一:web框架本质
所有的web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端,这样我们就可以实现web框架了
二:半成品自定义web框架
可以说web服务器本质上都是在这个一段代码的基础上扩展出来的。这段代码就是web框架的基石
import socket
server = socket.socket() # 应用层
server.bind(('127.0.0.1',8080)) # # -> 传输层(段,端口,tcp) -> 网络层(包,ip,arp) -> 数据链路层(帧,mac,ethernet) -> 物理层(为,二进制)
server.listen(5) # 半连接池,当前可以来连接请求的最大个数是5
while True:
conn,client = server.accept()
data_bytes = conn.recv(1024)
if not data_bytes:
break
conn.send(b'good')
conn.close()
用户的浏览器输入网址,给服务器端发送数据,那么浏览器会发送什么数据?怎么发?这个怎么确定?你的网站是一套规则,他的网站时另外一套规则,这个就不能愉快的聊天了
所以,必须有一个统一的规则,让大家发消息,接收消息,定一个规范,大家都是使用同一个规范。
HTTP协议就是一个规范,以后浏览器发送请求消息,服务器返回响应消息,都按照这个规范来
HTTP协议规定了客户端和服务端之间的通信格式,那http协议是如何规定消息格式?
三:HTTP协议
超文本传输协议是用来规定客户端和服务端之间的数据交互格式
该协议你可以不遵循 但是你写的服务端就不能被浏览器正常访问 你就自己跟自己玩
你就自己写客户端 用户想要使用 就下载你专门的app即可
一:HTTP协议的四大特性
-
基于请求响应,向服务端发送请求,服务端响应客户端请求
-
基于
tcp/ip之上的应用层协议 -
无状态,不保存用户的信息
举例: 波多这个人来了一千次 你都记不住 每次都当他如初见.
拓展: 由于
HTTP协议是无状态的 所以后续出现了一些专门用来记录用户状态的技术.cookie、session、token... -
无连接状态
请求来一次我响应一次,之后我们两个就没有任何连接关系
扩展: 长链接. 之后出现了websocket可以实现长链接, 可以让双方建立连接之后默认不断开. 可以实现: 群聊功能、服务端主动给客户端发送消息
二:HTTP GET请求
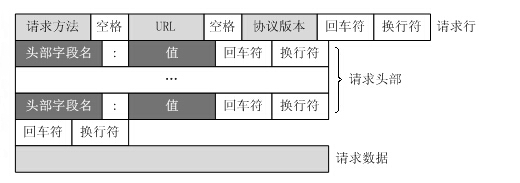 的格式
的格式
请求首行:
请求头
请求体(并不是所有的请求方式都有,GET 没有,post有,post放的是请求提交的敏感数据)
三:请求方式
get请求:朝服务端要数据(也可以提交数据)
输入网址获取内容
post请求:朝服务端提交数据
用户注册,登录
get和post区别
- get提交的数据会放在url之后,以?分割url和传输数据,参数之间以&相连接,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
- GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
四:响应状态码
用一串简单的数字来表示复杂的状态或者描述者信息,例如:返回响应状态码为403,表示请求资源不存在
1XX: 信息.服务器收到请求,需要请求者继续执行操作.
2XX: 成功.操作被服务器成功接收并处理.
200OK表明该请求被成功地完成,所请求的资源发送回客户端.
3XX: 重定向.需要进一步的操作以完成请求.(比如: 当你在访问一个需要登陆之后才能看的页面你会发现会自动跳转到登陆页面)
4XX: 客户端请求错误.请求包含语法错误或无法完成请求
404: 请求资源不存在(服务器无法根据客户端的请求找到对应的网页资源)
403: 服务器理解请求客户端的请求,但是拒绝执行此请求.(当前请求不合法或者不符合访问资源的条件.比如: 这是千万级别的俱乐部, 只有999万的你被限制无法进入)
5XX: 服务器内部错误
500: 服务器内部错误,无法完成请求
补充: 上述的状态码是HTTP协议规定的,其实到了公司之后每个公司还会自己定制自己的状态及提示信息
五:URL同一资源定位符
形式: scheme:[//[user:password@]host[:port]][/]path[?query-string][#anchor]
