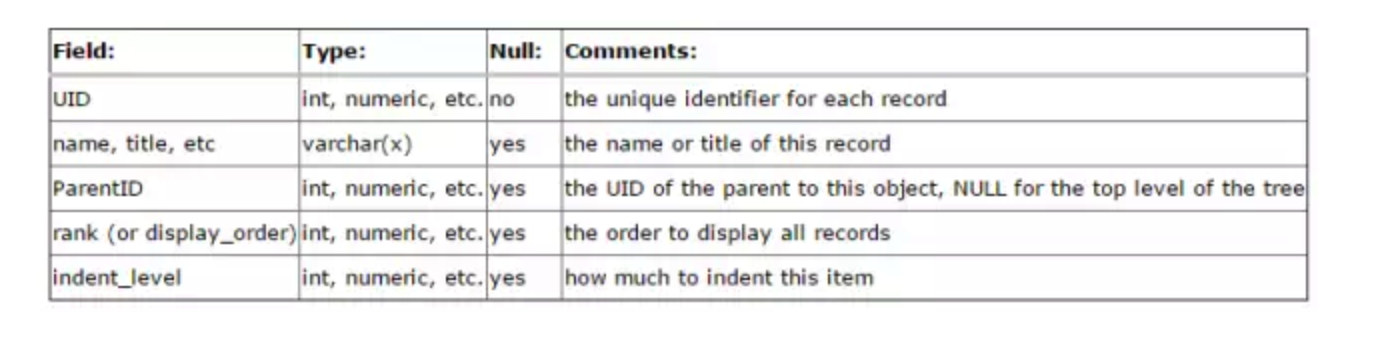
在程序开发中,我们常遇到用树型结构来表示某些数据间的关系,如企业的组织架构、商品的分类、操作栏目等,目前的关系型数据库都是以二维表的形式记录存储数据,而树型结构的数据如需存入二维表就必须进行Schema设计。
Adjacency List(邻接列表模式)
简单的说是根据节点之间的继承关系,显现的描述某一节点的父节点,从而建立二位的关系表。
表结构通常设计为{Node_id,Parent_id},如下图:
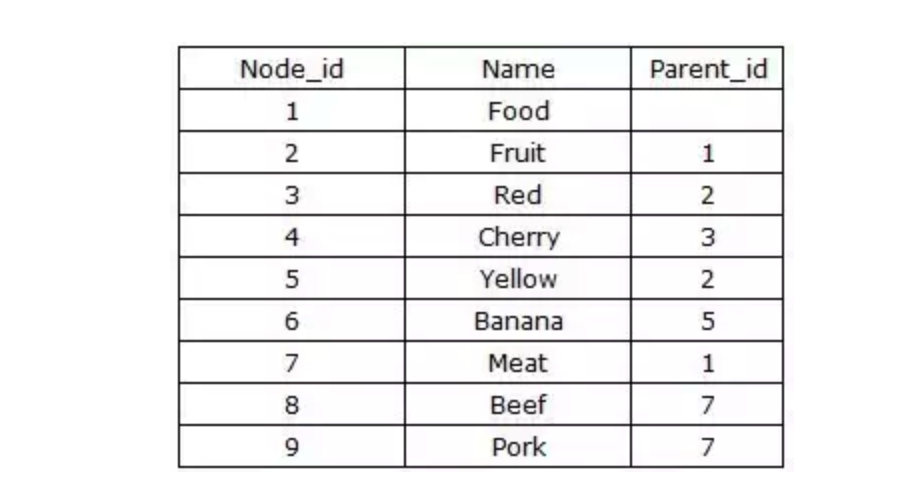
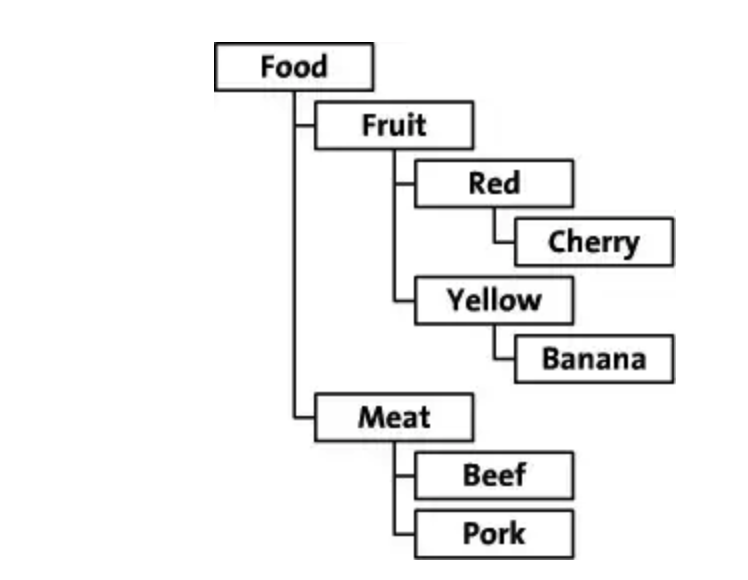
优点:
结构简单易懂,由于互相之间的关系只由一个parent_id维护,所以增删改都是非常容易,只需要改动和他直接相关的记录就可以。
缺点:
由于直接地记录了节点之间的继承关系,因此对Tree的任何CRUD操作都将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。
PS:在邻接列表模式的基础上还可以拓展的是平面表,区别是将节点的level和当前节点的顺序也放入表中,比较适合类似评论等场景。