数据记录查询:
1.简单数据记录查询:
select * from table_name;
select allfield from table_name;
select distinct(属性名) from table_name; // 避免重复查询
实现四则元素: select 运算;
连接查询(设置显示格式数据查询):
select concat(属性字段1,"描述",属性字段2) from table_name;
例子: select concat(ename," num is ",empno) from t_employee;
2.条件数据记录查询:
select * from table_name where 条件1 and|or 条件2.......;// 可以有多个条件
select * from table_name where 属性字段 between 范围下限 and 范围上限;// 他的意思是属性字段的值 >= 范围下限 and 属性字段的值 <= 范围上限;
select * from table_name where 属性字段 is null;// 查询属性字段为NULL的值,null不等于"";
select * from table_name where 属性字段 in (范围);// 范围查找,in也可以换为not in取反的意思.(使用关键字IN,查询的集合中如果存在NULL,则不会影响查询;如果使用NOT IN,查询的集合中存在NULL,则不会有任何的查询结果)
例子: select * from t_dept where deptno in (10,30,50,70);
带LIKE关键字的查询:
"_"通配符,匹配单个字符,
"%"通配符,匹配任意长度的字符串,可以是0个字符,一个字符,也可以是很多个字符.
查看变量: show variables like '%变量名%',表示包含变量名的变量,'%变量名',表示以变量名结尾的变量,'变量名%'表示以变量名开头的变量,例子:show variables '%max%';
select * from table_name where 属性字段 like '%%';// 一个%和两个%%都表示全部的结果.
select * from table_name where 属性字段 like '%变量';//表示以变量结尾的结果集.
select * from table_name where 属性字段 like '变量%';//表示以变量开头的结果集.
select * from table_name where 属性字段 like '%变量%';//表示包含变量的结果集.
如果要查询带有%的结果集呢?转义字符,将%转义为\%,其余的不变.
3.排序(order by)数据记录查询:
select * from table_name order by 属性字段 ASC|DESC;// ASC升序,DESC降序
select * from table_name order by 属性字段1 ASC|DESC, 属性字段2 ASC|DESC;先按照属性字段一进行排列,字段一相同的再用属性字段二进行排列.
在排序中NULL值是最小值.
4.限制(limit)数据记录查询数量:
num必须是常量整数
selecct * from table_name limit num;// num只数字,表示查询表中的前num行
selecct * from table_name limit num1,num2;// 表示第num1行后的num2条数据
5.统计函数和分组数据记录查询:
COUNT()函数:统计表中记录的条数
select count(属性字段) from table_name;// 属性字段可以为*,查询记录总和,如果字段中包含了null,null的那条结果不算入总和,但空值""算.
AVG()函数:实现计算字段值的平均值
select avg(属性字段) from table_name;
SUM()函数:实现计算字段值的总和
select sum(属性字段) from table_name;
MAX()函数:实现查询字段值的最大值
select max(属性字段) from table_name;
MIN()函数:实现查询字段值的最小值
select min(属性字段) from table_name;
select 属性字段 from table_name group by 属性字段;// 可以由多个条件(多列分组就要有多个条件,否则容易出错)
例子:
select deptno,job,count(1) from t_employee group by deptno, job;
功能分组查询:
select 属性字段1,group_concat(distinct(属性字段2)) from table_name group by 属性 字段1;
例子:
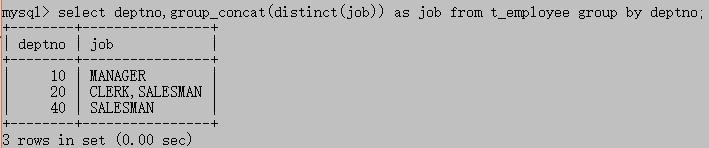
select deptno,group_concat(distinct(job)) as job from t_employee group by deptno;//如何理解?我认为是利用deptno分组,再将select distinct(job) from t_emplyee的结果再添加入表中,简单的来说就是配对连线.
利用图片来理解(只需要查看第三列和第四列):



多功能分组查询:
我理解为利用两个分组条件来分组,并统计每一个分组下另一个内容的个数或者种类.
直接用例子(不好理解):




使用having子句限定分组查询
相当于在分组的时候多加了一个条件
例子:select deptno,job,group_concat(ename) as p,count(1) as c from t_employee group by deptno,job having c > 3; 