提示: 方框内的是可选部分。
scheme:协议(例如:http, https, ftp)
user : password@用户的登录名以及密码
host:服务器的IP地址或者域名
port:服务器的端口(如果是走协议默认端口,http 80 or https 443)
path:访问资源的路径
query-string:参数,它通常使用键值对来制定发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
四:查看客户端和服务端的通信格式
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
data_bytes = conn.recv(8192)
print(data_bytes) # 将浏览器发来的消息打印出来
"""
===================== HTTP协议的请求数据格式4部份 =====================
b'GET / HTTP/1.1
# 请求首行(标识HTTP协议版本,当前请求方式)
Host: 127.0.0.1:8080
# 请求头(一大堆k,v键值对)
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
' #
# 请求体(并不是所有的请求方式都有. get没有post有, post存放的是请求提交的敏感数据)
b''
"""
conn.send(b'ok')
conn.close()
然后我们再看一下我们访问博客园官网时浏览器收到的响应信息是什么。
响应相关信息可以在浏览器调试窗口的network标签页中看到。
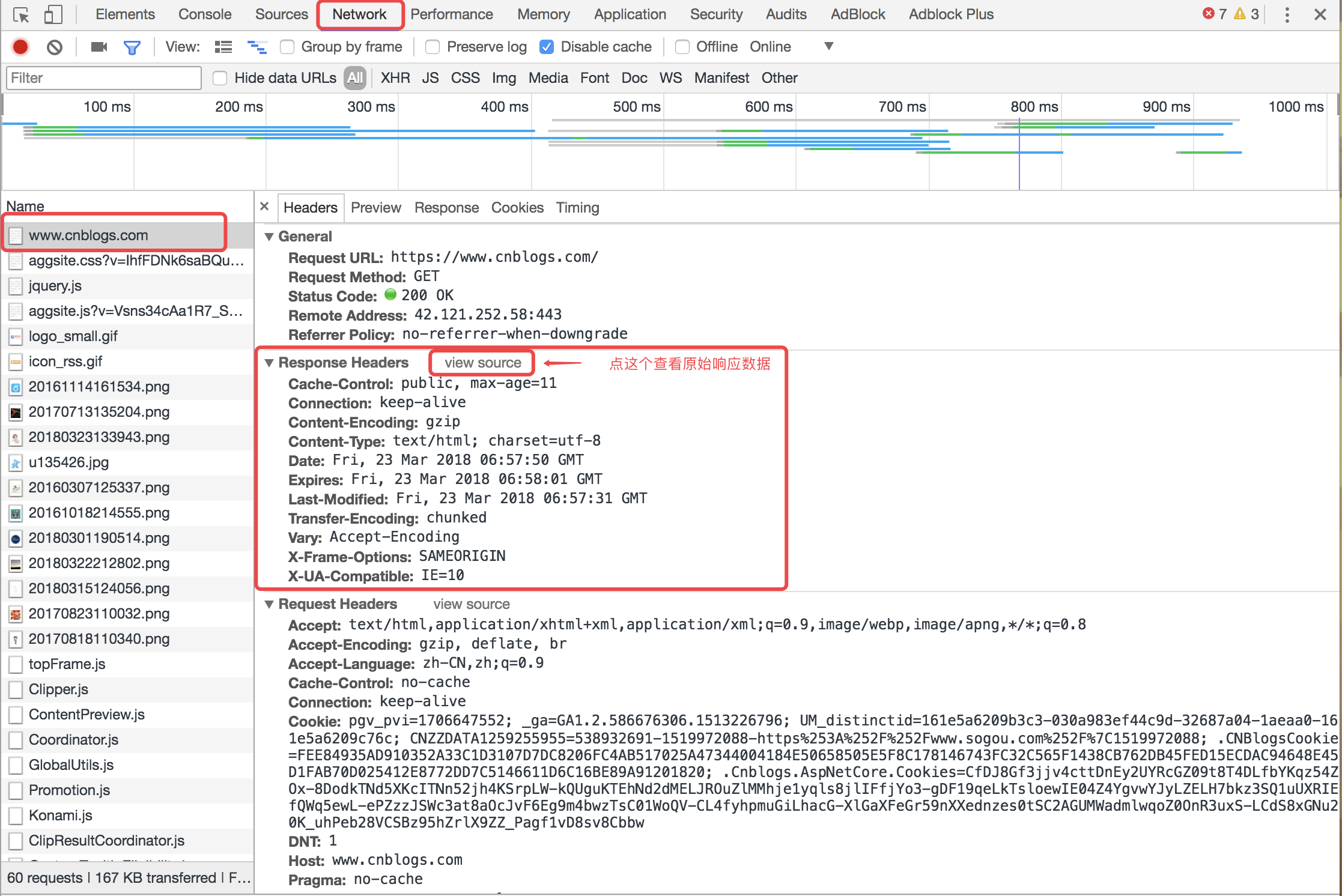
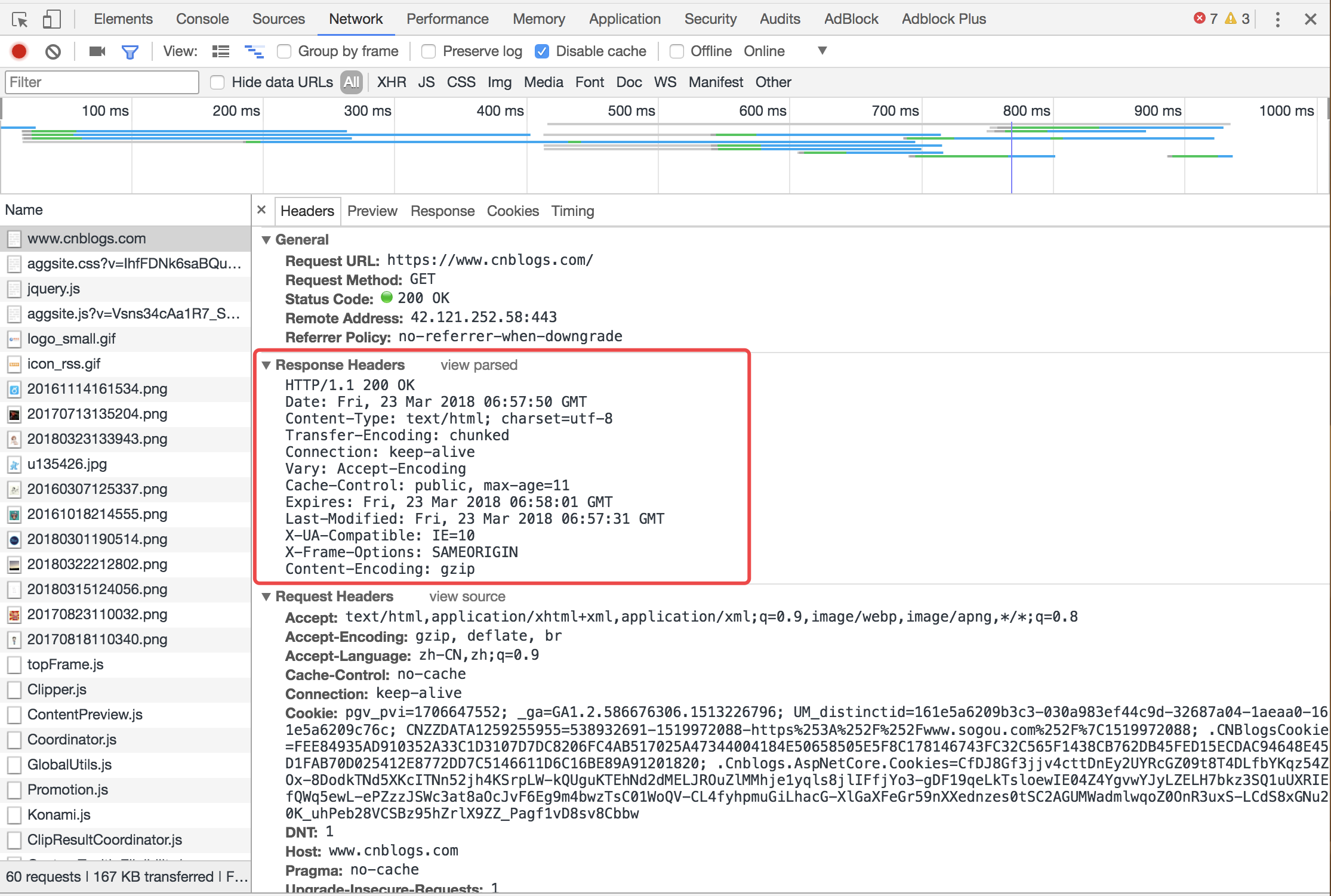
点击view source之后显示如下图:
五. 处女版自定义web框架
由上面可以知道, 我们想让自己写的web server端正经起来,必须要让我们的Web server在给客户端回复消息的时候按照HTTP协议的规则加上响应状态行,这样我们就实现了一个正经的Web框架了。
TCP服务端:
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
data_bytes = conn.recv(8192)
print(data_bytes)
'''
===================== HTTP协议的请求数据格式4部份 =====================
b'GET / HTTP/1.1
# 请求首行(标识HTTP协议版本,当前请求方式)
Host: 127.0.0.1:8080
# 请求头(一大堆k,v键值对)
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
' #
# 请求体(并不是所有的请求方式都有. get没有post有, post存放的是请求提交的敏感数据)
b'GET /favicon.ico HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept: image/webp,image/apng,image/*,*/*;q=0.8
Referer: http://127.0.0.1:8080/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
'
b'GET / HTTP/1.1
Host: 127.0.0.1:8080
# 请求头(一大堆k,v键值对)
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
'
b'' # 请求体(并不是所有的请求方式都有. get没有post有, post存放的是请求提交的敏感数据)
'''
conn.send(b'HTTP/1.1 200 OK
')
'''
=========== HTTP协议的响应数据格式4部分 ===========
HTTP/1.1 200 OK # 响应首行(标识HTTP协议版本,响应状态码)
# 响应头(一大堆k,v键值对). 这里指定为空
#
'''
conn.send(b'Are you OK?') # 响应体(返回给浏览器展示给用户看的数据)
