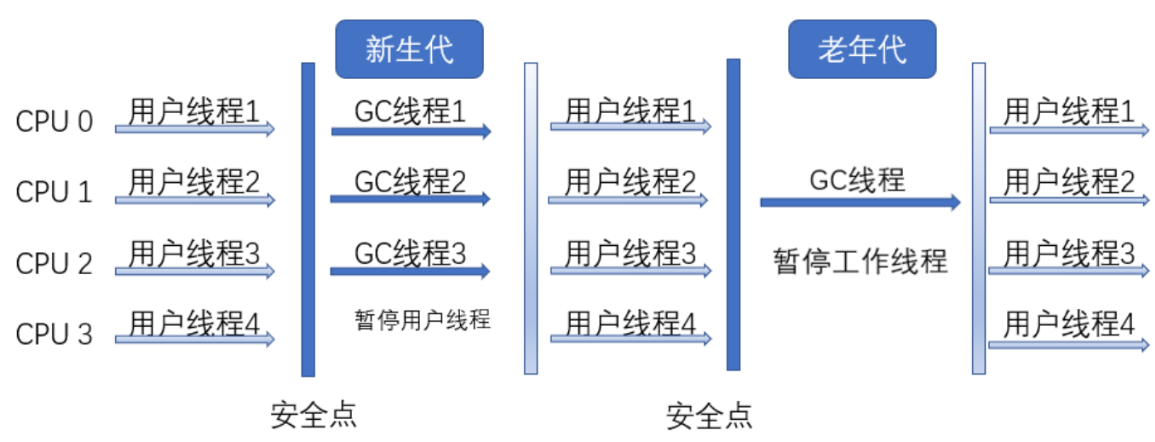
Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代收集器,采用复制算法,又是并行的多线程垃圾收集器。它的关注点与其它收集器的关注点不一样,CMS等收集器的关注点在于缩短垃圾回收时用户线程停止的时间,而Parallel Scavenge收集器则是达到一个可控制的吞吐量,所谓吞吐量就是CPU运行用户线程的时间与CPU运行总时间的比值,即 吞吐量 = (用户线程工作时间)/(用户线程工作时间 + 垃圾回收时间),比如虚拟机总共运行100分钟,垃圾收集消耗1分钟,则吞吐量为99%。停顿时间越短越适合与用户交互的程序,良好的响应速度能提高用户体验,但是高吞吐量则可以高效率的利用CPU的时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的程序。有两个参数控制吞吐量,分别为最大垃圾收集时间: -XX:MaxGCPauseMills, 直接设置吞吐量的大小: -XX:GCTimeRatio
Serial Old收集器
Serial Old收集器是Serial收集器的老年代版本,它同样是一个单线程收集器,使用标记-整理算法,这个收集器的主要目的也是在与给Client模式下使用。如果在Server模式下,还有两种用途,一种是在jdk5以前的版本中配合Parallel Scavenge收集器使用,另一种用途作为CMS的备用方案,在并发收集发生Concurrent Mode Failure时使用。
Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法,这个收集器在jdk6中才开始使用的,在此之前Parallel Scavenge收集器一直处于比较尴尬的阶段,原因是,如果新生代采用了Parallel Scavenge收集器,那么老年代除了Serial Old之外,别无选择,由于老年代Serial在服务端的拖累,使得使用了Parallel Scavenge收集器也未必能达到吞吐量最大化的效果,由于单线程的老年代无法充分利用服务器多CPU的处理能力,在老年代很大而且硬件比较高级的环境中,这种组合的吞吐量甚至不如Parallel Scavenge收集器 + CMS。直到Parallel Old收集器出现后,"吞吐量优先收集器"终于有了名副其实的组合,在注重吞吐量优先和CPU资源敏感的场合,可以采用Parallel Scavenge收集器 + Parallel Old收集器