conn.close()
浏览器客户端: 实现
六. 根据URL中不同的路径返回不同的内容
这样就结束了吗? 如何让我们的Web服务根据用户请求的URL不同而返回不同的内容呢?
小事一桩,我们可以从请求相关数据里面拿到请求URL的路径,然后拿路径做一个判断...
Copyimport socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, client_addr = server.accept()
data_bytes = conn.recv(8192)
print(data_bytes)
'''
b'GET /index HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
'
'''
path = data_bytes.split()[1]
print(path) # b'/index'
conn.send(b"HTTP/1.1 200 OK
") # 因为要遵循HTTP协议,所以回复的消息也要加状态行
if path == b'/index':
response = b'you can you not bb: %s' % path
elif path == b'/login':
response = b'you can you not bb: %s' % path
else:
response = b'404 Not Found'
conn.send(response)
conn.close()
后缀是/index时
 ]
]
后缀是/login时

后缀没有匹配到时

七. 根据不同的路径返回不同的内容--函数进阶版
上面的代码解决了不同URL路径返回不同内容的需求。
但是问题又来了,如果有很多很多路径要判断怎么办?难道要挨个写if判断? 当然不用,我们有更聪明的办法。
Copyimport socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
# 将返回不同的内容部分封装成函数
def index(path):
s = "This is {} page table!".format(path)
return s
def login(path):
s = "This is {} page table!".format(path)
return s
def error(path):
return '404 not found: {}'.format(path)
# 定义一个url和实际要执行的函数的对应关系
urls = [
('/index', index),
('/login', login),
]
while True:
conn, client_addr = server.accept()
data_bytes = conn.recv(8192)
print(data_bytes)
path = data_bytes.split()[1].decode('utf-8') # 分离出的访问路径, 再把收到的字节类型的数据转换成字符串
print(path) # '/index'
conn.send(b"HTTP/1.1 200 OK
") # 因为要遵循HTTP协议,所以回复的消息也要加状态行
func = None # 定义一个保存将要执行的函数名的变量
for url in urls:
if path == url[0]:
func = url[1]
break
if func:
response = func(path)
else:
response = error(path)
# 返回具体的响应消息
conn.send(response.encode('utf-8'))
print(response.encode('utf-8'))
conn.close()
后缀是/index时

后缀是/login时
后缀没有匹配到时
八. 动静态网页
Copy# 判断条件: 根据html页面内容是写死的还是从后端动态获取的
静态网页: 页面上的数据是直接写死的 万年不变
动态网页: 数据是实时获取的. 如下例子:
1.后端获取当前时间展示到html页面上
2.数据是从数据库中获取的展示到html页面上
九. 静态网页: 返回具体的HTML文件
完美解决了不同URL返回不同内容的问题。 但是我不想仅仅返回几个字符串,我想给浏览器返回完整的HTML内容,这又该怎么办呢?
没问题,不管是什么内容,最后都是转换成字节数据发送出去的。 我们可以打开HTML文件,读取出它内部的二进制数据,然后再发送给浏览器。
Copyimport socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
# 将返回不同的内容部分封装成函数
def _open_read(filename):
with open(filename, 'rt', encoding='utf-8') as f:
return f.read()
def index(path):
return _open_read('index.html')
def login(path):
return _open_read('login.html')
def error(path):
return _open_read('error.html')
# 定义一个url和实际要执行的函数的对应关系
urls = [
('/index', index),
('/login', login),
]
while True:
conn, client_addr = server.accept()
data_bytes = conn.recv(8192)
print(data_bytes)
path = data_bytes.split()[1].decode('utf-8') # 分离出的访问路径, 再把收到的字节类型的数据转换成字符串
print(path) # '/index'
conn.send(b"HTTP/1.1 200 OK
") # 因为要遵循HTTP协议,所以回复的消息也要加状态行
func = None # 定义一个保存将要执行的函数名的变量
for url in urls:
if path == url[0]:
func = url[1]
break
if func:
response = func(path)
else:
response = error(path)
# 返回具体的响应消息
conn.send(response.encode('utf-8'))
print(response.encode('utf-8'))
conn.close()
后缀是/index时
后缀是/login时
后缀没有匹配到时
templates文件: https://www.cnblogs.com/yang1333/articles/12942729.html
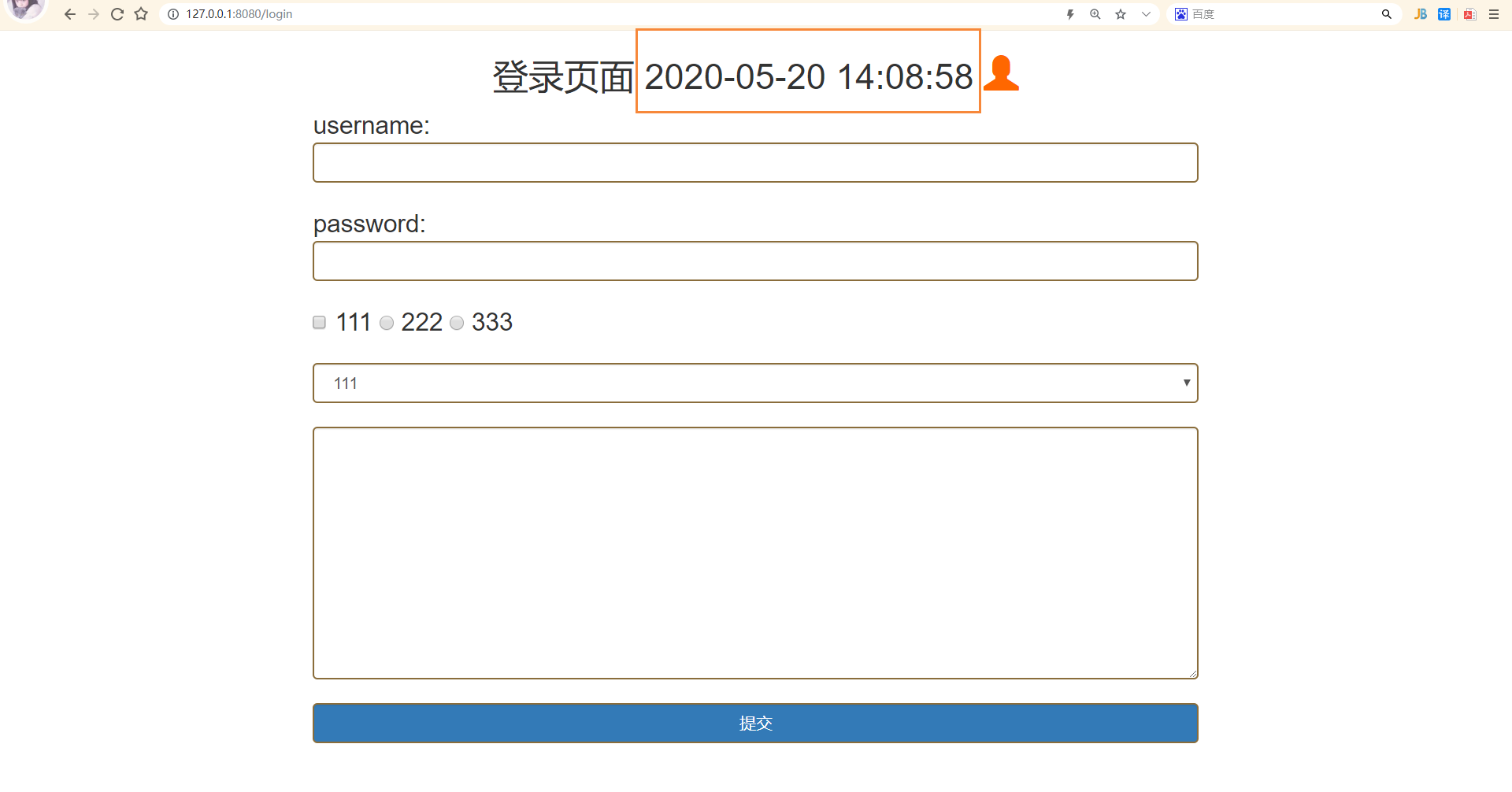
十. 动态网页: 后端获取当前时间展示到html页面上
Copyimport socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
# 将返回不同的内容部分封装成函数
def _open_read(filename):
with open(filename, 'rt', encoding='utf-8') as f:
return f.read()
def index(path):
return _open_read('index.html')
from datetime import datetime
def login(path): # !!!动态网页!!: 后端获取当前时间展示到html页面上
data = _open_read('login.html')
data = data.replace('qwertyuiop', datetime.now().strftime('%Y-%m-%y %X'))
return data
def error(path):
return _open_read('error.html')
# 定义一个url和实际要执行的函数的对应关系
urls = [
('/index', index),
('/login', login),
]
while True:
conn, client_addr = server.accept()
data_bytes = conn.recv(8192)
print(data_bytes)
path = data_bytes.split()[1].decode('utf-8') # 分离出的访问路径, 再把收到的字节类型的数据转换成字符串
print(path) # '/index'
conn.send(b"HTTP/1.1 200 OK
") # 因为要遵循HTTP协议,所以回复的消息也要加状态行
func = None # 定义一个保存将要执行的函数名的变量
for url in urls:
if path == url[0]:
func = url[1]
break
if func:
response = func(path)
else:
response = error(path)
# 返回具体的响应消息
conn.sendall(response.encode('utf-8'))
print(response.encode('utf-8'))
conn.close()
templates文件: https://www.cnblogs.com/yang1333/articles/12942729.html
十一. 使用wsgiref模块替换之前 web框架的socket server部分
之前的缺陷:
Copy1. 代码重复: 服务端socket代码需要我们自己写
2. http格式的数据自己处理, 并且只能拿到url后缀 其他数据获取繁琐.(只能拿到用户输入的路由).
现在利用swgiref模块优势:
Copy1. swgiref模块帮助我们封装了socket代码
2. 帮我们处理http格式的数据
swgiref模块就是一个web服务网关接口:
1. 请求来的时候帮助你自动拆分http格式数据并封装成非常方便处理的数据格式 -> env大字典
2. 响应走的时候帮你将数据再打包成符合http格式的数据
还有一点是, 上面没有对不同的功能进行分类, 后面功能将会越来越多, 因此我们分文件管理:
Copy"""
urls.py
路由与视图函数对应关系
补充: 视图函数可以是函数其实也可以是类
views.py
视图函数(后端业务逻辑)
templates文件夹
专门用来存储html文件
"""
# 按照功能的不同拆分之后 后续添加功能只需要在urls.py书写对应关系然后取views.py书写业务逻辑即可
启动脚本
Copyfrom wsgiref.simple_server import make_server
from views import *
from urls import *
def run_server(env, response):
"""
函数名定义什么都无所谓, 我们这里就用run_server.
:param env: 请求相关的所有数据.
是一个大字典, wsgiref模块帮你处理好http格式的数据 封装成了字典让你更加方便的操作
:param response: 响应相关的所有数据.
:return: 返回给浏览器的数据, 返回个格式必须是'return [二进制格式的数据]' 这种样式
"""
response('200 OK', []) # 响应首行 响应头
path_info = env.get('PATH_INFO')
print(path_info)
func = None # 定义一个变量 存储匹配到的函数名
for url in urls:
if path_info == url[0]:
func = url[1] # 将url对应的函数名赋值给func
break # 匹配到一个之后 应该立刻结束for循环
if func: # 判断func是否有值
data = func(env)
else:
data = error(env)
return [data.encode('utf-8')]
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run_server)
"""
会实时监听127.0.0.1:8080地址 只要有客户端来了
都会交给run函数处理(加括号触发run函数的运行)
flask启动源码
make_server('127.0.0.1',8080,obj)
__call__
"""
server.serve_forever() # 启动服务端
urls.py
Copyfrom views import *
# 定义一个url和实际要执行的函数的对应关系
urls = [
('/index', index),
('/login', login),
]
views.py
Copy# 将返回不同的内容部分封装成函数
def _open_read(filename):
with open(filename, 'rt', encoding='utf-8') as f:
return f.read()
def index(env):
return _open_read('templates/index.html')
from datetime import datetime
def login(env): # !!!动态网页!!: 后端获取当前时间展示到html页面上
data = _open_read('templates/login.html')
data = data.replace('qwertyuiop', datetime.now().strftime('%Y-%m-%y %X'))
return data
def error(env):
return _open_read('templates/error.html')
templates文件: https://www.cnblogs.com/yang1333/articles/12942729.html
十二. 续wsgiref再通过jinja2优化上面replace, 再通过pymysql实现后端获取数据库中数据展示到前端页面
jinja2作用: jiaja2的原理就是字符串替换,我们只要在HTML页面中遵循jinja2的语法规则写上,其内部就会按照指定的语法进行相应的替换,从而达到动态的返回内容.
jinjia2模板语法:
"""定义变量使用双花括号"""
{{ user_list }}
"""for循环使用双花括号+百分号"""
{% for user_dict in user_list %}
{{ user_dict.id }} # 支持python操作对象的方式取值
{% endfor %}
使用国内清华源下载:
# 前提: 配置了环境变量
pip3.8 install -i https://pypi.tuna.tsinghua.edu.cn/simple jinja2
from wsgiref.simple_server import make_server
from views import *
from urls import *
def run_server(env, response):
"""
函数名定义什么都无所谓, 我们这里就用run_server.
:param env: 请求相关的所有数据.
是一个大字典, wsgiref模块帮你处理好http格式的数据 封装成了字典让你更加方便的操作
:param response: 响应相关的所有数据.
:return: 返回给浏览器的数据, 返回个格式必须是'return [二进制格式的数据]' 这种演示
"""
response('200 OK', []) # 响应首行 响应头
path_info = env.get('PATH_INFO')
print(path_info)
func = None # 定义一个变量 存储匹配到的函数名
for url in urls:
if path_info == url[0]:
func = url[1] # 将url对应的函数名赋值给func
break # 匹配到一个之后 应该立刻结束for循环
if func: # 判断func是否有值
data = func(env)
else:
data = error(env)
return [data.encode('utf-8')]
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run_server)
"""
会实时监听127.0.0.1:8080地址 只要有客户端来了
都会交给run函数处理(加括号触发run函数的运行)
flask启动源码
make_server('127.0.0.1',8080,obj)
__call__
"""
server.serve_forever() # 启动服务端
views
Copyimport pymysql
from jinja2 import Template
# 将返回不同的内容部分封装成函数
def _open_read(filename):
with open(filename, 'rt', encoding='utf-8') as f:
return f.read()
def index(env):
return _open_read('templates/index.html')
from datetime import datetime
def login(env): # !!!动态网页!!: 后端获取当前时间展示到html页面上
data = _open_read('templates/login.html')
data = data.replace('qwertyuiop', datetime.now().strftime('%Y-%m-%y %X'))
return data
def error(env):
return _open_read('templates/error.html')
def _open_mysql():
"""
去数据库中获取数据 传递给html页面 借助于模版语法 发送给浏览器. 以下为数据库准备数据:
drop database db10; # 注意: 操作危险, 酌情使用
create database db10 charset utf8;
use db10;
create table user(
id int primary key auto_increment,
username varchar(25) not null,
sex enum('男', '女'),
password varchar(255) not null,
hobbies set('吃生蚝', '喝泔水', '吃虾米', '遛狗')
);
insert into user(username, sex, password, hobbies) values
('egon', '男', 'egon3714', '吃虾米'),
('jason', '女', 'jason3714', '喝泔水,遛狗'),
('egon', '男', 'egon3714', '吃生蚝,喝泔水'),
('alex', '男', 'alex3714', '遛狗'),
('lxx', '男', 'lxx3714', '遛狗');
:return:
"""
print(11111111111111111)
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='1234',
database='db10',
charset='utf8',
autocommit=True,
# passwd=1234,
# db='db10',
)
print(22222222222222222)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
affected_rows = cursor.execute('select * from user;')
print(affected_rows)
if affected_rows:
user_list_dict = cursor.fetchall()
return user_list_dict
else:
print('对不起, 你要查找的数据不存在!')
cursor.close()
conn.close()
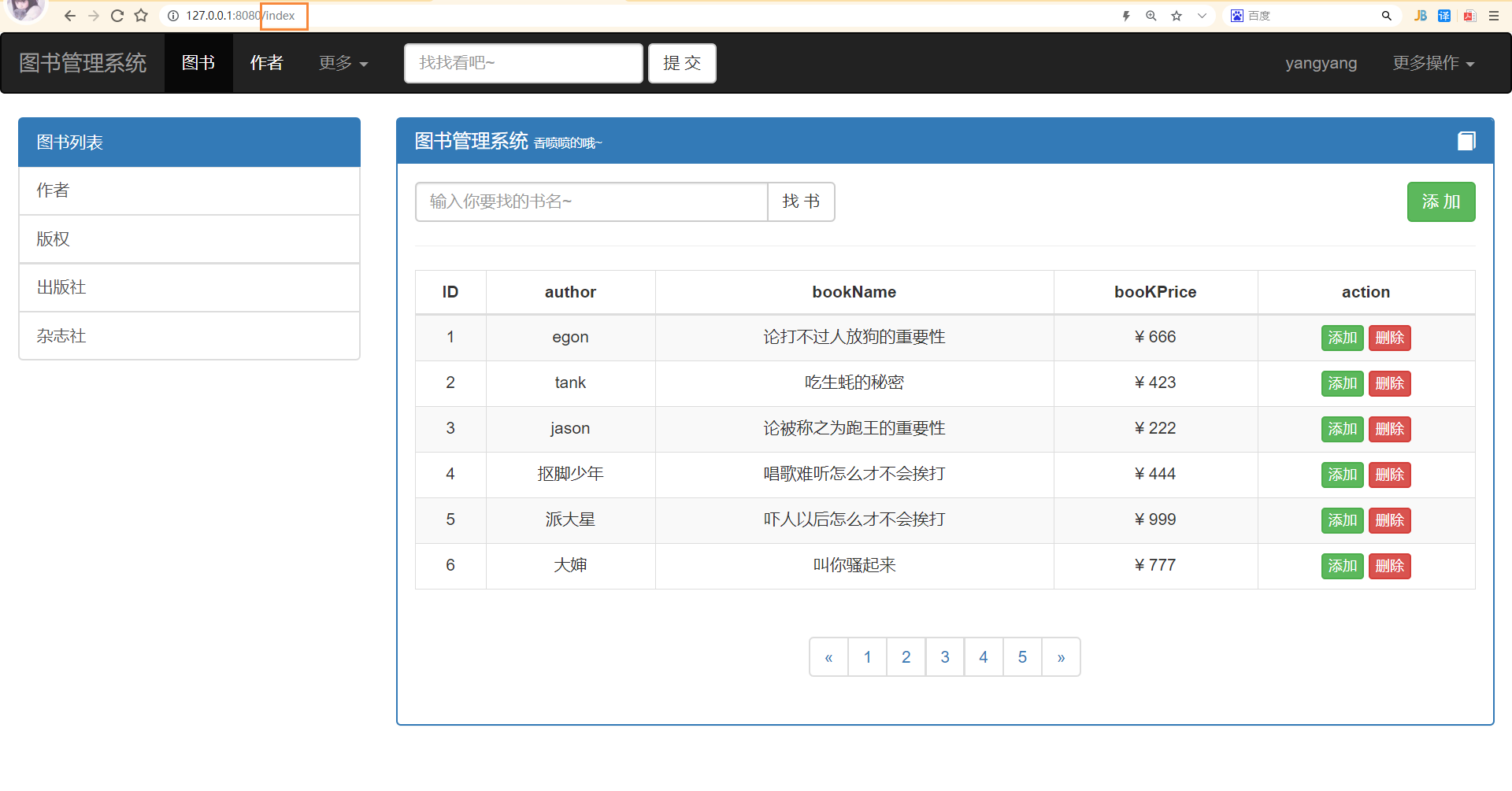
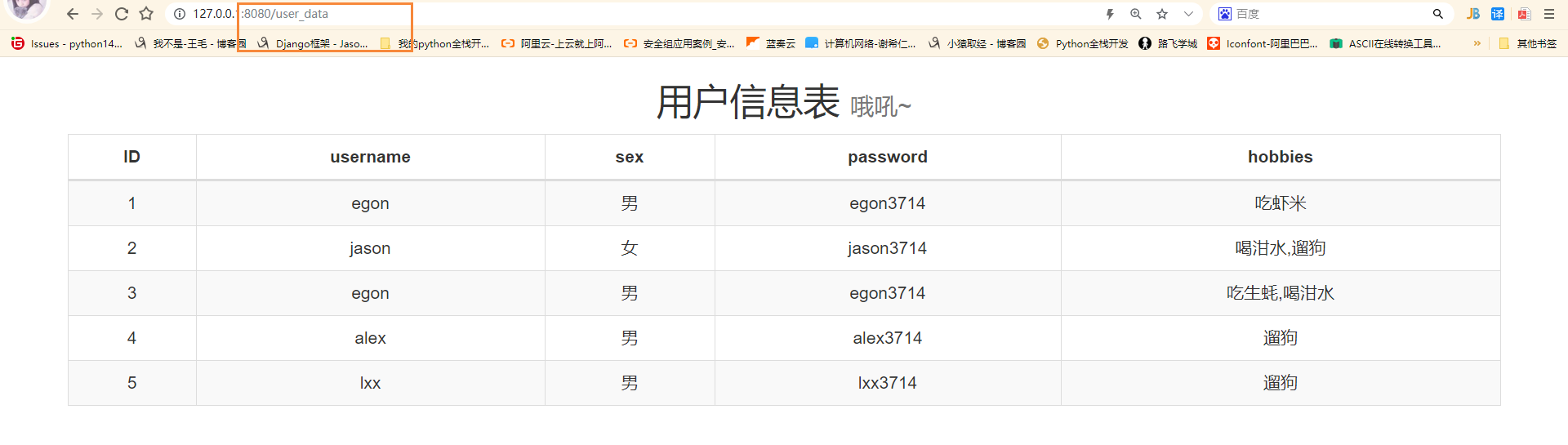
def user_data(env):
data = _open_read('templates/user_data.html')
user_list_dict = _open_mysql()
if user_list_dict:
temp = Template(data)
res = temp.render(user_list=user_list_dict) # 给user_data.html传递数据user_list_dict 页面上通过变量名user_list就能够拿到
return res
return error(env)
urls
Copyfrom views import *
# 定义一个url和实际要执行的函数的对应关系
urls = [
('/index', index),
('/login', login),
('/user_data', user_data),
]
templates文件: https://www.cnblogs.com/yang1333/articles/12942729.html
十三. 总结
1. 自定义简易版本web框架请求流程图
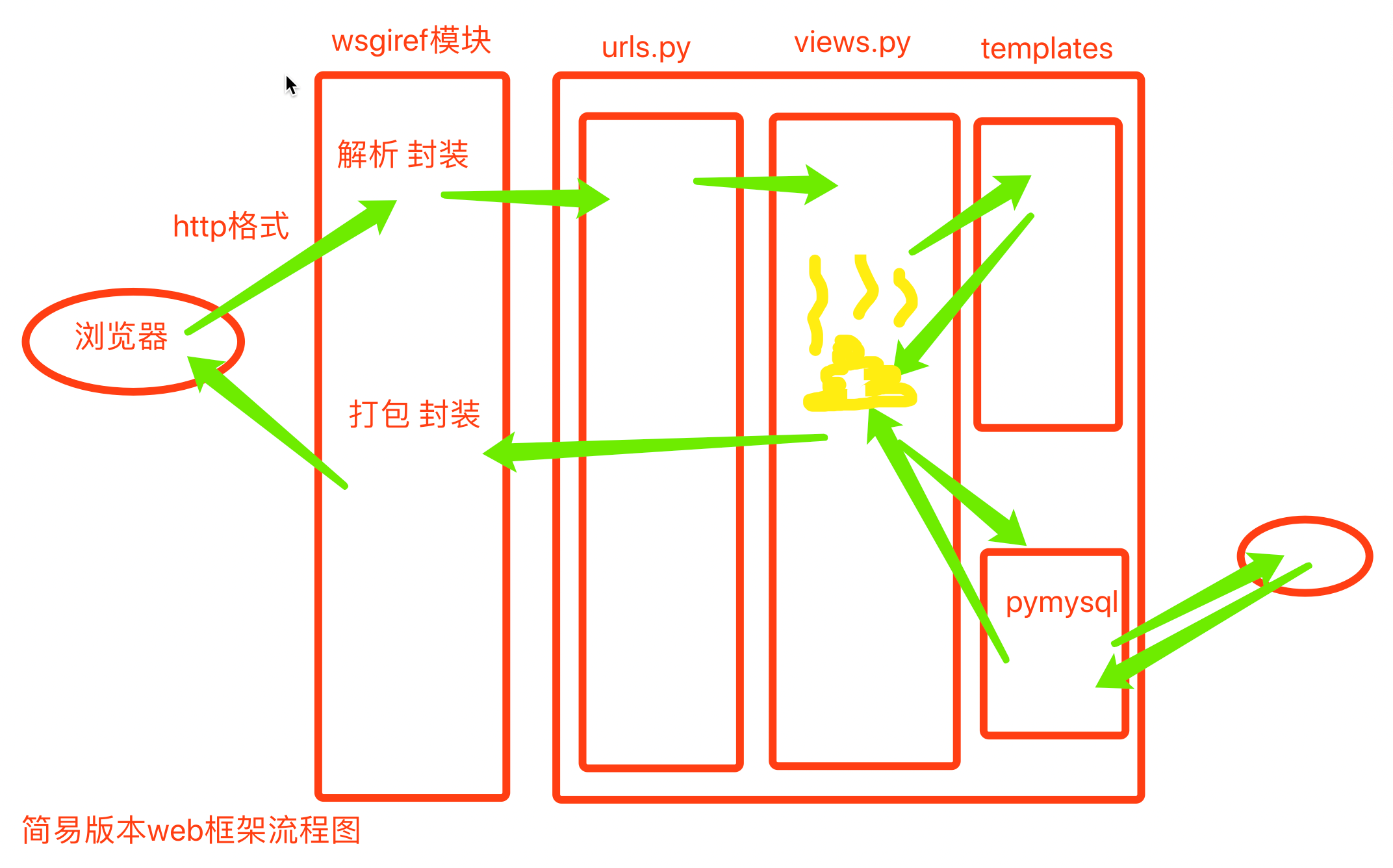
流程图流程:
浏览器客户端
wsgiref模块
请求来: 处理浏览器请求, 解析浏览器http格式的数据, 封装成大字典(PATH_INFO中存放的用访问资源的路径)
响应去: 将数据打包成符合http格式 再返回给浏览器
后端
urls.py: 找用处输入的路径有没有与视图函数的对应关系. 如果有则取到views.py找对应的视图函数.
views.py:
功能1(静态): 视图函数找templates中的html文件, 返回给wsgiref做HTTP格式的封包处理, 再返回给浏览器.
功能2(动态): 视图函数通过pymysql链接数据库, 通过jinja2模板语法将数据库中取出的数据在tmpelates文件夹下的html文件做一个数据的动态渲染, 最后返回给wsgiref做HTTP格式的封包处理, 再返回给浏览器.
功能3(动态): 也可以通过jinja2模板语法对tmpelates文件夹下的html文件进行数据的动态渲染, 渲染完毕, 再经过wsgiref做HTTP格式的封包处理, 再返回给浏览器.
templates: html文件
数据库
2. 基本使用流程
# wsgiref模块: socket服务端(后端)
from wsgiref.simple_server import make_server
def run_server(env, response):
"""
函数名定义什么都无所谓, 我们这里就用run_server.
:param env: 请求相关的所有数据.
是一个大字典, wsgiref模块帮你处理好http格式的数据 封装成了字典让你更加方便的操作
:param response: 响应相关的所有数据.
:return: 返回给浏览器的数据, 返回个格式必须是'return [二进制格式的数据]' 这种样式
"""
response('200 OK', []) # 响应首行 响应头
return [二进制格式的数据]
if __name__ == '__main__':
server = make_server(host, port, app) # app=run_server
server.serve_forever()
# urls.py: 路由与视图函数对应关系
urls = [(路由, 视图函数), ]
# views.py:
def 视图函数():
pass
# pymysql模块: socket服务端(后端)与数据库交互
import pymysql
conn = pymysql.connection(host, port, user, password, database, charset='utf8')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
affected_rows = cursor.execute(sql);
cursor.fetchall()
cursor.close()
conn.close()
# jinja2模块: 后端与html文件交互. 本质是一种替换操作
from jinja2 import Template
temp = Template(data) # data是要操作的替换的数据
res = temp.render(user=user_date) # user是给html页面传的操作变量
# templates文件夹: 管理html文件
html中使用jinja2模板语法:
定义变量: {{ user }}
for循环: {% for xxx in user %} ... {% endfor %} 如果xxx是一个对象, 可以`xxx.id`或者`xxx['id']`取值
十四. python三大主流web框架
1. 三大主流web框架介绍
# django
特点: 大而全 自带的功能特别特别特别的多 类似于航空母舰
不足之处: 有时候过于笨重
# flask
特点: 小而精 自带的功能特别特别特别的少 类似于游骑兵
第三方的模块特别特别特别的多,如果将flask第三方的模块加起来完全可以盖过django, 并且也越来越像django
不足之处: 比较依赖于第三方的开发者
# tornado
特点: 异步非阻塞 支持高并发 牛逼到甚至可以开发游戏服务器
不足之处: 待定
SANIC
FASKAPI
...
2. web框架可以分成三部分
A: socket部分
B: 路由与视图函数对应关系(路由匹配)
C: 模版语法
# django
A用的是别人的 wsgiref模块
B用的是自己的
C用的是自己的 没有jinja2好用 但是也很方便
# flask
A用的是别人的 werkzeug(内部还是wsgiref模块)
B自己写的
C用的别人的 jinja2
# tornado
A,B,C都是自己写的